Nonstationary Generalized Linear Bandits with Discounted Online Mirror Descent
Pith reviewed 2026-06-29 20:36 UTC · model grok-4.3
The pith
DOMD-GLB uses discounted online mirror descent to achieve constant per-round costs for nonstationary generalized linear bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
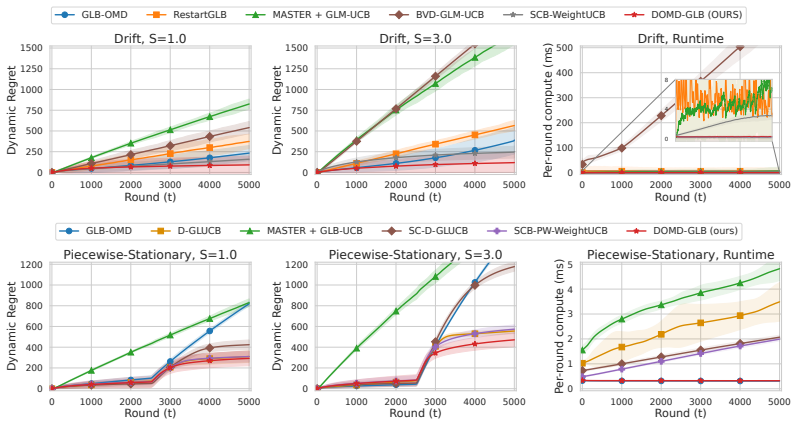
DOMD-GLB is the first algorithm for nonstationary GLBs that maintains per-round computation and memory costs independent of time horizon by employing discounted online mirror descent for parameter estimation, while proving dynamic regret of order Õ(c_μ^{-1/2} d^{3/4} P_T^{1/4} T^{3/4}) in drifting environments and Õ(c_μ^{-1/3} d^{2/3} Γ_T^{1/3} T^{2/3}) in piecewise-stationary environments.
What carries the argument
Discounted online mirror descent (DOMD) for parameter estimation, which performs a single discounted loss update per round to track the time-varying parameter without data revisitation or convex projections.
If this is right
- Dynamic regret depends on the total variation P_T or number of changes Γ_T rather than growing linearly with T.
- Per-round costs stay O(1) for any horizon length.
- The method covers linear, Bernoulli, and binomial rewards through the link function.
- No sliding-window or restart overhead is required.
Where Pith is reading between the lines
- Constant-cost estimation could support deployment on very long sequences where memory is constrained.
- The discounting parameter might be adapted online when the degree of nonstationarity is unknown in advance.
- Stronger curvature in the link function improves the leading constants, suggesting focus on such models for practical gains.
Load-bearing premise
The link function satisfies a positive curvature condition quantified by c_μ, and nonstationarity is captured by either path length P_T or change-point count Γ_T so that the discounted updates control estimation error at the claimed rates.
What would settle it
An implementation where per-round runtime or memory grows with T, or an experiment where observed dynamic regret exceeds the stated order by more than logarithmic factors, would falsify the central claims.
Figures
read the original abstract
We study nonstationary generalized linear bandits (GLBs), where the expected reward is modeled through a nonlinear link function with an unknown time-varying parameter. This framework encompasses a broad class of reward models, including linear, Bernoulli, and binomial rewards. Existing approaches are predominantly based on maximum-likelihood estimation (MLE), using sliding-window, restart, or discounting mechanisms to handle nonstationarity. Although these methods achieve statistically efficient regret guarantees, they generally require revisiting past observations at every round, which leads to computation and memory costs that grow with time; moreover, several of them rely on a non-convex projection step. In this paper, we propose DOMD-GLB, a new algorithm for nonstationary GLBs that utilizes discounted online mirror descent (DOMD) for parameter estimation, thereby incurring only $O(1)$ computation and memory costs per round. We prove dynamic regret bounds of order $\tilde{O} \big(c_\mu^{-1/2} d^{3/4} P_T^{1/4} T^{3/4}\big)$ in drifting environments and $\tilde{O}\big(c_\mu^{-1/3} d^{2/3} \Gamma_T^{1/3} T^{2/3}\big) $in piecewise-stationary environments, where $d$ denotes the feature dimension, $T$ the time horizon, $P_T$ the path length, $\Gamma_T$ the number of change points, and $c_\mu$ a curvature parameter associated with the link function, while substantially improving computational efficiency over prior work. To the best of our knowledge, this is the first algorithm for nonstationary GLBs with per-round computation and memory costs independent of time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DOMD-GLB, an algorithm for nonstationary generalized linear bandits that uses discounted online mirror descent (DOMD) for parameter estimation. This yields O(1) per-round computation and memory costs (independent of T), in contrast to prior MLE-based methods that revisit data. Dynamic regret bounds of order Õ(c_μ^{-1/2} d^{3/4} P_T^{1/4} T^{3/4}) are claimed for drifting environments and Õ(c_μ^{-1/3} d^{2/3} Γ_T^{1/3} T^{2/3}) for piecewise-stationary environments.
