Detecting Unfaithful Chain-of-Thought via Circuit-Guided Internal-External Discrepancy
Pith reviewed 2026-06-29 21:45 UTC · model grok-4.3
The pith
CIE-Scorer detects unfaithful chain-of-thought by measuring discrepancy between internal model circuits and external reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
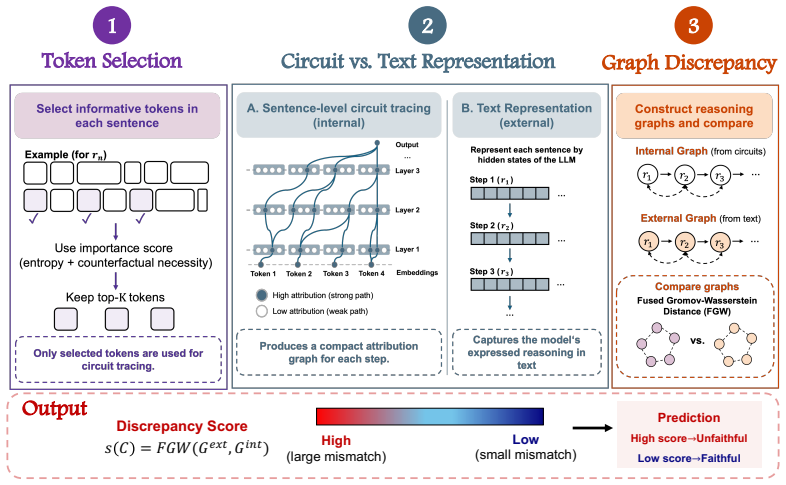
Faithful reasoning traces align with the model's computational process while unfaithful traces diverge from it. CIE-Scorer efficiently traces compact sentence-level circuits from informative reasoning tokens, constructs internal and external reasoning graphs, and measures their discrepancy using Fused Gromov-Wasserstein distance to perform instance-level CoT unfaithfulness detection.
What carries the argument
Circuit-guided Internal-External Discrepancy Scorer (CIE-Scorer) that traces sentence-level circuits from informative tokens and computes Fused Gromov-Wasserstein distance between the resulting internal and external reasoning graphs.
If this is right
- CIE-Scorer reaches state-of-the-art detection performance on four datasets from FaithCoT-Bench.
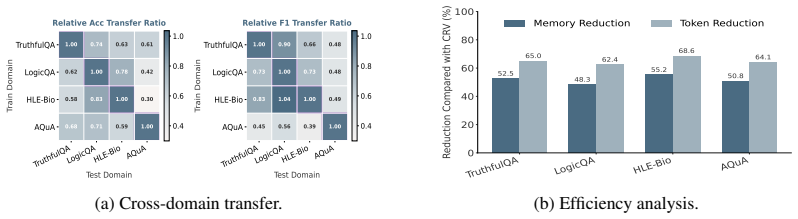
- The approach reduces the cost of circuit construction relative to tracing full reasoning circuits.
- Combining mechanistic interpretability signals from circuits with external reasoning traces improves unfaithfulness detection over external-only methods.
- Sentence-level circuits extracted from informative reasoning tokens suffice for the discrepancy measurement.
Where Pith is reading between the lines
- The same internal-external graph comparison could be tested on reasoning formats other than chain-of-thought.
- Graph discrepancy measures might be reused to compare circuits across different models or tasks.
- Lower circuit-construction cost could make real-time faithfulness checks feasible during generation.
- The alignment premise suggests internal signals could help audit or debug other model-generated explanations.
Load-bearing premise
Faithful reasoning traces align with the model's computational process while unfaithful ones diverge, and sentence-level circuits from informative tokens are enough to represent the full reasoning for discrepancy measurement.
What would settle it
A collection of chain-of-thought examples where the internal-external graph discrepancy scores fail to separate human-labeled faithful cases from unfaithful cases on any of the FaithCoT-Bench datasets.
