Names Are All You Need: Effective and Safe Regression Test Selection for Python
Pith reviewed 2026-06-29 21:04 UTC · model grok-4.3
The pith
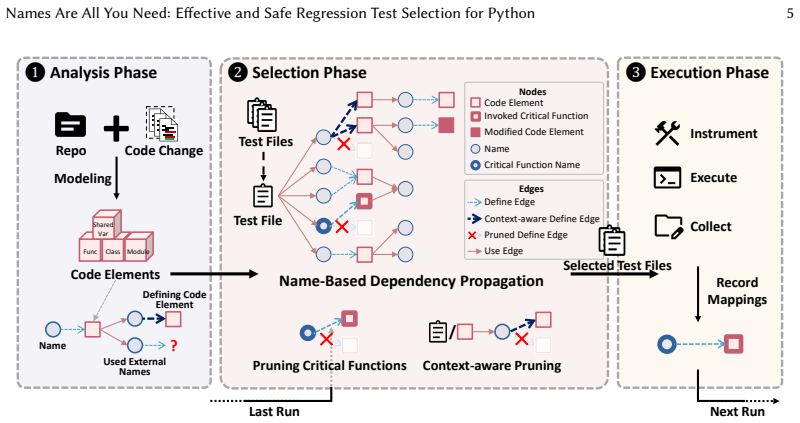
NameRTS models Python code as a bipartite graph of elements and names to select affected tests via reachability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NameRTS models a Python program as a bipartite graph of code element nodes and name nodes, with edges capturing definitions and references. RTS is formulated as a reachability problem on this graph: a test is selected if any modified code element is reachable from the names used in that test. This design avoids call-graph construction, enabling a conservative analysis amenable to safety. To control dependency cascades introduced by coarse name matching, NameRTS applies two pruning strategies that leverage prior test executions and context information to refine name matching.
What carries the argument
Bipartite graph of code element nodes and name nodes whose reachability relation determines test selection, augmented by execution-history and context-based pruning of name matches.
If this is right
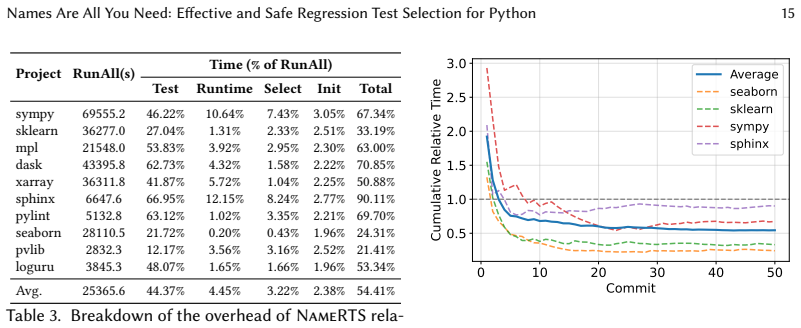
- NameRTS skips 69.90 percent of test files on average across the benchmark.
- It reduces end-to-end testing time by 45.59 percent.
- It selects every affected test for 99.6 percent of commits.
- It outperforms a file-level baseline both in the fraction of tests skipped and in the fraction of commits handled safely.
Where Pith is reading between the lines
- The name-reachability model could be adapted to other dynamically typed languages that rely on eager imports.
- The new dataset could become a shared resource for comparing additional Python testing techniques.
- Extending the pruning rules with more execution context might further reduce the small number of missed tests.
- Combining the static reachability check with lightweight runtime monitoring could address the exceptional cases where dynamic behavior evades the graph.
Load-bearing premise
The newly constructed Python RTS dataset supplies accurate ground truth that identifies exactly which test files are affected by each commit.
What would settle it
A commit for which the dataset labels certain test files as unaffected yet those files fail when run after the commit, or vice versa.
