Towards Reliable Fetal Ultrasound Interpretation with Multi-Agent Collaboration
Pith reviewed 2026-06-29 22:49 UTC · model grok-4.3
The pith
FetUSAgents uses multi-agent collaboration with visual tools and Dual-Path Evidence Arbitration to exceed MLLM baselines by more than 25 percent in fetal ultrasound VQA accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
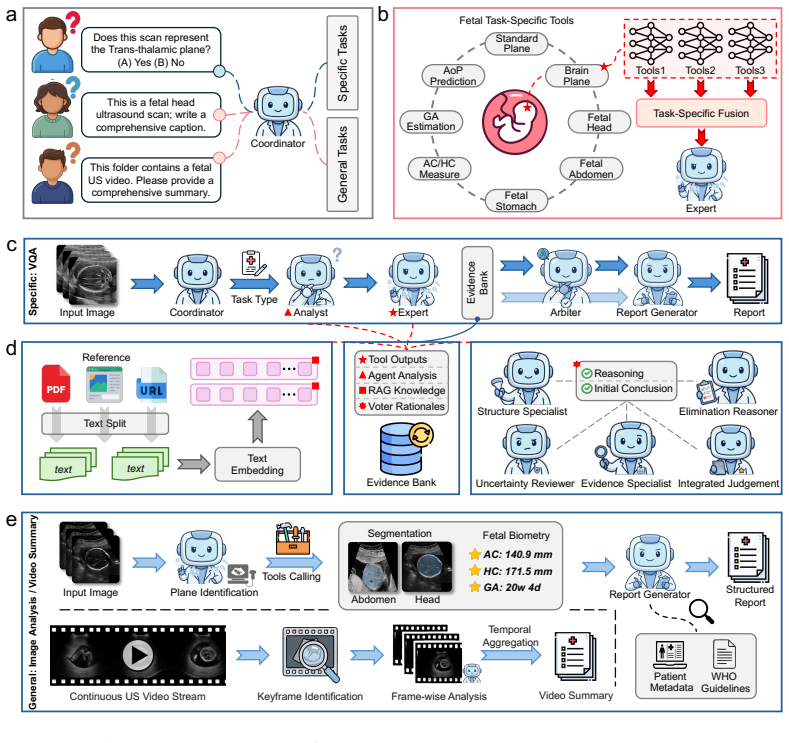
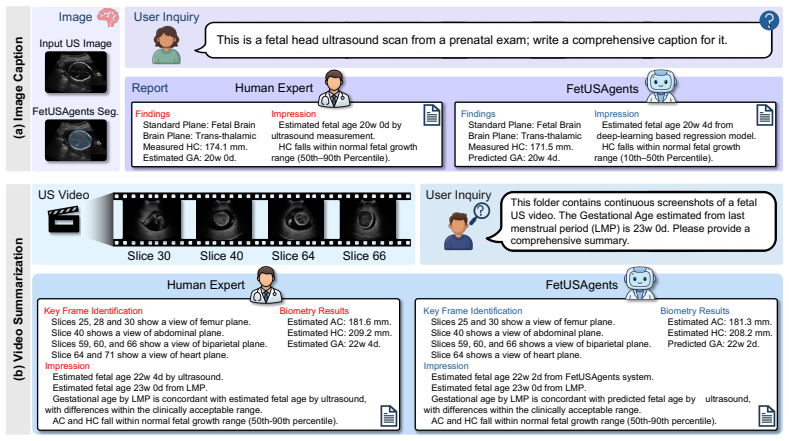
FetUSAgents is a tool-augmented multi-agent system that coordinates task-specific visual tools through collaborative LLM agents, decomposes queries from anatomical recognition to quantitative measurement, and applies Dual-Path Evidence Arbitration together with a retrieval-enhanced evidence bank to deliver traceable and clinically grounded outputs across visual question answering, report generation, image captioning, and video summarization.
What carries the argument
Dual-Path Evidence Arbitration (DPEA), which integrates LLM-based deliberative reasoning with structured computational evidence from specialized visual tools while a retrieval-enhanced evidence bank consolidates findings for traceable conclusions.
