Bandwidth-Aware and Cost-Efficient Pipeline Parallel Scheduling in Geo-Distributed LLM Training
Pith reviewed 2026-06-29 20:52 UTC · model grok-4.3
The pith
BACE-Pipe schedules pipeline-parallel LLM training across regions to cut both job completion time and electricity cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
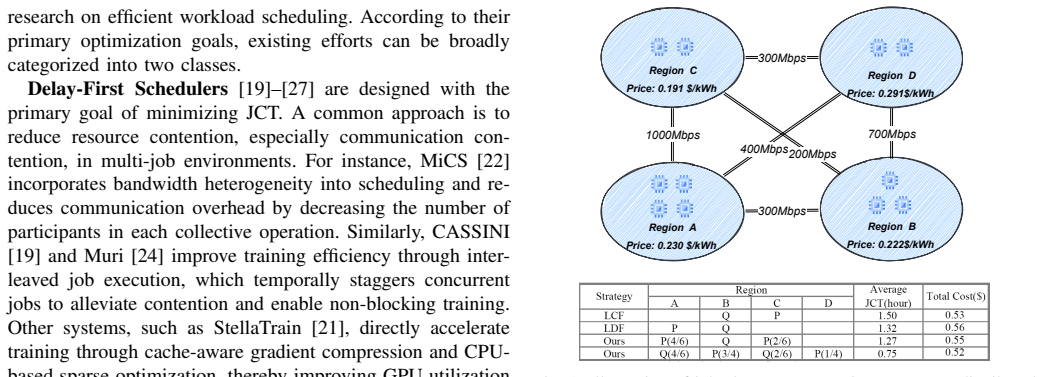
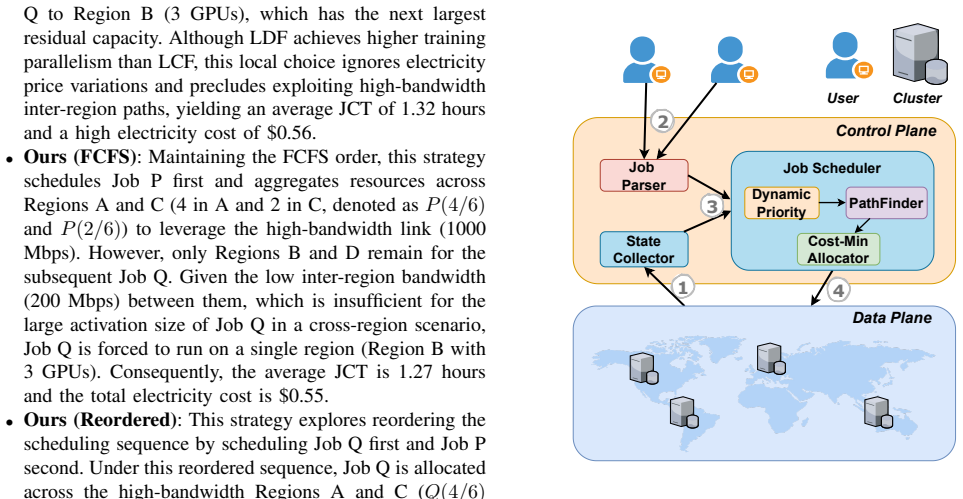
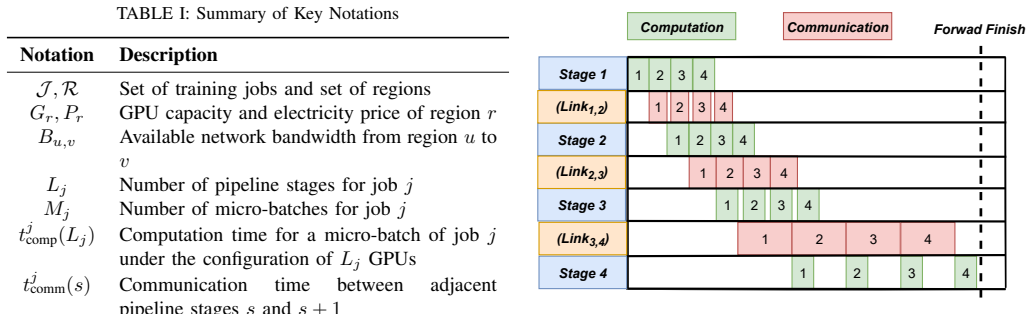
BACE-Pipe is a bandwidth-aware and cost-efficient pipeline scheduling framework for LLM training across geo-distributed clusters. It first applies a dynamic job prioritization mechanism that optimizes execution order by jointly considering job characteristics such as computation time and real-time network utilization. It then uses a bandwidth-aware pathfinder to locate feasible cross-region pipeline paths that avoid communication stalls, and among those paths a cost-minimizing allocator places GPUs in regions offering lower electricity prices. The result is reduced head-of-line blocking, higher resource utilization, and simultaneous drops in job completion time and total electricity cost, wi
What carries the argument
Dynamic job prioritization mechanism together with bandwidth-aware pathfinder and cost-minimizing allocator