Figures

read the original abstract
Regression test selection reduces the cost of regression testing by executing only those tests affected by a code change. Despite extensive study of RTS in statically typed languages, achieving effective and safe RTS in Python is challenging. Python's dynamic typing makes precise call-graph construction difficult, which can cause call-graph-based RTS to miss affected tests. Python's eager importing mechanism, in contrast, renders file-level dependency analysis overly conservative. This paper presents NameRTS, the first Python RTS approach based on fine-grained dependency analysis. NameRTS models a Python program as a bipartite graph of code element nodes and name nodes, with edges capturing definitions and references. RTS is formulated as a reachability problem on this graph: a test is selected if any modified code element is reachable from the names used in that test. This design avoids call-graph construction, enabling a conservative analysis amenable to safety. To control dependency cascades introduced by coarse name matching, NameRTS applies two pruning strategies that leverage prior test executions and context information to refine name matching. To evaluate NameRTS, we construct the first Python RTS dataset with a ground truth indicating which test files are affected by each commit. We compare NameRTS with the best-performing baseline, BabelRTS, an RTS technique based on coarse file-level dependencies. On this benchmark, NameRTS skips 69.90% of test files on average, outperforming BabelRTS by 146.5%. It also reduces end-to-end testing time by 45.59%, yielding a 107.7% improvement over BabelRTS. In terms of safety, NameRTS selects all affected tests for 99.6% of commits, with only rare misses in exceptional cases. In contrast, BabelRTS is safe for 76.6% of commits. These results demonstrate the effectiveness of NameRTS, paving the way for more efficient regression testing in Python.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NameRTS, the first Python-specific regression test selection (RTS) technique that models programs as a bipartite graph of code-element nodes and name nodes, formulates RTS as a reachability query on this graph, and applies two pruning strategies based on prior executions and context. It constructs a new Python RTS benchmark dataset providing ground-truth affected test files per commit, and reports that NameRTS skips 69.90% of test files on average (146.5% better than BabelRTS), reduces end-to-end testing time by 45.59%, and is safe on 99.6% of commits (vs. 76.6% for BabelRTS).
Significance. If the ground-truth labels prove accurate, the work would be significant for the RTS literature by demonstrating that name-based fine-grained analysis can be both effective and safe in a dynamically typed language where call-graph and file-level methods struggle; the bipartite-graph formulation and pruning heuristics are a concrete, falsifiable contribution that could be replicated or extended.
major comments (2)
- [Abstract and Evaluation section (dataset construction)] The manuscript provides no description of the labeling procedure used to establish ground truth (which test files are affected by each commit) in the newly constructed dataset referenced in the abstract and evaluation. All headline metrics—69.90% skip rate, 99.6% safety, 45.59% time reduction, and the 146.5% outperformance—are computed directly against these labels; without details on whether labels were obtained via full re-execution, coverage instrumentation, differential outcomes, or static reachability, the validity of the safety and effectiveness claims cannot be assessed.
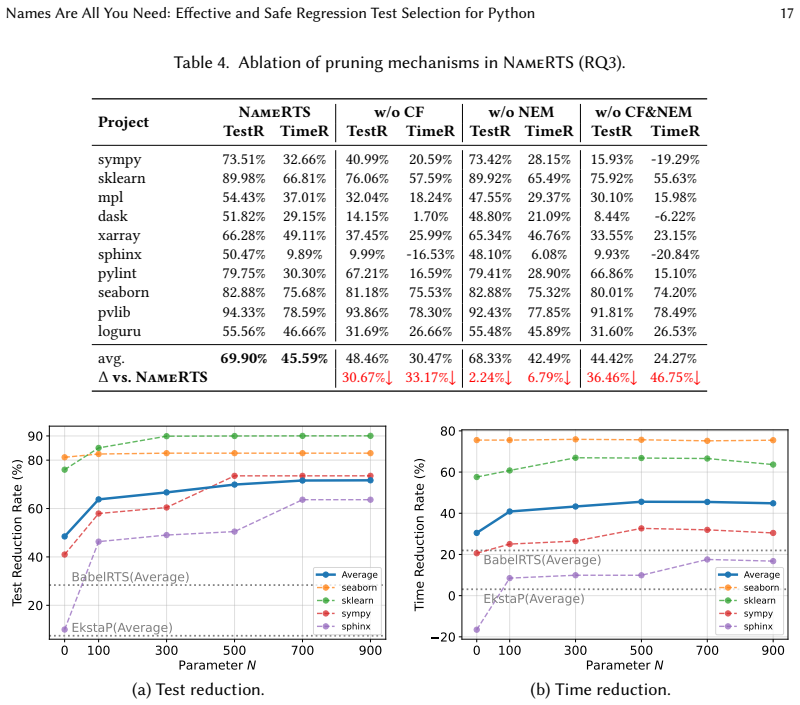
- [Approach section (pruning strategies)] The two pruning strategies that refine name matching (to control dependency cascades) are presented as preserving conservatism, yet no ablation or separate quantification is given showing their effect on the safety rate; if pruning ever drops an affected test, the 99.6% safety figure would be overstated.