If this is right
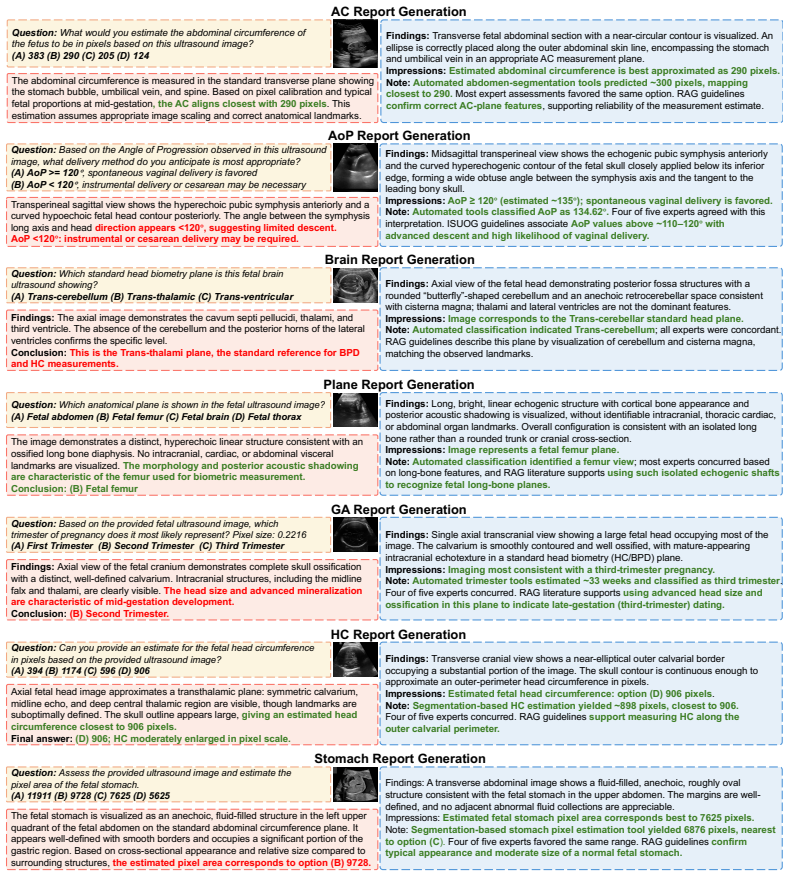
- FetUSAgents supports four tasks: visual question answering, report generation, image captioning, and video summarization.
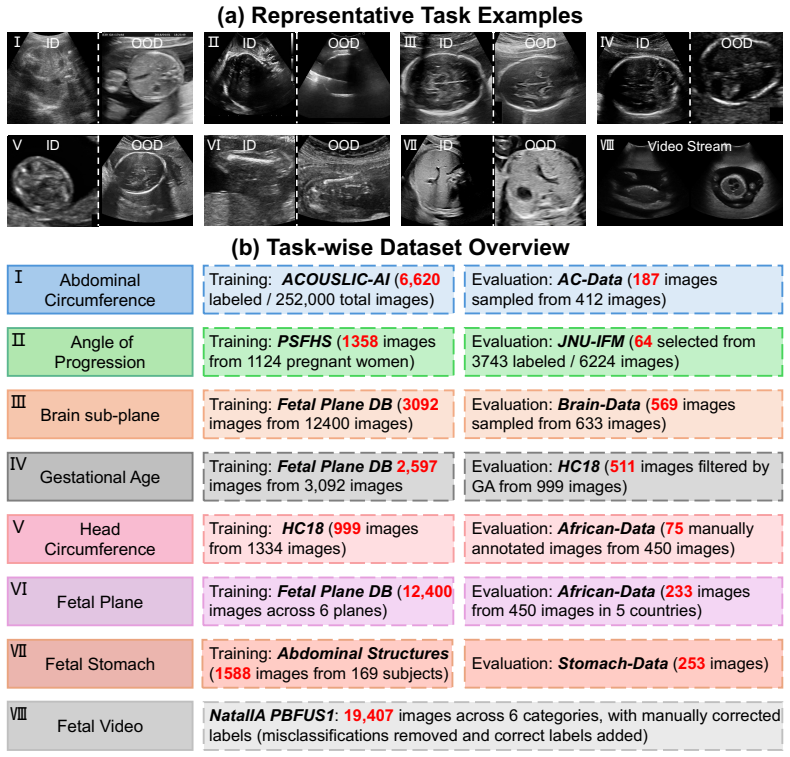
