UAV-OVO: Out-of-Viewpoint Generalization in UAV Action Recognition
Pith reviewed 2026-06-29 22:27 UTC · model grok-4.3
The pith
UAV action recognition models show large accuracy drops on high-depression viewpoints unseen in training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
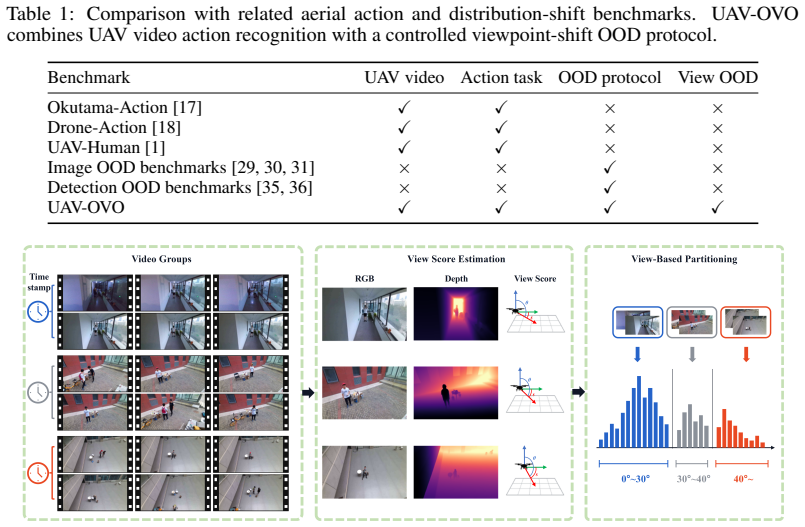
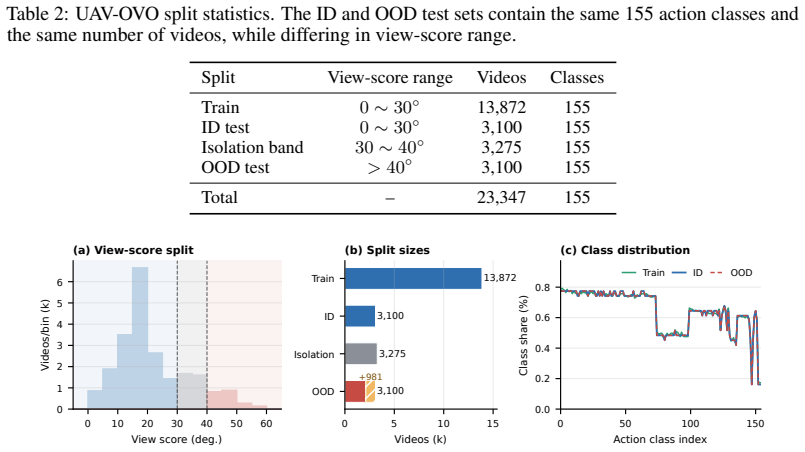
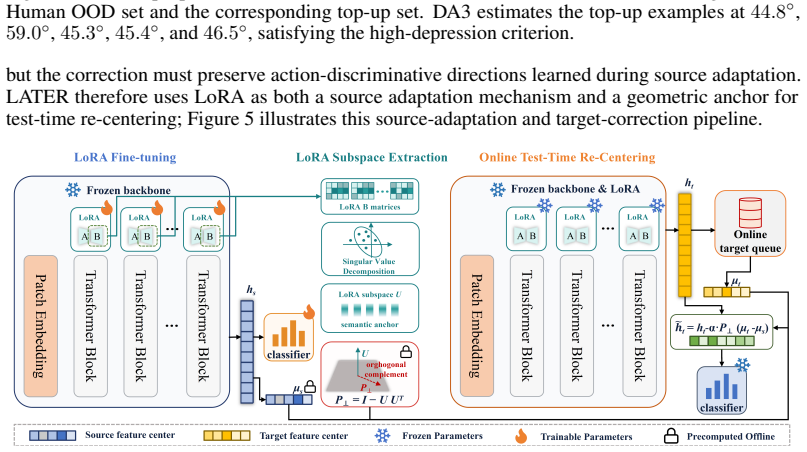
UAV-OVO derives view scores from uncalibrated videos, applies a view-isolation band to place low-depression videos in training and in-distribution test sets while holding high-depression videos for out-of-distribution testing, and builds class-balanced ID/OOD test sets so that measured differences trace to viewpoint change. Representative video models exhibit a clear ID/OOD performance gap that aggregate accuracy conceals. LATER first adapts the model via Low-Rank Adaptation and then uses the resulting subspace as a semantic anchor to project target-domain displacement onto its orthogonal complement before re-centering, thereby limiting viewpoint drift while retaining task semantics.