Figures
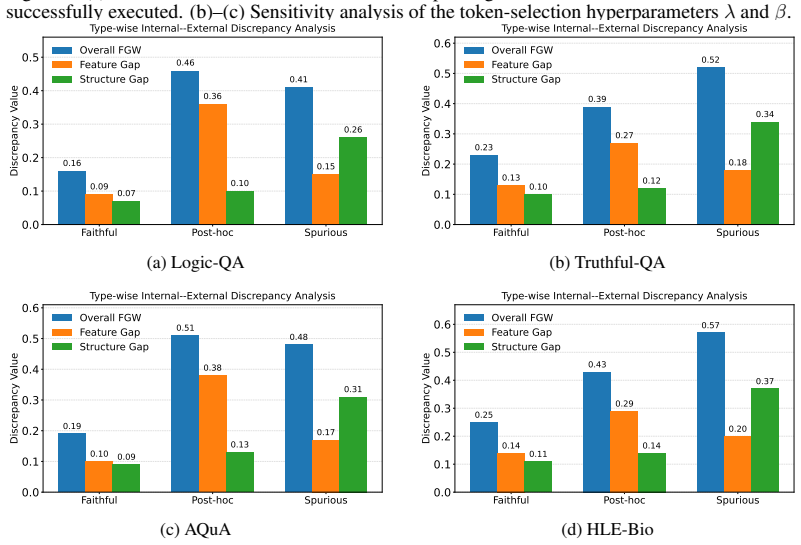

read the original abstract
Chain-of-thought (CoT) reasoning improves the problem-solving ability of large language models (LLMs), but generated reasoning traces may not faithfully reflect the model's actual decision process. Existing CoT unfaithfulness detectors mainly rely on external signals from generated rationales, such as textual plausibility or answer consistency, while overlooking evidence from the model's internal computation. Although recent circuit tracing methods provide a way to obtain model-internal evidence by tracing how information flows through model components during reasoning, constructing full reasoning circuits for long CoTs is costly and difficult to scale. To address these challenges, we propose Circuit-guided Internal-External Discrepancy Scorer (CIE-Scorer), a framework for instance-level CoT unfaithfulness detection. The key idea is that faithful reasoning traces should align with the model's computational process, whereas unfaithful traces may diverge from it. CIE-Scorer efficiently traces compact sentence-level circuits from informative reasoning tokens, constructs internal and external reasoning graphs, and measures their discrepancy using Fused Gromov--Wasserstein distance. Experiments on four datasets from FaithCoT-Bench show that CIE-Scorer achieves state-of-the-art performance while reducing the cost of circuit construction, demonstrating the effectiveness of combining mechanistic interpretability signals with external reasoning traces for CoT unfaithfulness detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Circuit-guided Internal-External Discrepancy Scorer (CIE-Scorer) for instance-level detection of unfaithful chain-of-thought (CoT) reasoning in LLMs. Faithful traces are hypothesized to align with the model's internal computation while unfaithful ones diverge; the method extracts compact sentence-level circuits from informative reasoning tokens, constructs internal and external reasoning graphs, and quantifies discrepancy via Fused Gromov-Wasserstein distance. Experiments on four datasets from FaithCoT-Bench are reported to achieve state-of-the-art performance while lowering circuit-construction cost.
Significance. If the experimental results hold, the work demonstrates a scalable way to combine mechanistic-interpretability signals with external reasoning traces, addressing the cost and scalability limitations of full-circuit tracing for long CoTs. This integration could strengthen unfaithfulness detection beyond purely external-signal methods and support more reliable CoT deployment.
minor comments (2)
- The abstract asserts SOTA performance and cost reduction but does not name the four FaithCoT-Bench datasets, the competing baselines, or any statistical significance tests; the full paper should ensure these details appear prominently in the experimental section with clear tables.