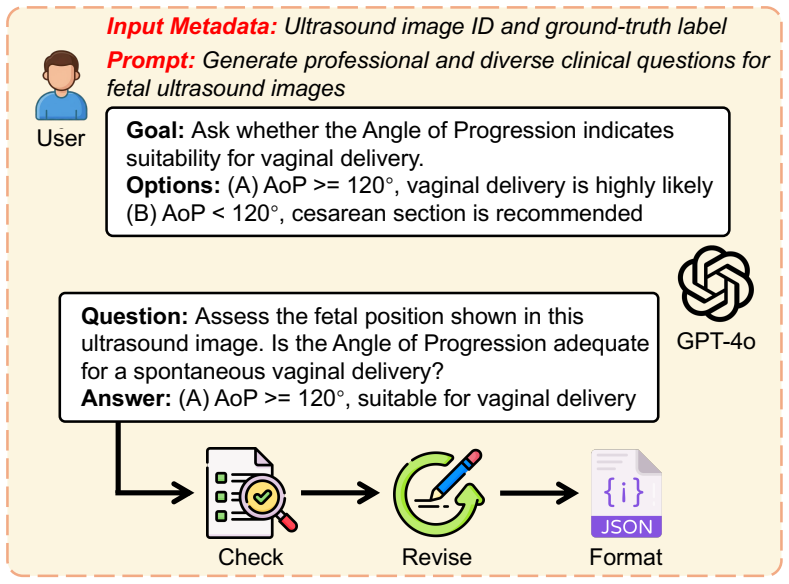
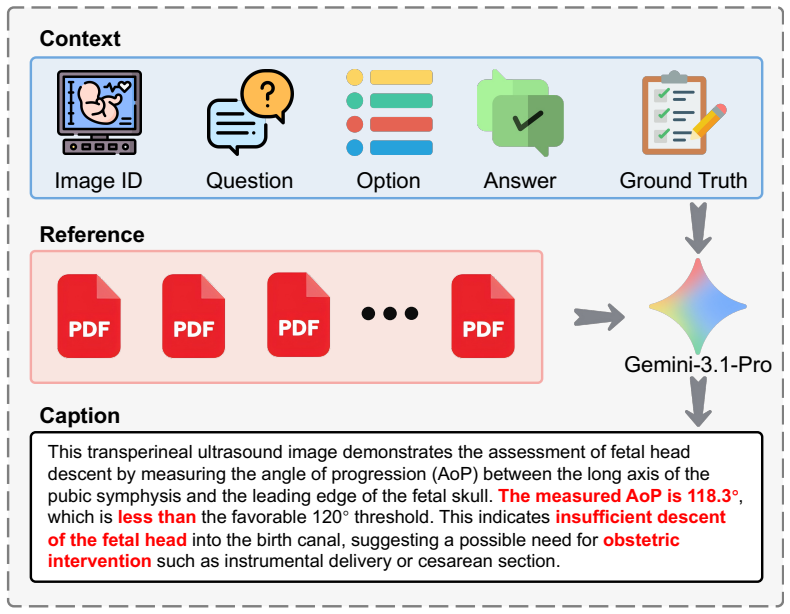
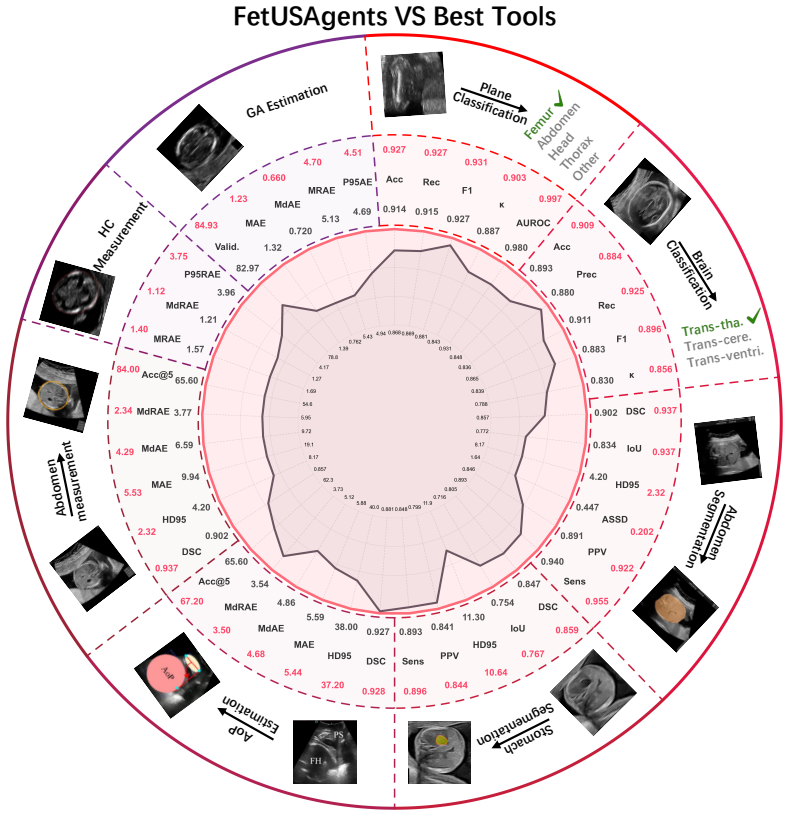
- The FetUS-VQA benchmark provides 1892 images and 3205 question-answer pairs across 10 clinical tasks for standardized evaluation.