What carries the argument
The view-isolation band that partitions low- versus high-depression videos together with the LoRA subspace serving as an anchor for orthogonal feature re-centering at test time.
If this is right
- Performance gaps measured on UAV-OVO reflect viewpoint shift rather than class imbalance because the ID and OOD sets share the same class distribution.
- LATER reduces viewpoint-induced feature drift while preserving the semantics needed for action classification.
- The combination of UAV-OVO and LATER supplies a controlled testbed for developing viewpoint-robust UAV video models.
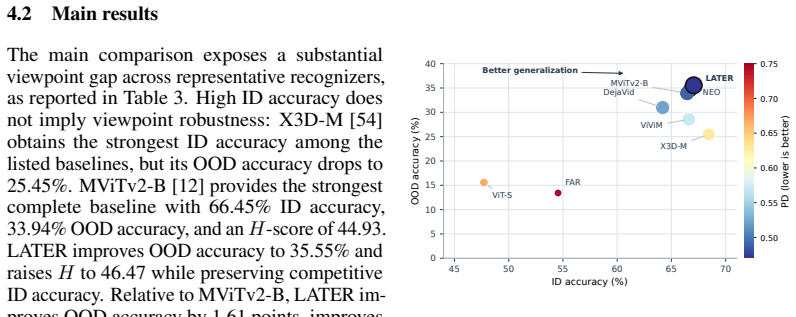
- Models that fit low-depression data well still rely on shortcuts that break under high-depression conditions.
Where Pith is reading between the lines
- Similar angle-based splitting could expose shortcut learning in other video domains where camera elevation varies systematically.
- If depression angle correlates with motion statistics, future splits might add explicit motion matching to strengthen the isolation.
- The orthogonal-projection step in LATER might generalize to other test-time adaptation settings where a low-rank subspace captures task-relevant change.
Load-bearing premise
View scores derived from uncalibrated videos plus the isolation band cleanly separate depression angles without confounding by scene content or motion statistics that happen to correlate with angle.
What would settle it
Finding no ID/OOD accuracy gap once depression angles are matched between training and test sets, or observing that LATER fails to raise high-depression accuracy while leaving low-depression accuracy unchanged.
