A Lightweight Hybrid Transformer-CRF Architecture for Multi-Type Bangla Medical Entity Recognition
Pith reviewed 2026-06-29 22:07 UTC · model grok-4.3
The pith
A 4-layer student distilled from BanglaBERT-CRF with INT8 quantization achieves 8.6x CPU speedup and 48 percent less storage for Bangla medical entity recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Distilling a compact 4-layer transformer student from the pre-CRF soft logits of a 12-layer BanglaBERT-CRF teacher, then applying INT8 dynamic quantization, yields a model that matches the teacher's entity detection capability while delivering an 8.6x CPU speedup and nearly 48 percent reduction in storage.
What carries the argument
Knowledge distillation from the teacher's pre-CRF soft emission logits to train a smaller student network, followed by INT8 quantization.
If this is right
- The compressed model supports real-time medical entity extraction on standard CPUs in Bangla clinical workflows.
- Exact-boundary performance remains usable for downstream tasks that require precise spans rather than token-level accuracy.
- The pipeline lowers the barrier for deploying clinical NLP in other low-resource languages that have BERT-style models available.
- Quantization can be applied after distillation without requiring retraining from scratch.
Where Pith is reading between the lines
- The same distillation target could be tested on sequence labeling tasks outside medical NER, such as part-of-speech tagging in Bangla.
- Combining the approach with larger teacher models might further improve the student's accuracy ceiling before quantization.
- Deployment on edge devices could be measured by end-to-end latency on actual clinical documents rather than synthetic benchmarks.
Load-bearing premise
That the teacher's pre-CRF soft logits carry enough boundary information for the student to retain exact-match entity detection accuracy after compression.
What would settle it
A direct comparison on a held-out Bangla medical test set where the quantized student's strict-boundary F1 score falls substantially below the 12-layer teacher's score.
Figures

read the original abstract
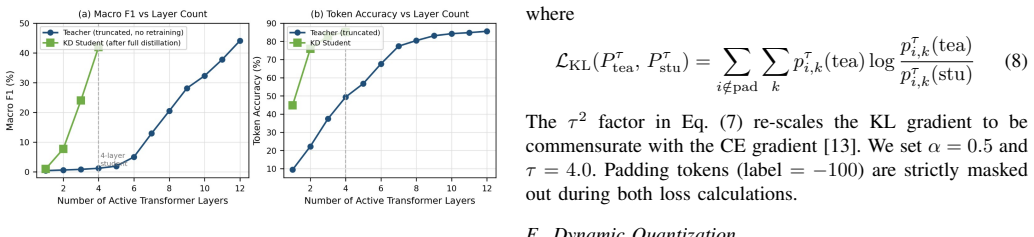
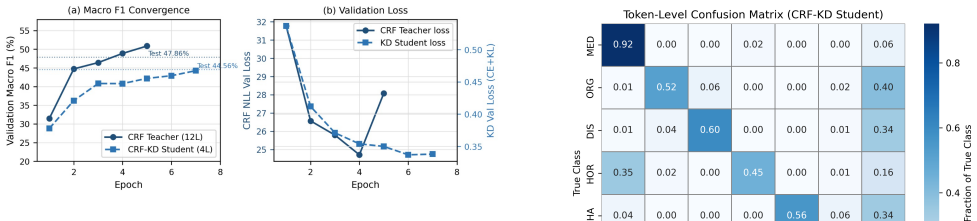
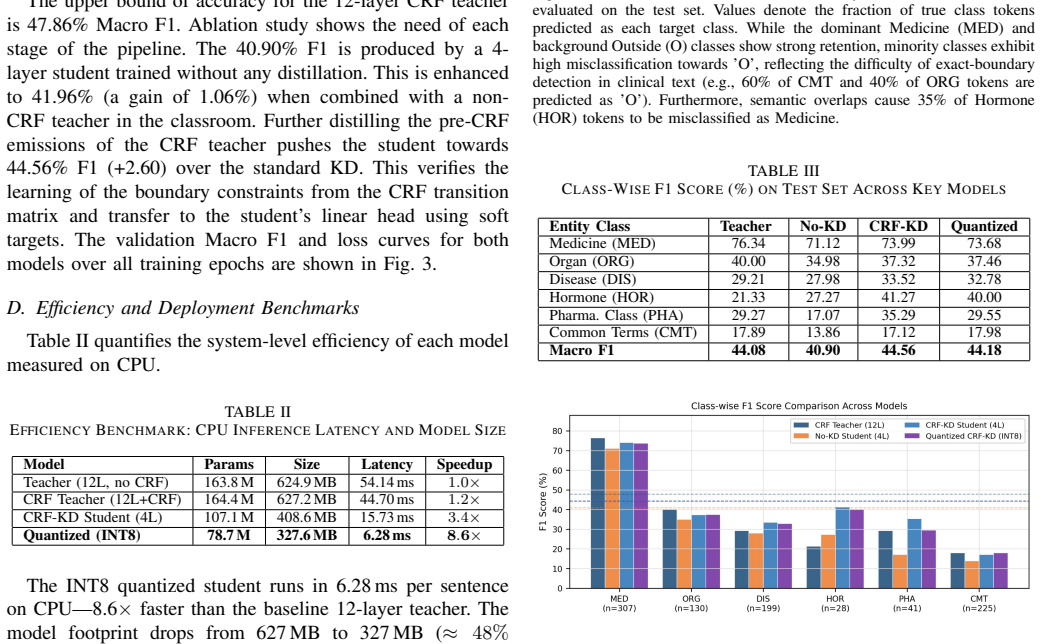
MedER refers to the identification of medical entities. It is crucial for extracting structured clinical information from unstructured medical text. Many existing systems rely on transformer-based models, which are computationally expensive and difficult to deploy in resource-constrained environments. Furthermore, earlier works often use relaxed evaluation metrics that artificially inflate performance by rewarding correct prediction of dominant "Outside" (O) tokens. In this paper, we propose a lightweight Medical Entity Recognition (MedER) framework for the Bangla language. We establish a rigorous baseline using a 12-layer BanglaBERT model combined with a Conditional Random Field (CRF) layer for exact-boundary entity detection. To address deployment constraints, we compress this teacher model into a 4-layer student network through Knowledge Distillation (KD), where the student learns from the teacher's pre-CRF soft emission logits. Finally, we apply INT8 dynamic quantization to further reduce model size and inference cost. Our final quantized student achieves an 8.6x CPU speedup while requiring nearly 48 percent less storage than the CRF teacher model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a lightweight hybrid Transformer-CRF architecture for multi-type Bangla medical entity recognition (MedER). It establishes a 12-layer BanglaBERT-CRF teacher as a rigorous baseline using exact-boundary evaluation, distills the teacher to a 4-layer student via knowledge distillation on pre-CRF soft emission logits, applies INT8 dynamic quantization, and claims the final quantized student delivers an 8.6x CPU speedup with nearly 48% less storage than the teacher while remaining usable for MedER.
Significance. If accuracy is preserved, the work would provide a practical compression pipeline for deploying MedER systems in resource-constrained Bangla-language settings, where full transformer-CRF models are often impractical. The choice of exact-boundary evaluation (rather than relaxed token-level metrics) and the empirical reporting of CPU speedup and storage reduction are strengths that address real deployment constraints.
