AuthTrace: Diagnosing Evidence Construction in Thematically Dense Single-Author Corpora
Pith reviewed 2026-06-29 22:45 UTC · model grok-4.3
The pith
Evidence recall predicts answer correctness at r=0.96 in thematically dense single-author corpora, with fan-in exposing faster collapse for flat retrieval than organized methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
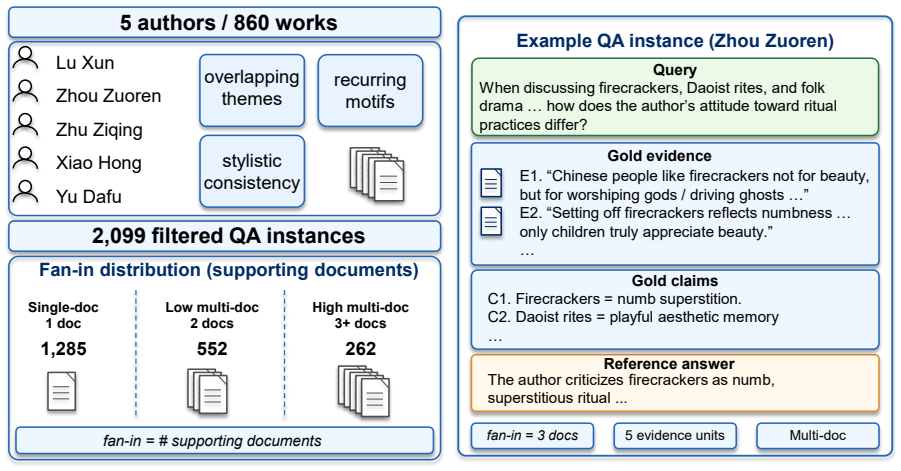
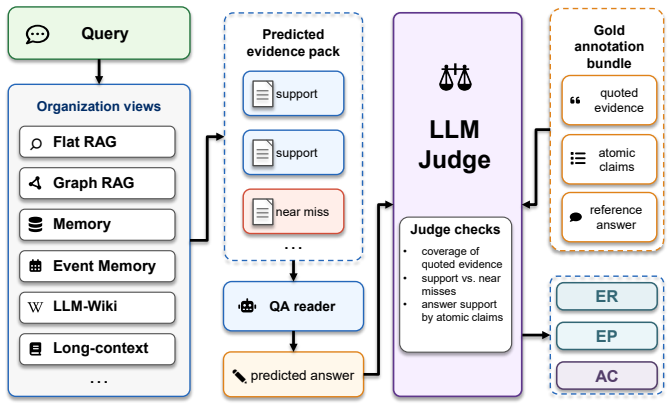
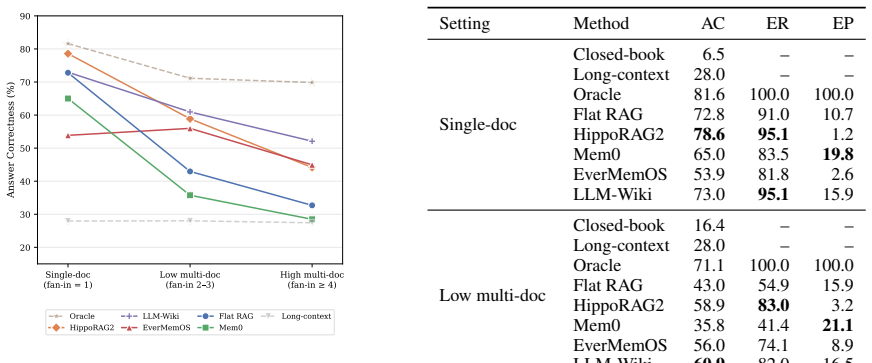
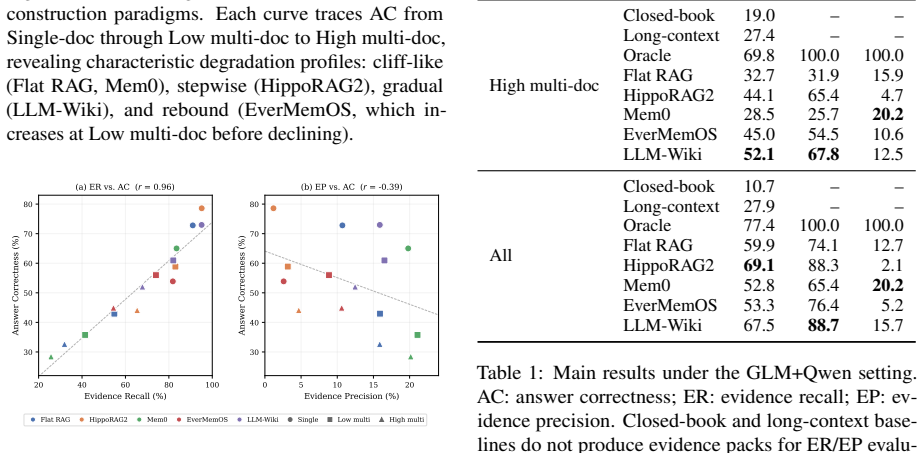
AuthTrace supplies quoted evidence, fan-in annotations, and a pack-level protocol that evaluates retrieval, memory, graph, and structured-evidence systems on the same thematically dense single-author corpora. Across eight systems and two QA models, evidence recall correlates at r=0.96 with answer correctness under the main reader-judge pair, and the majority of failures arise from omitted evidence rather than synthesis mistakes. The fan-in gradient further reveals that flat retrieval degrades two to three times faster than thematically organized evidence construction.