Figures


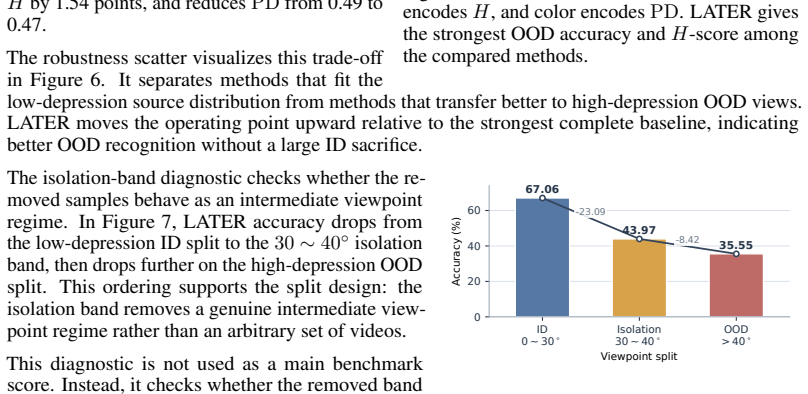
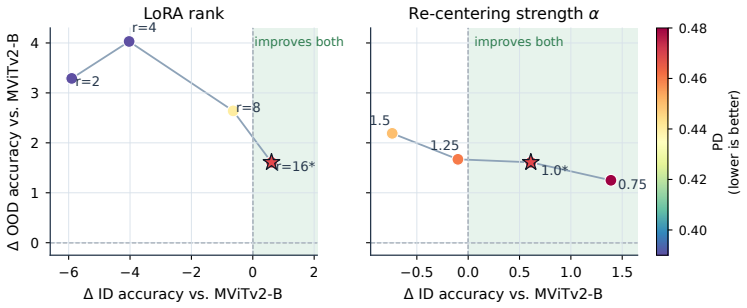
read the original abstract
UAV action recognition faces a deployment shift that standard benchmarks often obscure: a model trained on UAV footage captured from low-depression viewpoints may be required to recognize the same action classes from high-depression viewpoints. While the action labels remain unchanged, this shift alters body visibility, motion projection, and scene context, encouraging models to rely on viewpoint-specific shortcuts. We introduce UAV-OVO, an Out-of-Viewpoint generalization benchmark for UAV action recognition. UAV-OVO derives view scores from uncalibrated videos, uses a view-isolation band to assign low-depression videos to the training and in-distribution test splits while reserving high-depression videos for out-of-distribution testing, and constructs ID/OOD test sets matched by class distribution so that performance differences reflect viewpoint shift rather than label imbalance. Across representative video recognizers, UAV-OVO reveals a substantial ID/OOD gap: models that fit the low-depression training distribution well often fail to transfer to held-out high-depression views, exposing viewpoint shortcuts hidden by aggregate accuracy. We further propose LATER, LoRA-Anchored Test-time Re-centering, which first adapts the recognizer with Low-Rank Adaptation (LoRA) and then uses the learned LoRA subspace as a semantic anchor for online feature re-centering. Specifically, LATER projects target-domain displacement onto the orthogonal complement of the LoRA subspace before re-centering features, reducing viewpoint-induced drift while preserving task-relevant semantics. Together, UAV-OVO and LATER provide a controlled testbed and a practical adaptation method for viewpoint-robust UAV video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UAV-OVO, an out-of-viewpoint generalization benchmark for UAV action recognition. It derives view scores from uncalibrated videos and applies a view-isolation band to place low-depression clips in the training and ID test sets while reserving high-depression clips for OOD testing, with class distributions matched across splits. Standard video recognizers exhibit a substantial ID/OOD performance gap on this benchmark. The paper also proposes LATER (LoRA-Anchored Test-time Re-centering), which adapts a model via LoRA and then projects target-domain feature displacements onto the orthogonal complement of the learned LoRA subspace before re-centering to mitigate viewpoint drift while preserving semantics.
Significance. If the benchmark construction isolates viewpoint shift and LATER delivers the claimed gains, the work supplies a new controlled testbed for viewpoint robustness in UAV video tasks and a lightweight test-time adaptation technique. The explicit separation of ID/OOD by depression angle and the class-matched splits are useful design choices that could expose shortcut learning not visible in aggregate accuracy.
major comments (2)
- [Benchmark construction (view-isolation band)] Benchmark construction section: the claim that performance differences 'reflect viewpoint shift rather than label imbalance' (and by extension viewpoint shortcuts) rests on the view-isolation band cleanly separating depression angle without confounding by motion statistics or scene content. No validation is described that the resulting low- and high-depression partitions are balanced on covariates such as optical-flow magnitude, trajectory length, or background statistics; without such checks the observed ID/OOD gap cannot be attributed to viewpoint alone.
