FOUND-IT: Foundation-model-first Task-driven 3D Scene Graphs with Granularity on Demand
Pith reviewed 2026-06-29 22:01 UTC · model grok-4.3
The pith
Robots build hierarchical 3D scene graphs from monocular video by extending foundation models with an extra head for traversability and varying detail level as tasks evolve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FOUND-IT is the first approach to build hierarchical task-driven 3D scene graphs of arbitrary indoor or outdoor environments using an uncalibrated monocular camera in real-time by leveraging geometric foundation models to estimate geometric attributes while reconstructing traversability information for the places layer through an extra head added to models such as VGGT, with object and region granularity adjusted depending on the task as the list of tasks evolves during robot operation.
What carries the argument
An extra head attached to geometric foundation models such as VGGT that reconstructs the places layer for traversability, paired with a mechanism that adjusts the granularity of scene-graph elements according to the current and evolving task requirements.
If this is right
- The method runs in real time on a ground robot equipped with a Jetson Thor.
- It records 79 percent higher accuracy on the ASHiTA SG3D task grounding benchmark than prior approaches.
- It produces usable scene graphs from casually captured videos such as YouTube realtor apartment tours.
- It supports dynamic adjustment of the map representation during complex loco-manipulation tasks whose requirements change while the robot is operating.
Where Pith is reading between the lines
- The same extra-head technique might be tested on other scene-graph layers or on different camera or lidar inputs without retraining the base model.
- Sharing the resulting graphs across multiple robots could support coordinated mapping when task lists are allowed to evolve independently on each platform.
- The approach implies that foundation models already contain enough implicit structure to support places prediction, which could reduce the volume of labeled traversability data needed for new environments.
Load-bearing premise
Traversability information for the places layer can be directly obtained by adding an extra head to existing geometric foundation models without task-specific fine-tuning data or additional geometric constraints.
What would settle it
