SAE-FD: Sparse Autoencoder Feature Distillation for Continual Learning of Large Language Models
Pith reviewed 2026-06-29 22:36 UTC · model grok-4.3
The pith
Anchoring representations in a pre-trained sparse autoencoder basis allows more selective regularization that reduces interference with new tasks in continual LLM learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
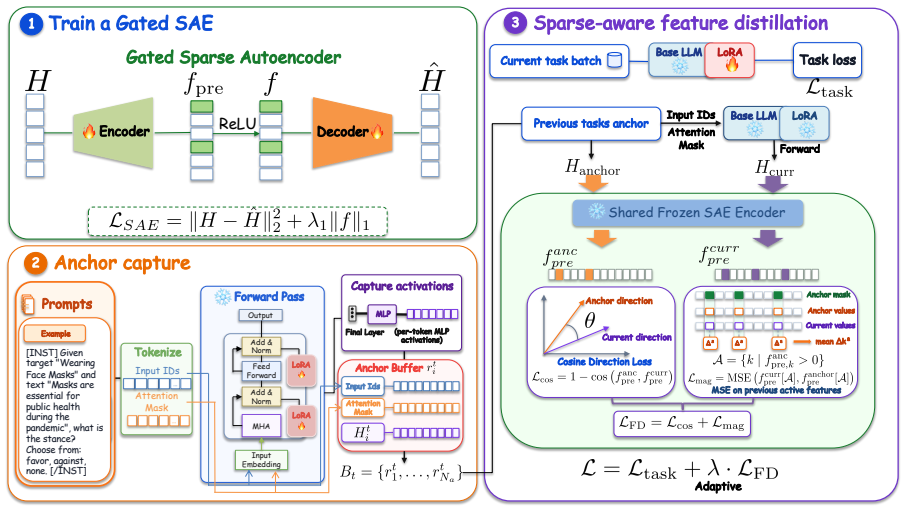
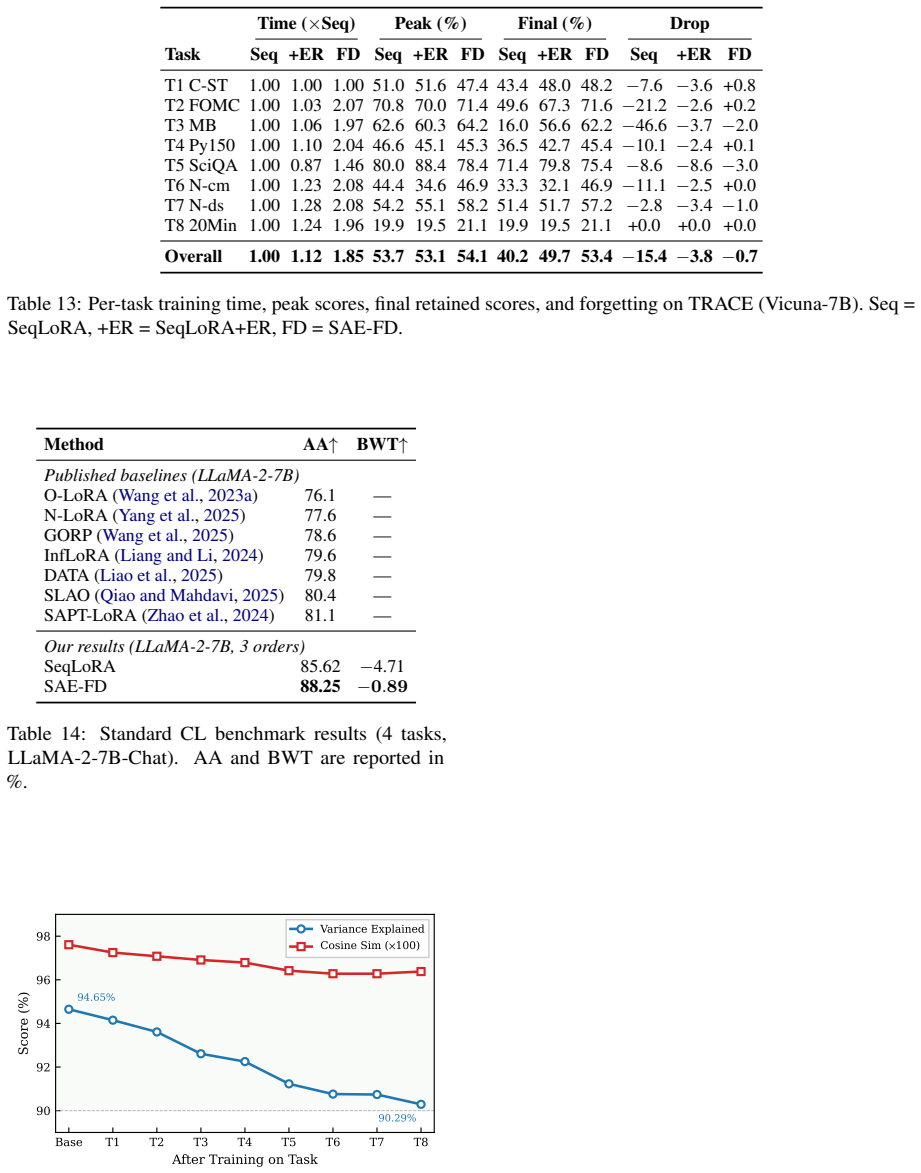
SAE-FD anchors model representations in the sparse feature space of a pre-trained Sparse Autoencoder, where dense activations are decomposed into a sparse overcomplete basis that reduces representational entanglement, enabling more targeted regularization with less interference to new-task learning. On two continual learning benchmarks across three model architectures the method reaches up to 52.70 percent average accuracy with only -0.46 backward transfer and consistently beats existing regularization baselines.
What carries the argument
The pre-trained Sparse Autoencoder's sparse overcomplete basis, which decomposes each dense activation vector into a small number of active features so that regularization can target individual concepts rather than entangled dimensions.
If this is right
- Regularization applied to sparse SAE coefficients interferes less with gradient updates for new tasks than regularization applied to dense activations.
- Previously learned knowledge can be protected more selectively because each sparse feature corresponds to a narrower set of concepts than a dense dimension.
- The same pre-trained SAE can be reused across multiple sequential tasks without retraining the autoencoder itself.
- Average task accuracy improves while backward transfer stays near zero across different model scales.
Where Pith is reading between the lines
- If the SAE basis remains stable across task distributions, the same distillation step could be inserted into other regularization or replay methods to reduce their interference cost.
- Sparse coefficients might allow post-hoc inspection of which concepts are being protected during a continual-learning run.
- The approach could extend to settings where the base model is updated infrequently and only the sparse projection is adjusted between tasks.
Load-bearing premise
