Physics-Aware 3D Gaussian Editing for Driving Scene Generation
Pith reviewed 2026-06-29 22:39 UTC · model grok-4.3
The pith
RoVES inserts road irregularities into 3D Gaussian driving scenes from one image and corrects vehicle poses with a half-car dynamics model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
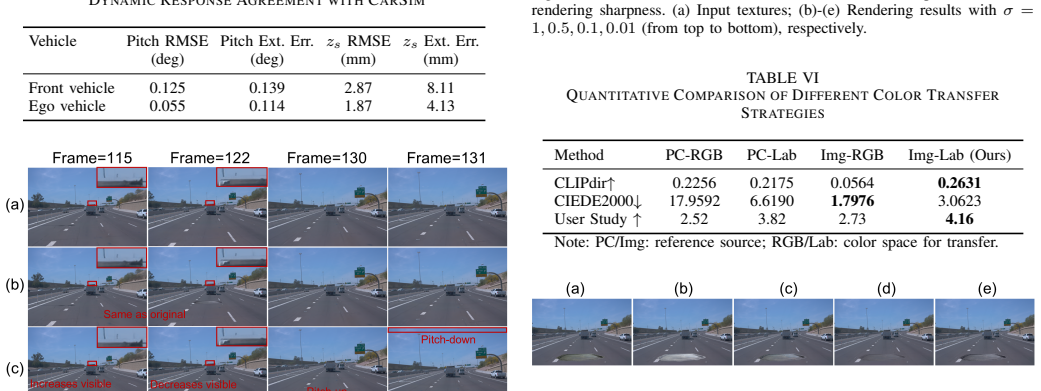
RoVES enables single-image-driven road geometry insertion in 3D Gaussian Splatting scenes and couples the edited road profile with a 4-DOF half-car vehicle dynamics model to achieve physics-aware vehicle pose correction in vertical displacement and pitch, completing core edits in 1.84 seconds and the full pipeline in 6.24 seconds on Waymo dataset scenes.
What carries the argument
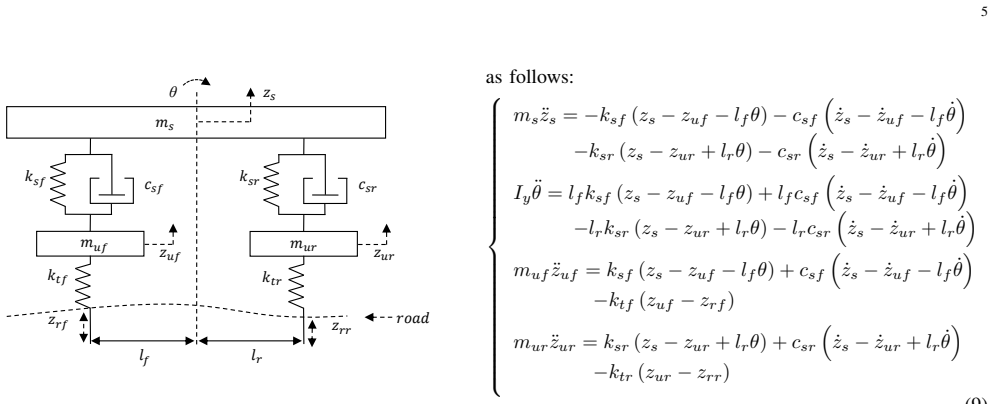
The 4-DOF half-car vehicle dynamics model that takes the edited road profile as input and produces frame-by-frame corrections to vehicle vertical displacement and pitch.
If this is right
- Enables rapid creation of synthetic training data for autonomous driving under road irregularities.
- Supports frame-by-frame pose correction for dynamic vehicles across edited sequences.
- Delivers practical runtimes without per-edit optimization loops.
- Maintains competitive visual consistency with existing 3D Gaussian scene editing methods.
Where Pith is reading between the lines
- Extending the dynamics model to include lateral or yaw degrees of freedom could handle turning maneuvers on irregular roads.
- Applying the same road-editing step to multi-view or LiDAR inputs might improve consistency across sensor types.
- Running the edited scenes through actual perception or control modules could quantify gains in robustness testing.
Load-bearing premise
The 4-DOF half-car model produces vertical displacement and pitch responses accurate enough to make edited vehicle poses look physically plausible.
What would settle it
Direct comparison of RoVES-corrected vehicle trajectories against real-vehicle sensor data recorded while driving over matching road features such as speed humps or sunken sections.
