Accelerated Dynamic Importance Weighting with Versatile Divergence-Minimizing Estimators
Pith reviewed 2026-06-29 22:45 UTC · model grok-4.3
The pith
ADIW replaces full per-batch optimization in dynamic importance weighting with a few warm-started projected gradient steps and supports multiple divergence measures for estimating test-to-train density ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
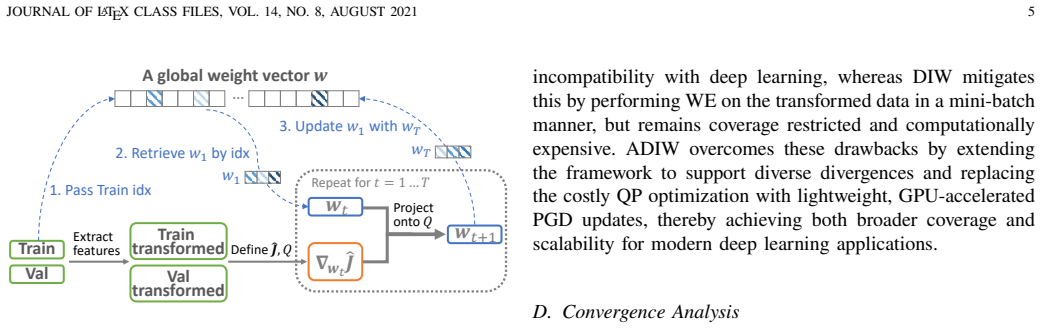
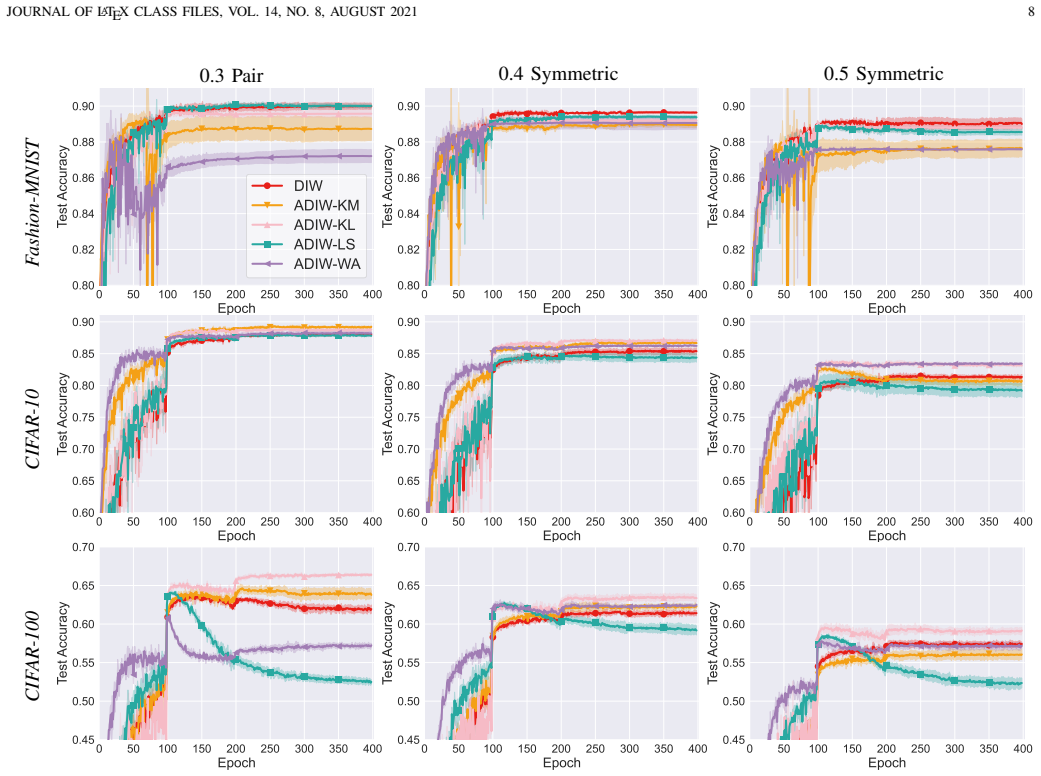
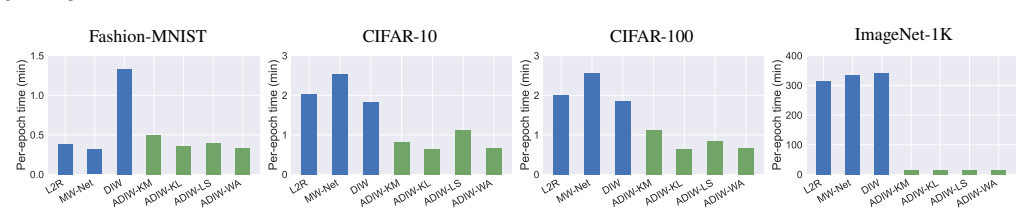
ADIW performs a small fixed number of projected gradient descent updates, warm-started from the weights of the prior mini-batch, inside a generalized divergence-minimization objective that accepts any of several estimators; this produces importance weights that reweight training losses to match the test distribution, achieves state-of-the-art performance, and runs substantially faster than solving the original kernel mean matching problem to convergence each batch.
What carries the argument
Warm-started projected gradient descent steps inside a unified divergence-minimization framework that replaces the per-batch kernel mean matching solve.
If this is right
- Diverse weight estimators based on Kullback-Leibler, squared, or Wasserstein-1 divergences become interchangeable inside the same training loop.
- Computational cost per mini-batch drops from a full optimization solve to a handful of gradient steps.
- Convergence of the overall procedure holds under the stated mild conditions on the step count and warm-start.
- The method scales to large modern datasets where earlier dynamic importance weighting was too slow.
Where Pith is reading between the lines
- The same warm-start trick could be tested on other per-batch optimization subproblems that arise in online or continual learning.
- Performance on very rapid distribution shifts might degrade if the warm-start becomes a poor initializer between consecutive batches.
- Plugging in new divergence estimators requires only that the estimator admit a differentiable objective compatible with the projection step.
Load-bearing premise
