Enhancing Single-Image Facial Demorphing using Multimodal Large Language Models
Pith reviewed 2026-06-29 22:47 UTC · model grok-4.3
The pith
Semantic embeddings from intermediate MLLM layers condition a coupled RGB diffusion model to enable reference-free facial demorphing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
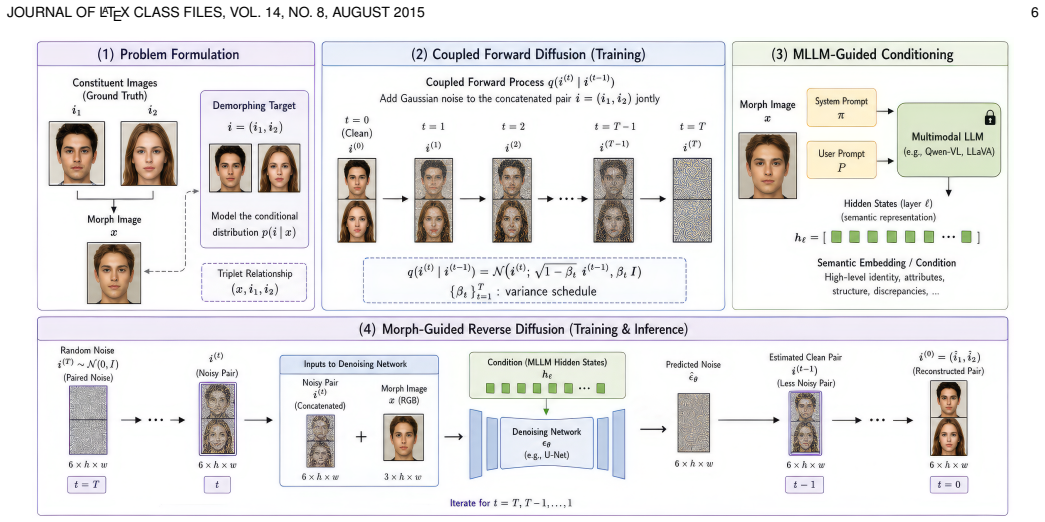
By extracting semantic embeddings from intermediate MLLM layers to condition a coupled conditional generation problem, a denoising diffusion model operating directly in the RGB domain can synthesize both constituent faces from a morphed image. This bypasses lossy text generation-reencoding cycles, preserves fine-grained perceptual details such as hair and textures, ensures inter-identity consistency, and requires no reference images or identity overlap between training and test sets.
What carries the argument
Direct use of intermediate MLLM hidden states as conditioning signals for a coupled RGB-domain denoising diffusion model that performs joint synthesis of both identities.
If this is right
- Middle MLLM layers encode more identity-discriminative representations than early or late layers.
- RGB-domain demorphing outperforms latent-space approaches by 30-40% at strict operating points.
- Full MLLM embeddings outperform raw ViT features due to enhanced semantic structuring from multimodal pretraining.
- The method functions without assuming identity overlap between training and test sets.
Where Pith is reading between the lines
- The direct embedding approach may apply to other image decomposition tasks where semantic guidance is needed without intermediate text.
- Joint synthesis in pixel space could extend to paired generation problems that require consistency between outputs.
- If middle-layer embeddings prove generally useful, similar layer-selection strategies might improve conditioning in other diffusion-based restoration methods.
Load-bearing premise
Semantic embeddings extracted from intermediate MLLM layers encode identity-discriminative facial attributes and cues that meaningfully complement low-level pixel information and can condition the diffusion process without reference images or identity overlap between training and test sets.
What would settle it
An experiment that replaces the MLLM hidden-state conditioning with either random vectors or text-generated descriptions and measures whether the 30-40% gain at strict operating points disappears would settle the claim.
