HyLaT: Efficient Multi-Agent Communication via Hybrid Latent-Text Protocol
Pith reviewed 2026-06-29 22:28 UTC · model grok-4.3
The pith
HyLaT lets LLM-based agents send most cognitive signals in compact latent form while keeping critical details in readable text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
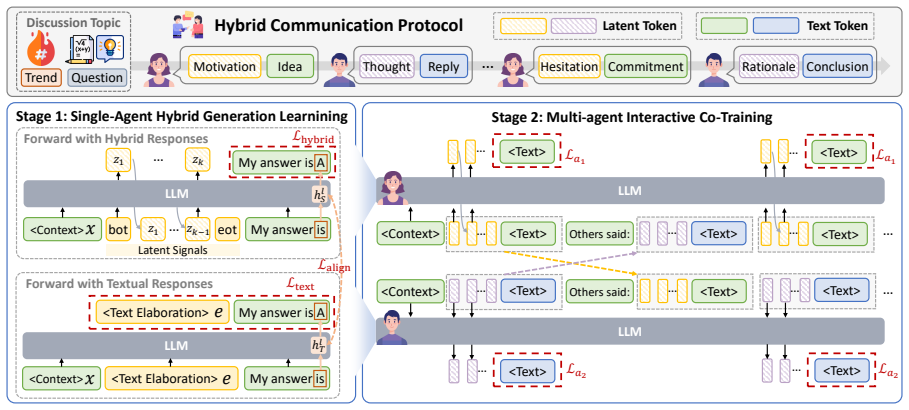
HyLaT transmits elaborate cognitive signals through a latent channel for efficiency while expressing concise critical signals in natural language to preserve interpretability and precision, using a two-stage training framework that first performs single-agent hybrid generation learning and then multi-agent interactive co-training so agents can generate and interpret hybrid messages across multiple rounds of interaction.
What carries the argument
The hybrid latent-text protocol, which routes bulk cognitive content through the latent channel and only essential signals through text.
If this is right
- Agent teams can sustain longer dialogues before hitting token budgets.
- Task performance stays comparable to single-channel baselines across varied environments.
- Human overseers can inspect the text portions of messages to understand key decisions.
- The protocol supports repeated back-and-forth exchanges without collapse into opacity.
- Generalization holds when the same agents are moved to new task domains.
Where Pith is reading between the lines
- The split-channel design could be tested in settings where one agent must explain its reasoning to a human after several latent exchanges.
- If latent spaces of different model families can be aligned, the same protocol might enable cross-model agent teams without full text translation.
- Lower per-message cost opens the possibility of running larger numbers of agents on the same compute budget.
Load-bearing premise
The two-stage training lets agents reliably split information across latent and text channels without losing essential content over repeated interaction rounds.
What would settle it
Run a multi-round collaborative task with three matched agent teams (HyLaT, text-only, latent-only) and measure total tokens used plus final task success rate; if HyLaT does not use substantially fewer tokens while matching or exceeding the success rate of the baselines, the central claim does not hold.
Figures




read the original abstract
Communication protocol design is a central challenge in large language model-based multi-agent systems. Existing single-channel approaches face an inherent communication trilemma: text-based methods are interpretable but verbose, while latent-space methods are efficient but opaque and limited to unidirectional workflows. Inspired by multi-channel communication theory, we propose HyLaT, a hybrid latent-text communication protocol that transmits elaborate cognitive signals through a latent channel for efficiency, while expressing concise critical signals in natural language to preserve interpretability and precision. We introduce a two-stage training framework combining single-agent hybrid generation learning and multi-agent interactive co-training, enabling agents to generate and interpret hybrid messages across multiple rounds of interaction. Experiments demonstrate that HyLaT reduces communication overhead significantly while maintaining competitive task performance, with strong generalization and robustness across diverse settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyLaT, a hybrid latent-text communication protocol for LLM-based multi-agent systems that transmits elaborate cognitive signals via a latent channel for efficiency while using natural language for concise critical signals to preserve interpretability. It introduces a two-stage training framework (single-agent hybrid generation learning followed by multi-agent interactive co-training) to enable multi-round hybrid message generation and interpretation. The central claim is that this approach reduces communication overhead significantly while maintaining competitive task performance, with strong generalization and robustness across diverse settings.
Significance. If the experimental results hold under scrutiny, the work addresses a relevant trilemma in multi-agent LLM communication by combining efficiency and interpretability, potentially advancing practical deployment of such systems. No machine-checked proofs, reproducible code, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments demonstrate that HyLaT reduces communication overhead significantly while maintaining competitive task performance' supplies no details on experimental setup, baselines, metrics, error bars, datasets, or ablation studies, preventing verification that the data supports the central claim of reduced overhead without critical information loss.