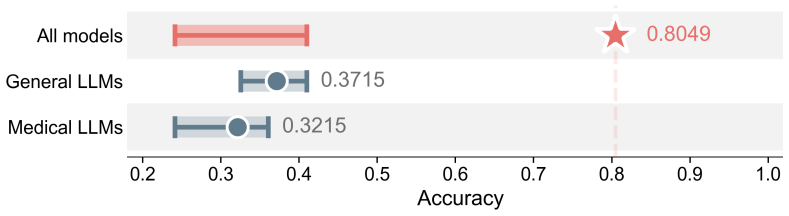
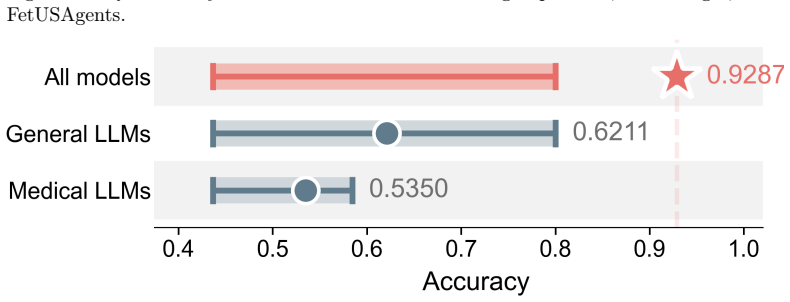
- Out-of-distribution experiments demonstrate more than 25 percent higher VQA accuracy than the strongest general or medical MLLM baseline.
- The architecture offers a route toward evidence-driven clinical assistants for prenatal imaging.
Where Pith is reading between the lines
- The same agent-coordination pattern could extend to other prenatal or obstetric imaging modalities that combine segmentation with measurement.
- The evidence bank structure may support audit requirements if the system is deployed in regulated clinical environments.
- Performance gains on VQA may translate to improved report consistency only if downstream clinical decisions are tracked in follow-up studies.
- Real-time video summarization capability opens the possibility of live assistance during ultrasound exams rather than post-scan review.
Load-bearing premise
The Dual-Path Evidence Arbitration and retrieval-enhanced evidence bank produce clinically grounded conclusions without introducing new hallucination risks from the LLM agents.
What would settle it
A side-by-side comparison of FetUSAgents reports against expert fetal-medicine specialist interpretations on an independent clinical dataset, measuring diagnostic agreement rates and specific error categories.