minor comments (1)
- [Approach] Notation for the bipartite graph (code-element nodes vs. name nodes) should be introduced with a small example or diagram early in the approach section to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity on dataset construction and to add supporting analysis on the pruning strategies.
read point-by-point responses
-
Referee: [Abstract and Evaluation section (dataset construction)] The manuscript provides no description of the labeling procedure used to establish ground truth (which test files are affected by each commit) in the newly constructed dataset referenced in the abstract and evaluation. All headline metrics—69.90% skip rate, 99.6% safety, 45.59% time reduction, and the 146.5% outperformance—are computed directly against these labels; without details on whether labels were obtained via full re-execution, coverage instrumentation, differential outcomes, or static reachability, the validity of the safety and effectiveness claims cannot be assessed.
Authors: We agree that the absence of a description of the ground-truth labeling procedure is a significant omission that prevents readers from assessing the validity of the reported metrics. In the revised manuscript we will add a dedicated subsection (likely in Section 5) that fully documents the labeling process, including the exact steps taken to determine which test files are affected by each commit. revision: yes
-
Referee: [Approach section (pruning strategies)] The two pruning strategies that refine name matching (to control dependency cascades) are presented as preserving conservatism, yet no ablation or separate quantification is given showing their effect on the safety rate; if pruning ever drops an affected test, the 99.6% safety figure would be overstated.
Authors: We acknowledge that an explicit ablation or quantification of the pruning strategies' impact on safety would strengthen the paper. In the revision we will add an ablation study (new table or figure in the Evaluation section) that reports safety rates with and without each pruning strategy, thereby directly addressing whether the 99.6% safety figure is affected by pruning. revision: yes
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The paper defines NameRTS via an explicit bipartite-graph reachability model, introduces two pruning heuristics, constructs an independent benchmark dataset, and reports empirical comparisons against an external baseline (BabelRTS). None of the load-bearing claims reduce by construction to the method's own inputs, fitted parameters, or self-citations; the safety and effectiveness numbers are measured against the separately constructed ground-truth labels rather than being tautological with the algorithm itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Python programs can be modeled as a bipartite graph of code element nodes and name nodes with edges capturing definitions and references.