Figures


read the original abstract
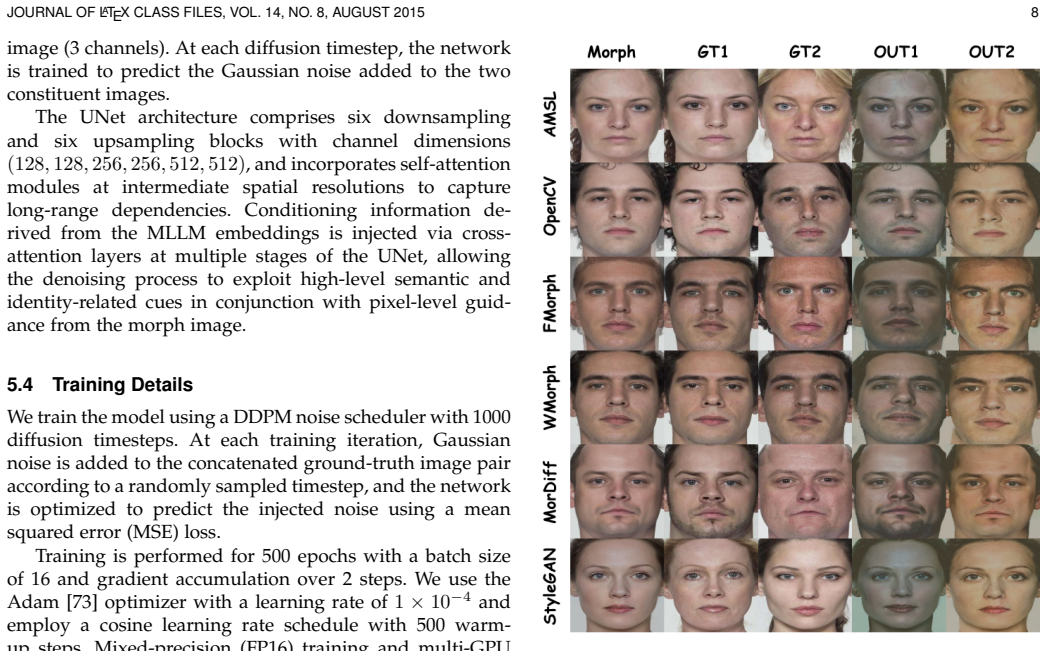
Face recognition systems are increasingly vulnerable to morphing attacks, where a composite image is crafted to match multiple identities, enabling unauthorized access and identity fraud. Existing detection methods identify morphed images but cannot recover constituent images or identities, limiting their forensic utility. This paper presents a novel reference-free facial demorphing framework that leverages Multimodal Large Language Models (MLLMs) to guide a coupled diffusion-based reconstruction process. Our key innovation lies in extracting semantic embeddings from intermediate MLLM layers to condition the demorphing, providing high-level reasoning about facial attributes and identity cues that complement low-level pixel information. We formulate demorphing as a coupled conditional generation problem, where both constituent faces are synthesized jointly through a denoising diffusion model operating directly in the RGB domain, ensuring inter-identity consistency while preserving fine-grained perceptual details. Unlike prior approaches that rely on compressed latent representations or assume identity overlap between training and testing sets, our method bypasses lossy text generation-reencoding cycles by directly utilizing MLLM hidden states as conditioning signals, enabling the denoising network to attend to subtle visual cues such as hair, background, and facial textures. Ablation studies further reveal that middle MLLM layers encode more identity-discriminative representations, RGB-domain demorphing outperforms latent-space approaches by 30--40\% at strict operating points, and full MLLM embeddings provide substantial advantages over raw ViT features through enhanced semantic structuring from multimodal pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present a reference-free facial demorphing method that extracts semantic embeddings from intermediate layers of Multimodal Large Language Models (MLLMs) to directly condition a coupled RGB-domain denoising diffusion model. This enables joint synthesis of the two constituent faces from a single morphed input image, bypassing text generation-reencoding cycles, with ablations indicating that middle MLLM layers are optimal, RGB-domain operation outperforms latent-space baselines by 30-40% at strict operating points, and MLLM embeddings outperform raw ViT features due to multimodal pretraining.
Significance. If the empirical performance claims and the disentanglement capability hold under scrutiny, the work would offer a meaningful advance in forensic tools for morphing attacks by removing the need for reference images or identity overlap between train and test sets. The direct use of MLLM hidden states as conditioning signals, rather than compressed latents or generated text, represents a potentially useful direction for integrating high-level semantic reasoning into pixel-level generative models for biometrics.
major comments (2)
- [Abstract] Abstract: The central performance claims (30--40% gains over latent baselines, middle layers best, MLLM > ViT) and ablation outcomes are asserted without any accompanying quantitative tables, figures, dataset details, training protocols, metrics (e.g., verification rates, perceptual distances), error bars, or statistical tests. These omissions make the load-bearing empirical assertions unverifiable from the manuscript.