Feature superposition in dense spaces is the main obstacle to selective protection of prior knowledge, and a single pre-trained SAE basis will reliably separate task-relevant concepts across an arbitrary sequence of future tasks without introducing new interference or information loss.
What would settle it
An experiment that applies identical regularization strength directly in the original dense activation space and obtains equal or higher average accuracy with equal or lower backward transfer than SAE-FD on the same benchmarks.
Figures
read the original abstract
Continual learning enables large language models to adapt to evolving tasks without retraining from scratch, yet catastrophic forgetting remains a central obstacle. Among continual learning methods, regularization-based approaches are widely used to constrain model updates and reduce forgetting, operating in weight space, gradient space, or output space. However, these dense representation spaces suffer from feature superposition, where multiple concepts are encoded in overlapping dimensions, making it difficult to selectively protect previously learned knowledge without impeding new-task learning. To address this issue, we propose \method (Sparse Autoencoder Feature Distillation), which anchors model representations in the sparse feature space of a pre-trained Sparse Autoencoder, where dense activations are decomposed into a sparse overcomplete basis that reduces representational entanglement, enabling more targeted regularization with less interference to new-task learning. Experiments on two continual learning benchmarks across three model architectures show that \method consistently outperforms existing regularization-based methods, achieving up to 52.70% average accuracy with only -0.46 backward transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAE-FD, a regularization-based continual learning method for LLMs that distills knowledge by anchoring representations in the sparse overcomplete feature space of a pre-trained Sparse Autoencoder rather than dense activation spaces. This is claimed to reduce feature superposition and entanglement, enabling more selective protection of prior tasks with less interference to new-task learning. Experiments across two benchmarks and three model architectures report consistent outperformance over prior regularization methods, with peak results of 52.70% average accuracy and -0.46 backward transfer.