- Notation for the internal and external graphs and the precise definition of 'informative reasoning tokens' should be introduced with a short equation or pseudocode early in §3 to improve readability for readers unfamiliar with circuit tracing.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of integrating mechanistic interpretability signals with external traces, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; framework is a measurement construction without self-referential reduction
full rationale
The paper defines CIE-Scorer as a pipeline that extracts sentence-level circuits from informative tokens, builds internal/external graphs, and computes Fused Gromov-Wasserstein discrepancy under the explicit premise that faithful CoT aligns with internal computation. This premise is stated as an assumption in the abstract and is not derived from or equivalent to the output metric itself. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the discrepancy score to a tautology or to the input data by construction. The SOTA claim is an empirical result on FaithCoT-Bench rather than a forced outcome of the method definition. The derivation chain is therefore self-contained as a proposed measurement procedure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Faithful reasoning traces should align with the model's computational process, whereas unfaithful traces may diverge from it.
Reference graph
Works this paper leans on
-
[1]
Chirag Agarwal, Sree Harsha Tanneru, and Himabindu Lakkaraju. Faithfulness vs. plausibility: On the (un)reliability of explanations from large language models.ArXiv, abs/2402.04614,
-
[2]
URLhttps://api.semanticscholar.org/CorpusID:267523276
-
[3]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
2025
-
[4]
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful.arXiv preprint arXiv:2503.08679, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Chain-of-thought is not explainability.Preprint, alphaXiv, page v1, 2025
Fazl Barez, Tung-Yu Wu, Iván Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nico- las Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, et al. Chain-of-thought is not explainability.Preprint, alphaXiv, page v1, 2025
2025
-
[6]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
2024
-
[7]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
2023
-
[9]
Yingqian Cui, Pengfei He, Jingying Zeng, Hui Liu, Xianfeng Tang, Zhenwei Dai, Yan Han, Chen Luo, Jing Huang, Zhen Li, et al. Stepwise perplexity-guided refinement for efficient chain-of-thought reasoning in large language models.arXiv preprint arXiv:2502.13260, 2025
-
[10]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Techniques for interpretable machine learning
Mengnan Du, Ninghao Liu, and Xia Hu. Techniques for interpretable machine learning. Communications of the ACM, 63(1):68–77, 2019. 10
2019
-
[12]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
2021
-
[13]
Towards revealing the mystery behind chain of thought: a theoretical perspective.Advances in Neural Information Processing Systems, 36:70757–70798, 2023
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. Towards revealing the mystery behind chain of thought: a theoretical perspective.Advances in Neural Information Processing Systems, 36:70757–70798, 2023
2023
-
[14]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, and Ilya Sutskever Jan Leike Jeffrey Wu. Scaling and evaluating sparse autoencoders. 2024
2024
-
[15]
Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms. InFirst Conference on Language Modeling, 2024
2024
-
[16]
Pingjun Hong and Benjamin Roth. Do llm self-explanations help users predict model behavior? evaluating counterfactual simulatability with pragmatic perturbations, 2026. URL https: //arxiv.org/abs/2601.03775
-
[17]
Pingjun Hong, Beiduo Chen, Siyao Peng, Marie-Catherine de Marneffe, and Barbara Plank. LiTEx: A linguistic taxonomy of explanations for understanding within-label variation in natural language inference. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Nat...