If this is right
- Mitigates head-of-line blocking for multiple concurrent jobs
- Improves resource utilization across regions with varying bandwidth
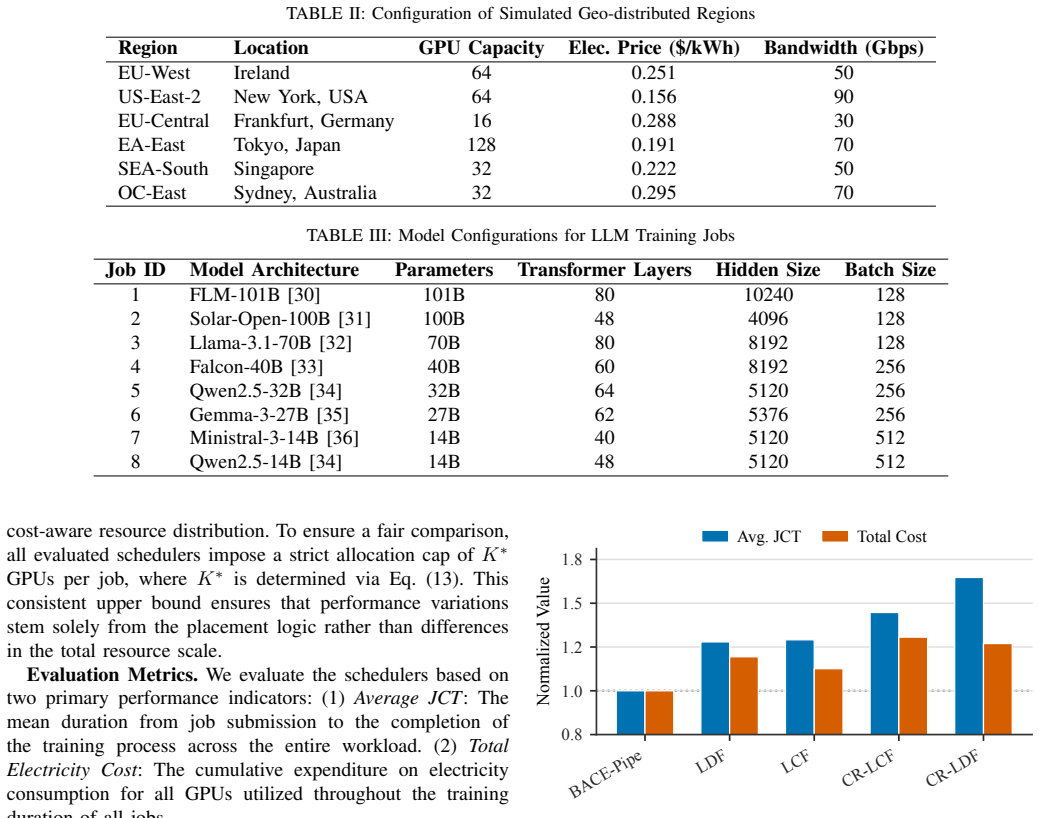
- Reduces average job completion time by 27.9 to 64.7 percent
- Reduces total electricity cost by 12.6 to 30.6 percent
- Enables joint optimization under heterogeneous bandwidth and power prices
Where Pith is reading between the lines
- The same prioritization and placement logic could apply to data-parallel or tensor-parallel training jobs with similar cross-region constraints
- Real deployments would need accurate online estimates of bandwidth and prices to match simulation gains
- Cloud providers could incorporate the allocator into existing multi-tenant schedulers to lower operational costs for AI workloads
- Extending the pathfinder to account for latency variation rather than bandwidth alone might further improve pipeline stability
Load-bearing premise
The dynamic prioritization, bandwidth-aware pathfinding, and cost-minimizing allocation can be realized in practice without unmodeled overheads or inaccuracies in heterogeneous bandwidth and electricity price modeling.