A small fixed number of projected gradient steps per mini-batch, initialized from the previous solution, produces weights close enough to the exact per-batch optimum that final model performance and convergence guarantees remain intact.
What would settle it
An experiment on a standard joint distribution shift benchmark in which increasing the number of gradient steps per batch beyond the paper's fixed small count produces a statistically significant rise in test accuracy would show the lightweight updates are insufficient.
Figures

read the original abstract
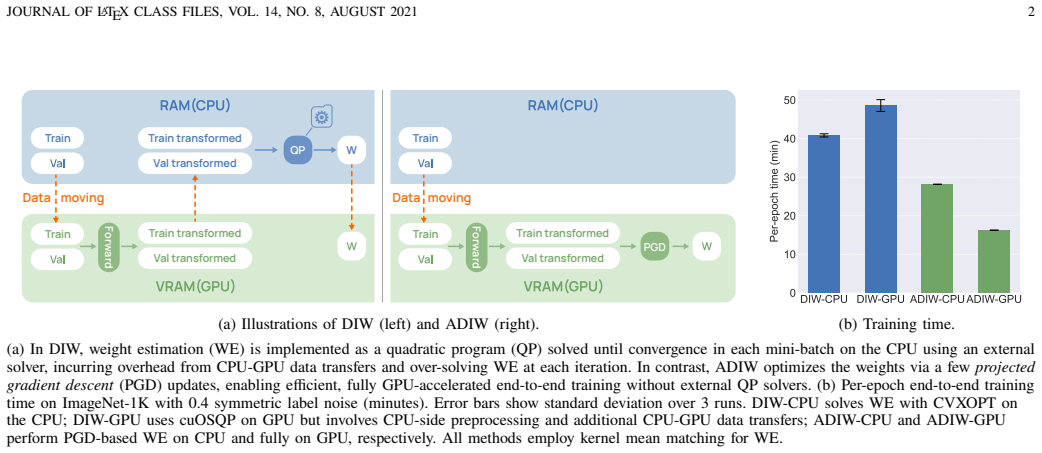
Importance weighting (IW) is a golden solver for joint distribution shift, where the joint distributions differ between the training and test data. To solve this problem, IW estimates test-to-training density ratios as importance weights and reweights the training losses accordingly. Recent advances in dynamic IW (DIW) integrate weight estimation into model training, enabling scalable IW for deep models and achieving strong performance on large modern datasets. Despite its promise, DIW remains limited in two aspects. First, it incurs substantial computational overhead by solving a kernel mean matching (KMM)-induced optimization problem to convergence in every mini-batch. Second, it relies solely on KMM for weight estimation, whereas the IW literature contains diverse estimation methods based on different divergence measures. In this paper, we propose accelerated DIW (ADIW), a unified and efficient IW framework for deep learning under joint distribution shift. ADIW performs a few lightweight projected gradient descent updates that warm-start from previously updated weights, substantially improving efficiency. Moreover, ADIW generalizes DIW into a unified divergence-minimization framework that supports diverse weight-estimation methods in a plug-and-play manner, including those based on the Kullback-Leibler divergence, squared distance, and Wasserstein-1 distance. We establish convergence guarantees for ADIW under mild conditions, and empirical results demonstrate that ADIW achieves state-of-the-art IW performance while being substantially more efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Accelerated Dynamic Importance Weighting (ADIW) as an efficient generalization of Dynamic Importance Weighting (DIW). It replaces per-mini-batch exact optimization of kernel mean matching (KMM) with a small fixed number of warm-started projected gradient descent (PGD) steps and extends the framework to a unified divergence-minimization setting supporting KL, squared-distance, and Wasserstein-1 estimators. Convergence guarantees are claimed under mild conditions, and experiments are said to show state-of-the-art IW performance with substantially lower computational cost.
Significance. If the approximation error induced by the fixed-step warm-started PGD procedure can be shown to remain controlled and the stated convergence guarantees can be extended to the inexact iterates, the work would provide a practical, plug-and-play acceleration for dynamic importance weighting under joint distribution shift. The unification across multiple divergences is a useful organizational contribution, but the efficiency and theoretical claims rest on the quality of the per-batch approximation.
major comments (2)
- [§4] §4 (Convergence Analysis): The theorems establish convergence for the exact per-batch minimizer of the chosen divergence objective. The algorithm description in §3.2 instead performs a fixed small number of warm-started PGD steps; no explicit bound on the resulting approximation error (or extension of the guarantees to inexact iterates) is provided. This gap directly affects both the formal claims and the empirical performance assertions.
- [§3.2] §3.2 and Algorithm 1: The choice of step count, step-size schedule, and projection radius are presented as fixed hyperparameters. No sensitivity analysis or worst-case deviation from the true per-batch optimum is reported for non-quadratic divergences (KL, W1), which are known to be more sensitive to early stopping than the original KMM quadratic objective.
minor comments (2)
- Notation for the generalized divergence objective (Eq. (7) or equivalent) should explicitly distinguish the exact minimizer from the PGD iterate used in practice.