- [Abstract] Abstract and method description: The single shared MLLM embedding extracted from the morphed image is used to condition joint synthesis of two distinct identities, yet no mechanism is described for how this embedding is split, attended, or disentangled across the two output faces in the coupled diffusion process. This is load-bearing for the reference-free claim, as the skeptic concern that the embedding may primarily capture averaged features is not addressed by any ablation or architectural detail.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (30--40% gains over latent baselines, middle layers best, MLLM > ViT) and ablation outcomes are asserted without any accompanying quantitative tables, figures, dataset details, training protocols, metrics (e.g., verification rates, perceptual distances), error bars, or statistical tests. These omissions make the load-bearing empirical assertions unverifiable from the manuscript.
Authors: The full manuscript (Sections 4 and 5) contains the supporting ablation tables, performance curves, dataset descriptions, training protocols, and metrics with error bars. The abstract summarizes these results at a high level. To improve verifiability, we will revise the abstract to incorporate key quantitative highlights (e.g., specific verification rate improvements and layer comparisons) while retaining brevity. revision: yes
-
Referee: [Abstract] Abstract and method description: The single shared MLLM embedding extracted from the morphed image is used to condition joint synthesis of two distinct identities, yet no mechanism is described for how this embedding is split, attended, or disentangled across the two output faces in the coupled diffusion process. This is load-bearing for the reference-free claim, as the skeptic concern that the embedding may primarily capture averaged features is not addressed by any ablation or architectural detail.
Authors: The coupled diffusion formulation (Section 3) applies the shared embedding via cross-attention to two parallel denoising branches, with the joint training objective encouraging identity-specific feature extraction. We agree the description of disentanglement is insufficient and the averaging concern is not explicitly ablated. We will add an architectural diagram, expanded conditioning details, and a targeted ablation on embedding splitting in the revised method section. revision: yes
Circularity Check
No significant circularity; empirical claims rest on ablations, not derivations or self-citations.
full rationale
The paper describes an MLLM-conditioned RGB diffusion model for reference-free demorphing, with all performance claims (30-40% gains, layer selection benefits) presented as outcomes of ablation experiments rather than quantities derived from equations or prior self-citations. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The central conditioning step is justified by empirical results on identity-discriminative embeddings, not by construction or imported uniqueness theorems. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Intermediate MLLM layers encode identity-discriminative representations that complement pixel-level information.
- domain assumption Joint synthesis of both constituent faces through a single denoising process preserves inter-identity consistency.
Reference graph
Works this paper leans on
-
[1]
Elasticface: Elastic margin loss for deep face recognition,
F. Boutros, N. Damer, F. Kirchbuchner, and A. Kuijper, “Elasticface: Elastic margin loss for deep face recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[2]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[3]
50 years of automated face recogni- tion,
M. Kim, A. Jain, and X. Liu, “50 years of automated face recogni- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–20, 2026
2026
-
[4]
The magic passport,
M. Ferrara, A. Franco, and D. Maltoni, “The magic passport,” inProceedings of International Joint Conference on Biometrics (IJCB), 2014
2014
-
[5]
Unveiling the two-faced truth: Disentangling morphed identities for face morphing detection,
E. Caldeira, P . C. Neto, T. Gonc ¸alves, N. Damer, A. F. Sequeira, and J. S. Cardoso, “Unveiling the two-faced truth: Disentangling morphed identities for face morphing detection,” inProceedings of European Signal Processing Conference (EUSIPCO), 2023
2023
-
[6]
Mordiff: Recognition vulnerability and attack detectability of face morphing attacks created by diffusion autoencoders,