What would settle it
Running BACE-Pipe on real geo-distributed GPU clusters and comparing observed job completion times and electricity costs against the same baselines used in the simulations.
Figures
read the original abstract
The rapid evolution of large language models (LLMs) has made geographically distributed training necessary due to GPU scarcity within a single cloud region. In such cross-region settings, Pipeline Parallelism (PP) is communication-efficient, yet scheduling PP remains challenging under heterogeneous inter-region bandwidth and regional electricity prices. Existing schedulers are either delay-first, incurring high electricity cost, or cost-first, relying on rigid resource allocation that prolongs Job Completion Time (JCT). They are also ineffective at optimizing execution order in multi-tenant environments, where long-running and bandwidth-intensive jobs can cause head-of-line (HoL) blocking and degrade overall performance. To this end, we propose BACE-Pipe, a bandwidth-aware and cost-efficient pipeline scheduling framework for LLM training across geo-distributed clusters. BACE-Pipe first introduces a dynamic job prioritization mechanism that optimizes execution order by jointly considering job characteristics (e.g., computation time) and real-time network utilization. It then employs a bandwidth-aware pathfinder to identify feasible cross-region pipeline paths that satisfy communication constraints, thereby preventing communication from stalling the pipeline. Among all feasible paths, a cost-minimizing allocator determines the optimal GPU placement strategy by preferentially assigning resources to regions with lower electricity prices. Consequently, BACE-Pipe mitigates HoL blocking, improves resource utilization, and simultaneously reduces both JCT and total electricity cost. Extensive simulations show that BACE-Pipe reduces average JCT by 27.9%--64.7% and total electricity cost by 12.6%--30.6% compared with state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BACE-Pipe, a scheduling framework for pipeline-parallel LLM training across geo-distributed clusters with heterogeneous bandwidth and electricity prices. It introduces three components: (1) a dynamic job prioritization mechanism that jointly considers job compute characteristics and real-time network utilization to mitigate head-of-line blocking, (2) a bandwidth-aware pathfinder that selects feasible cross-region pipeline paths satisfying communication constraints, and (3) a cost-minimizing allocator that preferentially places GPUs in lower-electricity-price regions among feasible paths. Extensive simulations are reported to show average JCT reductions of 27.9%--64.7% and total electricity cost reductions of 12.6%--30.6% relative to state-of-the-art baselines.
Significance. If the simulation results prove robust and the mechanisms can be realized with low overhead, the work addresses a timely problem in scaling LLM training under GPU scarcity by jointly optimizing JCT and operational cost in multi-tenant geo-distributed settings. The explicit combination of bandwidth awareness, dynamic prioritization, and electricity-price sensitivity in pipeline scheduling is a relevant direction for distributed ML systems.
major comments (2)
- [Evaluation] Evaluation section: the manuscript states specific quantitative improvements (27.9%--64.7% JCT, 12.6%--30.6% cost) from simulations but provides no description of simulation methodology, workload traces, baseline implementations, number of runs, statistical tests, or ablation of the three components. This information is load-bearing for the central claim that the dynamic prioritization, pathfinder, and allocator together eliminate HoL blocking and deliver the reported gains.
- [§3] §3 (mechanism description): no analysis or bounds are given on the overhead of real-time network utilization monitoring and dynamic re-prioritization, which is required to substantiate that the approach remains effective once measurement latency, noise, or non-stationary prices are present.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the manuscript states specific quantitative improvements (27.9%--64.7% JCT, 12.6%--30.6% cost) from simulations but provides no description of simulation methodology, workload traces, baseline implementations, number of runs, statistical tests, or ablation of the three components. This information is load-bearing for the central claim that the dynamic prioritization, pathfinder, and allocator together eliminate HoL blocking and deliver the reported gains.