- [Abstract] The weakest assumption—that the two-stage training enables agents to generate and interpret hybrid messages across multiple rounds without critical information loss in the latent channel—is stated at a high level without quantitative metrics on information preservation or ablation results isolating the contribution of each training stage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional details will strengthen the presentation of our claims and will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments demonstrate that HyLaT reduces communication overhead significantly while maintaining competitive task performance' supplies no details on experimental setup, baselines, metrics, error bars, datasets, or ablation studies, preventing verification that the data supports the central claim of reduced overhead without critical information loss.
Authors: We agree the abstract would benefit from greater specificity. In the revised version we will expand the abstract to specify the experimental setup (multi-agent task environments including collaborative reasoning and negotiation benchmarks), baselines (pure text-based and pure latent-space protocols), metrics (communication overhead in average tokens per message and bits per latent vector; task performance via success rate and efficiency ratio), error bars (standard deviation over 5 random seeds), and reference to ablation studies on the hybrid channel. revision: yes
-
Referee: [Abstract] The weakest assumption—that the two-stage training enables agents to generate and interpret hybrid messages across multiple rounds without critical information loss in the latent channel—is stated at a high level without quantitative metrics on information preservation or ablation results isolating the contribution of each training stage.
Authors: We acknowledge that the abstract states the two-stage training at a high level. We will revise the abstract to include quantitative metrics on information preservation (latent reconstruction fidelity and downstream task accuracy when the latent channel is ablated) and to note the ablation results that isolate the single-agent hybrid generation stage from the multi-agent interactive co-training stage. These metrics and ablations appear in Sections 4.3 and 5.2 of the full manuscript; we will surface the key numbers in the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, fitted parameters, self-citations, or derivation steps that reduce to inputs by construction. The two-stage training framework and hybrid protocol are described conceptually as a proposed method, with performance claims tied to experiments rather than any self-definitional or fitted-input prediction. No load-bearing elements match the enumerated circularity patterns, and the central claims remain independent of the inputs in the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pages 10626–10641
Beyond natural language: Llms leveraging alternative formats for enhanced rea- soning and communication. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, pages 10626–10641. Weize Chen, Jiarui Yuan, Chen Qian, Cheng Yang, Zhiyuan Liu, and Maosong Sun
2024
-
[2]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 11534–11557
Optima: Op- timizing effectiveness and efficiency for llm-based multi-agent system. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11534–11557. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord
2025
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question an- swering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457. Francois Cochard, Phu Nguyen Van, and Marc Willinger
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Improving factual- ity and reasoning in language models through multia- gent debate.arXiv preprint arXiv:2305.14325. Zhuoyun Du, Runze Wang, Huiyu Bai, Zouying Cao, Xiaoyong Zhu, Yu Cheng, Bo Zheng, Wei Chen, and Haochao Ying
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Enabling Agents to Communicate Entirely in Latent Space
Enabling agents to com- municate entirely in latent space.arXiv preprint arXiv:2511.09149. Tianyu Fu, Zihan Min, Hanling Zhang, Jichao Yan, Guohao Dai, Wanli Ouyang, and Yu Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant
Cache-to-cache: Direct semantic communication between large language models.arXiv preprint arXiv:2510.03215. Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant
-
[7]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xi- angliang Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680. Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a contin- uous latent space.arXiv preprint arXiv:2412.06769. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
InPro- ceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)
Worldtree: A corpus of explanation graphs for elementary science questions supporting multi-hop inference. InPro- ceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits
2018
-
[11]
Pubmedqa: A dataset for biomedical research question answering. InProceed- ings of the 2019 conference on empirical methods in natural language processing and the 9th interna- tional joint conference on natural language process- ing (EMNLP-IJCNLP), pages 2567–2577. Angeliki Lazaridou and Marco Baroni
2019
-
[12]
arXiv preprint arXiv:2006.02419
Emergent multi-agent communication in the deep learning era. arXiv preprint arXiv:2006.02419. Samuele Marro, Emanuele La Malfa, Jesse Wright, Guo- hao Li, Nigel Shadbolt, Michael Wooldridge, and Philip Torr
-
[13]
Peter R Monge and Noshir S Contractor
A scalable communication pro- tocol for networks of large language models.arXiv preprint arXiv:2410.11905. Peter R Monge and Noshir S Contractor. 2003.Theo- ries of communication networks. Oxford University Press, USA. Xinyi Mou, Xuanwen Ding, Qi He, Liang Wang, Jing- cong Liang, Xinnong Zhang, Libo Sun, Jiayu Lin, Jie Zhou, Xuanjing Huang, and 1 others. ...