- [LATER method] LATER method description: the projection of target-domain displacement onto the orthogonal complement of the LoRA subspace is presented as the core mechanism for reducing drift while preserving semantics, yet the manuscript supplies neither the explicit projection formula nor pseudocode showing how the re-centering is performed at test time; this makes it impossible to verify that the operation is parameter-free with respect to the target domain or to reproduce the claimed preservation of task-relevant semantics.
minor comments (1)
- [Abstract] The abstract states that view scores are 'derived from uncalibrated videos' but does not specify the exact procedure (e.g., which geometric cues or learned estimator is used); a short methods paragraph or reference would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on UAV-OVO and LATER. We address the two major comments below, agreeing where additional validation or details are warranted, and outline the planned revisions.
read point-by-point responses
-
Referee: [Benchmark construction (view-isolation band)] Benchmark construction section: the claim that performance differences 'reflect viewpoint shift rather than label imbalance' (and by extension viewpoint shortcuts) rests on the view-isolation band cleanly separating depression angle without confounding by motion statistics or scene content. No validation is described that the resulting low- and high-depression partitions are balanced on covariates such as optical-flow magnitude, trajectory length, or background statistics; without such checks the observed ID/OOD gap cannot be attributed to viewpoint alone.
Authors: We agree that the current manuscript only matches class distributions and does not explicitly validate balance on motion or scene covariates, which limits the strength of the claim that the gap is due to viewpoint alone. In the revised version we will add quantitative checks: histograms and statistical tests (e.g., Kolmogorov-Smirnov) comparing optical-flow magnitude, average trajectory length, and background descriptors (color histograms and a pre-trained scene classifier) between the low- and high-depression partitions. These results will be reported in an expanded benchmark-construction section. revision: yes
-
Referee: [LATER method] LATER method description: the projection of target-domain displacement onto the orthogonal complement of the LoRA subspace is presented as the core mechanism for reducing drift while preserving semantics, yet the manuscript supplies neither the explicit projection formula nor pseudocode showing how the re-centering is performed at test time; this makes it impossible to verify that the operation is parameter-free with respect to the target domain or to reproduce the claimed preservation of task-relevant semantics.
Authors: We acknowledge the omission of the explicit formula and pseudocode. The revised manuscript will include the projection equation: given displacement vector d and orthonormal basis S of the LoRA subspace, the anchored displacement is d - S(SᵀS)⁻¹Sᵀd, after which features are recentered by subtracting the mean of the projected displacements. We will also add a short algorithm box showing the full test-time procedure, confirming it uses only the already-trained LoRA weights and requires no target labels or extra hyperparameters. revision: yes
Circularity Check
No circularity: empirical benchmark construction with no derivation chain
full rationale
The paper constructs a data partitioning scheme (view scores from uncalibrated videos + view-isolation band) and proposes an adaptation method (LATER) without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. Claims rest on empirical ID/OOD gaps rather than reductions by construction. The partitioning is a deliberate design choice, not a self-definitional or fitted-input step. No uniqueness theorems or ansatzes are invoked. This is a standard empirical benchmark paper whose central results are falsifiable against external data splits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption View scores derived from uncalibrated videos can reliably isolate low-depression from high-depression footage for split assignment.
Reference graph
Works this paper leans on
-
[1]
Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles
Tianjiao Li, Jun Liu, Wei Zhang, Yun Ni, Wenqian Wang, and Zhiheng Li. Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16266–16275, June 2021
2021
-
[2]
HMDB: A large video database for human motion recognition
Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. HMDB: A large video database for human motion recognition. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2556–2563, 2011
2011
-
[3]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[4]
Two-stream convolutional networks for action recognition in videos
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. InAdvances in Neural Information Processing Systems, volume 27, 2014
2014
-
[5]
Learning spatiotemporal features with 3d convolutional networks
Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 4489–4497, 2015
2015
-
[6]
The Kinetics Human Action Video Dataset
Will Kay, João Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Quo vadis, action recognition? a new model and the kinetics dataset
João Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6299–6308, 2017
2017
-
[8]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6202–6211, 2019
2019
-
[9]
Far: Fourier aerial video recognition
Divya Kothandaraman, Tianrui Guan, Xijun Wang, Shuowen Hu, Ming Lin, and Dinesh Manocha. Far: Fourier aerial video recognition. InComputer Vision – ECCV 2022, volume 13697 ofLecture Notes in Computer Science, pages 657–676. Springer, 2022
2022
-
[10]
Xijun Wang, Ruiqi Xian, Tianrui Guan, Celso M. de Melo, Stephen M. Nogar, Aniket Bera, and Dinesh Manocha. Aztr: Aerial video action recognition with auto zoom and temporal reasoning.arXiv preprint arXiv:2303.01589, 2023
-
[11]
Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[12]
Mvitv2: Improved multiscale vision transformers for classification and detection
Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Mvitv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4804–4814, June 2022
2022
-
[13]
Learning social etiquette: Human trajectory understanding in crowded scenes
Alexandre Robicquet, Amir Sadeghian, Alexandre Alahi, and Silvio Savarese. Learning social etiquette: Human trajectory understanding in crowded scenes. InComputer Vision – ECCV 2016, volume 9912 of Lecture Notes in Computer Science, pages 549–565. Springer, 2016
2016
-
[14]
A benchmark and simulator for uav tracking
Matthias Mueller, Neil Smith, and Bernard Ghanem. A benchmark and simulator for uav tracking. In Computer Vision – ECCV 2016, volume 9905 ofLecture Notes in Computer Science, pages 445–461. Springer, 2016
2016
-
[15]
VisDrone-VDT2018: The vision meets drone video detection and tracking challenge results
Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Haibin Ling, Qinghua Hu, et al. VisDrone-VDT2018: The vision meets drone video detection and tracking challenge results. InProceedings of the European Conference on Computer Vision Workshops (ECCVW), 2018
2018
-
[16]
Spacenet mvoi: A multi-view overhead imagery dataset
Nicholas Weir, David Lindenbaum, Alexei Bastidas, Adam Van Etten, Sean McPherson, Jacob Shermeyer, Varun Kumar, and Hanlin Tang. Spacenet mvoi: A multi-view overhead imagery dataset. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 992–1001, October 2019
2019
-
[17]
Okutama-action: An aerial view video dataset for concurrent human action detection
Mohammadamin Barekatain, Miquel Marti, Hsueh-Fu Shih, Samuel Murray, Kotaro Nakayama, Yutaka Matsuo, and Helmut Prendinger. Okutama-action: An aerial view video dataset for concurrent human action detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 28–35, 2017. 10
2017
-
[18]
Perera, Yee Wei Law, and Javaan Chahl
Asanka G. Perera, Yee Wei Law, and Javaan Chahl. Drone-action: An outdoor recorded drone video dataset for action recognition.Drones, 3(4):82, 2019
2019
-
[19]
Temporal segment networks: Towards good practices for deep action recognition
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. InComputer Vision – ECCV 2016, volume 9912 ofLecture Notes in Computer Science, pages 20–36. Springer, 2016
2016
-
[20]
A closer look at spatiotemporal convolutions for action recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6450–6459, 2018
2018
-
[21]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InProceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 813–824. PMLR, 2021
2021
-
[22]
ViViT: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Luˇci´c, and Cordelia Schmid. ViViT: A video vision transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6836–6846, 2021
2021
-
[23]
Multiscale vision transformers
Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6824–6835, 2021
2021
-
[24]
Video swin transformer
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3202–3211, 2022
2022
-
[25]
VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems, volume 35, pages 10078–10093, 2022
2022
-
[26]
Antonio Torralba and Alexei A. Efros. Unbiased look at dataset bias. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1521–1528, 2011
2011
-
[27]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do ImageNet classifiers generalize to ImageNet? InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5389–5400. PMLR, 2019
2019
-
[28]
ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Dan Gutfreund, Josh Tenenbaum, and Boris Katz. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[29]
Hospedales
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. Deeper, broader and artier domain generalization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 5542–5550, 2017
2017
-
[30]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1406–1415, 2019
2019
-
[31]
Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton Earnshaw, Imran Haque, Sara M. Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang. Wilds: A...
2021
-
[32]
Benchmarking neural network robustness to common corruptions and perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. InInternational Conference on Learning Representations, 2019
2019
-
[33]
Natural adversarial examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15262–15271, 2021
2021
-
[34]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, and Justin Gilmer. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pag...
