Action-Prior Denoising for Smooth Real-Time Chunking
Pith reviewed 2026-06-29 21:59 UTC · model grok-4.3
The pith
Soft real-time chunking with action-prior denoising matches hard RTC solve rates while reducing action jerk by 9.6%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Soft RTC generalizes hard training-time RTC by constructing corrupted overlap tokens from partially denoised states rather than pure noise and injecting the aligned previous chunk as prior via token-wise blending at inference, allowing overlap actions to stay close to the previous plan while remaining editable.
What carries the argument
Action-prior denoising that builds corrupted tokens from partial denoising and applies lightweight token-wise blending with the previous chunk.
If this is right
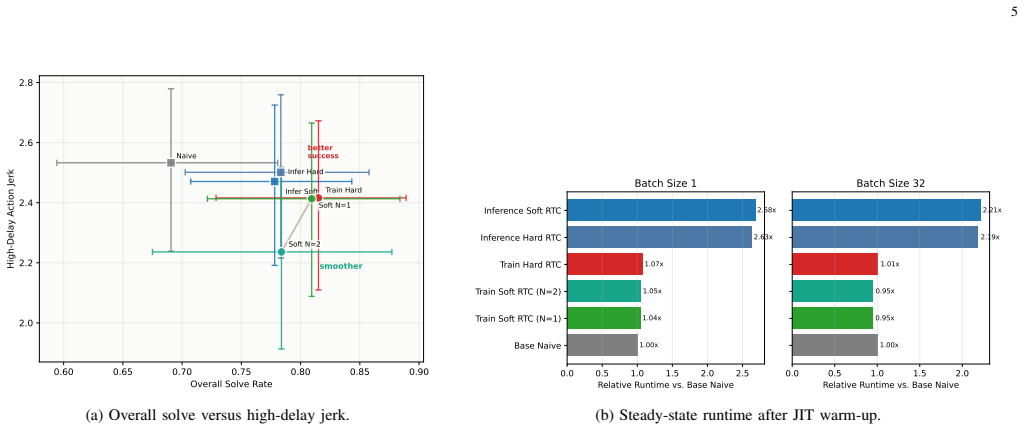
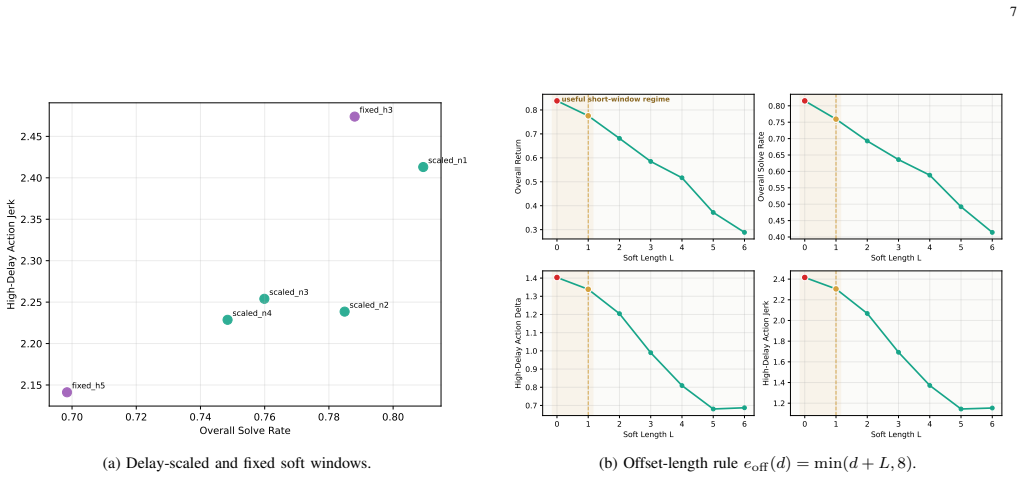
- Short soft window achieves solve rate of 0.809 compared to 0.815 for hard RTC on Kinetix levels.
- Medium soft window reduces high-delay action delta by 9.1% and jerk by 9.6%.
- Both soft variants maintain near-naive runtime unlike inference-time baselines.
- Training-time RTC improves completion in preliminary real-robot sorting study.
- Soft RTC achieves the lowest commanded-action finite-difference metrics among tested policies.
Where Pith is reading between the lines
- Soft RTC could extend to other diffusion policy applications where smooth transitions between plans are needed.
- Lower jerk might lead to more reliable long-term robot operation by reducing mechanical stress.
- Further validation on diverse tasks could test if the blending rule introduces biases in highly dynamic environments.
- The approach suggests that modeling partial constraints in chunk overlap can improve policy smoothness without added computation.