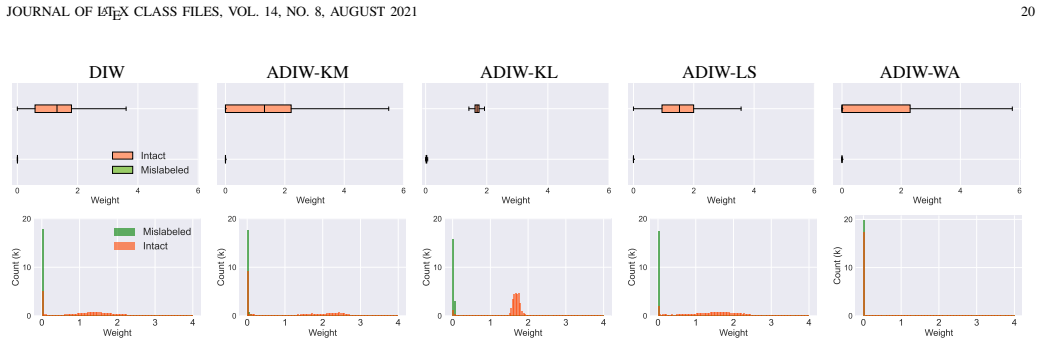
- Table 2 and Figure 3: clarify whether the reported runtimes include the cost of the warm-start initialization or only the PGD steps themselves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Convergence Analysis): The theorems establish convergence for the exact per-batch minimizer of the chosen divergence objective. The algorithm description in §3.2 instead performs a fixed small number of warm-started projected gradient descent (PGD) steps; no explicit bound on the resulting approximation error (or extension of the guarantees to inexact iterates) is provided. This gap directly affects both the formal claims and the empirical performance assertions.
Authors: We acknowledge that the convergence theorems in §4 are stated for the exact per-batch minimizer of the divergence objective. The ADIW procedure in §3.2 approximates this minimizer via a small fixed number of warm-started PGD steps. While the warm-start exploits the slow variation of weights across consecutive mini-batches, the manuscript does not supply an explicit approximation-error bound or an extension of the guarantees to inexact iterates. This is a valid observation. In the revision we will add a paragraph clarifying the relationship between the exact and inexact settings and, where feasible under the existing mild assumptions, provide a simple error bound that depends on the number of PGD steps and the warm-start quality. revision: yes
-
Referee: [§3.2] §3.2 and Algorithm 1: The choice of step count, step-size schedule, and projection radius are presented as fixed hyperparameters. No sensitivity analysis or worst-case deviation from the true per-batch optimum is reported for non-quadratic divergences (KL, W1), which are known to be more sensitive to early stopping than the original KMM quadratic objective.
Authors: The PGD hyperparameters are indeed fixed after a modest validation-set search and are used uniformly for all reported experiments. For the quadratic KMM objective the early-stopping behavior is relatively benign, but the referee correctly notes that KL and Wasserstein-1 objectives can be more sensitive. The original submission does not contain a sensitivity study or worst-case deviation metrics for these non-quadratic cases. We agree that such an analysis would strengthen the practical claims and will include it (empirical deviation plots and a short discussion of step-count sensitivity) in an appendix of the revised manuscript. revision: yes
Circularity Check
No circularity; derivation is self-contained
full rationale
The paper proposes ADIW as an acceleration of prior DIW via a fixed number of warm-started PGD steps plus a plug-and-play generalization to multiple divergences (KL, squared, W1), together with separate convergence analysis under mild conditions. No load-bearing step in the abstract or description reduces a claimed result (performance or guarantees) to fitted inputs by construction, nor depends on self-citation chains or imported uniqueness theorems. The central efficiency and unification claims rest on the explicit algorithmic change and the stated analysis rather than tautological re-use of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Convergence guarantees hold under mild conditions
Reference graph
Works this paper leans on
-
[1]
Quionero-Candela, M
J. Quionero-Candela, M. Sugiyama, A. Schwaighofer, and N. Lawrence,Dataset shift in machine learning. Cambridge, MA: The MIT Press, 2009
2009
-
[2]
A survey on transfer learning,
S. Pan and Q. Yang, “A survey on transfer learning,” IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345–1359, 2009
2009
-
[3]
Improving predictive inference under covariate shift by weighting the log-likelihood function,
H. Shimodaira, “Improving predictive inference under covariate shift by weighting the log-likelihood function,” Journal of Statistical Planning and Inference, vol. 90, no. 2, pp. 227–244, 2000
2000
-
[4]
Covariate shift adaptation by importance weighted cross valida- tion,
M. Sugiyama, M. Krauledat, and K. M¨ uller, “Covariate shift adaptation by importance weighted cross valida- tion,”Journal of Machine Learning Research, vol. 8, no. 5, pp. 985–1005, 2007
2007
-
[5]
What is the effect of impor- tance weighting in deep learning?