invented entities (1)
-
Bipartite graph of code elements and name nodes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025. 3. Data model - Python 3.14.0 documentation. https://docs.python.org/3/reference/datamodel.html
2025
-
[2]
Compound statements – Python 3.14.0 documentation
2025. Compound statements – Python 3.14.0 documentation. https://docs.python.org/3/reference/compound_stmts. html#function-definitions
2025
-
[3]
dis - Disassembler for Python bytecode - Python 3.14.0 documentation
2025. dis - Disassembler for Python bytecode - Python 3.14.0 documentation. https://docs.python.org/3/library/dis. html#dis.hasname
2025
-
[4]
The import system – Python 3.14.0 documentation
2025. The import system – Python 3.14.0 documentation. https://docs.python.org/3/reference/import.html#regular- packages
2025
-
[5]
Octoverse: A new developer joins GitHub every second as AI leads TypeScript to #1
2025. Octoverse: A new developer joins GitHub every second as AI leads TypeScript to #1. https://github.blog/news- insights/octoverse/octoverse-a-new-developer-joins-github-every-second-as-ai-leads-typescript-to-1/
2025
-
[6]
Technology | 2025 Stack Overflow Developer Survey
2025. Technology | 2025 Stack Overflow Developer Survey. https://survey.stackoverflow.co/2025/technology#most- popular-technologies
2025
-
[7]
TIOBE Index - TIOBE
2025. TIOBE Index - TIOBE. https://www.tiobe.com/tiobe-index/
2025
-
[8]
Tools and Trends - The State of Developer Ecosystem in 2025
2025. Tools and Trends - The State of Developer Ecosystem in 2025. https://devecosystem-2025.jetbrains.com/tools- and-trends
2025
-
[9]
Our replication package
2026. Our replication package. https://github.com/ZJU-CTAG/NameRTS
2026
-
[10]
Beatrice Åkerblom, Jonathan Stendahl, Mattias Tumlin, and Tobias Wrigstad. 2014. Tracing dynamic features in python programs. InProceedings of the 11th working conference on mining software repositories. 292–295
2014
-
[11]
Khaled Walid Al-Sabbagh, Miroslaw Staron, Miroslaw Ochodek, Regina Hebig, and Wilhelm Meding. 2020. Selective regression testing based on big data: Comparing feature extraction techniques. In2020 IEEE International Conference on Software Testing, Verification and Validation Workshops. 322–329
2020
-
[12]
Jeff Anderson, Saeed Salem, and Hyunsook Do. 2014. Improving the effectiveness of test suite through mining historical data. InProceedings of the 11th Working Conference on Mining Software Repositories. 142–151
2014
-
[13]
Maral Azizi and Hyunsook Do. 2018. ReTEST: A cost effective test case selection technique for modern software development. In2018 IEEE 29th International Symposium on Software Reliability Engineering. 144–154
2018
-
[14]
Antonia Bertolino, Antonio Guerriero, Breno Miranda, Roberto Pietrantuono, and Stefano Russo. 2020. Learning-to- rank vs ranking-to-learn: Strategies for regression testing in continuous integration. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 1–12
2020
-
[15]
Vincent Blondeau, Anne Etien, Nicolas Anquetil, Sylvain Cresson, Pascal Croisy, and Stéphane Ducasse. 2017. Test case selection in industry: An analysis of issues related to static approaches.Software Quality Journal25, 4 (2017), 1203–1237
2017
-
[16]
Islem Bouzenia, Bajaj Piyush Krishan, and Michael Pradel. 2024. DyPyBench: A benchmark of executable python software.Proceedings of the ACM on Software Engineering1 (2024), 338–358
2024
-
[17]
Islem Bouzenia and Michael Pradel. 2024. Resource usage and optimization opportunities in workflows of github actions. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
2024
-
[18]
Yufeng Chen. 2021. NodeSRT: a selective regression testing tool for Node. js application. In2021 IEEE/ACM 43rd International Conference on Software Engineering: Companion Proceedings. 126–128
2021
-
[19]
Pavan Kumar Chittimalli and Mary Jean Harrold. 2009. Recomputing coverage information to assist regression testing. IEEE Transactions on Software Engineering35, 4 (2009), 452–469
2009
- [20]
-
[21]
