MTLLFM: Multimodal-Temporal Laughter Localization: UR-FUNNY-Temporal and SMILE-Temporal Benchmarks with an Adaptive Multimodal Fusion Model
Pith reviewed 2026-06-29 23:00 UTC · model grok-4.3
The pith
A weakly-supervised multimodal model learns precise laughter timing from clip-level labels alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
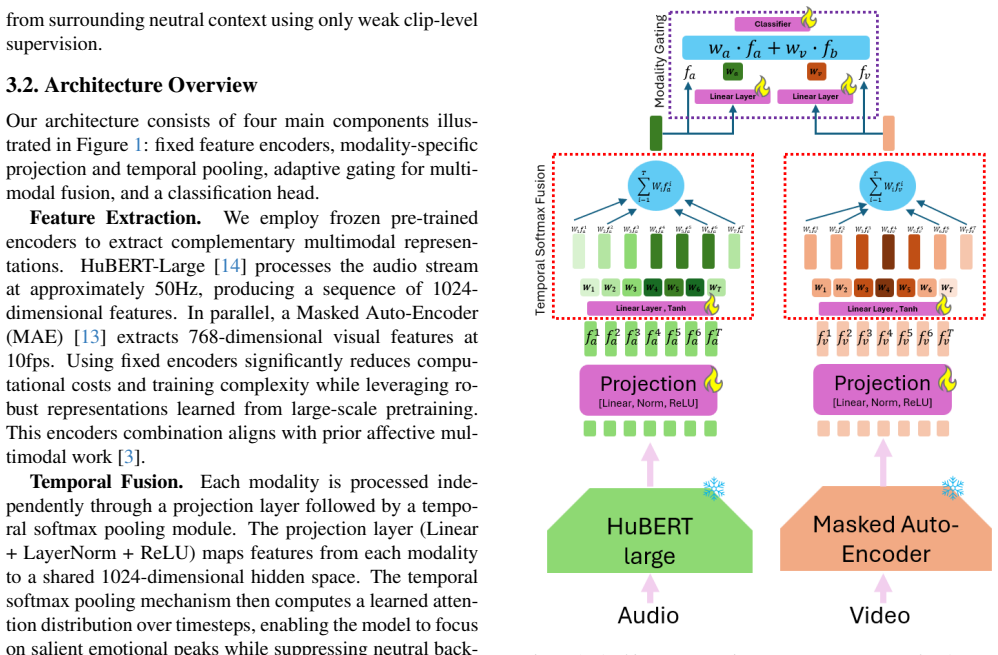
The central discovery is that an architecture combining fixed HuBERT and MAE encoders, temporal softmax pooling, and adaptive modality gating can learn fine-grained temporal localization of laughter events from clip-level supervision, achieving 99% F1 score and 68.1% localization precision on sports broadcast data while outperforming models such as Gemini 3 Flash, and that supplying these temporal tags to GPT-3.5 improves its laughter reasoning CIDEr score by 227% over using GPT-4o without them.
What carries the argument
The adaptive modality gating mechanism together with temporal softmax pooling, which selects and fuses acoustic and visual features over time to produce precise onset and offset predictions from coarse labels.
If this is right
- Precise temporal laughter tags improve downstream laughter reasoning performance by 227% on CIDEr, allowing GPT-3.5 to surpass GPT-4o.
- The model achieves 99% F1 and 68.1% localization precision on sports broadcast data.
- Each architectural component, including the encoders, pooling, and gating, contributes to the overall performance as shown by ablations.
- The new temporal datasets cover speaker vs audience laughter, modality dominance, and intensity levels across 78.8 hours of video.
Where Pith is reading between the lines
- Similar weakly-supervised techniques could reduce the need for expensive frame-level annotations in other short-duration event localization tasks such as detecting applause or key gestures.
- The datasets provide rich metadata that could support studies on how laughter intensity or speaker identity affects multimodal fusion.
- Applying the same architecture to other affective computing domains might reveal whether clip-level supervision generalizes beyond laughter.
- Improved temporal grounding could enhance narrative understanding systems that rely on timing of emotional responses in media.
Load-bearing premise
Clip-level supervision alone is sufficient for a model to learn accurate fine-grained temporal boundaries for brief, transient laughter events without any frame-level annotations during training.