J. Byrd and Z. C. Lipton, “What is the effect of impor- tance weighting in deep learning?” inProceedings of the International Conference on Machine Learning (ICML), 2019
2019
-
[6]
Rethinking importance weighting for deep learning under distribu- tion shift,
T. Fang, N. Lu, G. Niu, and M. Sugiyama, “Rethinking importance weighting for deep learning under distribu- tion shift,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[7]
Correcting sample selection bias by unla- beled data,
J. Huang, A. Gretton, K. Borgwardt, B. Sch ¨olkopf, and A. Smola, “Correcting sample selection bias by unla- beled data,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2007
2007
-
[8]
GPU acceler- ation of ADMM for large-scale quadratic programming,
M. Schubiger, G. Banjac, and J. Lygeros, “GPU acceler- ation of ADMM for large-scale quadratic programming,” Journal of Parallel and Distributed Computing, vol. 144, pp. 55–67, 2020
2020
-
[9]
Direct importance estimation with model selection and its application to covariate shift adaptation,
M. Sugiyama, S. Nakajima, H. Kashima, P. Buenau, and M. Kawanabe, “Direct importance estimation with model selection and its application to covariate shift adaptation,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2007
2007
-
[10]
A least-squares approach to direct importance estimation,
T. Kanamori, S. Hido, and M. Sugiyama, “A least-squares approach to direct importance estimation,”Journal of Machine Learning Research, vol. 10, no. 7, pp. 1391– 1445, 2009
2009
-
[11]
Density- ratio matching under the Bregman divergence: a unified framework of density-ratio estimation,
M. Sugiyama, T. Suzuki, and T. Kanamori, “Density- ratio matching under the Bregman divergence: a unified framework of density-ratio estimation,”Annals of the Institute of Statistical Mathematics, vol. 64, pp. 1009– 1044, 2012
2012
-
[12]
The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming,
L. M. Bregman, “The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming,”USSR Computational Mathematics and Mathematical Physics, vol. 7, no. 3, pp. 200–217, 1967
1967
-
[13]
Im- portance weighting for aligning language models under deployment distribution shift,
T. Lodkaew, T. Fang, T. Ishida, and M. Sugiyama, “Im- portance weighting for aligning language models under deployment distribution shift,”Transactions on Machine Learning Research, 2025
2025
-
[14]
Importance-weighted positive-unlabeled learning for distribution shift adaptation,
A. Kumagai, T. Iwata, H. Takahashi, T. Nishiyama, and Y. Fujiwara, “Importance-weighted positive-unlabeled learning for distribution shift adaptation,” inProceedings JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 of the International Conference on Artificial Intelligence and Statistics (AISTATS), 2025
2021
-
[15]
Constrained minimiza- tion methods,
E. S. Levitin and B. T. Polyak, “Constrained minimiza- tion methods,”USSR Computational Mathematics and Mathematical Physics, vol. 6, no. 5, pp. 1–50, 1966
1966
-
[16]
Integral probability metrics and their gener- ating classes of functions,
A. M¨ uller, “Integral probability metrics and their gener- ating classes of functions,”Advances in Applied Proba- bility, vol. 29, no. 2, pp. 429–443, 1997
1997
-
[17]
A general class of coefficients of divergence of one distribution from another,
S. M. Ali and S. D. Silvey, “A general class of coefficients of divergence of one distribution from another,”Journal of the Royal Statistical Society: Series B (Methodologi- cal), vol. 28, no. 1, pp. 131–142, 1966
1966
-
[18]
Markov processes over denumerable products of spaces describing large system of automata,
L. N. Vaserstein, “Markov processes over denumerable products of spaces describing large system of automata,” Problems Inform. Transmission, vol. 5, no. 3, pp. 47–52, 1969
1969
-
[19]
On choosing and bound- ing probability metrics,