N. Damer, M. Fang, P . Siebke, J. N. Kolf, M. Huber, and F. Boutros, “Mordiff: Recognition vulnerability and attack detectability of face morphing attacks created by diffusion autoencoders,” inProceed- ings of International Workshop on Biometrics and Forensics (IWBF), 2023
2023
-
[7]
MIPGAN - generating strong and high quality morphing attacks using identity prior driven GAN,
H. Zhang, S. Venkatesh, R. Ramachandra, K. B. Raja, N. Damer, and C. Busch, “MIPGAN - generating strong and high quality morphing attacks using identity prior driven GAN,”IEEE Trans- actions on Biometrics, Behavior, and Identity Science (T-BIOM), vol. 3, no. 3, pp. 365–383, 2021
2021
-
[8]
Automatic gener- ation and detection of visually faultless facial morphs,
A. Makrushin, T. Neubert, and J. Dittmann, “Automatic gener- ation and detection of visually faultless facial morphs,” inPro- ceedings of International Conference on Computer Vision Theory and Applications (VISAPP), 2017
2017
-
[9]
Facemorpher,
A. Quek, “Facemorpher,” 2019
2019
-
[10]
Training generative adversarial networks with limited data,
T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila, “Training generative adversarial networks with limited data,” in Proceedings of Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[11]
Ladimo: Face morph generation through biometric template inversion with latent diffusion,
M. Grimmer and C. Busch, “Ladimo: Face morph generation through biometric template inversion with latent diffusion,” in Proceedings of IEEE International Joint Conference on Biometrics (IJCB), 2024
2024
-
[12]
FLOWING: Implicit neural flows for structure-preserving morphing,
A. Bizzi, M. G. Portnoy, V . P . Matias, D. Perazzo, J. P . S. do Monte Lima, L. Velho, N. Gonc ¸alves, J. M. Pereira, G. Schardong, and T. Novello, “FLOWING: Implicit neural flows for structure-preserving morphing,” inProceedings of Annual Con- ference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[13]
Face morphing detection using fourier spectrum of sensor pattern noise,
L.-B. Zhang, F. Peng, and M. Long, “Face morphing detection using fourier spectrum of sensor pattern noise,” inProceedings of International Conference on Multimedia and Expo (ICME), 2018
2018
-
[14]
Single Im- age Face Morphing Attack Detection Using Ensemble of Features,
S. Venkatesh, R. Ramachandra, K. Raja, and C. Busch, “Single Im- age Face Morphing Attack Detection Using Ensemble of Features,” inProceedings of 23rd International Conference on Information Fusion (FUSION), 2020
2020
-
[15]
Transfer- able Deep-CNN Features for Detecting Digital and Print-Scanned Morphed Face Images,
R. Raghavendra, K. B. Raja, S. Venkatesh, and C. Busch, “Transfer- able Deep-CNN Features for Detecting Digital and Print-Scanned Morphed Face Images,” inProceedings of IEEE Conference on Com- puter Vision and Pattern Recognition Workshops (CVPRW), 2017
2017
-
[16]
MADation: Face Morph- ing Attack Detection with Foundation Models,
E. Caldeira, G. Ozgur, T. Chettaoui, M. Ivanovska, P . Peer, F. Boutros, V . Struc, and N. Damer, “MADation: Face Morph- ing Attack Detection with Foundation Models,” inProceedings of IEEE/CVF Winter Conference on Applications of Computer Vision, WACV Workshops, 2025
2025
-
[17]
Orthomad: Morphing attack detection through or- thogonal identity disentanglement,
P . C. Neto, T. Gonc ¸alves, M. Huber, N. Damer, A. F. Sequeira, and J. S. Cardoso, “Orthomad: Morphing attack detection through or- thogonal identity disentanglement,” inProceedings of International Conference of the Biometrics Special Interest Group (BIOSIG), 2022
2022
-
[18]
Detecting face morphing attacks by analyzing the directed distances of facial landmarks shifts,
N. Damer, V . Boller, Y. Wainakh, F. Boutros, P . Terh¨orst, A. Braun, and A. Kuijper, “Detecting face morphing attacks by analyzing the directed distances of facial landmarks shifts,”Pattern Recognition, pp. 518–534, 2019
2019
-
[19]
Detecting morphed face images using facial landmarks,
U. Scherhag, D. Budhrani, M. Gomez-Barrero, and C. Busch, “Detecting morphed face images using facial landmarks,” inPro- ceedings of International Conference on Image and Signal Processing (ICISP), 2018
2018
-
[20]
Robust morph-detection at automated border control gate using deep decomposed 3d shape & diffuse reflectance,
J. M. Singh, R. Ramachandra, K. B. Raja, and C. Busch, “Robust morph-detection at automated border control gate using deep decomposed 3d shape & diffuse reflectance,” inProceedings of International Conference on Signal-Image Technology Internet-Based Systems (SITIS), 2019
