CODESKILL: Learning Self-Evolving Skills for Coding Agents
Pith reviewed 2026-06-29 22:01 UTC · model grok-4.3
The pith
CODESKILL trains a reinforcement learning policy to extract and maintain reusable skills from coding agent trajectories, raising task success rates while keeping the skill bank stable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
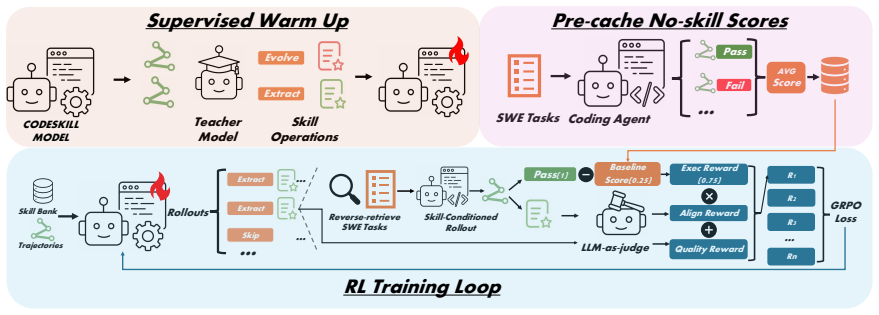
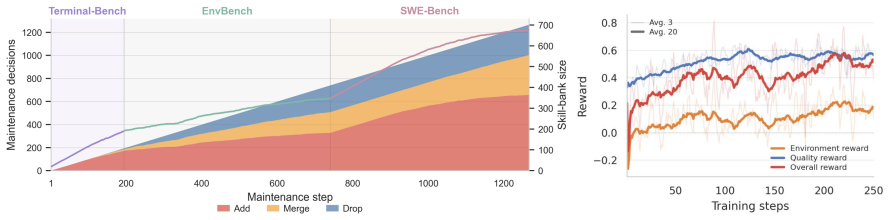
CODESKILL reformulates skill extraction and skill-bank maintenance as a learnable management policy. The policy is trained with reinforcement learning using a hybrid reward that combines dense rubric-based skill-quality feedback with sparse verifiable execution feedback from the frozen downstream agent. It extracts multi-granularity procedural skills from trajectories, evolves them with new experience, and maintains a compact bank, producing average pass-rate improvements of 9.69 over the no-skill baseline and 4.01 over the strongest prompt-based or memory baseline on EnvBench, SWE-Bench Verified, and Terminal-Bench 2 while holding bank size stable during iterative construction.
What carries the argument
A reinforcement learning management policy that decides when and how to extract, evolve, and retain multi-granularity procedural skills from agent trajectories using hybrid quality-plus-execution rewards.
If this is right
- Downstream agents using the maintained skill bank complete more tasks on software-engineering benchmarks.
- The skill bank remains compact and stable in size across repeated construction cycles.
- The learned policy outperforms both no-skill setups and strong fixed-prompt or memory baselines by measurable margins.
- Multi-granularity skills support tasks of varying complexity without manual abstraction rules.
Where Pith is reading between the lines
- The same policy-learning approach could be tested on agent domains outside coding, such as web interaction or scientific workflows.
- Hybrid rewards may reduce reliance on purely human-curated skill labels by leveraging execution signals.
- If the policy transfers across task distributions, deployed agents could keep improving their skill banks without periodic full retraining.
Load-bearing premise
The hybrid reward from skill-quality rubrics and downstream execution success is sufficient to train a policy whose extracted skills genuinely improve agent performance on new tasks rather than merely fitting the training distribution.
What would settle it
Retraining the management policy on fresh trajectories and finding that the resulting skill bank either grows substantially in size or produces downstream pass rates no higher than the no-skill baseline on the same benchmarks would falsify the central claim.
Figures












read the original abstract
Coding agents produce rich trajectories while solving software-engineering tasks. To enable agent self-evolution, these trajectories can be distilled into reusable procedural skills that compactly encode experience to guide future behavior. However, existing skill construction and maintenance methods often rely on fixed prompts and heuristic update rules, leaving it unclear how knowledge should be selected, abstracted, and maintained to best serve downstream agents. We propose CODESKILL, an LLM-based framework that reformulates skill extraction and skill-bank maintenance as a learnable management policy. CODESKILL extracts multi-granularity procedural skills from coding-agent trajectories, evolves skills with new experience, and maintains a compact skill bank for future task solving. We train CODESKILL with reinforcement learning, using a hybrid reward that combines dense rubric-based skill-quality feedback with sparse verifiable execution feedback from the frozen downstream agent. Experiments on EnvBench, SWE-Bench Verified, and Terminal-Bench 2 show that CODESKILL improves average pass rate by 9.69 over the no-skill baseline and by 4.01 over the strongest prompt-based or memory baseline, while maintaining the skill bank at a stable size during iterative construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CODESKILL, an LLM-based framework that reformulates skill extraction and skill-bank maintenance as a learnable management policy trained via reinforcement learning. It extracts multi-granularity procedural skills from coding-agent trajectories, evolves them with new experience, and maintains a compact skill bank. Training uses a hybrid reward combining dense rubric-based skill-quality feedback with sparse execution feedback from a frozen downstream agent. Experiments on EnvBench, SWE-Bench Verified, and Terminal-Bench 2 report average pass-rate gains of 9.69 over a no-skill baseline and 4.01 over the strongest prompt-based or memory baseline, while keeping the skill bank size stable.