-
[18]
URLhttps://aclanthology.org/2025.emnlp-main.1728/
2025
-
[19]
Agree, Disagree, Explain: Decomposing Human Label Variation in NLI through the Lens of Explanations
Pingjun Hong, Beiduo Chen, Siyao Peng, Marie-Catherine de Marneffe, Benjamin Roth, and Barbara Plank. Agree, disagree, explain: Decomposing human label variation in nli through the lens of explanations, 2026. URLhttps://arxiv.org/abs/2510.16458
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.arXiv preprint arXiv:2504.01296, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Towards reasoning in large language models: A survey
Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. In61st Annual Meeting of the Association for Computational Linguistics, ACL 2023, pages 1049–1065. Association for Computational Linguistics (ACL), 2023
2023
-
[22]
On the Trustworthiness of Generative Foundation Models: Guideline, Assessment, and Perspective
Yue Huang, Chujie Gao, Siyuan Wu, Haoran Wang, Xiangqi Wang, Yujun Zhou, Yanbo Wang, Jiayi Ye, Jiawen Shi, Qihui Zhang, et al. On the trustworthiness of generative foundation models: Guideline, assessment, and perspective.arXiv preprint arXiv:2502.14296, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Mathprompter: Mathematical reasoning using large language models
Shima Imani, Liang Du, and Harsh Shrivastava. Mathprompter: Mathematical reasoning using large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 37–42, 2023
2023
-
[24]
Self-planning code generation with large language models.ACM Transactions on Software Engineering and Methodology, 33(7):1–30, 2024
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. Self-planning code generation with large language models.ACM Transactions on Software Engineering and Methodology, 33(7):1–30, 2024
2024
-
[25]
Seungone Kim, Juyoung Suk, Ji Yong Cho, Shayne Longpre, Chaeeun Kim, Dongkeun Yoon, Guijin Son, Yejin Cho, Sheikh Shafayat, Jinheon Baek, Sue Hyun Park, Hyeonbin Hwang, Jinkyung Jo, Hyowon Cho, Haebin Shin, Seongyun Lee, Hanseok Oh, Noah Lee, Namgyu Ho, Se June Joo, Miyoung Ko, Yoonjoo Lee, Hyungjoo Chae, Jamin Shin, Joel Jang, Seonghyeon Ye, Bill Yuchen ...
-
[26]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022. 11
2022
-
[27]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Jiachun Li, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Towards faithful chain-of- thought: Large language models are bridging reasoners.arXiv preprint arXiv:2405.18915, 2024
-
[29]
Focus on your question! interpreting and mitigating toxic cot problems in commonsense reasoning
Jiachun Li, Pengfei Cao, Chenhao Wang, Zhuoran Jin, Yubo Chen, Daojian Zeng, Kang Liu, and Jun Zhao. Focus on your question! interpreting and mitigating toxic cot problems in commonsense reasoning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9206–9230, 2024
2024
-
[30]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by ratio- nale generation: Learning to solve and explain algebraic word problems.arXiv preprint arXiv:1705.04146, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning.arXiv preprint arXiv:2007.08124, 2020
-
[33]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. InProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Lon...
2023
-
[34]
Katie Matton, Robert Osazuwa Ness, John Guttag, and Emre Kıcıman. Walk the talk? measuring the faithfulness of large language model explanations.arXiv preprint arXiv:2504.14150, 2025
-
[35]
Steer llm latents for hallucination detection
Seongheon Park, Xuefeng Du, Min-Hsuan Yeh, Haobo Wang, and Yixuan Li. Steer llm latents for hallucination detection. InInternational Conference on Machine Learning, pages 47971–47990. PMLR, 2025
2025
-
[36]
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Measur- ing and improving faithfulness of chain-of-thought reasoning.arXiv preprint arXiv:2402.13950, 2024
-
[37]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep.arXiv preprint arXiv:2406.05946, 2024
-
[39]
From models to systems: A survey of explainability for tool-augmented language models and ai agents
Benjamin Roth, Nicholas Edwards, Pingjun Hong, Loris Schoenegger, and Sebastian Schuster. From models to systems: A survey of explainability for tool-augmented language models and ai agents. Discussion paper, University of Vienna, January 2026. URL http://eprints.cs. univie.ac.at/8619/