Figures
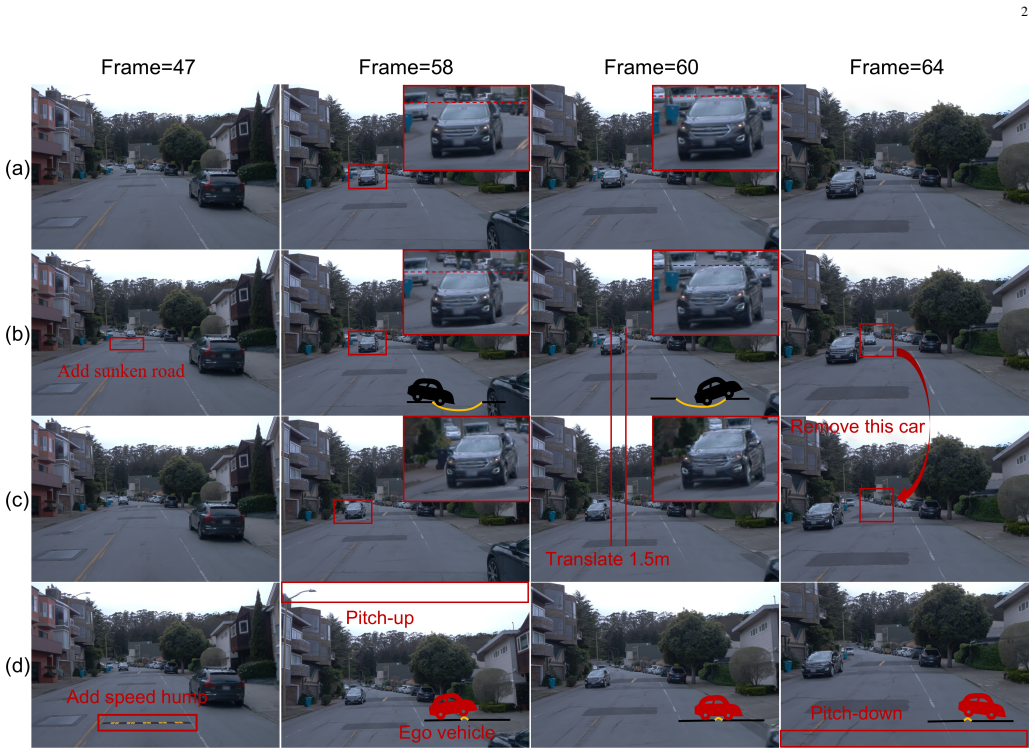
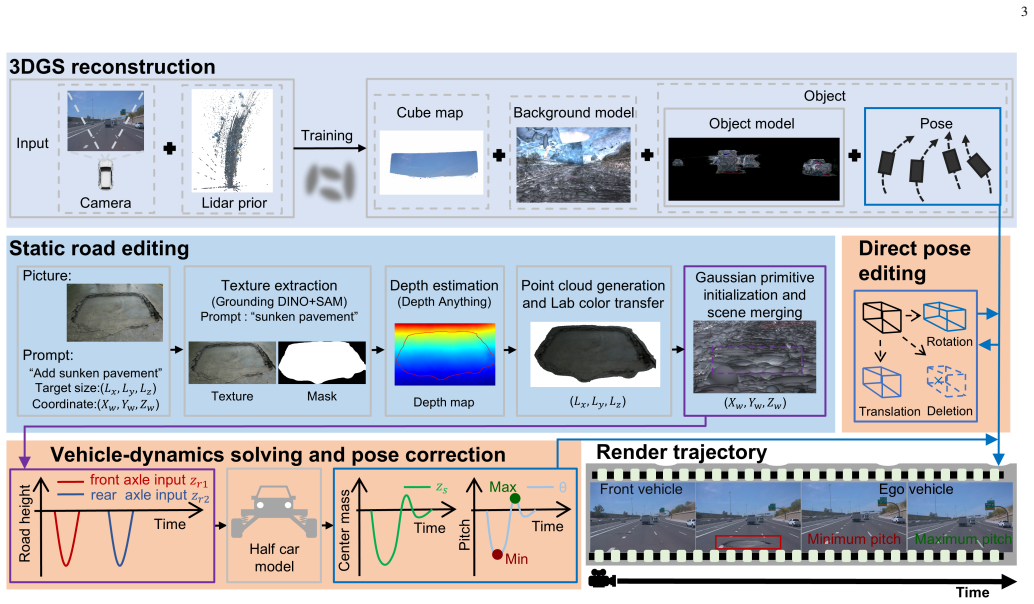

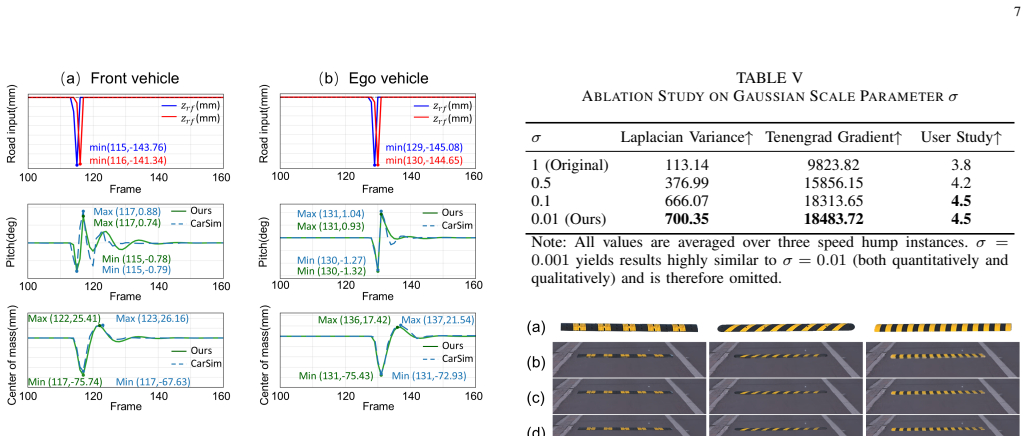
read the original abstract
3D Gaussian Splatting (3DGS) has shown great potential in autonomous driving simulation and data generation, enabling photorealistic reconstruction and flexible scene manipulation. However, existing 3DGS scene editing methods have limited support for road geometry editing (e.g., inserting speed humps or sunken roads), and generally do not couple such edits with plausible vehicle-road interaction dynamics. Such editing is essential for generating training data under extreme driving scenarios or evaluating system reliability under these road irregularities. Moreover, many optimization-based methods require minutes of per-edit refinement, while existing efficient alternatives mainly focus on appearance-level or object-level manipulation rather than physics-aware road irregularity editing. To address these limitations, we propose RoVES, a Road-and-Vehicle Editing System for physics-aware 3D Gaussian editing in driving scenes. RoVES enables single-image-driven road geometry insertion and couples the edited road profile with a 4-DOF half-car vehicle dynamics model to achieve physics-aware vehicle pose correction in vertical displacement and pitch. RoVES inserts road elements in a one-shot, optimization-free pipeline (1.84s), and the full pipeline (including color transfer and vehicle-dynamics-based pose correction) completes in 6.24s; it edits dynamic vehicles via pose editing and corrects poses frame-by-frame to approximate dynamics-consistent vertical displacement and pitch responses. Experiments on the Waymo dataset show that RoVES provides practical efficiency and competitive visual consistency for physics-aware driving scene generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoVES, a Road-and-Vehicle Editing System for physics-aware 3D Gaussian Splatting (3DGS) editing in driving scenes. It enables single-image-driven road geometry insertion (e.g., speed humps or sunken roads) and couples the edited road profile with a 4-DOF half-car vehicle dynamics model to correct vehicle poses for vertical displacement and pitch. The pipeline is optimization-free, completing core edits in 1.84s and the full pipeline (including color transfer and dynamics-based pose correction) in 6.24s. Experiments on the Waymo dataset are reported to demonstrate practical efficiency and competitive visual consistency for generating physics-aware driving scenes.