Significance. If the empirical gains hold under proper controls, the work would demonstrate that shifting regularization into a fixed sparse SAE basis can mitigate a key limitation of dense-space methods in continual learning. This could be of moderate significance for the field, as it offers a concrete mechanism (sparse decomposition) to address representational interference without requiring changes to the core model architecture. The multi-architecture, multi-benchmark evaluation is a positive aspect.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The reported metrics (52.70% average accuracy, -0.46 BWT) are presented without any information on number of runs, standard deviations, statistical significance tests, hyperparameter search protocol, or baseline implementation details. This makes it impossible to determine whether the claimed consistent outperformance is robust or could be explained by uncontrolled factors.
- [§3 and §2] §3 (Method) and §2 (Related Work): The central justification—that a pre-trained SAE's sparse basis reliably decomposes activations from all tasks in the continual-learning sequence into less entangled features—is load-bearing for the claimed advantage over dense regularization. However, the manuscript provides no description of the SAE's training corpus relative to the two CL benchmarks, leaving open the possibility that distribution mismatch produces poor reconstructions or new feature overlap, directly undermining the premise.
minor comments (1)
- [§3] Notation for the SAE reconstruction loss and the distillation term should be unified across equations to avoid ambiguity between the fixed SAE and the evolving model.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The reported metrics (52.70% average accuracy, -0.46 BWT) are presented without any information on number of runs, standard deviations, statistical significance tests, hyperparameter search protocol, or baseline implementation details. This makes it impossible to determine whether the claimed consistent outperformance is robust or could be explained by uncontrolled factors.
Authors: We agree that these experimental details are necessary for evaluating robustness. In the revised manuscript we will report the number of runs (5 independent random seeds), mean and standard deviation for all metrics, results of statistical significance tests against baselines, the full hyperparameter search protocol including ranges explored, and precise implementation details for each baseline. revision: yes
-
Referee: [§3 and §2] §3 (Method) and §2 (Related Work): The central justification—that a pre-trained SAE's sparse basis reliably decomposes activations from all tasks in the continual-learning sequence into less entangled features—is load-bearing for the claimed advantage over dense regularization. However, the manuscript provides no description of the SAE's training corpus relative to the two CL benchmarks, leaving open the possibility that distribution mismatch produces poor reconstructions or new feature overlap, directly undermining the premise.
Authors: We agree that the manuscript must supply this information to support the central claim. In the revision we will add an explicit description of the SAE training corpus and its relation to the CL benchmarks, along with any available reconstruction-quality analysis on benchmark data to address concerns about mismatch or entanglement. revision: yes
Circularity Check
No significant circularity; proposal is an independent modeling choice
full rationale
The abstract and provided text present SAE-FD as a new regularization approach that chooses to operate in the sparse feature space of an externally pre-trained SAE. No equations, derivations, or fitted parameters are shown that reduce the claimed reduction in entanglement or improved continual-learning performance to a quantity defined by the method itself. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the text. The central claim rests on the external properties of SAEs rather than re-expressing the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526. Zhizhong Li and Derek Hoiem. 2017. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947. Yan-Shuo Liang and Wu-Jun Li. 2024. InfLoRA: Interference-free low-rank adaptation for con...
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Progressive prompts: Continual learning for language models. InInternational Conference on Learning Representations. Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameber, Andy Jones, Hoagy Cunningham, Nicholas L. Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Free- man, T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.