Load-bearing premise
The method of building corrupted overlap tokens from partially denoised states and blending at inference correctly captures asynchronous execution constraints without adding biases or needing retraining.
What would settle it
Observing that soft window policies show solve rates significantly below 0.809 or jerk reductions fail to appear on new levels with different delay characteristics would challenge the claim.
Figures


read the original abstract
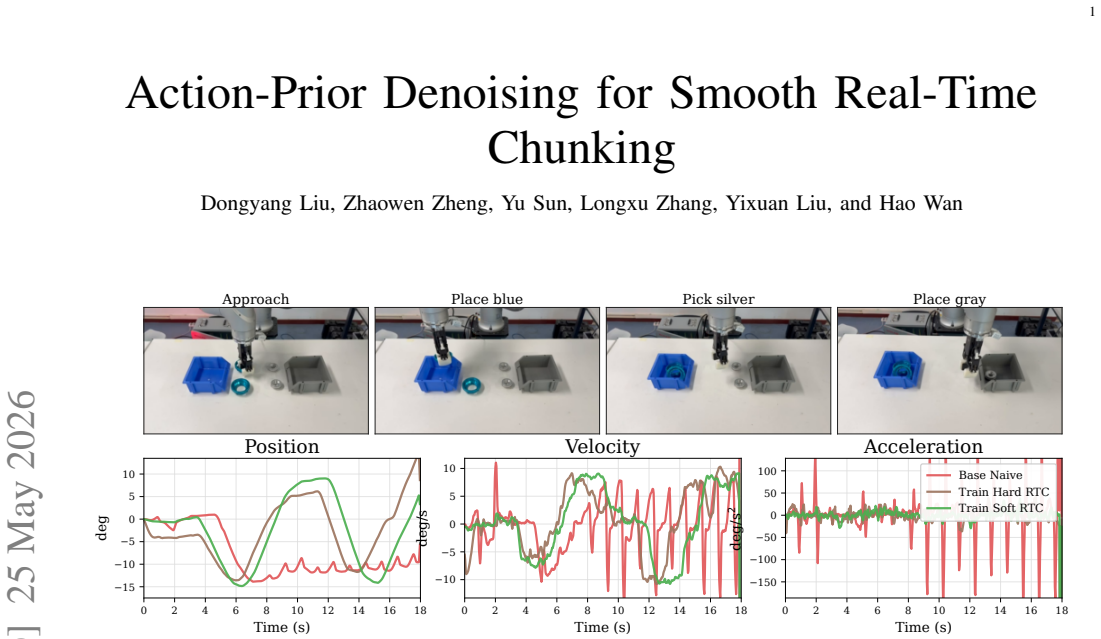
Real-time chunking (RTC) lets chunked action policies operate under inference delay by conditioning a newly generated action chunk on actions already committed by the previous chunk. Training-time RTC simulates this delay during learning and avoids expensive guidance at deployment, but its binary prefix mask treats all non-prefix tokens as fully unconstrained. This under-models asynchronous execution: early overlap actions are fixed, while later overlap actions remain editable but should still stay close to the previous plan. We propose Soft RTC, a training-time RTC generalization based on action-prior denoising. Soft RTC constructs corrupted overlap tokens from partially denoised states instead of pure noise and injects the aligned previous chunk as the same prior during inference through a lightweight token-wise blending rule. On the 12 released large Kinetix levels, a short soft window nearly matches hard training-time RTC in overall solve rate (0.809 vs. 0.815), while a medium window reduces high-delay action delta and jerk by 9.1% and 9.6% relative to hard RTC. Both variants keep near-naive runtime, unlike inference-time RTC baselines. A small preliminary real-robot sorting study provides additional evidence that training-time RTC can improve completion and that Soft RTC gives the lowest commanded-action finite-difference metrics among the tested policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Soft RTC as a training-time generalization of real-time chunking (RTC) for chunked action policies. It replaces the binary prefix mask with action-prior denoising: corrupted overlap tokens are built from partially denoised states, and the aligned previous chunk is injected as a prior at inference via a lightweight token-wise blending rule. On the 12 released large Kinetix levels, a short soft window reaches a solve rate of 0.809 (vs. 0.815 for hard RTC) while a medium window reduces high-delay action delta and jerk by 9.1% and 9.6% relative to hard RTC; both retain near-naive runtime. A preliminary real-robot sorting study is also reported.
Significance. If the results hold after proper statistical validation and ablations, the work supplies a practical, low-overhead way to improve action smoothness under inference delay by more faithfully modeling the fixed-vs-editable distinction in overlap regions. The release of concrete solve-rate and jerk numbers on public levels is a positive feature.
major comments (2)
- [Abstract] Abstract: the central empirical claim (solve-rate parity of 0.809 vs. 0.815 and 9.1%/9.6% reductions in delta/jerk) rests on the untested modeling assumption that constructing corrupted overlap tokens from partially denoised states plus token-wise blending correctly captures asynchronous execution constraints; no ablations isolate this construction from window length or prior strength, so the reported gains could be artifacts.