What would settle it
Running the model on a new set of videos that have independent frame-level human annotations for laughter onsets and offsets, then measuring if the predicted boundaries align closely with those annotations rather than just matching clip labels.
Figures

read the original abstract
Detecting laughter in video is essential for affective computing and narrative understanding, yet existing approaches treat it as coarse clip-level classification, failing to capture precise temporal boundaries of brief, transient laughter events. We address this gap with two complementary contributions. First, we introduce UR-FUNNY-Temporal and SMILE-Temporal, fully annotated temporal laughter datasets extending two widely-used humor benchmarks. Our annotations cover over 11,053 videos (78.8 hours) and provide precise onset/offset boundaries for each laughter event, along with rich metadata distinguishing speaker vs. audience laughter, modality dominance (acoustic, visual, or both), and intensity levels. Second, we propose a lightweight weakly-supervised framework for temporal laughter localization. Our architecture combines fixed HuBERT and MAE encoders with temporal softmax pooling and adaptive modality gating, learning fine-grained temporal grounding from clip-level labels without requiring frame-level annotations during training. Experiments across three datasets demonstrate that our approach substantially outperforms multimodal foundation models including Gemini 3 Flash, achieving 99% F1 and 68.1% localization precision on sports broadcast data. Ablations validate each architectural component. Furthermore, our precise temporal tags improve downstream laughter reasoning by 227% on CIDEr, enabling GPT-3.5 to outperform GPT-4o. The code, UR-FUNNY-Temporal and SMILE-Temporal datasets are publicly available at https://github.com/WSCSports/MTLLFM-temporal-laughter-localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UR-FUNNY-Temporal and SMILE-Temporal, two new datasets extending existing humor benchmarks with frame-level onset/offset annotations for laughter events across 11,053 videos (78.8 hours), including metadata on speaker vs. audience, modality dominance, and intensity. It proposes a weakly-supervised multimodal architecture using fixed HuBERT and MAE encoders, temporal softmax pooling, and adaptive modality gating to perform fine-grained temporal localization from clip-level labels alone. Experiments claim the model achieves 99% F1 and 68.1% localization precision on sports broadcast data, outperforming multimodal foundation models such as Gemini 3 Flash, with ablations supporting each component; additionally, the precise tags yield a 227% CIDEr gain in downstream laughter reasoning, allowing GPT-3.5 to surpass GPT-4o. Code and datasets are released publicly.
Significance. If the central performance claims hold under proper validation, the work would be significant for affective computing and multimodal video understanding: the new temporally annotated benchmarks address a gap in fine-grained laughter localization, and the weakly-supervised approach with adaptive fusion could provide a lightweight alternative to foundation models for transient event detection. Public release of data and code strengthens reproducibility.
major comments (2)
- [Experiments / Model evaluation] The central claim of 68.1% localization precision (and 99% F1) from clip-level supervision alone depends on the temporal softmax pooling learning accurate sub-clip boundaries for brief, sparse laughter events. No explicit check is reported that the learned attention maps align with the newly introduced frame-level annotations on held-out portions of UR-FUNNY-Temporal or SMILE-Temporal; without this, it remains possible that the model collapses to clip-level decisions rather than true temporal grounding.
- [Downstream task evaluation] The 227% CIDEr improvement on downstream laughter reasoning (enabling GPT-3.5 to outperform GPT-4o) is load-bearing for the utility claim. Details are needed on the exact prompting format used to inject the temporal tags, the number of test instances, and the full baseline comparison setup including GPT-4o variants.
minor comments (1)
- [Abstract / Results] Clarify the exact version of the Gemini model referenced (listed as 'Gemini 3 Flash') and confirm whether all reported metrics include standard deviations or confidence intervals across multiple runs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and validation.
read point-by-point responses
-
Referee: [Experiments / Model evaluation] The central claim of 68.1% localization precision (and 99% F1) from clip-level supervision alone depends on the temporal softmax pooling learning accurate sub-clip boundaries for brief, sparse laughter events. No explicit check is reported that the learned attention maps align with the newly introduced frame-level annotations on held-out portions of UR-FUNNY-Temporal or SMILE-Temporal; without this, it remains possible that the model collapses to clip-level decisions rather than true temporal grounding.