Significance. If the central claims hold, the work addresses a relevant gap in 3DGS-based driving scene editing by incorporating road-vehicle interaction dynamics, which is useful for generating training data under extreme road conditions. The reported one-shot, optimization-free efficiency is a clear strength compared to prior optimization-based methods. The explicit coupling to a vehicle dynamics model for pose correction is a novel direction worth exploring if validated.
major comments (2)
- Abstract: The abstract reports timing numbers (1.84s core, 6.24s full) and Waymo dataset use but provides no quantitative metrics on visual fidelity (e.g., PSNR, LPIPS), dynamics accuracy (e.g., pose error vs. ground truth), or baseline comparisons, leaving the claims of 'competitive visual consistency' and 'physics-aware' editing without visible supporting evidence.
- Experiments (implied by abstract claims): The 4-DOF half-car model is presented as producing 'physics-aware vehicle pose correction' without any reported validation against real vehicle data (IMU, suspension), parameter fitting to actual vehicles, or error metrics versus higher-fidelity simulators; this assumption is load-bearing for the central claim that the corrections make edited scenes appear physically plausible.
minor comments (1)
- The abstract could more explicitly state the range of road irregularities tested to clarify the scope of the single-image insertion method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with honest responses based on the current work and indicate where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [—] Abstract: The abstract reports timing numbers (1.84s core, 6.24s full) and Waymo dataset use but provides no quantitative metrics on visual fidelity (e.g., PSNR, LPIPS), dynamics accuracy (e.g., pose error vs. ground truth), or baseline comparisons, leaving the claims of 'competitive visual consistency' and 'physics-aware' editing without visible supporting evidence.