major comments (2)
- [Abstract] Abstract, final paragraph: The central claims of 8.6x CPU speedup and 48% storage reduction are stated without any accompanying accuracy metrics (F1, precision/recall on entity spans), error bars, or direct comparison of the student to the teacher on the MedER task. This omission is load-bearing because the usability claim ('remaining usable for MedER') cannot be evaluated without evidence that exact-boundary performance is retained after distillation and quantization.
- [Abstract] Abstract (knowledge distillation description): Distillation is performed solely on the teacher's pre-CRF soft emission logits, leaving the student's CRF transition matrix to be learned from hard labels or random initialization. Because exact-boundary detection relies on Viterbi decoding that jointly optimizes emissions and transitions to enforce valid BIO sequences, the lack of any reported ablation on transition distillation or boundary-specific metrics creates an unverified assumption that must be addressed with concrete results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the details of the knowledge distillation procedure. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract, final paragraph: The central claims of 8.6x CPU speedup and 48% storage reduction are stated without any accompanying accuracy metrics (F1, precision/recall on entity spans), error bars, or direct comparison of the student to the teacher on the MedER task. This omission is load-bearing because the usability claim ('remaining usable for MedER') cannot be evaluated without evidence that exact-boundary performance is retained after distillation and quantization.
Authors: We agree that the abstract should be self-contained with respect to the central performance claims. The full manuscript reports exact-boundary F1 scores together with direct teacher-student comparisons. In the revision we will add the key F1 figures and a concise comparison statement to the abstract so that the usability claim is directly supported by numbers. revision: yes
-
Referee: [Abstract] Abstract (knowledge distillation description): Distillation is performed solely on the teacher's pre-CRF soft emission logits, leaving the student's CRF transition matrix to be learned from hard labels or random initialization. Because exact-boundary detection relies on Viterbi decoding that jointly optimizes emissions and transitions to enforce valid BIO sequences, the lack of any reported ablation on transition distillation or boundary-specific metrics creates an unverified assumption that must be addressed with concrete results.
Authors: The manuscript already presents results under exact-boundary evaluation, which is a boundary-specific metric that incorporates Viterbi decoding over both the distilled emissions and the learned transitions. The CRF transition matrix is trained end-to-end on the task data rather than distilled; because the matrix is small we did not ablate its distillation. We will revise the abstract and methods to explicitly note this design choice and to emphasize that the reported exact-boundary F1 already reflects the joint optimization performed by the student. revision: partial
Circularity Check
No significant circularity; purely empirical pipeline
full rationale
The paper reports an empirical sequence of model training (12-layer BanglaBERT-CRF teacher), knowledge distillation from pre-CRF emission logits to a 4-layer student, INT8 quantization, and direct measurement of CPU speedup (8.6x) plus storage reduction (48%). No equations, predictions, or derivations appear that reduce any claimed result to a fitted parameter, self-definition, or self-citation chain by construction. All performance numbers are external benchmark measurements, making the work self-contained against independent evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- student_layer_count
axioms (1)
- domain assumption Soft logits from the teacher before the CRF layer contain sufficient information to train a student that respects exact entity boundaries.