A direct test showing that the extra head on a model such as VGGT yields unusable or inconsistent places-layer data on new indoor and outdoor sequences when no fine-tuning or extra constraints are supplied would falsify the central claim.
Figures





read the original abstract
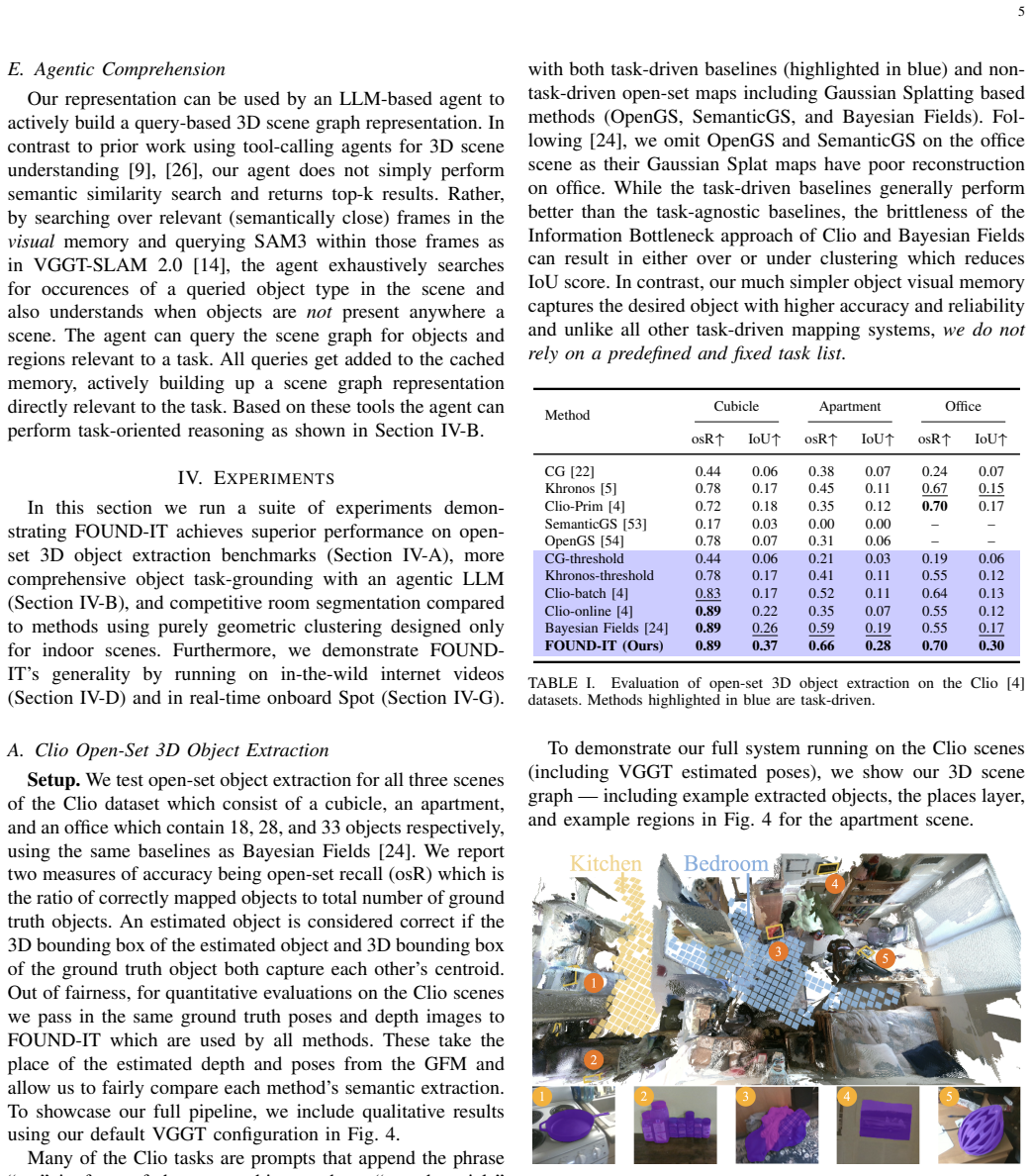
We present the first approach to build hierarchical task-driven 3D scene graphs of arbitrary indoor or outdoor environments using an uncalibrated monocular camera in real-time. We leverage geometric foundation models to estimate geometric attributes of the scene graph (e.g., object bounding boxes), but we also observe that traversability information (the "places" layer of a scene graph) can be directly reconstructed by adding an extra head to existing geometric foundation models, like VGGT. Our approach is task-driven in the sense that we adjust the granularity of the objects and regions in the map depending on the task; for instance, during a manipulation task, our approach is able to resolve small knobs on a stove, while during a navigation task it can focus on large objects (e.g., the entire stove). However, in a major departure from related work, we consider the realistic case where the list of tasks is not predefined and fixed, but evolves as the robot operates. This naturally allows dealing with complex loco-manipulation tasks, where the robot can dynamically adjust its representation as the task unfolds. We dub the resulting approach FOUND-IT. FOUND-IT also includes an agentic approach to query information in the scene graph. In addition to achieving 79% higher accuracy on the ASHiTA SG3D task grounding benchmark, we demonstrate FOUND-IT runs in real-time on a ground robot using a Jetson Thor. Furthermore, to highlight the robustness of our method, we demonstrate constructing 3D scene graphs on casually captured realtor apartment tours from YouTube. Code will be made available upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FOUND-IT, presented as the first method to construct hierarchical task-driven 3D scene graphs for arbitrary indoor/outdoor environments from uncalibrated monocular video in real time. It leverages geometric foundation models (e.g., VGGT) for object attributes, adds an extra head to reconstruct traversability in the 'places' layer, dynamically adjusts granularity for evolving tasks (including complex loco-manipulation), incorporates an agentic query mechanism, reports 79% higher accuracy on the ASHiTA SG3D benchmark, demonstrates real-time operation on a Jetson Thor, and shows results on YouTube apartment tours, with code to be released.