2019
-
[22]
Fd-gan: Face de-morphing generative adversarial network for restoring accomplice’s facial image,
F. Peng, L.-B. Zhang, and M. Long, “Fd-gan: Face de-morphing generative adversarial network for restoring accomplice’s facial image,”IEEE Access, vol. 7, pp. 75122–75131, 2019
2019
-
[23]
Face de-morphing based on diffusion autoencoders,
M. Long, Q. Yao, L.-B. Zhang, and F. Peng, “Face de-morphing based on diffusion autoencoders,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3051–3063, 2024
2024
-
[24]
diffDemorph: Extending Reference-Free Demorphing to Unseen Faces,
N. Shukla and A. Ross, “diffDemorph: Extending Reference-Free Demorphing to Unseen Faces,” inProceedings of IEEE International Conference on Image Processing (ICIP), 2025
2025
-
[25]
Facial demorphing via identity preserving image decomposition,
N. Shukla and A. Ross, “Facial demorphing via identity preserving image decomposition,” inProceedings of the IEEE International Joint Conference on Biometrics (IJCB), 2024
2024
-
[26]
Facial demorphing from a single morph using a latent conditional gan,
N. Shukla and A. Ross, “Facial demorphing from a single morph using a latent conditional gan,” inProceedings of IEEE International Joint Conference on Biometrics (IJCB), 2025
2025
-
[27]
dc-GAN: Dual-Conditioned GAN for Face Demorphing From a Single Morph,
N. Shukla and A. Ross, “dc-GAN: Dual-Conditioned GAN for Face Demorphing From a Single Morph,” inProceedings of IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2025
2025
-
[28]
Facial De-morphing: Extract- ing Component Faces from a Single Morph,
S. Banerjee, P . Jaiswal, and A. Ross, “Facial De-morphing: Extract- ing Component Faces from a Single Morph,” inProceedings of IEEE International Joint Conference on Biometrics, 2022
2022
-
[29]
Two algorithms for constructing a delaunay triangulation,
D. T. Lee and B. J. Schachter, “Two algorithms for constructing a delaunay triangulation,”International Journal of Computer & Information Sciences, vol. 9, pp. 219–242, Jun 1980
1980
-
[30]
GNU Image Manipulation Pro- gram (GIMP), Version 3.0.6. Community, Free Software (license GPLv3),
GIMP Development Team, “GNU Image Manipulation Pro- gram (GIMP), Version 3.0.6. Community, Free Software (license GPLv3),” 2025. Version 3.0.6, Free Software
2025
-
[31]
GIMP Animation Package,
The GIMP Development Team, “GIMP Animation Package,” 2025
2025
-
[32]
Active shape models with SIFT descriptors and MARS,
S. Milborrow and F. Nicolls, “Active shape models with SIFT descriptors and MARS,” inProceedings of International Conference on Computer Vision Theory and Applications, 2014
2014
-
[33]
Face morph using opencv — c++ / python,
S. Mallick, “Face morph using opencv — c++ / python,” LearnOpenCV, vol. 1, no. 1, 2016
2016
-
[34]
Privacy-friendly Synthetic Data for the Development of Face Morphing Attack Detectors,
N. Damer, C. A. F. L ´opez, M. Fang, N. Spiller, M. V . Pham, and F. Boutros, “Privacy-friendly Synthetic Data for the Development of Face Morphing Attack Detectors,” inProceedings of Computer Vision and Pattern Recognition Workshops (CVPRW), 2022
2022
-
[35]
Dlib-ml: A Machine Learning Toolkit,
D. E. King, “Dlib-ml: A Machine Learning Toolkit,”Journal of Machine Learning Research, vol. 10, p. 1755–1758, 2009
2009
-
[36]
Morgan: Recognition vulnerability and attack detectability of face morph- ing attacks created by generative adversarial network,
N. Damer, A. M. Saladie, A. Braun, and A. Kuijper, “Morgan: Recognition vulnerability and attack detectability of face morph- ing attacks created by generative adversarial network,” inProceed- ings of International Conference on Biometrics Theory, Applications and Systems (BTAS), 2018
2018
-
[37]
Can GAN generated morphs threaten face recog- nition systems equally as landmark based morphs? - vulnerability and detection,
S. Venkatesh, H. Zhang, R. Ramachandra, K. B. Raja, N. Damer, and C. Busch, “Can GAN generated morphs threaten face recog- nition systems equally as landmark based morphs? - vulnerability and detection,” inProceedings of the International Workshop on Biometrics and Forensics (IWBF), 2020
2020
-
[38]
Pw-mad: Pixel-wise supervision for generalized face morphing attack detection,
N. Damer, N. Spiller, M. Fang, F. Boutros, F. Kirchbuchner, and A. Kuijper, “Pw-mad: Pixel-wise supervision for generalized face morphing attack detection,”Advances in Visual Computing, pp. 291–304, 2021