Significance. If the central claim holds after proper controls, the work would provide a concrete, learnable alternative to heuristic skill management in coding agents, with potential for broader self-evolution pipelines. The hybrid-reward formulation and reported stability of the skill bank during iterative construction are the most distinctive elements.
major comments (3)
- [§4] §4 (Experiments): The reported pass-rate improvements (9.69 / 4.01) are presented without any description of statistical significance tests, variance across runs, or explicit controls for baseline implementation details (e.g., prompt templates, memory size, or temperature settings). This makes it impossible to determine whether the gains are robust or attributable to the RL-trained policy.
- [§3.2] §3.2 (Hybrid Reward): No ablation is reported that isolates the contribution of the dense rubric component versus the sparse execution feedback. Without such a test, it remains possible that the management policy learns to produce skills that score well on the rubric but do not causally improve downstream agent performance on held-out tasks.
- [§4.3] §4.3 (Cross-benchmark evaluation): The paper does not test whether skills learned with one downstream agent transfer when the frozen agent is replaced by a different model or architecture. This directly bears on the claim that the hybrid reward produces generally useful procedural knowledge rather than distribution-specific artifacts.
minor comments (2)
- [Abstract, §1] The abstract and §1 should explicitly state the number of independent runs and any hyper-parameter search procedure used for the hybrid reward weights.
- [Figure 3] Figure 3 (skill-bank size over iterations) would benefit from error bars or multiple runs to substantiate the stability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental rigor. We address each major comment below and describe the planned revisions.
read point-by-point responses
-
Referee: §4 (Experiments): The reported pass-rate improvements (9.69 / 4.01) are presented without any description of statistical significance tests, variance across runs, or explicit controls for baseline implementation details (e.g., prompt templates, memory size, or temperature settings). This makes it impossible to determine whether the gains are robust or attributable to the RL-trained policy.
Authors: We agree that the current manuscript lacks these details. In the revision we will report means and standard deviations over multiple runs with different seeds, include paired statistical significance tests, and document all baseline hyperparameters, prompt templates, memory sizes, and temperature settings for full reproducibility. revision: yes
-
Referee: §3.2 (Hybrid Reward): No ablation is reported that isolates the contribution of the dense rubric component versus the sparse execution feedback. Without such a test, it remains possible that the management policy learns to produce skills that score well on the rubric but do not causally improve downstream agent performance on held-out tasks.
Authors: We acknowledge the absence of this ablation. The revised manuscript will add an ablation comparing policies trained with rubric-only, execution-only, and hybrid rewards, measuring their effects on downstream pass rates to isolate each component's contribution. revision: yes
-
Referee: §4.3 (Cross-benchmark evaluation): The paper does not test whether skills learned with one downstream agent transfer when the frozen agent is replaced by a different model or architecture. This directly bears on the claim that the hybrid reward produces generally useful procedural knowledge rather than distribution-specific artifacts.
Authors: Our experiments hold the downstream agent fixed to isolate the skill-management policy while testing across three distinct task distributions. Full cross-agent transfer experiments would require new model pairings and substantial additional compute. We will add a limitations paragraph discussing this scope choice and the implications for generality. revision: partial
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper describes an RL-trained management policy for skill extraction and maintenance, evaluated via pass rates on EnvBench, SWE-Bench Verified, and Terminal-Bench 2 against no-skill and prompt/memory baselines. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that reduce the reported gains (9.69 / 4.01) to the training inputs by construction. The hybrid reward and downstream execution feedback are distinct from the final benchmark metric, and the central claim remains independent of any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agent skills: A data-driven analysis of claude skills for extending large language model functional- ity.Preprint, arXiv:2602.08004. Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. 2026. SkillClaw: Let skills evolve collectively with agentic evolver.Preprint, arXiv:2604.08377. Mike A. Merrill, Alexa...
-
[2]
InAdvances in Neural Infor- mation Processing Systems, volume 36, pages 8634– 8652
Reflexion: Language agents with verbal re- inforcement learning. InAdvances in Neural Infor- mation Processing Systems, volume 36, pages 8634– 8652. SWE-agent Team. 2025. mini-SWE-agent: A 100-line software engineering agent. https://github.com/ SWE-agent/mini-swe-agent. Software repository. Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Yanjun Sha...