2021
-
[35]
COCO-O: A benchmark for object detectors under natural distribution shifts
Xiaofeng Mao, Yuefeng Chen, Yao Zhu, Da Chen, Hang Su, Rong Zhang, and Hui Xue. COCO-O: A benchmark for object detectors under natural distribution shifts. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6339–6350, 2023
2023
-
[36]
Al-Emadi, Yin Yang, and Ferda Ofli
Sara A. Al-Emadi, Yin Yang, and Ferda Ofli. Benchmarking object detectors under real-world distribution shifts in satellite imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[37]
Efros, and Moritz Hardt
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei A. Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9229–9248. PMLR, 2020
2020
-
[38]
Revisiting batch normalization for practical domain adaptation.Pattern Recognition, 80:109–117, 2018
Yanghao Li, Naiyan Wang, Jianping Shi, Jiaying Liu, and Xiaodi Hou. Revisiting batch normalization for practical domain adaptation.Pattern Recognition, 80:109–117, 2018
2018
-
[39]
Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation
Jian Liang, Dapeng Hu, and Jiashi Feng. Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 6028–6039. PMLR, 2020
2020
-
[40]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, 2021
2021
-
[41]
Continual test-time domain adaptation
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. Continual test-time domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7201–7211, 2022
2022
-
[42]
Efficient test-time model adaptation without forgetting
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 16888–16905. PMLR, 2022
2022
-
[43]
Towards stable test-time adaptation in dynamic wild world
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards stable test-time adaptation in dynamic wild world. InInternational Conference on Learning Representations, 2023
2023
-
[44]
MEMO: Test time robustness via adaptation and augmentation
Marvin Zhang, Sergey Levine, and Chelsea Finn. MEMO: Test time robustness via adaptation and augmentation. InAdvances in Neural Information Processing Systems, volume 35, pages 38629–38642, 2022
2022
-
[45]
Test-time classifier adjustment module for model-agnostic domain generalization
Yusuke Iwasawa and Yutaka Matsuo. Test-time classifier adjustment module for model-agnostic domain generalization. InAdvances in Neural Information Processing Systems, volume 34, pages 2427–2440, 2021
2021
-
[46]
NEO—no-optimization test-time adaptation through latent re-centering
Alexander Murphy, Michal Danilowski, Soumyajit Chatterjee, and Abhirup Ghosh. NEO—no-optimization test-time adaptation through latent re-centering. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[47]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2790–2799. PMLR, 2019
2019
-
[48]
BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), pages 1–9, 2022
2022
-
[49]
Visual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InComputer Vision – ECCV 2022, volume 13693 ofLecture Notes in Computer Science, pages 709–727. Springer, 2022
2022
-
[50]
Adapt- Former: Adapting vision transformers for scalable visual recognition
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adapt- Former: Adapting vision transformers for scalable visual recognition. InAdvances in Neural Information Processing Systems, volume 35, pages 16664–16678, 2022
2022
-
[51]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. 12
2022
-
[52]
Ray3d: Ray-based 3d human pose estimation for monocular absolute 3d localization
Yu Zhan, Fenghai Li, Renliang Weng, and Wongun Choi. Ray3d: Ray-based 3d human pose estimation for monocular absolute 3d localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13116–13125, June 2022
2022
-
[53]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
2021
-
[54]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 200–210, 2020
2020
-
[55]
Video mamba suite: State space model as a versatile alternative for video understanding.International Journal of Computer Vision, 134(1):20, 2026
Guo Chen, Yifei Huang, Jilan Xu, Baoqi Pei, Jiahao Wang, Zhe Chen, Zhiqi Li, Tong Lu, and Limin Wang. Video mamba suite: State space model as a versatile alternative for video understanding.International Journal of Computer Vision, 134(1):20, 2026
2026
-
[56]
Dejavid: Encoder-agnostic learned temporal matching for video classifica- tion
Darryl Ho and Samuel Madden. Dejavid: Encoder-agnostic learned temporal matching for video classifica- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24023–24032, June 2025. 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.