2026
-
[40]
Understanding the information propagation effects of communication topologies in llm-based multi-agent systems
Xu Shen, Yixin Liu, Yiwei Dai, Yili Wang, Rui Miao, Yue Tan, Shirui Pan, and Xin Wang. Understanding the information propagation effects of communication topologies in llm-based multi-agent systems. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12358–12372, 2025
2025
-
[41]
Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning
Xu Shen, Song Wang, Zhen Tan, Laura Yao, Xinyu Zhao, Kaidi Xu, Xin Wang, and Tianlong Chen. Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning. arXiv preprint arXiv:2510.04040, 2025. 12
-
[42]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting, 2023. URL https://arxiv.org/abs/2305.04388
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Kun Wang, Guibin Zhang, Zhenhong Zhou, Jiahao Wu, Miao Yu, Shiqian Zhao, Chenlong Yin, Jinhu Fu, Yibo Yan, Hanjun Luo, et al. A comprehensive survey in llm (-agent) full stack safety: Data, training and deployment.arXiv preprint arXiv:2504.15585, 2025
-
[44]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[46]
Xumeng Wen, Zihan Liu, Shun Zheng, Zhijian Xu, Shengyu Ye, Zhirong Wu, Xiao Liang, Yang Wang, Junjie Li, Ziming Miao, et al. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Measuring the faithfulness of thinking drafts in large reasoning models, 2025
Zidi Xiong, Shan Chen, Zhenting Qi, and Himabindu Lakkaraju. Measuring the faithfulness of thinking drafts in large reasoning models, 2025. URL https://arxiv.org/abs/2505. 13774
2025
-
[48]
Survey on knowledge distillation for large language models: methods, evaluation, and application.ACM Transactions on Intelligent Systems and Technology, 2024
Chuanpeng Yang, Yao Zhu, Wang Lu, Yidong Wang, Qian Chen, Chenlong Gao, Bingjie Yan, and Yiqiang Chen. Survey on knowledge distillation for large language models: methods, evaluation, and application.ACM Transactions on Intelligent Systems and Technology, 2024
2024
-
[49]
How well can reasoning models identify and recover from unhelpful thoughts?, 2025
Sohee Yang, Sang-Woo Lee, Nora Kassner, Daniela Gottesman, Sebastian Riedel, and Mor Geva. How well can reasoning models identify and recover from unhelpful thoughts?, 2025. URLhttps://arxiv.org/abs/2506.10979
-
[50]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
2023
-
[51]
Dissociation of faithful and unfaithful reasoning in llms.arXiv preprint arXiv:2405.15092, 2024
Evelyn Yee, Alice Li, Chenyu Tang, Yeon Ho Jung, Ramamohan Paturi, and Leon Bergen. Dissociation of faithful and unfaithful reasoning in llms.arXiv preprint arXiv:2405.15092, 2024
-
[52]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning in llms.arXiv preprint arXiv:2502.03373, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
Chengshuai Zhao, Zhen Tan, Pingchuan Ma, Dawei Li, Bohan Jiang, Yancheng Wang, Yingzhen Yang, and Huan Liu. Is chain-of-thought reasoning of llms a mirage? a data distribution lens. arXiv preprint arXiv:2508.01191, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Explainability for large language models: A survey.ACM Transactions on Intelligent Systems and Technology, 15(2):1–38, 2024
Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. Explainability for large language models: A survey.ACM Transactions on Intelligent Systems and Technology, 15(2):1–38, 2024
2024
-
[55]
Zheng Zhao, Yeskendir Koishekenov, Xianjun Yang, Naila Murray, and Nicola Cancedda. Veri- fying chain-of-thought reasoning via its computational graph.arXiv preprint arXiv:2510.09312, 2025
-
[56]
Large language models as commonsense knowledge for large-scale task planning.Advances in neural information processing systems, 36:31967– 31987, 2023
Zirui Zhao, Wee Sun Lee, and David Hsu. Large language models as commonsense knowledge for large-scale task planning.Advances in neural information processing systems, 36:31967– 31987, 2023. 13 A Related Works A.1 Understanding Chain-of-Thought Reasoning Chain-of-thought (CoT) reasoning has become a widely adopted mechanism for enhancing the reasoning abi...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.