Authors: The abstract is written to emphasize the core technical contributions (one-shot road insertion and dynamics coupling) and reported runtime. The experiments section demonstrates visual consistency through qualitative results on Waymo sequences, as quantitative metrics such as PSNR/LPIPS are not applicable without ground-truth edited scenes. We agree that the abstract could better signpost the evaluation approach and will revise it to reference the qualitative and efficiency results shown in the experiments. revision: partial
-
Referee: [—] Experiments (implied by abstract claims): The 4-DOF half-car model is presented as producing 'physics-aware vehicle pose correction' without any reported validation against real vehicle data (IMU, suspension), parameter fitting to actual vehicles, or error metrics versus higher-fidelity simulators; this assumption is load-bearing for the central claim that the corrections make edited scenes appear physically plausible.
Authors: The 4-DOF half-car model is a standard, widely used approximation in vehicle dynamics literature for capturing vertical displacement and pitch under road irregularities. Our contribution lies in coupling this established model with 3DGS road edits for plausible pose correction in an optimization-free pipeline; we do not claim or demonstrate empirical matching to real IMU traces or higher-fidelity simulators, as that would require additional data collection outside the paper's scope. The resulting poses are shown to produce visually coherent edited driving scenes on Waymo data. We will add a brief discussion of the model's assumptions and limitations in the revised manuscript. revision: partial
Circularity Check
No circularity; derivation chain self-contained with external model coupling
full rationale
The provided abstract and description contain no equations, parameter-fitting steps, or self-citations that reduce any claimed output (road insertion, pose correction via 4-DOF half-car model) to an input by construction. The pipeline is described as one-shot and optimization-free, with timing and visual results on Waymo as external benchmarks. No self-definitional, fitted-prediction, or uniqueness-imported patterns are exhibited. Per rules, this is the normal honest finding of score 0 when the central claims do not reduce to the paper's own fitted values or prior self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Li, ”Choose your simulator wisely: A review on open-source simu- lators for autonomous driving,”IEEE Trans
Y . Li, ”Choose your simulator wisely: A review on open-source simu- lators for autonomous driving,”IEEE Trans. Intell. V eh., vol. 9, no. 5, pp. 4861–4876, May 2024
2024
-
[2]
Sadeghi and A
P. Sadeghi and A. Goli, ”Investigating the impact of pavement condition and weather characteristics on road accidents,”Int. J. Crashworthiness, vol. 2024, pp. 1–17, Jan. 2024
2024
-
[3]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkuehler, and G. Drettakis, ”3D Gaussian splatting for real-time radiance field rendering,”ACM Trans. Graph., vol. 42, no. 4, pp. 1–14, Jul. 2023
2023
-
[4]
Yan et al., ”Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting,” inProc
Y . Yan et al., ”Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting,” inProc. Eur . Conf. Comput. Vis., 2024, pp. 156- 173
2024
-
[5]
Liu et al., ”Omni-Scene: Omni-Gaussian Representation for Ego- Centric Sparse-View Scene Reconstruction,” inProc
P. Liu et al., ”Omni-Scene: Omni-Gaussian Representation for Ego- Centric Sparse-View Scene Reconstruction,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2025, pp. 22317-22327
2025
- [6]
- [7]
-
[8]
S. Liu, H. Zhang, et al., ”HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes,” 2026,arXiv:2604.04887
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Haque, M
A. Haque, M. Tancik, A. A. Efros, et al., ”Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions,” inProc. IEEE/CVF Int. Conf. Comput. Vis. , 2023, pp. 19740–19750
2023
-
[10]
Y . Chen, Z. Chen, C. Zhang, et al., ”GaussianEditor: Swift and Con- trollable 3D Editing with Gaussian Splatting,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 10206-10215
2024
-
[11]
Wu, ”GaussCtrl: Multi-view consistent text-driven 3D Gaussian splat- ting editing,” inProc