Aryaz Eghbali and Michael Pradel. 2022. DynaPyt: a dynamic analysis framework for Python. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 760–771
2022
-
[22]
Daniel Elsner, Severin Kacianka, Stephan Lipp, Alexander Pretschner, Axel Habermann, Maria Graber, and Silke Reimer
-
[23]
In2023 IEEE Conference on Software Testing, Verification and Validation
BinaryRTS: Cross-language regression test selection for C++ binaries in CI. In2023 IEEE Conference on Software Testing, Verification and Validation. 327–338. , Vol. 1, No. 1, Article . Publication date: May 2026. Names Are All You Need: Effective and Safe Regression Test Selection for Python 21
2026
-
[24]
Emelie Engström, Per Runeson, and Mats Skoglund. 2010. A systematic review on regression test selection techniques. Information and Software Technology52, 1 (2010), 14–30
2010
-
[25]
Ben Fu, Sasa Misailovic, and Milos Gligoric. 2019. Resurgence of regression test selection for C++. In2019 12th IEEE Conference on Software Testing, Validation and Verification. 323–334
2019
-
[26]
Milos Gligoric, Lamyaa Eloussi, and Darko Marinov. 2015. Practical regression test selection with dynamic file dependencies. InProceedings of the 2015 International Symposium on Software Testing and Analysis. 211–222
2015
-
[27]
Alex Gyori, Owolabi Legunsen, Farah Hariri, and Darko Marinov. 2018. Evaluating regression test selection oppor- tunities in a very large open-source ecosystem. In2018 IEEE 29th International Symposium on Software Reliability Engineering. 112–122
2018
-
[28]
M Jean Harrold, Rajiv Gupta, and Mary Lou Soffa. 1993. A methodology for controlling the size of a test suite.ACM Transactions on Software Engineering and Methodology2, 3 (1993), 270–285
1993
-
[29]
Simon Hundsdorfer, Roland Würsching, and Alexander Pretschner. 2025. RustyRTS: Regression Test Selection for Rust. In2025 IEEE Conference on Software Testing, Verification and Validation. 338–348
2025
- [30]
-
[31]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE- bench: Can language models resolve real-world GitHub issues?. InInternational Conference on Learning Representations
2024
-
[32]
Eero Kauhanen, Jukka K Nurminen, Tommi Mikkonen, and Matvei Pashkovskiy. 2021. Regression test selection tool for python in continuous integration process. In2021 IEEE International Conference on Software Analysis, Evolution and Reengineering. 618–621
2021
-
[33]
James Law and Gregg Rothermel. 2003. Whole program path-based dynamic impact analysis. In25th International Conference on Software Engineering, 2003. Proceedings.308–318
2003
-
[34]
Owolabi Legunsen, Farah Hariri, August Shi, Yafeng Lu, Lingming Zhang, and Darko Marinov. 2016. An extensive study of static regression test selection in modern software evolution. InProceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. 583–594
2016
-
[35]
Owolabi Legunsen, August Shi, and Darko Marinov. 2017. STARTS: STAtic regression test selection. In2017 32nd IEEE/ACM International Conference on Automated Software Engineering. 949–954
2017
-
[36]
Hareton KN Leung and Lee White. 1989. Insights into regression testing (software testing). InProceedings. Conference on Software Maintenance-1989. 60–69
1989
-
[37]
Hareton KN Leung and Lee White. 1990. A study of integration testing and software regression at the integration level. InProceedings. Conference on Software Maintenance 1990. 290–301
1990
-
[38]
Yue Li, Tian Tan, and Jingling Xue. 2019. Understanding and analyzing java reflection.ACM Transactions on Software Engineering and Methodology28, 2 (2019), 1–50
2019
-
[39]
Yingling Li, Junjie Wang, Yun Yang, and Qing Wang. 2019. Method-level test selection for continuous integration with static dependencies and dynamic execution rules. In2019 IEEE 19th International Conference on Software Quality, Reliability and Security. 350–361
2019
-
[40]
Yu Liu, Jiyang Zhang, Pengyu Nie, Milos Gligoric, and Owolabi Legunsen. 2023. More precise regression test selection via reasoning about semantics-modifying changes. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. 664–676