Significance. If the central claims hold after validation, this would be a meaningful contribution to robotic scene understanding by enabling adaptive, task-driven representations without predefined task lists and supporting real-time deployment on embedded hardware. Explicit credit is due for the stated plan to release code, which would support reproducibility.
major comments (2)
- [Abstract] Abstract: The reported 79% accuracy gain on the ASHiTA SG3D task grounding benchmark supplies no baseline details, error bars, dataset splits, or ablation results, so the central performance claim cannot be evaluated.
- [Abstract] Abstract / methods description: The claim that traversability information for the places layer can be directly reconstructed by adding an extra head to VGGT without task-specific fine-tuning data or additional geometric constraints is load-bearing for populating the scene graph and enabling downstream granularity adjustments, yet no supporting experiments, validation, or failure cases are described.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will make revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 79% accuracy gain on the ASHiTA SG3D task grounding benchmark supplies no baseline details, error bars, dataset splits, or ablation results, so the central performance claim cannot be evaluated.
Authors: The abstract is space-constrained and therefore summarizes the result without full experimental details. The complete evaluation—including the specific baseline, error bars, dataset splits, and ablations—is reported in Section 5 (Experiments) with tables and figures. To address the concern, we will revise the abstract to name the baseline method and explicitly direct readers to the experimental section for the supporting statistics. revision: yes
-
Referee: [Abstract] Abstract / methods description: The claim that traversability information for the places layer can be directly reconstructed by adding an extra head to VGGT without task-specific fine-tuning data or additional geometric constraints is load-bearing for populating the scene graph and enabling downstream granularity adjustments, yet no supporting experiments, validation, or failure cases are described.
Authors: The abstract condenses the architectural observation; the methods section details the extra head and training procedure, while the experiments section includes both quantitative metrics on traversability prediction and qualitative examples on real sequences. We agree that dedicated validation and explicit discussion of failure modes would strengthen the presentation. We will add a short subsection (or expanded paragraph) in the methods/experiments that reports the validation protocol, quantitative results, and observed failure cases for the traversability head. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes FOUND-IT as an engineering composition that leverages pre-existing geometric foundation models such as VGGT and adds one extra head for traversability information. No equations, fitted parameters, or derivations are presented that reduce any claimed output (scene-graph accuracy, real-time performance, or task-driven granularity) to quantities defined inside the paper itself. No self-citations are invoked to establish uniqueness theorems or to smuggle in ansatzes, and the central construction is not self-definitional. The approach is therefore self-contained against external benchmarks and foundation-model outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Geometric foundation models such as VGGT already contain enough latent information that a single added head can produce traversability maps usable for scene-graph construction.
Forward citations
Cited by 1 Pith paper
-
3D Scene Graphs: Open Challenges and Future Directions
A survey that formalizes 3D Scene Graphs under a common definition, analyzes modeling choices, reviews construction from sensory data, examines applications and evaluations, and highlights open challenges with a suppo...
Reference graph
Works this paper leans on
-
[1]
3D scene graph: A structure for unified semantics, 3D space, and camera,
I. Armeni, Z. He, J. Gwak, A. Zamir, M. Fischer, J. Malik, and S. Savarese, “3D scene graph: A structure for unified semantics, 3D space, and camera,” inIntl. Conf. on Computer Vision (ICCV), 2019, pp. 5664–5673