Figures
read the original abstract
Automated fetal ultrasound interpretation requires a workflow from visual perception, including plane recognition and anatomical segmentation, to clinical understanding, including biometric measurement and diagnostic reporting. However, the prevailing "one-task, one-model" paradigm limits systematic integration of evidence across this multi-step process. Although multimodal large language models (MLLMs) show promising visual understanding, their limited domain-specific grounding and hallucination risks restrict reliability in fetal ultrasound analysis. To address these limitations, we propose FetUSAgents, a tool-augmented multi-agent system for comprehensive fetal ultrasound interpretation, supporting visual question answering (VQA), report generation, image captioning, and video summarization. FetUSAgents coordinates task-specific visual tools through collaborative LLM agents and decomposes clinical queries into subtasks that progress from anatomical recognition to quantitative measurement. We further introduce Dual-Path Evidence Arbitration (DPEA), which integrates LLM-based deliberative reasoning with structured computational evidence from specialized visual tools. A retrieval-enhanced evidence bank consolidates intermediate findings to support traceable and clinically grounded conclusions. In addition, we construct FetUS-VQA, a dedicated VQA benchmark for fetal ultrasound, comprising 1,892 images and 3,205 question-answer pairs across 10 clinical tasks. Extensive out-of-distribution experiments show that FetUSAgents outperforms general and medical MLLMs, exceeding the strongest baseline by more than 25 percent in VQA accuracy. These results suggest a scalable route toward evidence-driven clinical assistants for prenatal imaging. Code is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
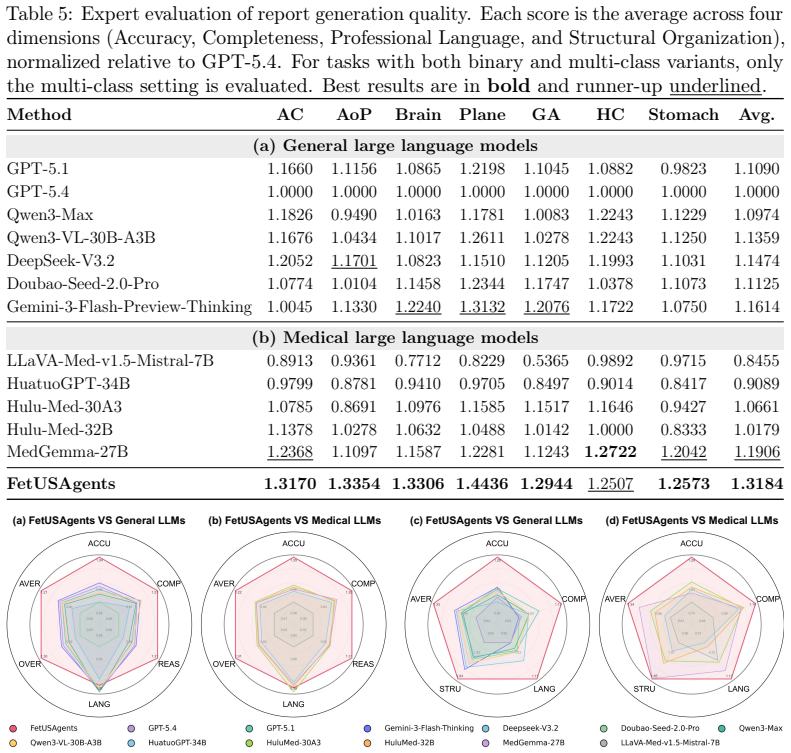
Summary. The paper introduces FetUSAgents, a tool-augmented multi-agent system for fetal ultrasound interpretation that coordinates task-specific visual tools (plane recognition, segmentation, biometry) via collaborative LLM agents, Dual-Path Evidence Arbitration (DPEA), and a retrieval-enhanced evidence bank. It constructs the FetUS-VQA benchmark (1,892 images, 3,205 QA pairs across 10 tasks) and claims that FetUSAgents outperforms general and medical MLLMs by more than 25% VQA accuracy on out-of-distribution experiments, with code released.
Significance. If the reported gains are shown to stem from the multi-agent architecture and DPEA rather than tool access alone, the approach could offer a scalable path to evidence-driven clinical assistants in prenatal imaging. The public release of code and the FetUS-VQA benchmark are clear strengths that support reproducibility and further research.
major comments (2)
- [Abstract] Abstract: The central claim that FetUSAgents exceeds the strongest baseline by more than 25% in VQA accuracy on OOD experiments does not specify whether the compared MLLM baselines were granted equivalent access to the same task-specific visual tools used by FetUSAgents. Without an ablation isolating the multi-agent layer (and DPEA) from tool augmentation, the performance delta cannot be attributed to the proposed architecture.
- [Abstract] Abstract: No details are supplied on baselines, statistical significance testing, error bars, dataset splits, or ablation studies supporting the >25% accuracy gain, preventing verification of the out-of-distribution performance claim from the provided text.
minor comments (1)
- [Abstract] The abstract states that FetUS-VQA covers '10 clinical tasks' but does not enumerate them; listing the tasks explicitly would improve clarity when describing the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and will revise the manuscript to improve clarity on experimental details and attribution of gains.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that FetUSAgents exceeds the strongest baseline by more than 25% in VQA accuracy on OOD experiments does not specify whether the compared MLLM baselines were granted equivalent access to the same task-specific visual tools used by FetUSAgents. Without an ablation isolating the multi-agent layer (and DPEA) from tool augmentation, the performance delta cannot be attributed to the proposed architecture.