What carries the argument
The fan-in gradient, defined as the number of source documents needed to support a given answer, used as the primary axis for controlled comparison of evidence-construction paradigms.
If this is right
- Evidence recall is the strongest observed predictor of answer correctness.
- Most failures stem from missing evidence rather than answer synthesis.
- Flat retrieval degrades 2-3x faster than thematically organized evidence construction as fan-in rises.
- Organized evidence paradigms maintain higher performance under higher fan-in workloads.
Where Pith is reading between the lines
- Real-world QA systems on single-author document collections may gain more from graph or structured-evidence methods than from simple flat retrieval when answers span multiple passages.
- Testing the same fan-in protocol on multi-author corpora could reveal whether style variation changes the relative strengths of each paradigm.
- Fan-in could serve as a workload classifier to select an evidence-construction approach based on expected evidence density in a target domain.
Load-bearing premise
The near-miss distractors that share style, topic, and vocabulary in single-author corpora create a controlled setting in which fan-in serves as a valid primary diagnostic for comparing evidence paradigms.
What would settle it
An experiment in which evidence recall shows low or no correlation with answer correctness, or in which flat retrieval and thematically organized methods exhibit similar degradation rates as fan-in increases.
Figures




read the original abstract
Evidence construction--the stage that determines which passages reach the language model before generation begins--is evaluated paradigm by paradigm, leaving practitioners with no principled way to diagnose which organization strategy fails, where, or why. We introduce AuthTrace, a diagnostic benchmark built on thematically dense single-author corpora where near-miss distractors share style, topic, and vocabulary with the required evidence. AuthTrace provides explicit quoted evidence, exact fan-in annotation, and a unified pack-level protocol measuring evidence recall, evidence precision, and answer correctness. A fan-in gradient--the number of source documents required to support the answer--serves as the primary diagnostic axis, enabling controlled comparison across retrieval, memory, graph, and structured-evidence paradigms. Evaluating eight systems across two QA models, we find that evidence recall is the strongest observed predictor of answer correctness under the primary reader-judge pair (r = 0.96); most failures stem from missing evidence rather than answer synthesis. Fan-in further exposes paradigm-specific collapse patterns: flat retrieval degrades 2-3x faster than thematically organized evidence construction. These results show fan-in decomposition to be a reusable diagnostic lens for identifying where evidence-construction systems fail and which paradigm best serves a given workload.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AuthTrace, a diagnostic benchmark for evidence construction in QA over thematically dense single-author corpora containing near-miss distractors that share style, topic, and vocabulary. The benchmark supplies explicit quoted evidence annotations, exact fan-in labels (number of source documents required), and a unified pack-level evaluation protocol that separately measures evidence recall, evidence precision, and answer correctness. Eight systems spanning retrieval, memory, graph, and structured-evidence paradigms are evaluated across two QA models; the central empirical findings are that evidence recall correlates at r = 0.96 with answer correctness under the primary reader-judge pair and that flat retrieval degrades 2–3 imes faster than thematically organized approaches as fan-in increases.
Significance. If the reported correlation and paradigm-collapse patterns hold under the stated protocol, AuthTrace supplies a reusable, controlled diagnostic lens that isolates recall failures from synthesis failures and exposes workload-specific strengths of different evidence-construction paradigms. The explicit fan-in axis and pack-level metrics constitute a concrete methodological contribution that enables head-to-head comparison without conflating retrieval quality with generation quality.
minor comments (3)
- Abstract and §3 (benchmark construction) should report the total number of QA pairs, number of source documents per corpus, and the distribution of fan-in values so that the r = 0.96 correlation can be interpreted with respect to sample size and coverage.