Authors: We agree that an explicit validation of attention map alignment with held-out frame-level annotations would strengthen the temporal grounding claim. The reported localization precision is measured on sports broadcast data with independent temporal annotations, but we did not include a direct comparison on held-out splits of UR-FUNNY-Temporal and SMILE-Temporal. In the revision we will add quantitative metrics (e.g., temporal IoU, boundary F1 at multiple thresholds) and qualitative examples comparing the model's softmax attention maps against the ground-truth onset/offset labels on held-out portions of both datasets. This analysis will confirm whether the model learns genuine sub-clip boundaries or defaults to clip-level behavior. revision: yes
-
Referee: [Downstream task evaluation] The 227% CIDEr improvement on downstream laughter reasoning (enabling GPT-3.5 to outperform GPT-4o) is load-bearing for the utility claim. Details are needed on the exact prompting format used to inject the temporal tags, the number of test instances, and the full baseline comparison setup including GPT-4o variants.
Authors: We acknowledge that the downstream evaluation section requires more implementation details for full reproducibility. In the revised manuscript we will expand this section to specify: the exact prompt templates used to incorporate the temporal tags, the precise number of test instances evaluated, and a complete baseline table that includes multiple GPT-4o prompting variants (zero-shot, few-shot, and tag-augmented) in addition to the GPT-3.5 results already reported. These additions will allow readers to assess the robustness of the 227% CIDEr gain. revision: yes
Circularity Check
No circularity: empirical metrics on new annotations are measured outcomes
full rationale
The paper introduces new temporally annotated datasets (UR-FUNNY-Temporal, SMILE-Temporal) and reports measured F1, localization precision, and downstream CIDEr gains from a weakly-supervised model trained on clip-level labels. No equations are presented that reduce the reported metrics to fitted parameters by construction, nor does any load-bearing claim rest on a self-citation chain or self-definitional ansatz. The architecture (fixed encoders + temporal softmax pooling + gating) is described as a design choice whose performance is validated by ablation and external comparison; the results remain falsifiable against the public code and held-out annotations. This is the standard non-circular case for empirical ML work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gated Multimodal Units for Information Fusion
John Arevalo, Thamar Solorio, Manuel Montes-y G ´omez, and Fabio A. Gonz ´alez. Gated multimodal units for infor- mation fusion.arXiv preprint arXiv:1702.01992, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
StandUp4AI: A new multilin- gual dataset for humor detection in stand-up comedy videos
Valentin Barriere, Nahuel Gomez, Leo Hemamou, Sofia Callejas, and Brian Ravenet. StandUp4AI: A new multilin- gual dataset for humor detection in stand-up comedy videos. InFindings of the Association for Computational Linguis- tics: EMNLP 2025, pages 16951–16959, 2025. 4
2025
-
[3]
Hauptmann
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Chen, Yuxiang Peng, Zheng Lian, and Alexander G. Hauptmann. Emotion-llama: Multimodal emotion recogni- tion and reasoning with instruction tuning. InAdvances in Neural Information Processing Systems, 2024. 3
2024
-
[4]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhi- fang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Jingren Chang, and Chang Zhou. Qwen2-audio techni- cal report.arXiv preprint arXiv:2407.10759, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Toward ex- plainable affective computing: A review.IEEE Transactions on Neural Networks and Learning Systems, 35(10):13101– 13121, 2023
Karina Corti ˜nas-Lorenzo and Gerard Lacey. Toward ex- plainable affective computing: A review.IEEE Transactions on Neural Networks and Learning Systems, 35(10):13101– 13121, 2023. 1
2023
-
[6]
Bcfnet: Bi-temporal collabo- rative fusion network for multi-modal humor detection.Pat- tern Recognition, page 112744, 2025