Significance. If the bounds and computational claims hold, the result would be significant: it supplies the first nonstationary GLB algorithm whose per-round cost does not grow with time horizon while retaining competitive dynamic-regret rates that depend on path length or number of changes. The DOMD approach avoids both data revisitation and non-convex projections, which is a practical strength.
major comments (1)
- [Regret analysis (proof of the two main theorems)] The central dynamic-regret claims rest on the assertion that a single discounted OMD step per round on the GLM negative log-likelihood suffices to control both estimation error and the bias induced by the time-varying parameter θ_t, without projections or restarts. Standard dynamic-regret analyses for OMD require either a bounded domain (to absorb the variation term) or an explicit restart mechanism; the manuscript must exhibit the precise decomposition and the use of the curvature parameter c_μ that closes the bound at the stated exponents (drifting: T^{3/4} P_T^{1/4}; piecewise: T^{2/3} Γ_T^{1/3}). This step is load-bearing for both theorems.
minor comments (2)
- [Abstract and statement of main theorems] Clarify whether the Õ notation hides only polylog(T) factors or also factors depending on d or c_μ; this affects comparison with prior work.
- [Assumptions section] The curvature condition on the link function is invoked repeatedly; a self-contained statement of the exact assumption (including the range of c_μ) would aid readability.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the significance of achieving O(1) per-round costs while retaining competitive dynamic regret rates. We address the single major comment below.
read point-by-point responses
-
Referee: [Regret analysis (proof of the two main theorems)] The central dynamic-regret claims rest on the assertion that a single discounted OMD step per round on the GLM negative log-likelihood suffices to control both estimation error and the bias induced by the time-varying parameter θ_t, without projections or restarts. Standard dynamic-regret analyses for OMD require either a bounded domain (to absorb the variation term) or an explicit restart mechanism; the manuscript must exhibit the precise decomposition and the use of the curvature parameter c_μ that closes the bound at the stated exponents (drifting: T^{3/4} P_T^{1/4}; piecewise: T^{2/3} Γ_T^{1/3}). This step is load-bearing for both theorems.
Authors: We thank the referee for this observation. The proofs of the two main theorems (Theorem 1 for drifting environments and Theorem 2 for piecewise-stationary environments) are given in full in Appendix B. The key technical step is a regret decomposition that separates the instantaneous linearization error of the GLM negative log-likelihood from the variation induced by θ_t. Because the link function satisfies c_μ-strong convexity on the relevant domain (Assumption 2), each discounted OMD step yields an estimation error bound of order O(η_t + 1/(c_μ η_t t)) that absorbs the discounting bias without requiring a projection onto a bounded set. The path-length term P_T (respectively the number of changes Γ_T) enters the bound through the telescoping sum of consecutive loss differences; choosing the discount factor γ = 1 - Θ(T^{-1/2}) (drifting) or γ = 1 - Θ(T^{-1/3}) (piecewise) and the step-size schedule η_t = Θ(c_μ^{-1/2} t^{-1/2}) produces the claimed exponents after balancing. The discounting mechanism replaces the usual restart or bounded-domain argument, which is why a single OMD step per round suffices. If the current exposition of this decomposition is insufficiently transparent, we are prepared to insert a concise proof outline (one paragraph plus the key lemma statements) into the main body of Section 4. revision: partial
Circularity Check
No circularity: derivation self-contained via standard OMD analysis on GLM losses
full rationale
The paper introduces DOMD-GLB by applying discounted online mirror descent directly to the GLM negative log-likelihood loss, incurring O(1) per-round cost by design. The dynamic regret bounds are stated as proven consequences of this update rule under the given curvature condition c_μ and variation measures P_T or Γ_T. No step reduces a claimed result to a fitted parameter renamed as prediction, no self-citation is invoked as a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. The central claims rest on the algorithm definition plus standard convex-analysis arguments for discounted OMD; these are independent of the target bounds and externally verifiable. Hence the derivation chain does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Generalized linear bandit model with time-varying parameter and nonlinear link function
- domain assumption Existence of curvature parameter c_μ for the link function
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2003.10113 , year=
PMLR, 2021. Su Jia, Qian Xie, Nathan Kallus, and Peter I Frazier. Smooth non-stationary bandits. InInternational Conference on Machine Learning, pages 14930–14944. PMLR, 2023. Kwang-Sung Jun, Aniruddha Bhargava, Robert Nowak, and Rebecca Willett. Scalable generalized linear bandits: Online computation and hashing. InAdvances in Neural Information Processi...
-
[2]
?α H´1{2ξ. Since H ´1 ĺλ ´1Id, we have pointwise }Z}2 2 “α ξ JH ´1ξď α λ }ξ}2 2. Therefore E
Hence ż 1 0 p1´sqe us dsď 1 2 exp ˆ u 3 ` u2 8 ˙ ď 1 2 e2{9eu2{4 ďe u2{4,(e 2{9{2ă1) which proves (A.20). Lemma A.6(Gaussian exponential moment).For any α, cą0 , let Z„Np0, αH ´1q, where HľλI d. Ifλě 64αdc 7 ,then, we have E ” ec}Z}2 2 ı ď 4 3 . Proof of Lemma A.6. Let ξ„Np0, I dq and write Z“ ?α H´1{2ξ. Since H ´1 ĺλ ´1Id, we have pointwise }Z}2 2 “α ξ J...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.