- Figure 4 (or equivalent) showing degradation curves should include error bars or confidence intervals and state the number of runs per system.
- The definition of the primary reader-judge pair and any inter-annotator agreement statistics for the evidence annotations belong in the main text rather than solely in an appendix.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description accurately reflects the goals and findings of AuthTrace. No major comments were raised in the report.
Circularity Check
No significant circularity; empirical benchmark with independent protocol
full rationale
The paper presents an empirical diagnostic benchmark (AuthTrace) built on thematically dense corpora with explicit evidence annotations, fan-in gradients, and pack-level metrics for recall/precision/correctness. It evaluates eight systems across two QA models and reports observed correlations (e.g., r=0.96 between recall and correctness) plus paradigm-specific degradation patterns. No equations, first-principles derivations, or predictions are claimed that reduce to fitted inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. The benchmark definition, near-miss distractors, and evaluation protocol are stated independently of the reported outcomes. This matches the default expectation for non-circular empirical work; the reader's score of 2.0 is noted but no load-bearing circular step is exhibited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions that recall, precision, and answer correctness are meaningful and comparable metrics across evidence-construction paradigms.
invented entities (1)
-
AuthTrace benchmark with fan-in annotation
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Retrieval as Reasoning: Self-Evolving Agent-Native Retrieval via LLM-Wiki
LLM-Wiki structures external knowledge as compilable wiki pages with links and persistent self-correction, achieving SOTA results on HotpotQA, MuSiQue, and 2WikiMultiHopQA by 2.0-8.1 F1 points over prior RAG systems.
Reference graph
Works this paper leans on
-
[1]
GLM-5: from Vibe Coding to Agentic Engineering
Enabling large language models to generate text with citations. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 6465–6488, Singapore. Associa- tion for Computational Linguistics. 9 GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengx...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu
Curran Associates, Inc. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human align- ment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore. Association for Com- putational Linguistics. Adyasha Maharana, Do...
2023
-
[3]
Retrieval as Reasoning: Self-Evolving Agent-Native Retrieval via LLM-Wiki
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand. Association for Compu- tational Linguistics. Haoliang Ming, Feifei Li, Xiaoqing Wu, and Wen- hui Que. 2026. Retrieval as reasoning: Self- ev...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rocktäschel, and Sebastian Riedel. 2021. KILT: a benchmark for knowledge intensive language tasks. InProc...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
A-MEM: Agentic Memory for LLM Agents
RAPTOR: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth Interna- tional Conference on Learning Representations. Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming- Wei Chang. 2022. ASQA: Factoid questions meet long-form answers. InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing, pages 827...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Answer generation uses a maximum of 2,048 tokens at temperature 0.0
The top 10 retrieved documents (full articles) are passed to the QA reader. Answer generation uses a maximum of 2,048 tokens at temperature 0.0. Mem0.Mem0 extracts and compresses memory entries from the chunked corpus (300-character chunks, matching Flat RAG) using GLM-5.1- FP8, producing abstracted entries shorter than raw chunks. We use Qwen3-Embedding-...
2026
-
[7]
Answer based on the context; do not fabricate
-
[8]
The answer should completely cover the key points required by the question
-
[9]
If the context is insufficient to support the answer, state that the evidence is insufficient
-
[10]
[Please answer based on prior knowledge and the prompt directly]
Do not output your reasoning process. [Question] {query} [Context] [Evidence 1] {text_1} [Evidence 2] {text_2} ... Please provide the answer directly. For the closed-book setting, the context section is replaced with: “[Please answer based on prior knowledge and the prompt directly]”, and an addi- tional line specifies the author’s name. G Additional Diag...
-
[11]
It can be answered primarily from this article alone
-
[12]
The question must be grounded in concrete textual details in the article
-
[13]
The answer must be supported by direct evidence from this article
-
[14]
The instance should be suitable as a single-document sample for an author-grounded QA benchmark. II. Query Requirements
-
[15]
The query must NOT contain the article title, title abbreviations, title hints, or any information that would reveal which article to retrieve
-
[16]
the author
Always refer to the writer as “the author”; never use the author’s real name or pen name
-
[17]
in this article
Do not use explicit range indicators such as “in this article” or “in the text”; instead, implicitly delimit the scope through textual details
-
[18]
A question may only be generated if it can be stably anchored by unique details in the current article
-
[19]
If a question would likely hold equally well in many other articles by the same author, do not generate it
-
[20]
By default, do not generate overly abstract questions with high generalization risk, such as: - Overly broad central-idea questions - Overly broad writing-motivation questions - Overly broad author-attitude summary questions - Overly broad concept-definition questions unless the question is strongly anchored by highly specific, low-ambiguity in-text detai...