2019
-
[2]
SceneGraphFu- sion: Incremental 3D scene graph prediction from RGB-D sequences,
S. Wu, J. Wald, K. Tateno, N. Navab, and F. Tombari, “SceneGraphFu- sion: Incremental 3D scene graph prediction from RGB-D sequences,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 7515–7525
2021
-
[3]
Foundations of spatial perception for robotics: Hierarchical representations and real-time systems,
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone, “Foundations of spatial perception for robotics: Hierarchical representations and real-time systems,”Intl. J. of Robotics Research, 2024
2024
-
[4]
Clio: Real-time task-driven open-set 3D scene graphs,
D. Maggioet al., “Clio: Real-time task-driven open-set 3D scene graphs,”IEEE Robotics and Automation Letters (RA-L), vol. 9, no. 10, pp. 8921–8928, 2024
2024
-
[5]
Khronos: A unified approach for spatio-temporal metric-semantic SLAM in dynamic envi- ronments,
L. Schmid, M. Abate, Y . Chang, and L. Carlone, “Khronos: A unified approach for spatio-temporal metric-semantic SLAM in dynamic envi- ronments,” inRobotics: Science and Systems (RSS), 2024
2024
-
[6]
Hier- archical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. Büchner, A. Valada, and W. Burgard, “Hier- archical open-vocabulary 3d scene graphs for language-grounded robot navigation,”Robotics: Science and Systems (RSS), 2024
2024
-
[7]
Task and motion planning in hierarchical 3D scene graphs,
A. Ray, C. Bradley, L. Carlone, and N. Roy, “Task and motion planning in hierarchical 3D scene graphs,” inProc. of the Intl. Symp. of Robotics Research (ISRR), 2024
2024
-
[8]
Indoor and outdoor 3D scene graph generation via language-enabled spatial ontologies,
J. Strader, N. Hughes, W. Chen, A. Speranzon, and L. Carlone, “Indoor and outdoor 3D scene graph generation via language-enabled spatial ontologies,”IEEE Robotics and Automation Letters (RA-L), vol. 9, no. 6, pp. 4886–4893, 2024
2024
-
[9]
Describe anything anywhere at any moment,
N. Gorlo, L. Schmid, and L. Carlone, “Describe anything anywhere at any moment,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[10]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[11]
Grounding image matching in 3d with MASt3R,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3d with MASt3R,” inEuropean Conf. on Computer Vision (ECCV), vol. 15130, 2024, pp. 71–91
2024
-
[12]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 20 697–20 709
2024
-
[13]
TTT3R: 3D Reconstruction as Test-Time Training
X. Chen, Y . Chen, Y . Xiu, A. Geiger, and A. Chen, “Ttt3r: 3d reconstruction as test-time training,”arXiv preprint arXiv:2509.26645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
VGGT-SLAM 2.0: Real-time dense feed- forward scene reconstruction,
D. Maggio and L. Carlone, “VGGT-SLAM 2.0: Real-time dense feed- forward scene reconstruction,” 2026
2026
-
[15]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Z. Fanet al., “Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction,”arXiv preprint arXiv:2505.20279, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
D. Wu, F. Liu, Y .-H. Hung, and Y . Duan, “Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence,”arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Unified Semantic Transformer for 3D Scene Understanding
S. Koch, J. Wald, H. Matsuki, P. Hermosilla, T. Ropinski, and F. Tombari, “Unified semantic transformer for 3d scene understanding,” arXiv preprint arXiv:2512.14364, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Learning transferable visual models from natural language supervision,
A. Radfordet al., “Learning transferable visual models from natural language supervision,” inIntl. Conf. on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 18–24 Jul 2021, pp. 8748–8763
2021
-
[19]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inIntl. Conf. on Computer Vision (ICCV), 2023, pp. 11 975–11 986
2023
-
[20]
Conceptfusion: Open-set multimodal 3d map- ping,
K. Jatavallabhulaet al., “Conceptfusion: Open-set multimodal 3d map- ping,” inRobotics: Science and Systems (RSS), 2023
2023
-
[21]
OpenMask3D: Open-V ocabulary 3D Instance Segmenta- tion,
A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann, “OpenMask3D: Open-V ocabulary 3D Instance Segmenta- tion,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[22]
Conceptgraphs: Open-vocabulary 3d scene graphs for per- ception and planning,