Reference graph
Works this paper leans on
-
[1]
Named entity recognition and relation detection for biomedical information extraction,
N. Perera, M. Dehmer, and F. Emmert-Streib, “Named entity recognition and relation detection for biomedical information extraction,”Frontiers in Cell and Developmental Biology, vol. 8, p. 673, 2020
2020
-
[2]
BioBERT: a pre-trained biomedical language representa- tion model for biomedical text mining,
J. Lee et al., “BioBERT: a pre-trained biomedical language representa- tion model for biomedical text mining,”Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020
2020
-
[3]
Publicly available clinical BERT embeddings,
E. Alsentzer et al., “Publicly available clinical BERT embeddings,” in Proc. 2nd Clinical NLP Workshop, 2019, pp. 72–78
2019
-
[4]
BanglaBERT: Language model pretraining and benchmarks for low-resource language understanding evaluation in Bangla,
A. Bhattacharjee et al., “BanglaBERT: Language model pretraining and benchmarks for low-resource language understanding evaluation in Bangla,” inFindings of NAACL, 2022, pp. 1318–1327
2022
-
[5]
Bangla MedER: Multi-BERT ensemble ap- proach for the recognition of Bangla medical entity,
T. T. Aurpa et al., “Bangla MedER: Multi-BERT ensemble ap- proach for the recognition of Bangla medical entity,”arXiv preprint arXiv:2512.17769v1, 2025
-
[6]
Named entity recognition for AI-driven medical text processing in the silicon revolution,
H. Wei and Y . Zhang, “Named entity recognition for AI-driven medical text processing in the silicon revolution,”IEEE Access, 2025
2025
-
[7]
An overview of biomedical entity linking throughout the years,
E. French and B. T. McInnes, “An overview of biomedical entity linking throughout the years,”Journal of Biomedical Informatics, vol. 137, p. 104252, 2023
2023
-
[8]
Neural architectures for named entity recognition,
G. Lample et al., “Neural architectures for named entity recognition,” inProc. NAACL-HLT, 2016, pp. 260–270
2016
-
[9]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProc. NAACL-HLT, 2019, pp. 4171–4186
2019
-
[10]
BANNER: A cost-sensitive contextualized model for Bangla named entity recognition,
I. Ashrafi et al., “BANNER: A cost-sensitive contextualized model for Bangla named entity recognition,”IEEE Access, vol. 8, pp. 58206– 58226, 2020
2020
-
[11]
B-NER: A novel Bangla named entity recog- nition dataset with largest entities,
M. ZHz H. Alvi et al., “B-NER: A novel Bangla named entity recog- nition dataset with largest entities,”IEEE Access, vol. 11, pp. 45194– 45205, 2023
2023
-
[12]
BanglaMedNER: A gold standard medical named entity recognition corpus for Bangla text,
A. Muntakim, F. Sadaf, and K. A. Hasan, “BanglaMedNER: A gold standard medical named entity recognition corpus for Bangla text,” in Proc. 6th Int. Conf. EICT, IEEE, 2023, pp. 1–6
2023
-
[13]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” inNIPS Deep Learning and Representation Learning Workshop, 2015
2015
-
[14]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter,”arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[15]
TinyBERT: Distilling BERT for natural language under- standing,
X. Jiao et al., “TinyBERT: Distilling BERT for natural language under- standing,” inFindings of EMNLP, 2020, pp. 4163–4174
2020
-
[16]
MiniLM: Deep self-attention distillation for task- agnostic compression of pre-trained transformers,
W. Wang et al., “MiniLM: Deep self-attention distillation for task- agnostic compression of pre-trained transformers,” inNeurIPS, 2020
2020
-
[17]
Quantization and training of neural networks for effi- cient integer-arithmetic-only inference,
B. Jacob et al., “Quantization and training of neural networks for effi- cient integer-arithmetic-only inference,” inProc. CVPR, 2018, pp. 2704– 2713
2018
-
[18]
I-BERT: Integer-only BERT quantization,
S. Kim et al., “I-BERT: Integer-only BERT quantization,” inProc. ICML, 2021, pp. 5506–5515
2021
-
[19]
BanglaBERT: Language model pretraining and benchmarks for low-resource language understanding,
A. Bhattacharjee et al., “BanglaBERT: Language model pretraining and benchmarks for low-resource language understanding,” inFindings of NAACL, 2022
2022
-
[20]
Small and practical BERT models for sequence labeling,
H.-Y . Tsai et al., “Small and practical BERT models for sequence labeling,” inProc. EMNLP-IJCNLP, 2019, pp. 3622–3631
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.