-
[21]
gold_evidence_units must be direct quotations from the article; no paraphrasing, no summarizing
-
[22]
doc_id":
Each element in gold_evidence_units must be: {"doc_id": "...", "text": "..."}
-
[23]
core conclusion units the reference answer should cover
gold_claim_units must be written as “core conclusion units the reference answer should cover”—clear, verifiable, and appropriately granular
-
[24]
reference_answer must be concise, definitive, and supportable by gold_evidence_units
-
[25]
gold_claim_units should not merely paraphrase the reference_answer; they should be the genuine core information points that the answer must cover
-
[26]
instances
query, gold_claim_units, and reference_answer must be mutually consistent. IV. Output Format Output only the following JSON structure. No explanations, no Markdown, no code fences. Top-level must be: {"instances": [{"query": "...", "gold_evidence_units": [...], "gold_claim_units": [...], "reference_answer": "..."}]} If the article cannot stably produce hi...
-
[27]
This is single-document; all evidence must come from this article
-
[28]
All doc_id in gold_evidence_units must be: {doc_id}
-
[29]
Query must avoid title leakage and explicit range indicators
-
[33]
Suggested number of instances: up to {instances_per_doc}
reference_answer must be a concise standard answer supportable by the evidence. Suggested number of instances: up to {instances_per_doc}. Full article text: {article_text} Output only JSON. J.2 Multi-Document Generation Prompt Multi-document generation operates in two passes over same-theme document groups: alow-fan- in pass(input: 5 articles, target evid...
-
[34]
thematic_synthesis — Integrate information from multiple articles around the same theme to form an inductive answer
-
[35]
contrastive_reasoning — Organize evidence around two or more objects, cases, or approaches to form a comparative structure
-
[36]
diachronic_evolution — Only permitted when there exist describable stage differences, temporal ordering, and phase-level changes. II. Query Requirements
-
[37]
Query must NOT contain any article titles, title abbreviations, or retrieval hints
-
[38]
the author
Always use “the author”; never use the author’s name
-
[39]
in these articles
Do not use explicit range indicators such as “in these articles”; instead, implicitly delimit scope through combinations of textual details
-
[40]
Each instance must genuinely require multiple articles for joint support; if any single article suffices, do not generate
-
[41]
If a question merely looks like a synthesis question but can actually be answered from one article alone, do not generate
-
[42]
By default, do not generate overly broad questions such as: - How does the author view a certain broad topic - What is the author’s consistent attitude - What does the author advocate long-term unless the query is clearly narrowed by low-ambiguity cross-document details
-
[43]
Queries should preferably ask about concrete phenomena, examples, statements, or judgments that can be directly located across multiple articles, rather than requiring the answerer to construct a grand interpretive framework
-
[44]
The answer should be easily verifiable by different annotators after reading the evidence; if the answer requires extensive literary interpretation or value judgment, do not generate
-
[45]
Details in the query should mainly serve to bound the question, not to pre-reveal the full answer structure
-
[46]
Each query must contain exactly one main question
-
[47]
[Fan-in mode block] Low-fan-in mode: Prioritize generating instances that genuinely depend on 2–3 articles for joint support
Keep query length restrained; given the above requirements, the question should be as concise as possible. [Fan-in mode block] Low-fan-in mode: Prioritize generating instances that genuinely depend on 2–3 articles for joint support. If a question requires 4 or more articles, do not generate in this round. High-fan-in mode: Prioritize generating instances ...
-
[48]
gold_evidence_units must be direct quotations; no paraphrasing
-
[49]
doc_id":
Each element: {"doc_id": "...", "text": "..."}
-
[50]
Evidence must be distributed across the multiple articles that the question actually requires; it must not concentrate in a single article
-
[51]
gold_claim_units must be clear, verifiable, and reflect cross-document induction, comparison, or evolution structure
-
[52]
reference_answer must be concise, definitive, and supportable by the listed evidence
-
[53]
reference_answer may only perform within-evidence induction; do not add unsupported literary interpretation
-
[54]
gold_claim_units should correspond to verifiable information points in the source text
-
[56]
instances
thematic_synthesis and contrastive_reasoning should be roughly equal in quantity. IV. Output Format Output only JSON. Top-level: {"instances": [{"query": "...", "task_type": "...", "gold_evidence_units": [...], "gold_claim_units": [...], "reference_answer": "..."}]} No explanations, no Markdown, no code fences. If the scope of the question is ambiguous, d...