J. Wu, ”GaussCtrl: Multi-view consistent text-driven 3D Gaussian splat- ting editing,” inProc. Eur . Conf. Comput. Vis., 2024, pp. 55–71
2024
-
[12]
Ye et al., ”Gaussian grouping: Segment and edit anything in 3d scenes,” inProc
M. Ye et al., ”Gaussian grouping: Segment and edit anything in 3d scenes,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 162-179
2024
-
[13]
U. Jain, A. Mirzaei, and I. Gilitschenski, ”GaussianCut: Interactive segmentation via graph cut for 3D Gaussian splatting,” inProc. Adv. Neural Inf. Process. Syst., vol. 37, 2025, pp. 89184–89212
2025
-
[14]
H. Zhao, C. Zeng, L. Zhuang, et al., ”High-Fidelity Simulated Data Generation for Real-World Zero-Shot Robotic Manipulation Learning With Gaussian Splatting,”IEEE Robot. Automat. Lett., vol. 11, no. 5, pp. 5310-5317, Mar. 2026
2026
- [15]
-
[16]
Y . Xu, H. Cheng, Y . Yu, et al., ”Gaussian On-the-Fly Splatting: A Pro- gressive Framework for Robust Near Real-Time 3DGS Optimization,” IEEE Robot. Automat. Lett., vol. 11, no. 1, pp. 426-433, Nov. 2025
2025
-
[17]
D. I. Lee et al., ”EditSplat: Multi-view fusion and attention-guided optimization for view-consistent 3D scene editing with 3D Gaussian splatting,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2025, pp. 11135–11145
2025
-
[18]
Pahk, ”Lane segmentation data augmentation for heavy rain sensor blockage using realistically translated raindrop images and CARLA simulator,”IEEE Robot
J. Pahk, ”Lane segmentation data augmentation for heavy rain sensor blockage using realistically translated raindrop images and CARLA simulator,”IEEE Robot. Automat. Lett., vol. 9, no. 6, pp. 5488–5495, Jun. 2024
2024
-
[19]
Lin and M
P. Lin and M. Tsukada, ”Model predictive path-planning controller with potential function for emergency collision avoidance on highway driving,”IEEE Robot. Automat. Lett., vol. 7, no. 2, pp. 4662–4669, Apr. 2022
2022
-
[20]
Feng et al., ”Gaussian Splashing: Unified Particles for Versatile Motion Synthesis and Rendering,” inProc
Y . Feng et al., ”Gaussian Splashing: Unified Particles for Versatile Motion Synthesis and Rendering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2025, pp. 518-529
2025
-
[21]
Y . Ma et al., ”FastPhysGS: Accelerating Physics-based Dynamic 3DGS Simulation via Interior Completion and Adaptive Optimization,” 2026, arXiv:2602.01723
-
[22]
SimScale: Learning to Drive via Real-World Simulation at Scale
H. Tian et al., ”SimScale: Learning to Drive via Real-World Simulation at Scale,” 2025,arXiv:2511.23369
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning,
H. Gao, ”RAD: Training an end-to-end driving policy via large-scale 3DGS-based reinforcement learning,” 2025,arXiv:2502.13144
-
[24]
Sun, ”Scalability in perception for autonomous driving: Waymo open dataset,” inProc
P. Sun, ”Scalability in perception for autonomous driving: Waymo open dataset,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 2446–2454
2020
-
[25]
Liu et al., ”Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inProc
S. Liu et al., ”Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inProc. Eur . Conf. Comput. Vis., 2024, pp. 38–55
2024
-
[26]
Kirillov et al., ”Segment anything,” inProc
A. Kirillov et al., ”Segment anything,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2023, pp. 3992–4003
2023
-
[27]
H. Lin, S. Chen, J. Liew, et al., ”Depth anything 3: Recovering the visual space from any views,” 2025,arXiv:2511.10647
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Reinhard, M
E. Reinhard, M. Adhikhmin, B. Gooch, and P. Shirley, ”Color transfer between images,”IEEE Comput. Graph. Appl., vol. 21, no. 4, pp. 34–41, 2001
2001
-
[29]
Rajamani,V ehicle Dynamics and Control
R. Rajamani,V ehicle Dynamics and Control. New York, NY , USA: Springer Science & Business Media, 2011
2011
-
[30]
Tejada-Casado, J
M. Tejada-Casado, J. Ruiz-L ´opez, R. I. Ghinea, et al., ”Exploring the CIEDE2000 thresholds for lightness, chroma, and hue differences in dentistry,”J. Dent., vol. 150, 2024, Art. no. 105327
2024
-
[31]
Kong et al., ”Progressive Multi-Scale Perception Network for Non- Uniformly Blurred Underwater Image Restoration,”Sensors, vol
D. Kong et al., ”Progressive Multi-Scale Perception Network for Non- Uniformly Blurred Underwater Image Restoration,”Sensors, vol. 25, no. 17, p. 5439, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.