Authors: We agree that the evaluation section lacks the necessary methodological details. In the revised manuscript we will add a dedicated subsection describing the simulation setup, including workload traces, baseline implementations, number of runs, statistical tests, and ablation studies isolating each of the three components. revision: yes
-
Referee: [§3] §3 (mechanism description): no analysis or bounds are given on the overhead of real-time network utilization monitoring and dynamic re-prioritization, which is required to substantiate that the approach remains effective once measurement latency, noise, or non-stationary prices are present.
Authors: We acknowledge the absence of overhead analysis. The revised manuscript will include bounds and discussion of the monitoring and re-prioritization overheads, explicitly addressing measurement latency, noise, and non-stationary prices to substantiate practicality. revision: yes
Circularity Check
No circularity: algorithmic proposal evaluated by simulation, no derivations or fitted predictions
full rationale
The paper presents BACE-Pipe as a scheduling framework with three components (dynamic prioritization, bandwidth-aware pathfinder, cost-minimizing allocator) whose performance is assessed exclusively through simulation against baselines. No equations, parameter fitting, uniqueness theorems, or self-citations appear in the provided text as load-bearing steps. The claimed JCT and cost reductions are simulation outcomes, not reductions of a result to its own inputs by construction. This matches the default case of a self-contained empirical proposal without circular derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Z. Tang, X. Kang, Y . Yin, X. Pan, Y . Wang, X. He, Q. Wang, R. Zeng, K. Zhao, S. Shiet al., “Fusionllm: A decentralized llm training system on geo-distributed gpus with adaptive compression,”arXiv preprint arXiv:2410.12707, 2024
-
[4]
Identifying who you are no matter what you write through abstracting handwriting style,
J. Huang, Y . Feng, F.-Q. Cui, X. Zhang, Z. Liu, X. Liu, J. Liu, F. Zhang, and M. Li, “Identifying who you are no matter what you write through abstracting handwriting style,”IEEE Transactions on Dependable and Secure Computing, 2026
2026
-
[5]
Megascale: Scaling large language model training to more than 10,000 gpus,
Z. Jiang, H. Lin, Y . Zhong, Q. Huang, Y . Chen, Z. Zhang, Y . Peng, X. Li, C. Xie, S. Nonget al., “Megascale: Scaling large language model training to more than 10,000 gpus,” in21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), 2024, pp. 745–760
2024
-
[6]
Aws global infrastructure,
“Aws global infrastructure,” https://aws.amazon.com/about-aws/ global-infrastructure/, accessed: April 27, 2025
2025
-
[7]
Skypilot: An intercloud broker for sky computing,
Z. Yang, Z. Wu, M. Luo, W.-L. Chiang, R. Bhardwaj, W. Kwon, S. Zhuang, F. S. Luan, G. Mittal, S. Shenkeret al., “Skypilot: An intercloud broker for sky computing,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 2023, pp. 437–455
2023
-
[8]
Ml training with cloud gpu shortages: Is cross-region the answer?
F. Strati, P. Elvinger, T. Kerimoglu, and A. Klimovic, “Ml training with cloud gpu shortages: Is cross-region the answer?” inProceedings of the 4th Workshop on Machine Learning and Systems, 2024, pp. 107–116
2024
-
[9]
Tango: A cost optimization framework for tenant task placement in geo-distributed clouds,
L. Luo, G. Zhao, H. Xu, Z. Yu, and L. Xie, “Tango: A cost optimization framework for tenant task placement in geo-distributed clouds,” in IEEE INFOCOM 2023-IEEE Conference on Computer Communications. IEEE, 2023, pp. 1–10
2023
-
[10]
Auction- based vm allocation for deadline-sensitive tasks in distributed edge cloud,
G. Gao, M. Xiao, J. Wu, H. Huang, S. Wang, and G. Chen, “Auction- based vm allocation for deadline-sensitive tasks in distributed edge cloud,”IEEE Transactions on Services Computing, vol. 14, no. 6, pp. 1702–1716, 2021
2021
-
[11]
Fedquad: Adaptive layer-wise lora deployment and activation quantization for federated fine-tuning,
