Can MLLMs Reason Beyond Language? VisReason: A Comprehensive Benchmark for Vision-Centric Reasoning
Pith reviewed 2026-06-29 22:42 UTC · model grok-4.3
The pith
VisReason benchmark shows current MLLMs fall short on reasoning that requires direct visual evidence over language shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
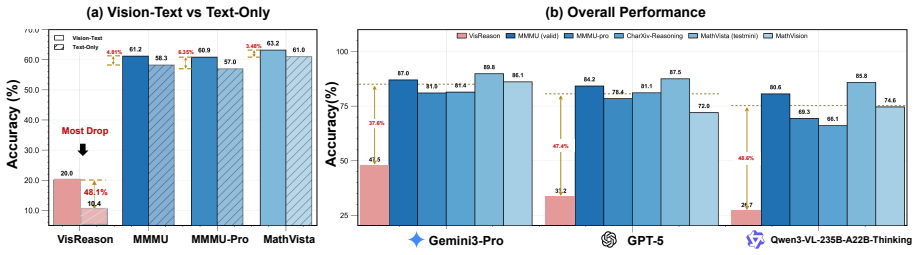
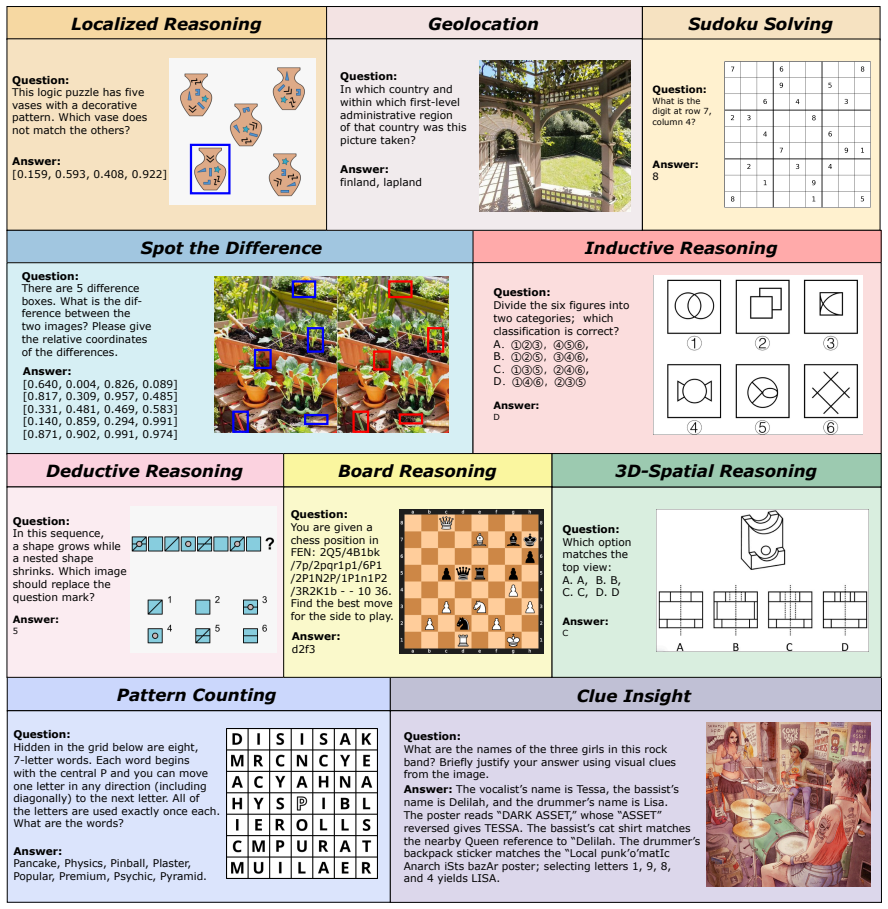
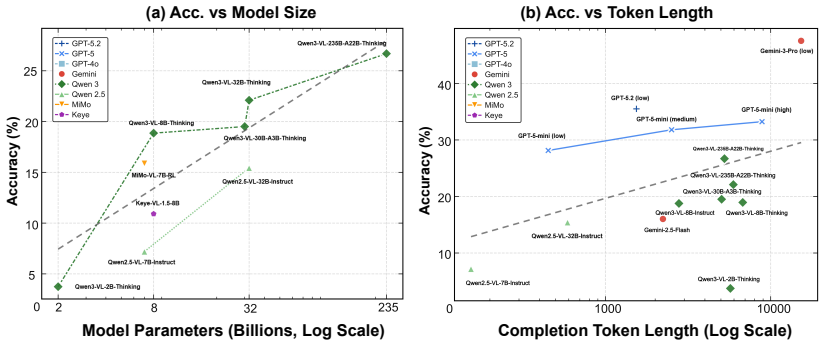
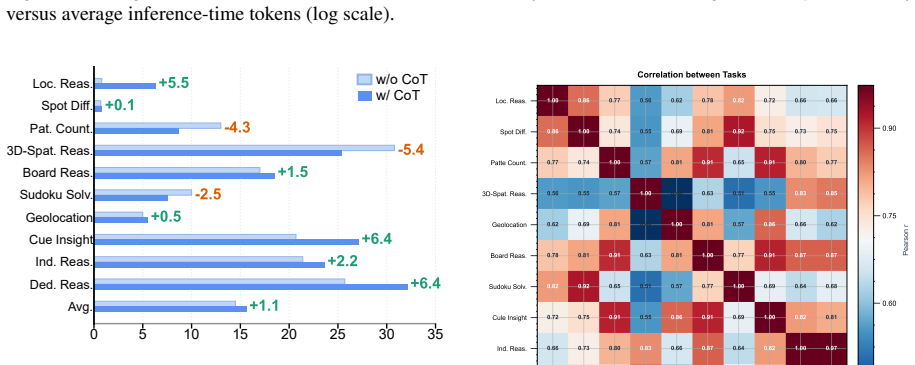
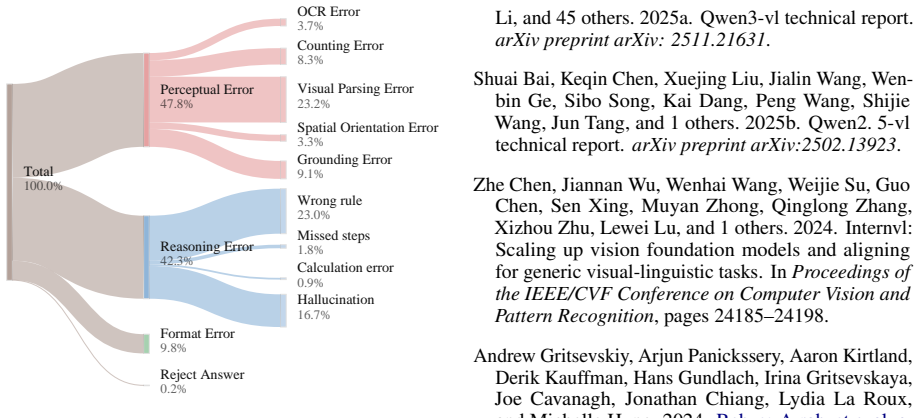
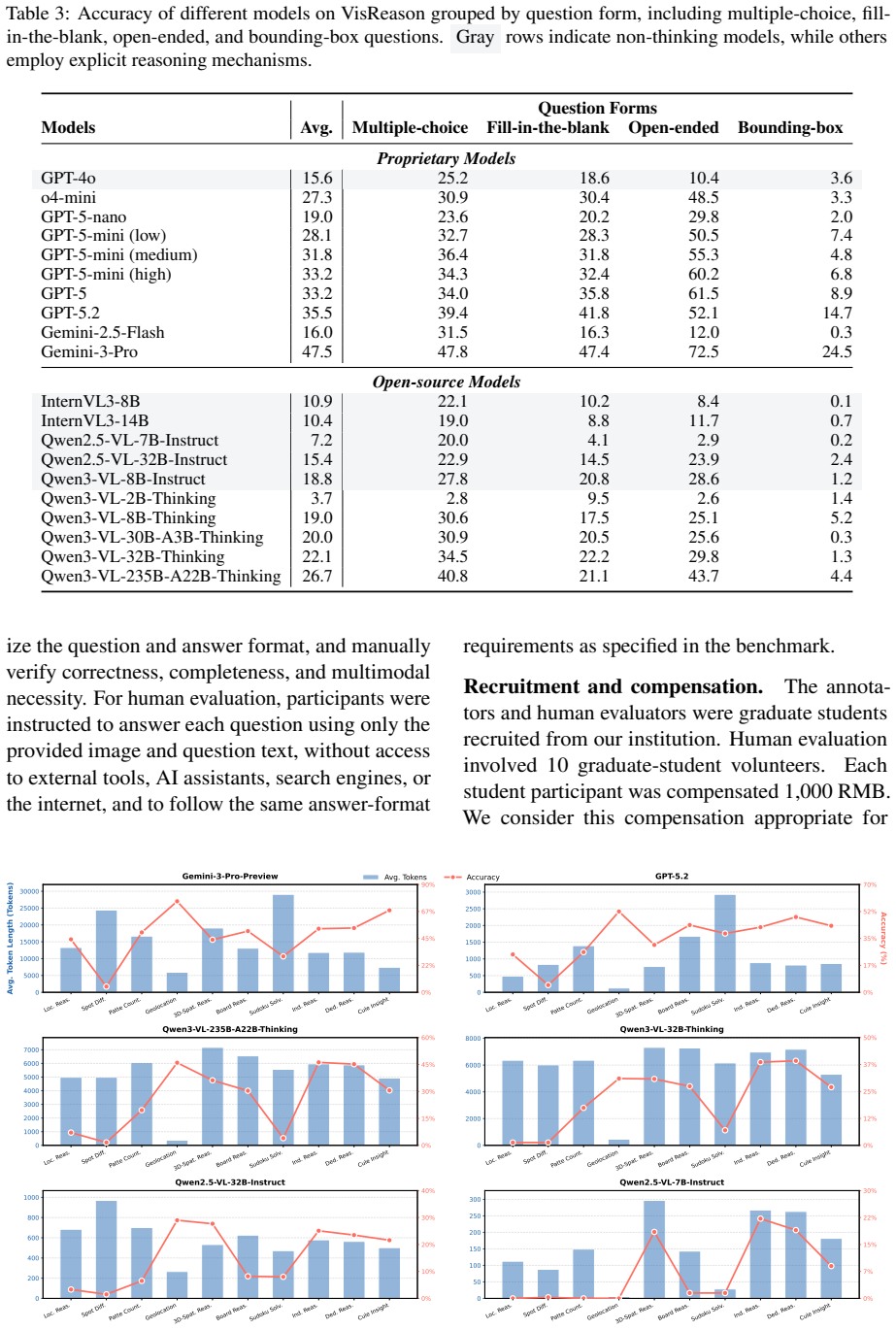
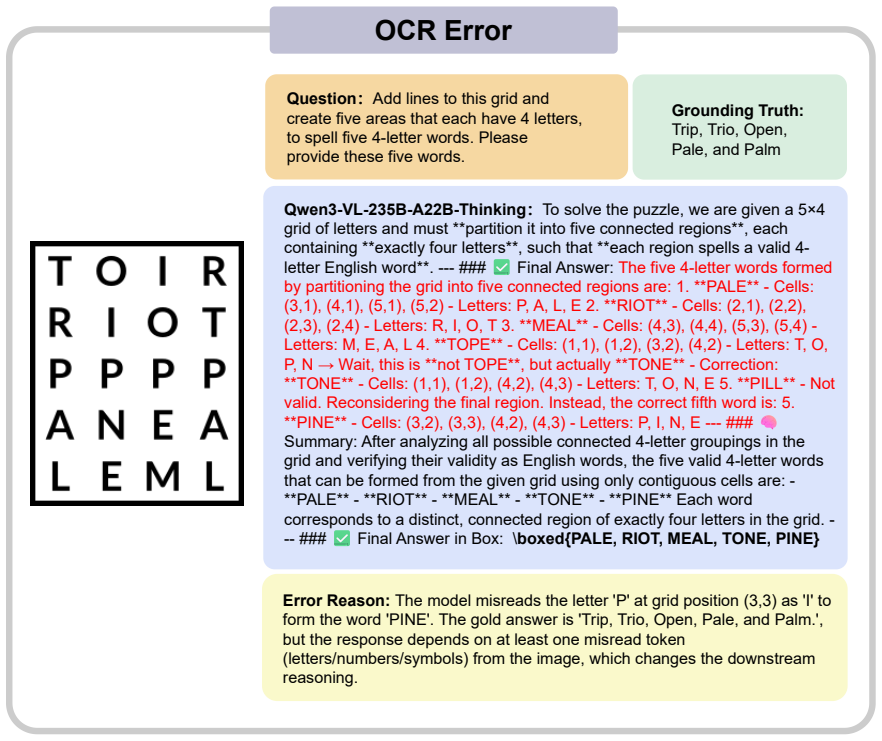
VisReason is a benchmark for vision-centric reasoning in which perception and inference are tightly coupled, containing 1,505 questions across 10 categories that span perceptual, structural, and conceptual levels. The evaluation demonstrates that this benchmark poses a qualitatively different challenge from prior suites, with current MLLMs exhibiting substantial gaps relative to human performance and showing only limited benefits from test-time reasoning strategies.