-
[57]
All doc_ids in gold_evidence_units must come from the allowed list above
-
[58]
multiple articles for joint support
Each instance must genuinely require 20 Parameter Value Generation model Claude Opus 4.6 Temperature 0.2 Max generation tokens 24,000 Single-doc instances per article up to 3 Low-fan-in input articles per group 5 High-fan-in input articles per group 8 Low-fan-in instances per group up to 4 High-fan-in instances per group up to 5 Low-fan-in groups per them...
-
[59]
task_type must be one of: thematic_synthesis, contrastive_reasoning, diachronic_evolution
-
[60]
Query must not contain title information or explicit range indicators
-
[61]
the author
Always use “the author” to refer to the writer
-
[62]
gold_evidence_units must be direct quotations
-
[63]
gold_claim_units must be core conclusion units
-
[64]
reference_answer must be a concise standard answer supportable by the evidence
-
[65]
Prefer questions with clear answer boundaries verifiable from the evidence
-
[66]
Suggested number of instances: up to {target_instances}
reference_answer should not over-elaborate; only summarize what the evidence stably supports. Suggested number of instances: up to {target_instances}. Input articles: [For each article: doc_id, doc_title (internal only), full text] Output only JSON. J.3 Generation Configuration Summary Table 9 summarizes the generation hyperparame- ters. K Evaluation Prot...
2023
-
[67]
Text is cleaned by normalizing encoding, col- lapsing whitespace, and standardizing quotation marks
-
[68]
The text is split into sentences at Chinese sentence-ending punctuation (U+3002,U+FF01, U+FF1F,U+FF1B) and paragraph boundaries
-
[69]
Sentences exceeding 180 tokens are hard-split at the token level
-
[70]
Sentences are greedily merged into segments targeting approximately 120 tokens, with a max- imum of 180 tokens and a minimum of 40 to- kens
-
[71]
Trailing segments below the minimum threshold are merged with the preceding segment when the combined length remains under the maxi- mum
-
[72]
Token counting uses a regex-based approxima- tion: each Chinese character counts as one token, 21 and each contiguous Latin alphanumeric string counts as one token
Duplicate segments (by exact string match after normalization) are removed. Token counting uses a regex-based approxima- tion: each Chinese character counts as one token, 21 and each contiguous Latin alphanumeric string counts as one token. The maximum number of pre- dicted evidence segments submitted to the judge per instance is capped at 2,000. K.3 Answ...
-
[73]
Analyze the coverage of each gold_claim_unit (for diagnostics)
-
[74]
claim_judgments
Assign a holistic 0–3 score based on the rubric (the final metric). When scoring, you must consider two dimensions simultaneously: - Dimension A: Coverage of gold claims. - Dimension B: Whether the answer contains irrelevant, incorrect, or redundant content. Output only JSON. Do not output anything else. User prompt template. Please evaluate the quality o...
-
[75]
Evidence Recall: Only assess whether gold evidence is covered by the predicted context
-
[76]
Evidence Precision: Only assess whether predicted evidence matches gold evidence
-
[77]
Do not conflate answer correctness with evidence quality
-
[78]
User prompt template
Output only JSON. User prompt template. Please determine: Is the given gold evidence unit covered by the predicted context? Coverage criteria:
-
[79]
Verbatim identity is not required
-
[80]
Longer excerpts, shorter excerpts, or essentially equivalent source passages are acceptable
-
[81]
As long as the predicted context contains a passage sufficient to carry the key information of this gold evidence, judge as covered=1
-
[82]
covered": 0 or 1,
Otherwise covered=0. [Query] {query} [Gold Evidence Unit] {gold_evidence_unit_json} [Predicted Context Pack] {predicted_context_pack_json} Please output only JSON: {"covered": 0 or 1, "reason": "one sentence explanation"} Evidence Recall is computed as: ER= P|E⋆| i=1 coveredi |E⋆| ×100%.(4) K.5 Evidence Precision (EP) Judge The EP judge determines whether...
-
[83]
matched = 1: The predicted evidence unit can be aligned with, covers, or is essentially equivalent to at least one entry in gold_evidence_units
-
[84]
matched = 0: The predicted evidence unit cannot be aligned with any gold evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.