2021
-
[39]
Unsupervised face morphing attack detection via self-paced anomaly detection,
M. Fang, F. Boutros, and N. Damer, “Unsupervised face morphing attack detection via self-paced anomaly detection,” inProceedings of International Joint Conference on Biometrics (IJCB), 2022
2022
-
[40]
SYN-MAD 2022: Competition on face morphing attack detection based on privacy-aware synthetic training data,
M. Huber, F. Boutros, A. T. Luu, K. Raja, R. Ramachandra, N. Damer, P . C. Neto, T. Gonc ¸alves, A. F. Sequeira, J. S. Cardoso, et al., “SYN-MAD 2022: Competition on face morphing attack detection based on privacy-aware synthetic training data,” inPro- ceedings of IEEE International Joint Conference on Biometrics (IJCB), 2022
2022
-
[41]
Detecting face morphing attacks with collaborative representation of steer- able features,
R. Ramachandra, S. Venkatesh, K. Raja, and C. Busch, “Detecting face morphing attacks with collaborative representation of steer- able features,” inProceedings of International Conference on Computer Vision and Image Processing (CVIP), 2019. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 14
2019
-
[42]
MSA-CNN: Face Morphing Detection via a Multiple Scales Attention Convolutional Neural Network,
L.-B. Zhang, J. Cai, F. Peng, and M. Long, “MSA-CNN: Face Morphing Detection via a Multiple Scales Attention Convolutional Neural Network,” inProceedings of 20th International Workshop on Digital Forensics and Watermarking (IWDW), 2021
2021
-
[43]
A Multi-detector Solution Towards an Accurate and Generalized Detection of Face Morphing Attacks,
N. Damer, S. Zienert, Y. Wainakh, A. M. Saladi ´e, F. Kirchbuchner, and A. Kuijper, “A Multi-detector Solution Towards an Accurate and Generalized Detection of Face Morphing Attacks,” inProceed- ings of 22th International Conference on Information Fusion (FUSION), 2019
2019
-
[44]
Towards making Morphing Attack Detection robust using hybrid Scale- Space Colour Texture Features,
R. Ramachandra, S. Venkatesh, K. Raja, and C. Busch, “Towards making Morphing Attack Detection robust using hybrid Scale- Space Colour Texture Features,” inProceedings of 5th International Conference on Identity, Security, and Behavior Analysis (ISBA), 2019
2019
-
[45]
General- ized Single-Image-Based Morphing Attack Detection Using Deep Representations from Vision Transformer,
H. Zhang, R. Ramachandra, K. Raja, and C. Busch, “General- ized Single-Image-Based Morphing Attack Detection Using Deep Representations from Vision Transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024
2024
-
[46]
Face morphing attack detection with denoising diffusion probabilistic models,
M. Ivanovska and V . Struc, “Face morphing attack detection with denoising diffusion probabilistic models,” inProceedings of International Workshop on Biometrics and Forensics (IWBF), 2023
2023
-
[47]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,” inProceedings of Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[48]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agar- wal, G. Sastry, A. Askell, P . Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” in Proceedings of International Conference on Machine Learning (ICML), 2021
2021
-
[49]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P . J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of Machine Learning Research, vol. 21, Jan. 2020
2020
-
[50]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” in Proceedings of NeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[51]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[52]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” in Proceedings of International Conference on Neural Information Process- ing Systems (NeurIPS), 2023
2023
-
[53]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P . Fung, and S. Hoi, “InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning,” inProceedings of Annual Confer- ence on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[54]
GPT-4 technical report,
OpenAI, “GPT-4 technical report,” 2023
2023
-
[55]
Claude: A new AI assistant,
Anthropic, “Claude: A new AI assistant,” 2023
2023
-
[56]
Gemini: Advancements in AI models.,
Google, “Gemini: Advancements in AI models.,” 2023
2023
-
[57]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023
2023
-
[58]
Llava-onevision-chat: Improving chat with preference learning,
T. Xiong, B. Li, D. Guo, H. Yuan, Q. Gu, and C. Li, “Llava-onevision-chat: Improving chat with preference learning,” September 2024
2024
-
[59]