2025
-
[3]
Dynamic Dual-Granularity Skill Bank for Agentic RL
AGENT KB: A hierarchical memory frame- work for cross-domain agentic problem solving. In ICML 2025 Workshop on Collaborative and Feder- ated Agentic Workflows. Oral. Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dongbin Zhao. 2026. Dynamic dual-granularity skill bank for agentic RL.Preprint, arXiv:2603.28716. Guanz...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SWE-smith: Scaling Data for Software Engineering Agents
SWE-smith: Scaling data for software engi- neering agents.arXiv preprint arXiv:2504.21798. Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yux- uan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, Bo Zhang, and Liang He. 2026. AutoSkill: Experience-driven lifelong learning via skill self- evolution.Preprint, arXiv:2603.01145. Shunyu Yao, Jeffrey Zhao, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
SWE Context Bench: A Benchmark for Context Learning in Coding
SWE Context Bench: A benchmark for con- text learning in coding.Preprint, arXiv:2602.08316. A Training Details This appendix provides additional details on the data construction and training configuration of CODESKILL. We organize the discussion by train- ing stage. Supervised fine-tuning first teaches the model the action schema and basic skill- manageme...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
It must be broader than a single local event
A bootstrap skill is a task-level reusable pattern supported by multiple trajectories. It must be broader than a single local event
-
[7]
Keep when_to_apply high-level and write transferable, actionablerules
Generate only if the pattern is reusable across similar tasks. Keep when_to_apply high-level and write transferable, actionablerules
-
[8]
Do not invent unsupported steps, checks, or guidance
Ground every part of the skill in repeated evidence from the trajectories and outcomes. Do not invent unsupported steps, checks, or guidance. If failed trajectories reveal reusable cautions, include them as cautionary rules
-
[9]
Skip if the evidence is weak, contradictory, accidental, too local, or collapses into an event-level reaction instead of a task-level pattern
-
[10]
action":
Do not include repository names, issue descriptions, exact task goals, variable names, function names, class names, module names, exact file paths, or one-off literals. Output Schema generate { "action": "generate", "skill": { "title": "short reusable skill name", "granularity": "general", "when_to_apply": "high-level task situation where this skill shoul...
-
[11]
It must focus on one important event inside the trajectory and stay narrower than a whole-task workflow
An event-driven skill is a local trigger-response pattern. It must focus on one important event inside the trajectory and stay narrower than a whole-task workflow
-
[12]
Keep when_to_apply transferable and write local actionablerules
Generate only if the event yields a reusable lesson beyond this exact task. Keep when_to_apply transferable and write local actionablerules
-
[13]
Do not invent an event that is not clearly present
Ground the trigger and guidance in the trajectory and result. Do not invent an event that is not clearly present. Failure- derived cautions are valid if they are clearly supported
-
[14]
If multiple candidate events exist, choose the single most reusable one
-
[15]
Skip if there is no strong reusable local event, or if the lesson is too task-specific or workflow-level
-
[16]
action":
Do not include repository names, issue descriptions, exact task goals, variable names, function names, class names, module names, exact file paths, or one-off literals. Output Schema generate { "action": "generate", "skill": { "title": "short reusable skill name", "granularity": "event-driven", "when_to_apply": "high-level local signal or situation where ...
-
[17]
If multiple skills are aligned and all are plausible revision targets, choose the single one that is most worth revising based on the strength and reusability of the evidence
Alignment and need for revision.Choose evolve only when one existing skill is clearly aligned with the current trajectory context and trigger pattern, and the current trajectory result shows that this aligned skill should be revised. If multiple skills are aligned and all are plausible revision targets, choose the single one that is most worth revising ba...
-
[18]
rules should contain the revised reusable core of the skill as actionable guidance
Reusability and rule writing.Revise the skill only if the trajectory reveals a reusable missing case, missing check, better decision rule, improved ordering, or reusable caution. rules should contain the revised reusable core of the skill as actionable guidance. 3.Applicability.when_to_applyshould remain at a high transferable level rather than concrete task text
-
[19]
Do not add unsupported refinements
Grounding.The revision must be directly supported by the provided trajectory and result. Do not add unsupported refinements. 5.Identity preservation.Keep the same capability identity. Do not drift into a different skill
-
[20]
When to skip.Choose skip if the evidence is weak, contradictory, too local, or if the trajectory is better described as a brand-new skill rather than a revision
-
[21]
action":
Do not include task-specific details.Do not include repository names, issue descriptions, exact task goals, variable names, function names, class names, module names, exact file paths, or one-off literals that only make sense for one instance. Output Schema evolve { "action": "evolve", "target_skill_id": "id of the single skill you chose to revise", "reas...
-
[22]
The merged skill should have clearer applicability and cleaner rules with less duplication
Merge.Choose merge when the candidate and one retrieved skill share the same capability identity and can be combined into one stronger reusable skill. The merged skill should have clearer applicability and cleaner rules with less duplication
-
[23]
Drop.Choose drop when the candidate is already covered by stronger retrieved skills, redundant, weakly evidenced, unsafe, too local, or too task-specific
-
[24]
action":
Do not include task-specific details.No resulting skill may include repository names, issue descriptions, exact task goals, variable names, function names, class names, module names, exact file paths, or one-off literals that only make sense for one instance. Output Schema add { "action": "add", "reason": "short reason" } drop { "action": "drop", "reason"...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.