Authors: We agree the abstract should explicitly distinguish the baselines. The compared MLLMs are standard general and medical models without access to the task-specific visual tools (plane recognition, segmentation, biometry) coordinated by the agents. The full manuscript contains ablation studies that isolate the multi-agent collaboration and DPEA from tool augmentation alone; we will revise the abstract to state this distinction and reference the relevant ablations. revision: yes
-
Referee: [Abstract] Abstract: No details are supplied on baselines, statistical significance testing, error bars, dataset splits, or ablation studies supporting the >25% accuracy gain, preventing verification of the out-of-distribution performance claim from the provided text.
Authors: The abstract is concise by design; the full manuscript specifies the MLLM baselines, describes the FetUS-VQA construction and splits, and presents ablation studies supporting the OOD gains. We will add a brief reference to the experimental protocol in the abstract. If statistical significance testing and error bars are not already reported in the results section, we will incorporate them in the revision. revision: partial
Circularity Check
No circularity: empirical performance claims rest on external baselines
full rationale
The paper advances no mathematical derivation, first-principles equations, or fitted parameters that could reduce to self-defined inputs. Its central claim is an empirical accuracy delta (>25% VQA on OOD data) obtained by direct comparison to independent external MLLM baselines. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the architecture; the system description and benchmark construction are presented as engineering contributions evaluated against outside references. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
invented entities (3)
-
FetUSAgents
no independent evidence
-
Dual-Path Evidence Arbitration (DPEA)
no independent evidence
-
FetUS-VQA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3-VL technical report. arXiv e-prints , arXiv:2511.21631doi:10. 48550/arXiv.2511.21631,arXiv:2511.21631. Bano, S., Vasconcelos, F., Amo-Aparicio, J., Teles Rodrigues, P., Curado, I., Dall’Asta, A., David, A.L., Deprest, J., Ourselin, S., Vercauteren, T., Melbourne, A., 2021. Autofb: Automating fetal biometry estimation from standard ultrasound planes,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tmi.2017 2021
-
[2]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-V3.2: Pushing the frontier of open large language mod- els. arXiv e-prints , arXiv:2512.02556doi:10.48550/arXiv.2512.02556, arXiv:2512.02556. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Li, F.F., 2009. ImageNet: A large-scale hierarchical image database, in: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. doi:1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556 2009
-
[3]
Optimal transport for machine learners.CoRR, abs/2505.06589, 2025
nnu-net: a self-configuring method for deep learning-based biomed- ical image segmentation. Nature Methods 18, 203–211. doi:10.1038/ s41592-020-01008-z. 30 Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C.e.a., 2025. Hulu-Med: A Transparent Generalist Model towards Holistic Medical Vision-Language Understanding. arXiv e-prints , arXiv:2510.08668doi: 10.4855...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[4]
Expert Systems with Applications238, 122153 (2024).https://doi.org/10.1016/j.eswa.2023.122153
doi:10.1016/j.eswa.2023.122153. LangChain, 2026. Openaiembeddings. LangChain Python API Reference. Accessed: 2026-05-20. Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J., 2023. LLaVA-med: Training a large language-and-vision assistant for biomedicine in one day, in: Thirty-seventh Conference on Neural Information...
-
[5]
Ultrasound in Obstetrics & Gynecology 37, 116–126
Practice guidelines for performance of the routine mid-trimester fetal ultrasound scan. Ultrasound in Obstetrics & Gynecology 37, 116–126. doi:10.1002/uog.8831. Sappia, M.S., de Korte, C.L., van Ginneken, B., Ninalga, D., Kondo, S., et al., 2025. Acouslic-ai challenge report: Fetal abdominal circumference measurement on blind-sweep ultrasound data from lo...
-
[6]
Medgemma technical report. arXiv e-prints , arXiv:2507.05201doi:10. 48550/arXiv.2507.05201,arXiv:2507.05201. Sendra-Balcells, C., Campello, V.M., Torrents-Barrena, J., et al., 2023. Generalisability of fetal ultrasound deep learning models to low-resource imaging settings in five african countries. Scientific Reports 13, 2728. doi:10.1038/s41598-023-29490...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41598-023-29490-3 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.