2023
-
[41]
Mateusz Machalica, Alex Samylkin, Meredith Porth, and Satish Chandra. 2019. Predictive test selection. In2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice. 91–100
2019
-
[42]
Gabriele Maurina, Walter Cazzola, and Sudipto Ghosh. 2025. BabelRTS: Polyglot Regression Test Selection.IEEE Transactions on Software Engineering(2025)
2025
-
[43]
Alessandro Orso, Nanjuan Shi, and Mary Jean Harrold. 2004. Scaling regression testing to large software systems. ACM SIGSOFT Software Engineering Notes29, 6 (2004), 241–251
2004
-
[44]
Cong Pan and Michael Pradel. 2021. Continuous test suite failure prediction. InProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis. 553–565
2021
-
[45]
Gregg Rothermel and Mary Jean Harrold. 1997. A safe, efficient regression test selection technique.ACM Transactions on Software Engineering and Methodology6, 2 (1997), 173–210
1997
-
[46]
Gregg Rothermel and Mary Jean Harrold. 2002. Analyzing regression test selection techniques.IEEE Transactions on software engineering22, 8 (2002), 529–551
2002
-
[47]
Vitalis Salis, Thodoris Sotiropoulos, Panos Louridas, Diomidis Spinellis, and Dimitris Mitropoulos. 2021. Pycg: Practical call graph generation in python. In2021 IEEE/ACM 43rd International Conference on Software Engineering. 1646–1657
2021
-
[48]
August Shi, Milica Hadzi-Tanovic, Lingming Zhang, Darko Marinov, and Owolabi Legunsen. 2019. Reflection-aware static regression test selection.Proceedings of the ACM on Programming Languages3 (2019), 1–29
2019
-
[49]
Quinten David Soetens, Serge Demeyer, Andy Zaidman, and Javier Pérez. 2016. Change-based test selection: an empirical evaluation.Empirical software engineering21, 5 (2016), 1990–2032. , Vol. 1, No. 1, Article . Publication date: May 2026. 22 You Wang, Michael Pradel, and Zhongxin Liu
2016
-
[50]
Marko Vasic, Zuhair Parvez, Aleksandar Milicevic, and Milos Gligoric. 2017. File-level vs. module-level regression test selection for. net. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering. 848–853
2017
-
[51]
Kaiyuan Wang, Chenguang Zhu, Ahmet Celik, Jongwook Kim, Don Batory, and Milos Gligoric. 2018. Towards refactoring-aware regression test selection. InProceedings of the 40th international conference on software engineering. 233–244
2018
-
[52]
Solved Issues
You Wang, Michael Pradel, and Zhongxin Liu. 2026. Are “Solved Issues” in SWE-bench Really Solved Correctly? An Empirical Study. In2026 IEEE/ACM 48th International Conference on Software Engineering
2026
-
[53]
W Eric Wong, Joseph R Horgan, Saul London, and Hiralal Agrawal. 1997. A study of effective regression testing in practice. InPROCEEDINGS The Eighth International Symposium On Software Reliability Engineering. 264–274
1997
-
[54]
Shin Yoo and Mark Harman. 2012. Regression testing minimization, selection and prioritization: a survey.Software testing, verification and reliability22, 2 (2012), 67–120
2012
-
[55]
2021.Towards Parallelization of Regression Test Selection
Maruf Hasan Zaber. 2021.Towards Parallelization of Regression Test Selection. Master’s thesis. University of California, Irvine
2021
-
[56]
Chengming Zhang, Haoye Wang, Chuyang Xu, Jiakun Liu, Kui Liu, and Zhongxin Liu. 2026. Can test cases generated by large language models facilitate automated program repair?Empirical Software Engineering31, 3 (2026), 68
2026
-
[57]
Guofeng Zhang, Luyao Liu, Zhenbang Chen, and Ji Wang. 2024. Hybrid Regression Test Selection by Integrating File and Method Dependences. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1557–1569
2024
-
[58]
Lingming Zhang. 2018. Hybrid regression test selection. InProceedings of the 40th International Conference on Software Engineering. 199–209
2018
-
[59]
Chenguang Zhu, Owolabi Legunsen, August Shi, and Milos Gligoric. 2019. A framework for checking regression test selection tools. In2019 IEEE/ACM 41st International Conference on Software Engineering. 430–441. , Vol. 1, No. 1, Article . Publication date: May 2026
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.