How Reliable Are Semantic-ID Tokenizer Comparisons in Generative Recommendation?
Pith reviewed 2026-06-29 21:02 UTC · model grok-4.3
The pith
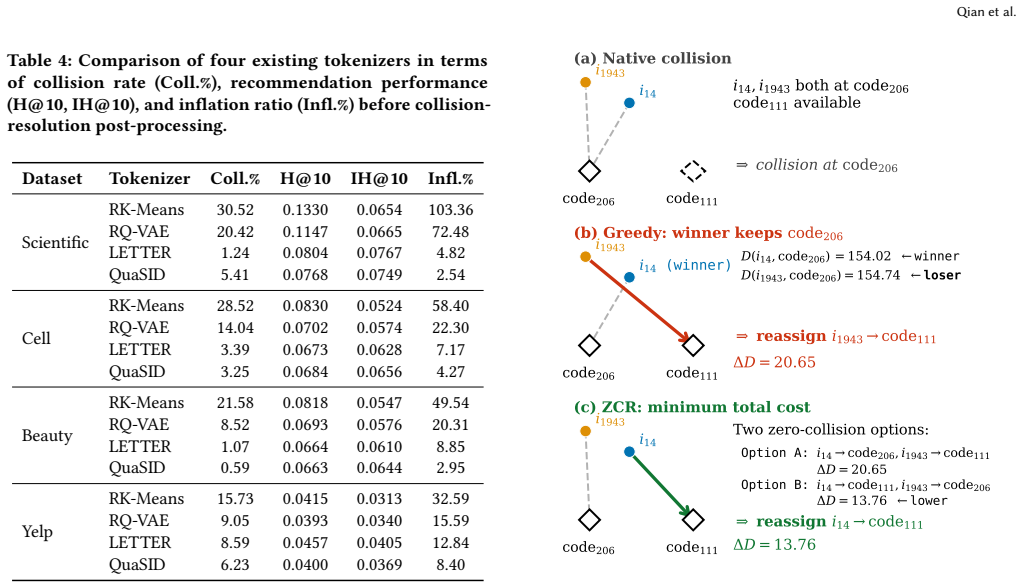
Semantic-ID tokenizers often assign identical code sequences to multiple items, so standard hit rates count group matches as successes and inflate performance by up to 103 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
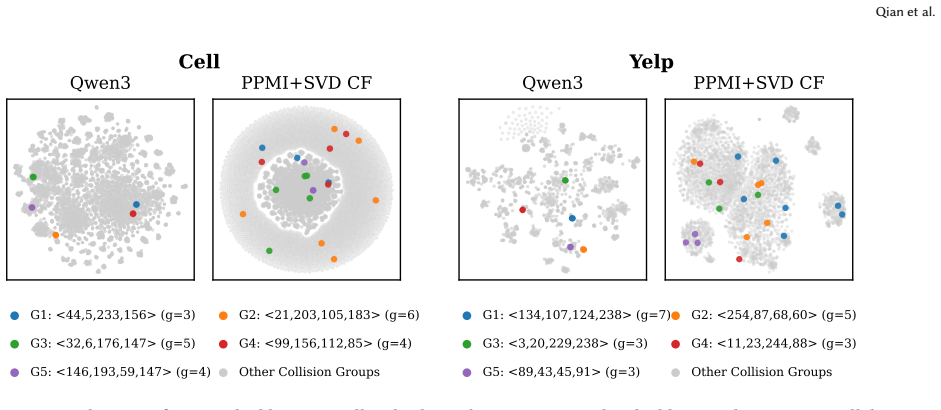
Because tokenizers compress item features into a code space, semantically similar but collaboratively distinct items are frequently assigned the same SID sequence; across four datasets and five representative tokenizers the fraction of items involved in collisions reaches 30.5 percent, so SID-level matching identifies only a collision group rather than the target item and inflates Hit@10 by up to 103.36 percent.
What carries the argument
SID collision groups, where multiple items share an identical code sequence produced by the tokenizer, which the paper measures directly and corrects via post-tokenizer last-level reassignment.