Boya Deng, Jianzhao Li, Maoguo Gong, Yourun Zhang, Kaiyuan Feng, Yue Wu, et al. Bcfnet: Bi-temporal collabo- rative fusion network for multi-modal humor detection.Pat- tern Recognition, page 112744, 2025. 1
2025
-
[7]
Multi-modal laughter recognition in video conversations
Sergio Escalera, Eloi Puertas, Petia Radeva, and Oriol Pu- jol. Multi-modal laughter recognition in video conversations. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 110–115, 2009. 2
2009
-
[8]
Fef-net: feature enhanced fusion network with crossmodal attention for mul- timodal humor prediction.Multimedia Systems, 30(4):195,
Peng Gao, Chuanqi Tao, and Donghai Guan. Fef-net: feature enhanced fusion network with crossmodal attention for mul- timodal humor prediction.Multimedia Systems, 30(4):195,
-
[9]
Audio set: An ontology and human- labeled dataset for audio events
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human- labeled dataset for audio events. In2017 IEEE interna- tional conference on acoustics, speech and signal processing (ICASSP), pages 776–780. IEEE, 2017. 4
2017
-
[10]
Switchboard: Telephone speech corpus for research and de- velopment
John J Godfrey, Edward C Holliman, and Jane McDaniel. Switchboard: Telephone speech corpus for research and de- velopment. In[Proceedings] ICASSP-92: 1992 IEEE Inter- national Conference on Acoustics, Speech, and Signal Pro- cessing, pages 517–520. IEEE, 1992. 4
1992
-
[11]
Ur-funny: A multimodal language dataset for un- derstanding humor
Md Kamrul Hasan, Wasifur Rahman, Amir Bagher Zadeh, Jiajun Zhong, Md Iftekhar Tanveer, and Louis-Philippe Morency. Ur-funny: A multimodal language dataset for un- derstanding humor. InEMNLP, 2019. 2, 4
2019
-
[12]
Misa: Modality-invariant and -specific representations for multimodal sentiment analysis
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. Misa: Modality-invariant and -specific representations for multimodal sentiment analysis. InProceedings of the 28th ACM International Conference on Multimedia, pages 1122–1131, 2020. 2
2020
-
[13]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022. 3, 6
2022
-
[14]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021. 3, 6
2021
-
[15]
Lita: Language instructed temporal-localization assistant
De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. Lita: Language instructed temporal-localization assistant. In European Conference on Computer Vision, pages 202–218. Springer, 2024. 8
2024
-
[16]
Smile: Multimodal dataset for understand- ing laughter in video with language models
Lee Hyun, Kim Sung-Bin, Seungju Han, Youngjae Yu, and Tae-Hyun Oh. Smile: Multimodal dataset for understand- ing laughter in video with language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 1149–1167, 2024. 2, 4, 6
2024
-
[17]
D-humor: Dark hu- mor understanding via multimodal open-ended reasoning
Sai Kartheek Reddy Kasu, Mohammad Zia Ur Rehman, Shahid Shafi Dar, Rishi Bharat Junghare, Dhanvin Sanjay Namboodiri, and Nagendra Kumar. D-humor: Dark hu- mor understanding via multimodal open-ended reasoning. In2025 IEEE International Conference on Data Mining (ICDM), pages 377–386. IEEE, 2025. 1
2025
-
[18]
Abaw: Valence-arousal estimation, ex- pression recognition, action unit detection & multi-task learning challenges
Dimitrios Kollias. Abaw: Valence-arousal estimation, ex- pression recognition, action unit detection & multi-task learning challenges. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops, pages 2328–2336, 2022. 2
2022
-
[19]
Multimodal and multilingual laughter detection in stand-up comedy videos
Anna Kuznetsova and Carlo Strapparava. Multimodal and multilingual laughter detection in stand-up comedy videos. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pages 11884–11889, 2024. 4
2024
-
[20]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017. 3, 6
2017
-
[21]
Funnynet-w: Multimodal learning of funny moments in videos in the wild.International Journal of Computer Vi- sion, 132(8):2885–2906, 2024
Zhi-Song Liu, Robin Courant, and Vicky Kalogeiton. Funnynet-w: Multimodal learning of funny moments in videos in the wild.International Journal of Computer Vi- sion, 132(8):2885–2906, 2024. 1
2024
-
[22]
Weakly supervised action localization by sparse temporal pooling network
Phuc Nguyen, Ting Liu, Gautam Prasad, and Bohyung Han. Weakly supervised action localization by sparse temporal pooling network. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6752–6761, 2018. 3, 4