W. Wang, Z. Chen, W. Wang, Y. Cao, Y. Liu, Z. Gao, J. Zhu, X. Zhu, L. Lu, Y. Qiao,et al., “Enhancing the reasoning ability of multi- modal large language models via mixed preference optimization,” arXiv preprint arXiv:2411.10442, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Face demorphing,
M. Ferrara, A. Franco, and D. Maltoni, “Face demorphing,”IEEE Transactions on Information Forensics and Security, vol. 13, no. 4, pp. 1008–1017, 2017
2017
-
[61]
Border control morphing attack detection with a convolu- tional neural network de-morphing approach,
D. Ortega-Delcampo, C. Conde, D. Palacios-Alonso, and E. Ca- bello, “Border control morphing attack detection with a convolu- tional neural network de-morphing approach,”IEEE Access, vol. 8, pp. 92301–92313, 2020
2020
-
[62]
MorphGANformer: Transformer-based face morphing and de-morphing,
N. Zhang, X. Liu, X. Li, and G.-J. Qi, “MorphGANformer: Transformer-based face morphing and de-morphing,”arXiv preprint arXiv:2302.09404, 2023
-
[63]
A styleGAN- based face de-morphing network for restoring accomplice’s facial image,
J. Cai, M. Long, L. Zhang, Q. Yao, and X. Ding, “A styleGAN- based face de-morphing network for restoring accomplice’s facial image,”Multimedia Systems, vol. 31, 2025
2025
-
[64]
SDeMorph: Towards Better Facial De-morphing from Single Morph,
N. Shukla, “SDeMorph: Towards Better Facial De-morphing from Single Morph,” inProceedings of IEEE International Joint Conference on Biometrics (IJCB), 2023
2023
-
[65]
Metric for Evaluating Performance of Reference-Free Demorphing Methods,
N. Shukla and A. Ross, “Metric for Evaluating Performance of Reference-Free Demorphing Methods,” inProceedings of IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), 2025
2025
-
[66]
Diffusers: State-of-the-art diffusion models
P . von Platen, S. Patil, A. Lozhkov, P . Cuenca, N. Lambert, K. Rasul, M. Davaadorj, D. Nair, S. Paul, W. Berman, Y. Xu, S. Liu, and T. Wolf, “Diffusers: State-of-the-art diffusion models.” https://github.com/huggingface/diffusers, 2022
2022
-
[67]
Joint face detection and alignment using multitask cascaded convolutional networks,
K. Zhang, Z. Zhang, Z. Li, and Y. Qiao, “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE Signal Processing Letters, vol. 23, pp. 1499–1503, Oct 2016
2016
-
[68]
Extended StirTrace Benchmarking of Biometric and Forensic Qualities of Morphed Face Images,
T. Neubert, A. Makrushin, M. Hildebrandt, C. Kraetzer, and J. Dittmann, “Extended StirTrace Benchmarking of Biometric and Forensic Qualities of Morphed Face Images,”IET Biometrics, vol. 7, pp. 325–332, 2018
2018
-
[69]
Face Research Lab London Set,
L. DeBruine and B. Jones, “Face Research Lab London Set,” 5 2017
2017
-
[70]
debruine/webmorph: Beta release 2,
L. DeBruine, “debruine/webmorph: Beta release 2,”Zenodo https://doi. org/10, vol. 5281, 2018
2018
-
[71]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P . Zhang, P . Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” 2023
2023
-
[73]
Adam: A Method for Stochastic Op- timization,
D. P . Kingma and J. Ba, “Adam: A Method for Stochastic Op- timization,” inProceedings of International Conference on Learning Representations (ICLR), 2017
2017
-
[74]
Accelerate: Training and inference at scale made simple, efficient and adaptable
S. Gugger, L. Debut, T. Wolf, P . Schmid, Z. Mueller, S. Mangrulkar, M. Sun, and B. Bossan, “Accelerate: Training and inference at scale made simple, efficient and adaptable.” https://github.com/ huggingface/accelerate, 2022
2022
-
[75]
Adaface: Quality adaptive margin for face recognition,
M. Kim, A. K. Jain, and X. Liu, “Adaface: Quality adaptive margin for face recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[76]
Transformers: State-of- the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P . Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P . von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of- the-art natural language processing,” inProceedings of the Confer- ence on Empirical Meth...
2020
-
[77]
Learning Face Representation from Scratch
D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Learning face representation from scratch,”arXiv preprint arXiv:1411.7923, 2014. Nitish Shuklais currently a Ph.D. candidate in the Department of Computer Science and Engineering at Michigan State University. His research interests include facial biometrics and multimodal learning. Arun Ross(Senior Member, IEEE) is t...
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.