A. L. Gibbs and F. E. Su, “On choosing and bound- ing probability metrics,”International Statistical Review, vol. 70, no. 3, pp. 419–435, 2002
2002
-
[20]
Integrating structured biological data by kernel maximum mean discrepancy,
K. M. Borgwardt, A. Gretton, M. J. Rasch, H.-P. Kriegel, B. Sch ¨olkopf, and A. J. Smola, “Integrating structured biological data by kernel maximum mean discrepancy,” Bioinformatics, vol. 22, no. 14, pp. e49–e57, 2006
2006
-
[21]
A kernel two-sample test,
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch ¨olkopf, and A. Smola, “A kernel two-sample test,”Journal of Machine Learning Research, vol. 13, no. 25, pp. 723– 773, 2012
2012
-
[22]
Hilbert space em- beddings and metrics on probability measures,
B. K. Sriperumbudur, A. Gretton, K. Fukumizu, B. Sch ¨olkopf, and G. R. Lanckriet, “Hilbert space em- beddings and metrics on probability measures,”Journal of Machine Learning Research, vol. 11, no. 50, pp. 1517– 1561, 2010
2010
-
[23]
Kernel measures of conditional dependence,
K. Fukumizu, A. Gretton, X. Sun, and B. Sch ¨olkopf, “Kernel measures of conditional dependence,” inPro- ceedings of the Advances in Neural Information Process- ing Systems (NeurIPS), 2007
2007
-
[24]
On information and suf- ficiency,
S. Kullback and R. A. Leibler, “On information and suf- ficiency,”The Annals of Mathematical Statistics, vol. 22, no. 1, pp. 79–86, 1951
1951
-
[25]
Neue begr¨ undung der theorie quadratischer formen von unendlichvielen ver¨anderlichen
E. Hellinger, “Neue begr¨ undung der theorie quadratischer formen von unendlichvielen ver¨anderlichen.”Journal f ¨ur die reine und angewandte Mathematik, vol. 136, pp. 210– 271, 1909
1909
-
[26]
Confliction of the convexity and metric properties in f-divergences,
M. Khosravifard, D. Fooladivanda, and T. A. Gulliver, “Confliction of the convexity and metric properties in f-divergences,”IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, vol. 90, no. 9, pp. 1848–1853, 2007
2007
-
[27]
The earth mover’s distance as a metric for image retrieval,
Y. Rubner, C. Tomasi, and L. J. Guibas, “The earth mover’s distance as a metric for image retrieval,”Inter- national Journal of Computer Vision, vol. 40, no. 2, pp. 99–121, 2000
2000
-
[28]
Villani,Topics in optimal transportation, ser
C. Villani,Topics in optimal transportation, ser. Graduate Studies in Mathematics. Providence, RI: American Mathematical Society, 2003, vol. 58
2003
-
[29]
Wasserstein generative adversarial networks,
M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein generative adversarial networks,” inProceedings of the International Conference on Machine Learning (ICML), 2017
2017
-
[30]
Improved training of Wasserstein GANs,
I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C. Courville, “Improved training of Wasserstein GANs,” inProceedings of the Advances in Neural Infor- mation Processing Systems (NeurIPS), 2017
2017
-
[31]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747v2, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” University of Toronto, Tech. Rep., 2009
2009
-
[33]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,”International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[34]
Gradient-based learning applied to document recogni- tion,
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recogni- tion,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278– 2324, 1998
1998
-
[35]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,”The Annals of Mathematical Statistics, vol. 22, no. 3, pp. 400–407, 1951
1951
-
[36]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[37]
Adam: A method for stochas- tic optimization,
D. P. Kingma and J. L. Ba, “Adam: A method for stochas- tic optimization,” inProceedings of the International Conference on Learning Representations (ICLR), 2015
2015
-
[38]