2018
-
[23]
Affective computing: Recent advances, challenges, and future trends.Intelligent Computing, 3:0076,
Guanxiong Pei, Haiying Li, Yandi Lu, Yanlei Wang, Shizhen Hua, and Taihao Li. Affective computing: Recent advances, challenges, and future trends.Intelligent Computing, 3:0076,
-
[24]
Fusion of audio and vi- sual cues for laughter detection
Stavros Petridis and Maja Pantic. Fusion of audio and vi- sual cues for laughter detection. InProceedings of the 7th ACM International Conference on Image and Video Re- trieval, pages 329–336, 2008. 2
2008
-
[25]
A review of affective computing: From unimodal anal- ysis to multimodal fusion.Information fusion, 37:98–125,
Soujanya Poria, Erik Cambria, Rajiv Bajpai, and Amir Hus- sain. A review of affective computing: From unimodal anal- ysis to multimodal fusion.Information fusion, 37:98–125,
-
[26]
Integrating multimodal information in large pretrained transformers
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. Integrating multimodal information in large pretrained transformers. InProceedings of the 58th An- nual Meeting of the Association for Computational Linguis- tics, pages 2359–2369, Online, 2020. Association for Com- putational Linguistics. 2
2020
-
[27]
Multimodal emotion recognition: A comprehensive review, trends, and challenges.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 14(6):e1563, 2024
Manju Priya Arthanarisamy Ramaswamy and Suja Palaniswamy. Multimodal emotion recognition: A comprehensive review, trends, and challenges.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 14(6):e1563, 2024. 1
2024
-
[28]
Computational understanding of narratives: A survey
Priyanka Ranade, Sanorita Dey, Anupam Joshi, and Tim Finin. Computational understanding of narratives: A survey. IEEE Access, 10:101575–101594, 2022. 1
2022
-
[29]
Yuntao Shou, Tao Meng, Wei Ai, and Keqin Li. Multimodal large language models meet multimodal emotion recognition and reasoning: A survey.arXiv preprint arXiv:2509.24322,
-
[30]
Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6558– 6569, Florence, Italy, 2019. Association for Computational Linguistics. 2
2019
-
[32]
Multimodal emotion recognition using visual, vocal and physiological signals: a review.Applied Sciences, 14(17): 8071, 2024
Gustave Udahemuka, Karim Djouani, and Anish M Kurien. Multimodal emotion recognition using visual, vocal and physiological signals: a review.Applied Sciences, 14(17): 8071, 2024. 1
2024
-
[33]
Deep learning-based action detection in untrimmed videos: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4302– 4320, 2022
Elahe Vahdani and Yingli Tian. Deep learning-based action detection in untrimmed videos: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4302– 4320, 2022. 1
2022
-
[34]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017. 1, 6
2017
-
[35]
Untrimmednets for weakly supervised action recognition and detection
Limin Wang, Yuanjun Xiong, Zhe Wang, and Yu Qiao. Untrimmednets for weakly supervised action recognition and detection. InCVPR, 2017. 2
2017
-
[36]
Jin Xu, Zhifang Chen, Cheng Zhu, et al. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Weakly supervised graph learning for action recog- nition in untrimmed video.The Visual Computer, 39(11): 5469–5483, 2023
Xiao Yao, Jia Zhang, Ruixuan Chen, Dan Zhang, and Yifeng Zeng. Weakly supervised graph learning for action recog- nition in untrimmed video.The Visual Computer, 39(11): 5469–5483, 2023. 1
2023
-
[38]
Tensor fusion network for mul- timodal sentiment analysis
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Tensor fusion network for mul- timodal sentiment analysis. InProceedings of the 2017 Con- ference on Empirical Methods in Natural Language Process- ing, pages 1103–1114, Copenhagen, Denmark, 2017. Asso- ciation for Computational Linguistics. 2
2017
-
[39]
Twinnet: twin structured knowledge transfer network for weakly supervised action localization.Machine Intelli- gence Research, 19(3):227–246, 2022
Xiao-Yu Zhang, Hai-Chao Shi, Chang-Sheng Li, and Li-Xin Duan. Twinnet: twin structured knowledge transfer network for weakly supervised action localization.Machine Intelli- gence Research, 19(3):227–246, 2022. 1
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.