Q. Guet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for per- ception and planning,” inIEEE Intl. Conf. on Robotics and Automation (ICRA), May 2024
2024
-
[23]
The bare necessities: Designing simple, effective open- vocabulary scene graphs,
C. Kassab, M. Mattamala, S. Morin, M. Büchner, A. Valada, L. Paull, and M. Fallon, “The bare necessities: Designing simple, effective open- vocabulary scene graphs,”arXiv preprint arXiv:2412.01539, 2024
-
[24]
Bayesian Fields: Task-driven open-set semantic gaussian splatting,
D. Maggio and L. Carlone, “Bayesian Fields: Task-driven open-set semantic gaussian splatting,”arXiv preprint, 2025
2025
-
[25]
ASHiTA: Automatic scene-grounded hierarchical task analysis,
Y . Chang, L. Fermoselle, D. Ta, B. Bucher, L. Carlone, and J. Wang, “ASHiTA: Automatic scene-grounded hierarchical task analysis,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[26]
ReMEmbR: Building and reasoning over long-horizon spatio-temporal memory for robot navigation,
A. Anwar, J. Welsh, J. Biswas, S. Pouya, and Y . Chang, “ReMEmbR: Building and reasoning over long-horizon spatio-temporal memory for robot navigation,” inIEEE Intl. Conf. on Robotics and Automation (ICRA), 2025
2025
-
[27]
Task-oriented sequential grounding in 3D scenes,
Z. Zhanget al., “Task-oriented sequential grounding in 3D scenes,”
-
[28]
Available: https://arxiv.org/abs/2408.04034
[Online]. Available: https://arxiv.org/abs/2408.04034
-
[29]
Kimera: from SLAM to spatial perception with 3D dynamic scene graphs,
A. Rosinolet al., “Kimera: from SLAM to spatial perception with 3D dynamic scene graphs,”Intl. J. of Robotics Research, vol. 40, no. 12–14, pp. 1510–1546, 2021
2021
-
[30]
Se- manticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks,
J. McCormac, A. Handa, A. J. Davison, and S. Leutenegger, “Se- manticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks,” inIEEE Intl. Conf. on Robotics and Automation (ICRA), 2017
2017
-
[31]
Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,
G. Narita, T. Seno, T. Ishikawa, and Y . Kaji, “Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,” in IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2019
2019
-
[32]
V olumetric Instance-Aware Semantic Mapping and 3D Object Discovery,
M. Grinvald, F. Furrer, T. Novkovic, J. J. Chung, C. Cadena, R. Siegwart, and J. Nieto, “V olumetric Instance-Aware Semantic Mapping and 3D Object Discovery,”IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 3037–3044, 2019
2019
-
[33]
Open3DSG: Open-vocabulary 3D scene graphs from point clouds with queryable objects and open-set relationships,
S. Koch, N. Vaskevicius, M. Colosi, P. Hermosilla, and T. Ropinski, “Open3DSG: Open-vocabulary 3D scene graphs from point clouds with queryable objects and open-set relationships,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[34]
Language-extended indoor slam (lexis): A versatile system for real-time visual scene understanding,
C. Kassab, M. Mattamala, L. Zhang, and M. Fallon, “Language-extended indoor slam (lexis): A versatile system for real-time visual scene understanding,”IEEE Intl. Conf. on Robotics and Automation (ICRA), 2024
2024
-
[35]
Taskography: Evaluating robot task planning over large 3D scene graphs,
C. Agiaet al., “Taskography: Evaluating robot task planning over large 3D scene graphs,” inConference on Robot Learning (CoRL), 2022, pp. 46–58
2022
-
[36]
Continuous 3D perception model with persistent state,
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa, “Continuous 3D perception model with persistent state,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[37]
π 3: Scalable permutation-equivariant visual geometry learning,
Y . Wanget al., “π 3: Scalable permutation-equivariant visual geometry learning,” inIntl. Conf. on Learning Representations (ICLR), 2026
2026
-
[38]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keethaet al., “Mapanything: Universal feed-forward metric 3d reconstruction,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Mast3r-slam: Real-time dense slam with 3d reconstruction priors,
R. Murai, E. Dexheimer, and A. J. Davison, “Mast3r-slam: Real-time dense slam with 3d reconstruction priors,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 16 695–16 705
2025
-
[40]