J. Liu, R. Li, H. Xu, Q. Ma, J. Yan, and L. Huang, “Fedquad: Adaptive layer-wise lora deployment and activation quantization for federated fine-tuning,”IEEE Transactions on Mobile Computing, 2025
2025
-
[12]
A quantitative survey of communication optimizations in distributed deep learning,
S. Shi, Z. Tang, X. Chu, C. Liu, W. Wang, and B. Li, “A quantitative survey of communication optimizations in distributed deep learning,” IEEE Network, vol. 35, no. 3, pp. 230–237, 2020
2020
-
[13]
Fed- impro: Measuring and improving client update in federated learning,
Z. Tang, Y . Zhang, S. Shi, X. Tian, T. Liu, B. Han, and X. Chu, “Fed- impro: Measuring and improving client update in federated learning,” arXiv preprint arXiv:2402.07011, 2024
-
[14]
Gpipe: Efficient training of giant neu- ral networks using pipeline parallelism,
Y . Huang, Y . Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wuet al., “Gpipe: Efficient training of giant neu- ral networks using pipeline parallelism,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[15]
HexiScale: Facilitating Large Language Model Training over Heterogeneous Hardware
R. Yan, Y . Jiang, W. Tao, X. Nie, B. Cui, and B. Yuan, “Flashflex: Accommodating large language model training over heterogeneous environment,”arXiv preprint arXiv:2409.01143, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Asynchronous federated learning over non-iid data via over-the-air computation,
Q. Ma, X. Song, J. Zhou, H. Wang, Y . Liao, J. Liu, and H. Xu, “Asynchronous federated learning over non-iid data via over-the-air computation,”IEEE Transactions on Networking, 2025
2025
-
[17]
Cisco annual internet report (2018-2023) white paper,
Cisco, “Cisco annual internet report (2018-2023) white paper,” 2018. [Online]. Available: https://www.cisco.com/c/en/us/solutions/collateral/ executive-perspectives/annual-internet-report/white-paper-c11-741490. html
2018
-
[18]
Globalpetrolprices,
“Globalpetrolprices,” https://zh.globalpetrolprices.com/electricity_ prices, accessed: December 27, 2024
2024
-
[19]
Cassini: Network-aware job scheduling in machine learning clusters,
S. Rajasekaran, M. Ghobadi, and A. Akella, “Cassini: Network-aware job scheduling in machine learning clusters,” in21st USENIX Sym- posium on Networked Systems Design and Implementation (NSDI 24), 2024, pp. 1403–1420
2024
-
[20]
Crux: Gpu-efficient communication scheduling for deep learn- ing training,
J. Cao, Y . Guan, K. Qian, J. Gao, W. Xiao, J. Dong, B. Fu, D. Cai, and E. Zhai, “Crux: Gpu-efficient communication scheduling for deep learn- ing training,” inProceedings of the ACM SIGCOMM 2024 Conference, 2024, pp. 1–15
2024
-
[21]
Accelerating model training in multi-cluster environments with consumer-grade gpus,
H. Lim, J. Ye, S. Abdu Jyothi, and D. Han, “Accelerating model training in multi-cluster environments with consumer-grade gpus,” in Proceedings of the ACM SIGCOMM 2024 Conference, 2024, pp. 707– 720
2024
-
[22]
Mics: near-linear scaling for training gigantic model on public cloud,
Z. Zhang, S. Zheng, Y . Wang, J. Chiu, G. Karypis, T. Chilimbi, M. Li, and X. Jin, “Mics: near-linear scaling for training gigantic model on public cloud,”arXiv preprint arXiv:2205.00119, 2022
-
[23]
Gandiva: Introspective cluster scheduling for deep learning,
W. Xiao, R. Bhardwaj, R. Ramjee, M. Sivathanu, N. Kwatra, Z. Han, P. Patel, X. Peng, H. Zhao, Q. Zhanget al., “Gandiva: Introspective cluster scheduling for deep learning,” in13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), 2018, pp. 595–610
2018
-
[24]
Multi-resource interleaving for deep learning training,
Y . Zhao, Y . Liu, Y . Peng, Y . Zhu, X. Liu, and X. Jin, “Multi-resource interleaving for deep learning training,” inProceedings of the ACM SIGCOMM 2022 Conference, 2022, pp. 428–440
2022
-
[25]
Shock- wave: Fair and efficient cluster scheduling for dynamic adaptation in machine learning,
P. Zheng, R. Pan, T. Khan, S. Venkataraman, and A. Akella, “Shock- wave: Fair and efficient cluster scheduling for dynamic adaptation in machine learning,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 2023, pp. 703–723