- [Abstract] Abstract: the reported solve rates and percentage reductions are given without variance, standard errors, confidence intervals, or statistical tests, preventing assessment of whether the observed differences are reliable.
minor comments (1)
- [Abstract] Abstract: the metric 'high-delay action delta' is used without definition or reference to its computation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (solve-rate parity of 0.809 vs. 0.815 and 9.1%/9.6% reductions in delta/jerk) rests on the untested modeling assumption that constructing corrupted overlap tokens from partially denoised states plus token-wise blending correctly captures asynchronous execution constraints; no ablations isolate this construction from window length or prior strength, so the reported gains could be artifacts.
Authors: We agree that the manuscript lacks dedicated ablations that independently vary the denoising schedule used to construct overlap tokens or the blending coefficient while holding window length fixed. The existing hard-RTC versus Soft-RTC comparisons control for window length but do not isolate the effect of the partial-denoising construction itself. We will add an ablation section that sweeps the fraction of denoising applied to overlap tokens and the blending weight, reporting solve rate, delta, and jerk for each setting. revision: yes
-
Referee: [Abstract] Abstract: the reported solve rates and percentage reductions are given without variance, standard errors, confidence intervals, or statistical tests, preventing assessment of whether the observed differences are reliable.
Authors: The referee is correct that the reported numbers are point estimates from single training runs. We will rerun the Kinetix experiments with at least five random seeds per configuration, add standard errors to all tables and figures, and include paired statistical tests for the reported differences in solve rate, action delta, and jerk. revision: yes
Circularity Check
No significant circularity; empirical claims rest on explicit method definition and direct evaluation
full rationale
The paper defines Soft RTC explicitly via construction of corrupted overlap tokens from partially denoised states plus token-wise blending, then reports empirical solve rates (0.809 vs 0.815) and smoothness metrics on Kinetix levels. No equations, fitted parameters, or self-citations reduce these outcomes to the inputs by construction. The central claims are falsifiable performance numbers from held-out evaluation, not tautological renamings or predictions forced by the training modification itself. This matches the default expectation of a non-circular empirical methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models for action generation can be trained with modified noise schedules on overlap tokens
invented entities (1)
-
Soft RTC
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y . Galliker, and Sergey Levine. Real-Time Execu- tion of Action Chunking Flow Policies.arXiv preprint arXiv:2506.07339, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Ren, Michael Equi, and Sergey Levine
Kevin Black, Allen Z. Ren, Michael Equi, and Sergey Levine. Training- Time Action Conditioning for Efficient Real-Time Chunking.arXiv preprint arXiv:2512.05964, 2025
-
[3]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.arXiv preprint arXiv:2303.04137, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Michael Matthews, Michael Beukman, Chris Lu, and Jakob Foerster. Kinetix: Investigating the Training of General Agents through Open- Ended Physics-Based Control Tasks.arXiv preprint arXiv:2410.23208, 2024
-
[6]
doi:10.48550/arXiv.2406.07539 , abstract =
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. BAKU: An Ef- ficient Transformer for Multi-Task Policy Learning.arXiv preprint arXiv:2406.07539, 2024
-
[7]
Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior Generation with Latent Actions.arXiv preprint arXiv:2403.03181, 2024
-
[8]
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation.arXiv preprint arXiv:2405.07503, 2024
-
[9]
Behavior Transformers: Cloning k modes with one stone.arXiv preprint arXiv:2206.11251, 2022
Nur Muhammad Mahi Shafiullah, Zichen Jeff Cui, Ariuntuya Altanzaya, and Lerrel Pinto. Behavior Transformers: Cloning k modes with one stone.arXiv preprint arXiv:2206.11251, 2022
-
[10]
Kohei Sendai, Maxime Alvarez, Tatsuya Matsushima, Yutaka Matsuo, and Yusuke Iwasawa. Leave No Observation Behind: Real-time Correction for VLA Action Chunks.arXiv preprint arXiv:2509.23224, 2025
-
[11]
Real-Time Robot Execution with Masked Action Chunking.arXiv preprint arXiv:2601.20130, 2026
Haoxuan Wang, Gengyu Zhang, Yan Yan, Yuzhang Shang, Ramana Rao Kompella, and Gaowen Liu. Real-Time Robot Execution with Masked Action Chunking.arXiv preprint arXiv:2601.20130, 2026
-
[12]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.