K. Deng, Z. Ti, J. Xu, J. Yang, and J. Xie, “Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences,” arXiv preprint arXiv:2507.16443, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
VGGT-SLAM: Dense RGB SLAM optimized on the SL(4) manifold,
D. Maggio, H. Lim, and L. Carlone, “VGGT-SLAM: Dense RGB SLAM optimized on the SL(4) manifold,” inConf. on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[42]
SayPlan: Grounding large language models using 3d scene graphs for scalable task planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suen- derhauf, “SayPlan: Grounding large language models using 3d scene graphs for scalable task planning,” inConference on Robot Learning (CoRL), 2023, pp. 23–72
2023
-
[43]
Q. Xieet al., “Embodied-RAG: General non-parametric embodied memory for retrieval and generation,” 2024. [Online]. Available: https://arxiv.org/abs/2409.18313
-
[44]
Grapheqa: Using 3d semantic scene graphs for real- time embodied question answering,
S. Saxenaet al., “Grapheqa: Using 3d semantic scene graphs for real- time embodied question answering,” inConference on Robot Learning (CoRL), 2025
2025
-
[45]
Language-grounded dynamic scene graphs for interactive object search with mobile manipulation,
D. Honerkamp, M. Büchner, F. Despinoy, T. Welschehold, and A. Val- ada, “Language-grounded dynamic scene graphs for interactive object search with mobile manipulation,”IEEE Robotics and Automation Letters, 2024
2024
-
[46]
SG-nav: Online 3d scene graph prompting for LLM-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “SG-nav: Online 3d scene graph prompting for LLM-based zero-shot object navigation,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id= HmCmxbCpp2
2024
-
[47]
Depth anything 3: Recovering the visual space from any views,
H. Linet al., “Depth anything 3: Recovering the visual space from any views,” inIntl. Conf. on Learning Representations (ICLR), 2026. 9
2026
-
[48]
Perception encoder: The best visual embeddings are not at the output of the network,
D. Bolyaet al., “Perception encoder: The best visual embeddings are not at the output of the network,” inAdvances in Neural Information Processing Systems 38 (NeurIPS), 2025
2025
-
[49]
SAM 3: Segment Anything with Concepts
N. Carionet al., “Sam 3: Segment anything with concepts,” 2025. [Online]. Available: https://arxiv.org/abs/2511.16719
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Hydra: a real-time spatial perception engine for 3D scene graph construction and optimization,
N. Hughes, Y . Chang, and L. Carlone, “Hydra: a real-time spatial perception engine for 3D scene graph construction and optimization,” inRobotics: Science and Systems (RSS), 2022
2022
-
[51]
Clus- tering on the unit hypersphere using von mises-fisher distributions
A. Banerjee, I. S. Dhillon, J. Ghosh, S. Sra, and G. Ridgeway, “Clus- tering on the unit hypersphere using von mises-fisher distributions.”J. of Machine Learning Research, vol. 6, no. 9, 2005
2005
-
[52]
Learning with local and global consistency,
D. Zhou, O. Bousquet, T. Lal, J. Weston, and B. Schölkopf, “Learning with local and global consistency,” vol. 16, 2003
2003
-
[53]
When and why vision-language models behave like bags-of-words, and what to do about it?
M. Yuksekgonul, F. Bianchi, P. Kalluri, D. Jurafsky, and J. Zou, “When and why vision-language models behave like bags-of-words, and what to do about it?” inIntl. Conf. on Learning Representations (ICLR), 2023
2023
-
[54]
Semantic gaussians: Open- vocabulary scene understanding with 3d gaussian splatting,
J. Guo, X. Ma, Y . Fan, H. Liu, and Q. Li, “Semantic gaussians: Open- vocabulary scene understanding with 3d gaussian splatting,” 2024
2024
-
[55]
Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,
Y . Wuet al., “Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,”Advances in Neural Information Pro- cessing Systems (NeurIPS), 2024
2024
-
[56]
Room segmentation: Survey, implementation, and analysis,
R. Bormann, F. Jordan, W. Li, J. Hampp, and M. H agele, “Room segmentation: Survey, implementation, and analysis,” in2016 IEEE International Conference on Robotics and Automation (ICRA), 2016, pp. 1019–1026
2016
-
[57]
Fast unfolding of communities in large networks,
V . D. Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,”Journal of statistical mechanics: theory and experiment, vol. 2008, no. 10, p. P10008, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.