If this is right
- SID-level rankings of tokenizers reported in prior work must be treated as upper bounds on item-level performance.
- The degree of metric inflation scales directly with the measured collision rate.
- Any generative recommender using SID generation requires either explicit collision correction or a collision-free code assignment to produce trustworthy item-level scores.
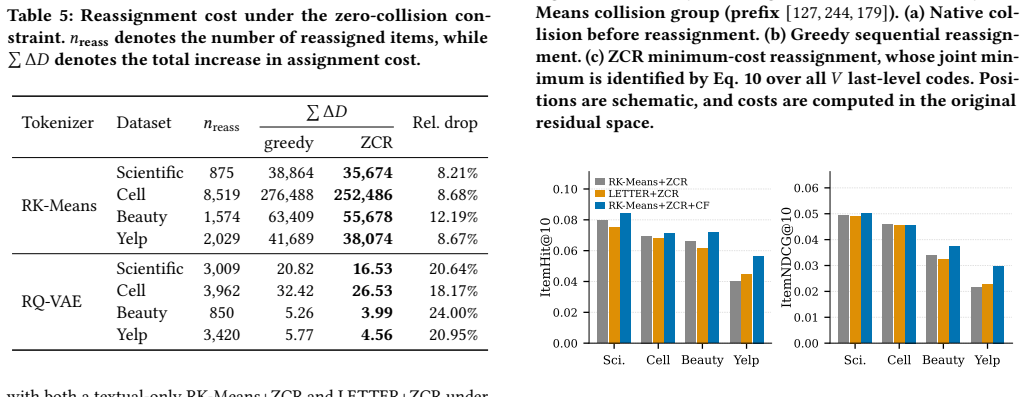
- The proposed minimum-cost reassignment produces a collision-free SID space for any existing tokenizer without retraining the tokenizer itself.
Where Pith is reading between the lines
- The same collision phenomenon could appear in any autoregressive model that decodes discrete codes to real-world entities, not only recommendation.
- Tokenizer designers may need to optimize jointly for semantic fidelity and uniqueness of the final code sequences.
- If the reassignment step alters downstream generation quality, an explicit trade-off study between collision rate and semantic coherence would be needed.
Load-bearing premise
The four chosen datasets and five tokenizers are representative enough that the observed collision rates and metric inflation generalize to other recommendation settings and tokenizers.
What would settle it
Compute both SID-level and true item-level Hit@10 on a held-out test set after applying the collision-aware metric; if the gap between the two metrics is near zero on every dataset, the claimed inflation does not hold.
Figures


read the original abstract
In Semantic-ID (SID) based generative recommendation, each item is represented as a sequence of discrete codes, and an autoregressive model is trained to generate the SID sequence of the next item; top-K performance is then measured by checking whether the SID sequence of the target item appears among the generated sequences. This evaluation protocol equates SID-level matching with item-level recommendation, an equivalence that holds only when every SID sequence maps to a single item. We show this assumption breaks down in practice: because tokenizers compress item features into a code space, semantically similar but collaboratively distinct items are frequently assigned the same SID sequence. Across four datasets and five representative tokenizers, the fraction of items involved in such collisions reaches 30.5%, so matching a shared SID sequence identifies only a collision group rather than the target item. Consequently, SID-level metrics overestimate item-level performance (Hit@10 is inflated by up to 103.36%), and the inflation grows with the collision rate. To support faithful comparison, we develop collision-aware item-level metrics computed directly from generated SID sequences, together with a post-tokenizer procedure that reassigns last-level SIDs at minimum cost to obtain a collision-free assignment for any existing tokenizer. Our results indicate that SID-level rankings in prior work should be interpreted with caution, and that reliable tokenizer evaluation requires either item-level correction or collision-free SID assignments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Semantic-ID (SID) collisions are common in generative recommendation (up to 30.5% of items involved across four datasets and five tokenizers), so that SID-level matching identifies collision groups rather than unique items; this causes SID-level metrics to overestimate item-level performance (Hit@10 inflated by up to 103.36%). It introduces collision-aware item-level metrics computed from generated SID sequences and a post-tokenizer last-level SID reassignment procedure that produces collision-free assignments at minimum cost.