-
[14]
Xinyi Mou, Zhongyu Wei, and Xuan-Jing Huang
Ecolang: Efficient and effective agent communication language induction for social simulation.arXiv preprint arXiv:2505.06904. Xinyi Mou, Zhongyu Wei, and Xuan-Jing Huang. 2024b. Unveiling the truth and facilitating change: Towards agent-based large-scale social movement simulation. InFindings of the Association for Computational Linguistics: ACL 2024, pa...
-
[15]
Let models speak ci- phers: Multiagent debate through embeddings.arXiv preprint arXiv:2310.06272. Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, and 1 others. 2024a. Chatdev: Com- municative agents for software development. InPro- ceedings of the 62nd annual meeting of the associa- tion fo...
-
[16]
Social iqa: Com- monsense reasoning about social interactions. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473. Claude Elwood Shannon
2019
-
[17]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 677–693
Codi: Compress- ing chain-of-thought into continuous space via self- distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 677–693. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 oth- ers
2025
-
[18]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267. Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Commonsenseqa: A question answering challenge targeting commonsense knowl- edge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers), pages 4149–4158. Yichen Tang, Weihang Su, Yujia Zhou, Yiqun Liu, Min Zhang, Shaoping Ma, and Q...
2019
-
[20]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10230–10251
Aug- menting multi-agent communication with state delta trajectory. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10230–10251. Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang, Xipeng Qiu, and Dahua Lin
2025
-
[21]
Shiguang Wu, Yaqing Wang, and Quanming Yao
Sim-cot: Supervised implicit chain-of- thought.arXiv preprint arXiv:2509.20317. Shiguang Wu, Yaqing Wang, and Quanming Yao
-
[22]
Language Model Networks: Supervision-Efficient Learning through Dense Communication
Dense communication between language models. arXiv preprint arXiv:2505.12741. Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Can large lan- guage model agents simulate human trust behavior? arXiv preprint arXiv:2402.04559. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D Manning
-
[24]
InProceedings of the 2018 conference on empiri- cal methods in natural language processing, pages 2369–2380
Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empiri- cal methods in natural language processing, pages 2369–2380. Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jef- frey Xu Yu, and Tianlong Chen
2018
-
[25]
Cut the crap: An economical communication pipeline for llm-based multi-agent systems.arXiv preprint arXiv:2410.02506. Xinnong Zhang, Jiayu Lin, Xinyi Mou, Shiyue Yang, Xiawei Liu, Libo Sun, Hanjia Lyu, Yihang Yang, Weihong Qi, Yue Chen, and 1 others
-
[26]
Socio- verse: A world model for social simulation powered by llm agents and a pool of 10 million real-world users.arXiv preprint arXiv:2504.10157. Jiaru Zou, Xiyuan Yang, Ruizhong Qiu, Gaotang Li, Katherine Tieu, Pan Lu, Ke Shen, Hanghang Tong, Yejin Choi, Jingrui He, and 1 others
-
[27]
Latent collaboration in multi-agent systems.arXiv preprint arXiv:2511.20639. A Supplemented Implementation Details A.1 Training Data Details Datasets of Stage 1To support hybrid communi- cation, Stage 1 training requires data that naturally exhibits the two-part structure of HyLaT’s output: an elaborate cognitive signal encoding dense inter- mediate reaso...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
(1)Refinement: In this setting, agents independently answer the same question in parallel and iteratively refine their responses through discussion
Datasets of Stage 2To support multi-round multi-agent communication, we construct train- ing data through multi-agent debate simulation along two complementary axes. (1)Refinement: In this setting, agents independently answer the same question in parallel and iteratively refine their responses through discussion. To ensure that inter- agent communication ...
2018
-
[29]
A.2 Evaluation Details We implement all the multi-agent communication experiments using the framework provided by Tang et al. (2025). Following them, for datasets with Dataset Type # samples CommonsenseQA (Talmor et al., 2019)commonsense reasoning3,600StrategyQA (Geva et al., 2021)commonsense reasoning1,800SocialIQA (Sap et al., 2019)social reasoning 1,80...
2025
-
[30]
Round 1: Initial Prompt Please answer the following question:{question} First explain your reasoning, and provide your final answer in the form \boxed{answer}, at the end of your response. Roundt >1: Multi-Agent Interaction Prompt These are the solutions from other agents: One agent’s response:ˋˋˋ{agent_response}ˋˋˋ [repeated for each other agent] Using t...
2021
-
[31]
For Stage 2 training, we only supervise on the last turn, considering that the intermediate con- clusions can be incorrect in the refinement data. Method In-Domain Out-of-Domain InferenceEfficiencyCommonsense StrategyQA SocialIQA WorldTree PubMedQAMedQA ARC-E ARC-CAvg. Maj. Avg. Maj. Avg. Maj. Avg. Maj. Avg. Maj.Avg. Maj. Avg. Maj. Avg. Maj.# token time T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.