Learn- ing to reweight examples for robust deep learning,
M. Ren, W. Zeng, B. Yang, and R. Urtasun, “Learn- ing to reweight examples for robust deep learning,” in Proceedings of the International Conference on Machine Learning (ICML), 2018
2018
-
[39]
Meta-weight-net: Learning an explicit mapping for sample weighting,
J. Shu, Q. Xie, L. Yi, Q. Zhao, S. Zhou, Z. Xu, and D. Meng, “Meta-weight-net: Learning an explicit mapping for sample weighting,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[40]
A systematic study of the class imbalance problem in convolutional neural networks,
M. Buda, A. Maki, and M. A. Mazurowski, “A systematic study of the class imbalance problem in convolutional neural networks,”Neural Networks, vol. 106, pp. 249– 259, 2018
2018
-
[41]
Co-teaching: Robust training of deep neural networks with extremely noisy labels,
B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural networks with extremely noisy labels,” inProceed- ings of the Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[42]
Learning with symmetric label noise: The importance of being unhinged,
B. Van Rooyen, A. Menon, and R. C. Williamson, “Learning with symmetric label noise: The importance of being unhinged,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[43]
Learning under concept drift: A review,
J. Lu, A. Liu, F. Dong, F. Gu, J. Gama, and G. Zhang, “Learning under concept drift: A review,”IEEE transac- tions on knowledge and data engineering, vol. 31, no. 12, pp. 2346–2363, 2018
2018
-
[44]
N. Lu, T. Zhang, T. Fang, T. Teshima, and M. Sugiyama, Rethinking Importance Weighting for Transfer Learning. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 Cham: Springer International Publishing, 2023, pp. 185– 231
2021
-
[45]
Deep visual domain adaptation: A survey,
M. Wang and W. Deng, “Deep visual domain adaptation: A survey,”Neurocomputing, vol. 312, pp. 135–153, 2018
2018
-
[46]
Learning transferable features with deep adaptation networks,
M. Long, Y. Cao, J. Wang, and M. Jordan, “Learning transferable features with deep adaptation networks,” in Proceedings of the International Conference on Machine Learning (ICML), 2015
2015
-
[47]
Domain-adversarial training of neural networks,
Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. March, and V. Lempit- sky, “Domain-adversarial training of neural networks,” Journal of Machine Learning Research, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[48]
Adver- sarial discriminative domain adaptation,
E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, “Adver- sarial discriminative domain adaptation,” inProceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2017
2017
-
[49]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural net- works,
D.-H. Leeet al., “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural net- works,” inInternational Conference on Machine Learn- ing (ICML) Workshop, 2013
2013
-
[50]
Asymmetric tri- training for unsupervised domain adaptation,
K. Saito, Y. Ushiku, and T. Harada, “Asymmetric tri- training for unsupervised domain adaptation,” inPro- ceedings of the International Conference on Machine Learning (ICML), 2017
2017
-
[51]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming,
S. Ghadimi and G. Lan, “Stochastic first-and zeroth-order methods for nonconvex stochastic programming,”SIAM Journal on Optimization, vol. 23, no. 4, pp. 2341–2368, 2013
2013
-
[52]
arXiv preprint arXiv:2301.11235 , year=
G. Garrigos and R. M. Gower, “Handbook of conver- gence theorems for (stochastic) gradient methods,”arXiv preprint arXiv:2301.11235, 2023. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 Appendix A Discussion of IW and DA Approaches under Distribution Shift This section briefly reviews distribution shift and representative approaches for hand...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.