Significance. If the empirical observations hold, the work identifies a previously under-appreciated source of metric inflation that affects the reliability of tokenizer comparisons in generative recommendation. Credit is due for the direct, parameter-free counting of collisions on held-out data and for supplying both diagnostic metrics and a practical correction procedure that can be applied to existing tokenizers.
major comments (2)
- [§4] §4 (Experiments): the claim that results generalize to 'prior work' and 'other recommendation settings' rests on four datasets and five tokenizers being representative, yet no additional datasets, tokenizer variants, or sensitivity analysis are reported to support this; the observed 30.5% and 103.36% figures are therefore load-bearing for the headline cautionary conclusion.
- [§3.3] §3.3 (Post-tokenizer reassignment): the procedure reassigns last-level SIDs to eliminate collisions, but no before/after check (e.g., item embedding cosine similarity, reconstruction quality, or downstream generation metrics) is provided to verify that semantic structure is preserved; this is required to ensure the corrected assignments remain faithful to the tokenizer's original intent.
minor comments (2)
- [Table 1] Table 1: the tokenizer names and their hyper-parameter settings should be listed explicitly rather than referenced only by citation, to allow replication of the collision counts.
- [§2] §2: the notation for 'collision group' versus 'unique SID' is introduced informally; a short formal definition or diagram would improve clarity when the collision-aware metrics are later defined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the significance of our findings on SID collisions. Below we respond point-by-point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the claim that results generalize to 'prior work' and 'other recommendation settings' rests on four datasets and five tokenizers being representative, yet no additional datasets, tokenizer variants, or sensitivity analysis are reported to support this; the observed 30.5% and 103.36% figures are therefore load-bearing for the headline cautionary conclusion.
Authors: The four datasets and five tokenizers were chosen because they match those used in prior generative recommendation studies; the collision rates and Hit@10 inflation are consistent in direction and scale across every dataset–tokenizer pair. We therefore view the reported maxima as illustrative of the problem’s potential severity rather than as universal constants. We agree that explicit sensitivity checks would strengthen the generalization statement. In revision we will expand the discussion of dataset and tokenizer representativeness and include any additional internal sensitivity results that can be computed from the existing experimental logs without new runs. revision: partial
-
Referee: [§3.3] §3.3 (Post-tokenizer reassignment): the procedure reassigns last-level SIDs to eliminate collisions, but no before/after check (e.g., item embedding cosine similarity, reconstruction quality, or downstream generation metrics) is provided to verify that semantic structure is preserved; this is required to ensure the corrected assignments remain faithful to the tokenizer's original intent.
Authors: The reassignment is deliberately restricted to the final SID level and is performed under a minimum-cost objective, which by construction changes the fewest assignments possible. We nevertheless accept that explicit verification is desirable. In the revised manuscript we will add before-and-after comparisons of item embedding cosine similarity for the reassigned items together with any available reconstruction-quality statistics to quantify how much semantic structure is retained. revision: yes
Circularity Check
No circularity; central results are direct empirical counts on held-out data.
full rationale
The paper reports collision fractions (up to 30.5%) and metric inflation (Hit@10 up to 103.36%) via explicit counting of shared SID sequences across four datasets and five tokenizers. These quantities are computed directly from the data and tokenizer outputs rather than fitted parameters, self-referential equations, or load-bearing self-citations. The collision-aware metrics and minimum-cost reassignment procedure are introduced as practical corrections without any derivation that reduces to the inputs by construction. The analysis chain is therefore self-contained empirical measurement.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SIDInspector: A Mapping-First Diagnostic Resource for Semantic-ID Tokenizers
SIDInspector provides a standardized adapter contract and mapping-level probes for Semantic-ID tokenizers, with empirical contrasts showing high aliasing in GRID-style exports and superior prefix alignment from determ...