2023
-
[26]
Themis: Fair and efficient gpu cluster scheduling,
K. Mahajan, A. Balasubramanian, A. Singhvi, S. Venkataraman, A. Akella, A. Phanishayee, and S. Chawla, “Themis: Fair and efficient gpu cluster scheduling,” in17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), 2020, pp. 289–304
2020
-
[27]
Hetpipe: Enabling large dnn training on (whimpy) heterogeneous gpu clusters through integration of pipelined model parallelism and data parallelism,
J. H. Park, G. Yun, M. Y . Chang, N. T. Nguyen, S. Lee, J. Choi, S. H. Noh, and Y .-r. Choi, “Hetpipe: Enabling large dnn training on (whimpy) heterogeneous gpu clusters through integration of pipelined model parallelism and data parallelism,” in2020 USENIX Annual Technical Conference (USENIX ATC 20), 2020, pp. 307–321
2020
-
[28]
Minimizing electricity cost: Optimization of distributed internet data centers in a multi-electricity- market environment,
L. Rao, X. Liu, L. Xie, and W. Liu, “Minimizing electricity cost: Optimization of distributed internet data centers in a multi-electricity- market environment,” in2010 Proceedings IEEE INFOCOM. IEEE, 2010, pp. 1–9
2010
-
[29]
Optimal task placement with qos constraints in geo-distributed data centers using dvfs,
L. Gu, D. Zeng, A. Barnawi, S. Guo, and I. Stojmenovic, “Optimal task placement with qos constraints in geo-distributed data centers using dvfs,”IEEE Transactions on Computers, vol. 64, no. 7, pp. 2049–2059, 2014
2049
-
[30]
Flm-101b: An open llm and how to train it with $100k budget,
X. Li, Y . Yao, X. Jiang, X. Fang, X. Meng, S. Fan, P. Han, J. Li, L. Du, B. Qin, Z. Zhang, A. Sun, and Y . Wang, “Flm-101b: An open llm and how to train it with $100k budget,” 2023
2023
-
[31]
S. Park, S. Kim, J. Cho, G. Gimet al., “Solar open technical report,”arXiv preprint arXiv:2601.07022, 2025. [Online]. Available: https://huggingface.co/papers/2601.07022
-
[32]
A. Grattafiori, A. Dubey, A. Jauhriet al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
[Online]. Available: https://arxiv.org/abs/2306.01116
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/
2024
-
[36]
Gemma 3 technical report,
G. Team, A. Kamath, J. Ferretet al., “Gemma 3 technical report,”
-
[37]
[Online]. Available: https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
A. H. Liu, K. Khandelwal, S. Subramanianet al., “Ministral 3,” 2026. [Online]. Available: https://arxiv.org/abs/2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Mitigating catastrophic forgetting with adaptive transformer block expansion in federated fine-tuning,
Y . Huo, J. Liu, H. Xu, Z. Ma, S. Wang, and L. Huang, “Mitigating catastrophic forgetting with adaptive transformer block expansion in federated fine-tuning,”IEEE Transactions on Mobile Computing, 2026
2026
-
[40]
Stanford alpaca: An instruction-following llama model,
R. Taori, I. Gulrajani, T. Zhang, Y . Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford alpaca: An instruction-following llama model,” https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[41]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” 2016
2016
-
[42]
Openwebtext corpus,
A. Gokaslan, V . Cohen, E. Pavlick, and S. Tellex, “Openwebtext corpus,” http://Skylion007.github.io/OpenWebTextCorpus, 2019
2019
-
[43]
Towards latency sensitive cloud native applications: A performance study on aws,
I. Pelle, J. Czentye, J. Dóka, and B. Sonkoly, “Towards latency sensitive cloud native applications: A performance study on aws,” in2019 IEEE 12th International Conference on Cloud Computing (CLOUD), 2019, pp. 272–280
2019
-
[44]
Decentralized training of foundation models in heterogeneous environments,
B. Yuan, Y . He, J. Davis, T. Zhang, T. Dao, B. Chen, P. S. Liang, C. Re, and C. Zhang, “Decentralized training of foundation models in heterogeneous environments,”Advances in Neural Information Process- ing Systems, vol. 35, pp. 25 464–25 477, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.