What carries the argument
The VisReason benchmark itself, whose 1,505 questions and 10 categories are constructed to require reasoning grounded in visual evidence rather than solvable through language shortcuts.
If this is right
- MLLMs do not yet perform vision-centric reasoning at human levels when language shortcuts are removed.
- Test-time reasoning strategies such as chain-of-thought yield only marginal improvements on these tasks.
- Existing visual-reasoning benchmarks likely overestimate model capabilities by permitting solutions based on textual priors.
- Progress on vision-centric reasoning will require training or evaluation methods that enforce tighter coupling between perception and inference.
Where Pith is reading between the lines
- Developers may need to redesign training objectives to reward direct use of visual features rather than language-model fallback.
- VisReason could serve as a recurring diagnostic to measure whether new architectures close the human-model gap on coupled perception-inference tasks.
- Similar benchmark designs might expose comparable gaps in other modalities such as video or spatial reasoning where language cues are also abundant.
Load-bearing premise
The questions succeed in forcing reasoning that depends on visual evidence and cannot be answered from language patterns or prior textual knowledge alone.
What would settle it
A controlled experiment in which an MLLM reaches human-level accuracy on the VisReason questions while test-time reasoning methods produce large score gains, yet the same model still solves the questions when visual input is removed or corrupted.
Figures











read the original abstract
Recent multimodal large language models (MLLMs) achieve strong performance on visual reasoning benchmarks, yet it remains unclear to what extent such performance reflects reasoning directly grounded in visual evidence. We introduce VisReason, a benchmark for vision-centric reasoning in everyday scenarios where perception and inference are tightly coupled. VisReason contains 1,505 questions across 10 categories spanning perceptual, structural, and conceptual reasoning. Our evaluation shows that VisReason poses a qualitatively different challenge from existing benchmarks, exposing substantial gaps between humans and current MLLMs and revealing limited benefits from test-time reasoning strategies. VisReason offers a focused diagnostic for evaluating vision-centric reasoning beyond language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VisReason, a benchmark containing 1,505 questions across 10 categories spanning perceptual, structural, and conceptual reasoning in everyday scenarios. It claims that current MLLMs exhibit substantial gaps relative to humans on this benchmark and show limited gains from test-time reasoning strategies, positioning VisReason as a diagnostic for vision-centric reasoning that existing benchmarks fail to capture.