Reference graph
Works this paper leans on
-
[1]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. InProceedings of the 17th ACM Conference on Recommender Systems (RecSys). 1007–1014
2023
-
[2]
Maurizio Ferrari Dacrema, Paolo Cremonesi, and Dietmar Jannach. 2019. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Rec- ommendation Approaches. InProceedings of the 13th ACM Conference on Recom- mender Systems (RecSys). 101–109
2019
-
[3]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment.arXiv preprint arXiv:2502.18965(2025), 1–10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Dengzhao Fang, Jingtong Gao, Chengcheng Zhu, Yu Li, Xiangyu Zhao, and Yi Chang. 2025. HiD-VAE: Interpretable Generative Recommendation via Hierar- chical and Disentangled Semantic IDs.arXiv preprint arXiv:2508.04618(2025), 1–13. How Reliable Are Semantic-ID Tokenizer Comparisons in Generative Recommendation?
-
[5]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
2022
-
[6]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Net- work for Recommendation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 639–648
2020
-
[7]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[8]
In Proceedings of the International Conference on Learning Representations
Session-based Recommendations with Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations. 1–10
-
[9]
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. 2023. Learn- ing Vector-Quantized Item Representation for Transferable Sequential Recom- menders. InProceedings of the ACM Web Conference (WWW). 1162–1171
2023
-
[10]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating Long Semantic IDs in Parallel for Recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1–12
2025
-
[11]
Peiyu Hu, Wayne Lu, and Jia Wang. 2026. From IDs to Semantics: A Genera- tive Framework for Cross-Domain Recommendation with Adaptive Semantic Tokenization. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[12]
Zheng Hu, Yuxin Chen, Yongsen Pan, Xu Yuan, Yuting Yin, Daoyuan Wang, Boyang Xia, Zefei Luo, Hongyang Wang, Songhao Ni, Dongxu Liang, Jun Wang, Shimin Cai, Tao Zhou, Fuji Ren, and Wenwu Ou. 2026. Stop Treating Collisions Equally: Qualification-Aware Semantic ID Learning for Recommendation at Industrial Scale.arXiv:2603.00632(2026), 1–10
-
[13]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Transactions on Pattern Analysis and Machine Intelligence33, 1 (2011), 117–128
2011
-
[14]
Bowen Jin, Hansi Zeng, Guoyin Wang, Xiusi Chen, Tianxin Wei, Ruirui Li, Zhengyang Wang, Zheng Li, Yang Li, Hanqing Lu, Suhang Wang, Jiawei Han, and Xianfeng Tang. 2024. Language Models as Semantic Indexers. InProceedings of the 41st International Conference on Machine Learning (ICML). 22244–22259
2024
-
[15]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (2021), 535–547
2021
-
[16]
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. 2025. Generative Recommendation with Seman- tic IDs: A Practitioner’s Handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6420–6425
2025
-
[17]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation. InProceedings of the IEEE International Conference on Data Mining. 197–206
2018
-
[18]
Walid Krichene and Steffen Rendle. 2020. On Sampled Metrics for Item Recom- mendation. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 1748–1757
2020
-
[19]
Harold W. Kuhn. 1955. The Hungarian Method for the Assignment Problem. Naval Research Logistics Quarterly2, 1–2 (1955), 83–97
1955
-
[20]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregressive Image Generation Using Residual Quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11513–11522
2022
-
[21]
Omer Levy and Yoav Goldberg. 2014. Neural Word Embedding as Implicit Matrix Factorization. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 27
2014
-
[22]
Yu Liang, Zhongjin Zhang, Yuxuan Zhu, Kerui Zhang, Zhiluohan Guo, Wenhang Zhou, Zonqi Yang, Kangle Wu, Yabo Ni, Anxiang Zeng, Cong Fu, Jianxin Wang, and Jiazhi Xia. 2026. Rethinking Generative Recommender Tokenizer: Recsys- Native Encoding and Semantic Quantization Beyond LLMs.arXiv preprint arXiv:2602.02338(2026), 1–22
-
[23]
Fake Lin, Binbin Hu, Zhi Zheng, Xi Zhu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, and Tong Xu. 2026. Token-level Collaborative Alignment for LLM-based Generative Recommendation. InProceedings of the ACM Web Conference (WWW)
2026
-
[24]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, Huifeng Guo, Yong Yu, Ruiming Tang, and Weinan Zhang. 2025. How Can Recommender Systems Benefit from Large Language Models: A Survey.ACM Transactions on Information Systems43, 2 (2025), 1–47
2025
-
[25]
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao
-
[26]
InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Generative Recommender with End-to-End Learnable Item Tokenization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 729–739
-
[27]
Jingzhe Liu, Liam Collins, Jiliang Tang, Tong Zhao, Neil Shah, and Clark Mingx- uan Ju. 2025. Understanding Generative Recommendation with Semantic IDs from a Model-Scaling View.arXiv preprint arXiv:2509.25522(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al. 2025. QARM: Quantitative alignment multi-modal recommendation at Kuaishou. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5915– 5922
2025
-
[29]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 188–197
2019
-
[30]
Haohao Qu, Wenqi Fan, Zihuai Zhao, and Qing Li. 2025. TokenRec: Learning to Tokenize ID for LLM-Based Generative Recommendations.IEEE Transactions on Knowledge and Data Engineering37, 10 (2025), 6216–6231
2025
-
[31]
Haohao Qu, Shanru Lin, Yujuan Ding, Yiqi Wang, and Wenqi Fan. 2026. Diffusion Generative Recommendation with Continuous Tokens. InProceedings of the ACM Web Conference (WWW)
2026
-
[32]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
2020
-
[33]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[34]
InAdvances in Neural Information Processing Systems (NeurIPS)
Recommender Systems with Generative Retrieval. InAdvances in Neural Information Processing Systems (NeurIPS). 10299–10315
-
[35]
Steffen Rendle, Li Zhang, and Yehuda Koren. 2019. On the Difficulty of Evaluating Baselines: A Study on Recommender Systems.arXiv preprint arXiv:1905.01395 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[37]
InProceedings of the 28th ACM International Conference on Information and Knowledge Management
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep- resentations from Transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 1441–1450
-
[38]
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural Discrete Representation Learning. InAdvances in Neural Information Processing Systems (NeurIPS). 6306–6315
2017
-
[39]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing Data using t-SNE.Journal of Machine Learning Research9, 86 (2008), 2579–2605
2008
-
[40]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems (NeurIPS). 5998– 6008
2017
-
[41]
Chao Wang, Yixin Song, Jinhui Ye, Chuan Qin, Dazhong Shen, Lingfeng Liu, Xi- ang Wang, and Yanyong Zhang. 2025. FACE: A General Framework for Mapping Collaborative Filtering Embeddings into LLM Tokens. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[42]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
-
[43]
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, and Zhenhua Dong. 2024. EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3245–3254
2024
-
[44]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive Learning for Sequential Recommendation. InProceedings of the 38th IEEE International Conference on Data Engineering (ICDE). 1259–1273
2022
-
[45]
Yuhao Yang, Zhi Ji, Zhaopeng Li, Yi Li, Zhonglin Mo, Yue Ding, Kai Chen, Zijian Zhang, Jie Li, Shuanglong Li, and Lin Liu. 2025. Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations. In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[46]
Jianyang Zhai, Zi-Feng Mai, Chang-Dong Wang, Feidiao Yang, Xiawu Zheng, Hui Li, and Yonghong Tian. 2025. Multimodal Quantitative Language for Generative Recommendation. InThe 13th International Conference on Learning Representa- tions. 1–23
2025
- [47]
-
[48]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[49]
Qwen3 Embedding: Advancing Text Embedding and Reranking through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
2024
- [51]
- [52]
-
[53]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S 3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. InPro- ceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM). 1893–1902
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.