Significance. If the benchmark construction succeeds in isolating reasoning that requires visual evidence rather than textual inference or priors, the work would supply a useful targeted evaluation set for diagnosing integration failures in MLLMs and for measuring progress beyond language-only shortcuts.
major comments (2)
- [Abstract / Benchmark Design] Abstract and benchmark construction: the assertion that VisReason poses a 'qualitatively different challenge' and that performance gaps reflect vision-centric reasoning deficits rests on the unverified premise that the 1,505 questions cannot be solved from text alone. No text-only LLM baselines, human text-only accuracy, or explicit controls for prior-knowledge leakage are reported, directly undermining the central claim.
- [Evaluation] Evaluation section: the abstract states that evaluation reveals gaps and limited test-time gains, yet the provided text supplies no methods, data splits, statistical details, full result tables, or per-category breakdowns. Without these, the reported human-MLLM gaps and strategy comparisons cannot be assessed for soundness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of benchmark validation and evaluation transparency. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Benchmark Design] Abstract and benchmark construction: the assertion that VisReason poses a 'qualitatively different challenge' and that performance gaps reflect vision-centric reasoning deficits rests on the unverified premise that the 1,505 questions cannot be solved from text alone. No text-only LLM baselines, human text-only accuracy, or explicit controls for prior-knowledge leakage are reported, directly undermining the central claim.
Authors: We agree that explicit verification is necessary to support the claim that VisReason isolates vision-centric reasoning. In the revised manuscript, we will add text-only LLM baselines using multiple models on question text alone, report human accuracy on text-only versions of the questions, and include analysis for prior-knowledge leakage. These additions will directly test whether the questions can be solved without visual input. revision: yes
-
Referee: [Evaluation] Evaluation section: the abstract states that evaluation reveals gaps and limited test-time gains, yet the provided text supplies no methods, data splits, statistical details, full result tables, or per-category breakdowns. Without these, the reported human-MLLM gaps and strategy comparisons cannot be assessed for soundness.
Authors: We acknowledge that the submitted version lacked sufficient detail in the evaluation section. The revised manuscript will expand this section to include full methodological descriptions, data split information, statistical details (including confidence intervals and significance tests), complete result tables, and per-category performance breakdowns for both MLLMs and humans, enabling readers to fully assess the reported gaps and strategy comparisons. revision: yes
Circularity Check
No circularity: benchmark dataset construction with no derivations or self-referential reductions
full rationale
This is a benchmark introduction paper whose central contribution is the creation and initial evaluation of the VisReason question set (1,505 questions, 10 categories). No equations, parameter fitting, or derivation chain exists in the provided text. The claim that the benchmark poses a 'qualitatively different challenge' rests on the authors' design choices for question content rather than any reduction to prior fitted values or self-citations. The skeptic concern about missing text-only baselines is a validity issue, not a circularity issue. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 10 categories and 1,505 questions isolate reasoning grounded in visual evidence from language-based shortcuts.
Reference graph
Works this paper leans on
-
[1]
Kwai keye-vl 1.5 technical report,
Kwai keye-vl 1.5 technical report.Preprint, arXiv:2509.01563. Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, and 3 others. 2024. Mmmu: A massive multi-discipline multimo...
-
[2]
zig-zag\
**Solid black circle** 4. **Empty square** 5. **Two small dots side by side** 6. **Octagon (white)** These faces are arranged in the following pattern: This is a \"zig-zag\" type of net. When folded into a cube, the adjacency relationships can be deduced as follows: - **Frame** is adjacent to **Stripes** - **Stripes** is adjacent to **Frame**, **Black** -...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.