Hierarchical Consistency Learning for Test-time Adaptation in Camouflage Perception
Pith reviewed 2026-06-29 22:22 UTC · model grok-4.3
The pith
Hierarchical consistency learning framework adapts camouflaged object detectors at test time using unlabeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
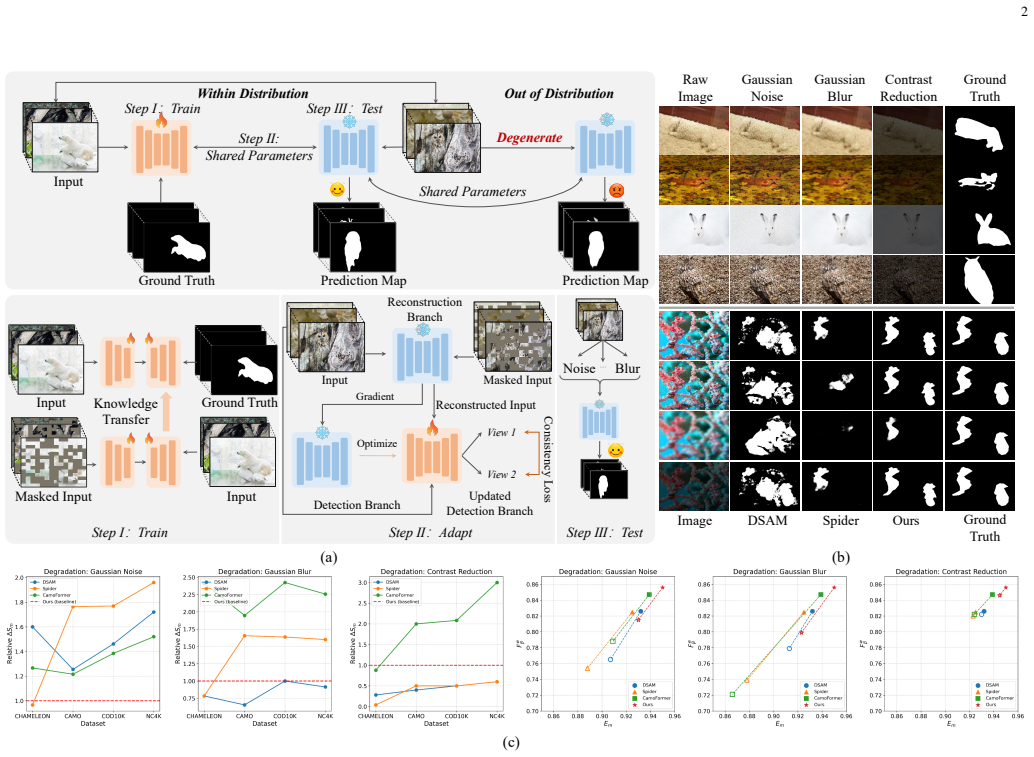
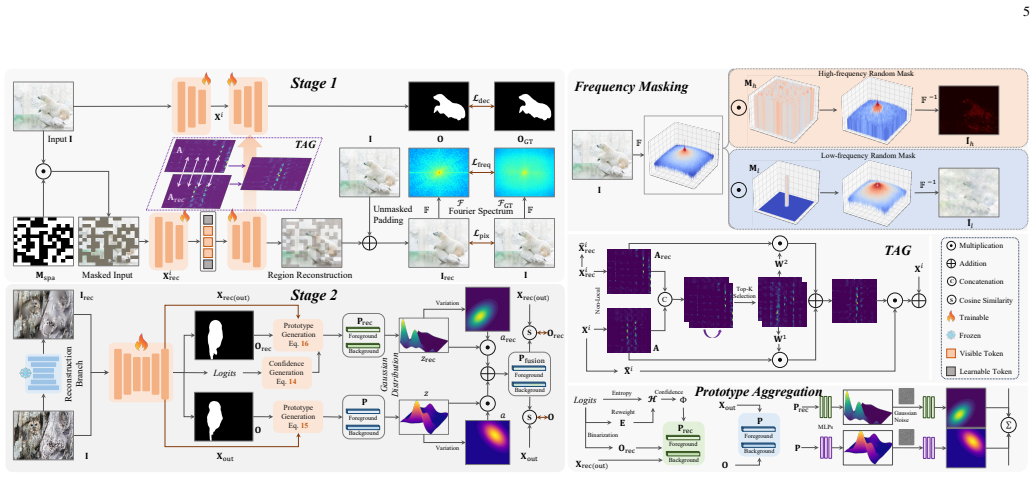
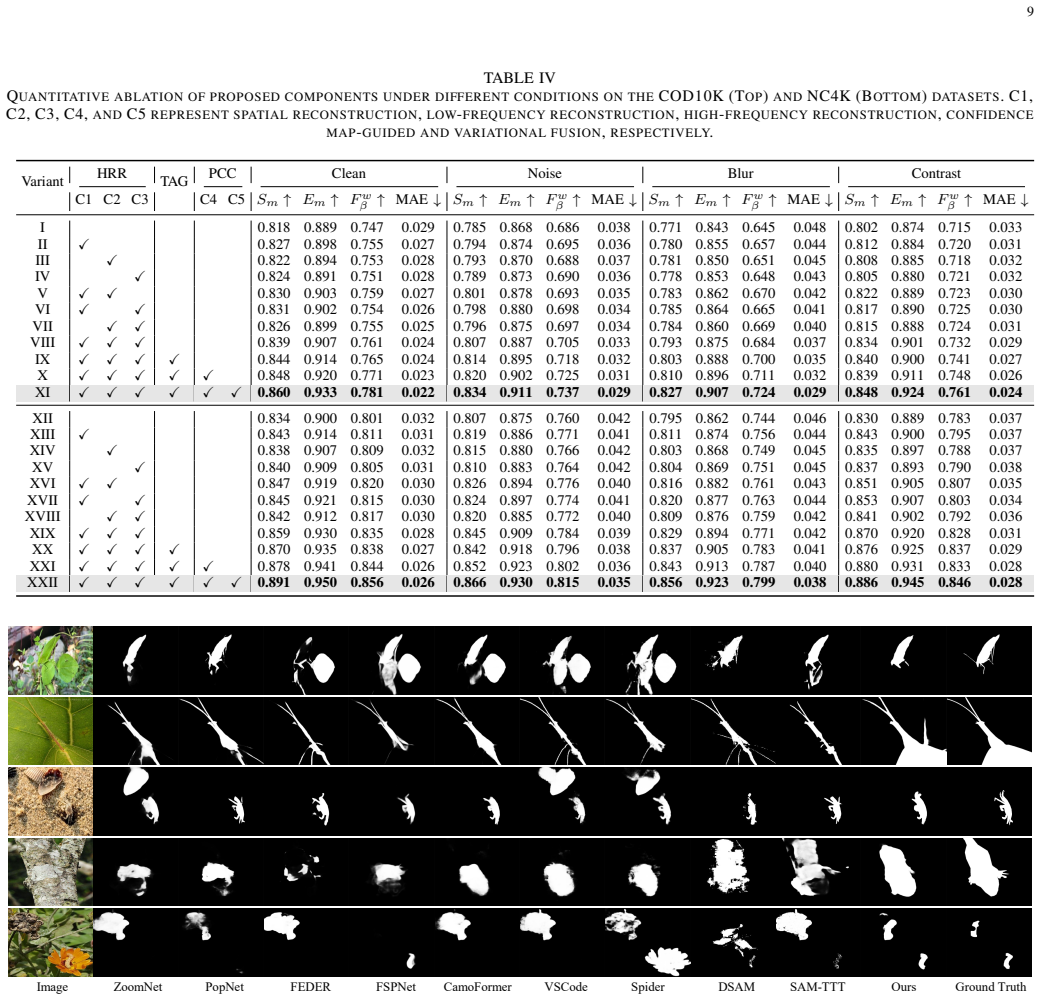
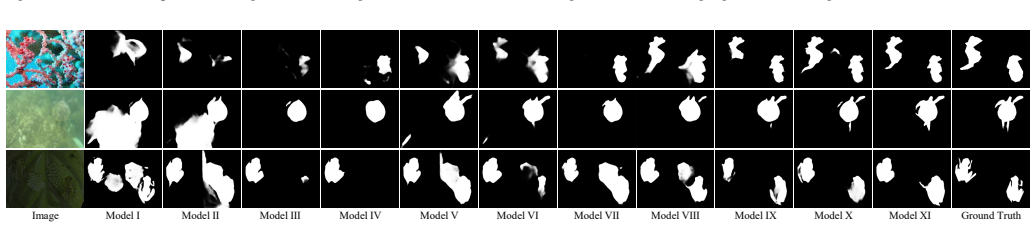
The hierarchical consistency learning (HCL) framework integrates hierarchical representation reconstruction (HRR) to disentangle features via spatial and dual-stream frequency decomposition, task affinity guidance (TAG) to propagate knowledge through channel-wise affinity, and prototype consistency calibration (PCC) to aggregate region features into prototypes and enforce similarity constraints, enabling dynamic recalibration of representations at test time for robustness under distribution shifts.
What carries the argument
Hierarchical consistency learning (HCL) framework combining hierarchical representation reconstruction, task affinity guidance, and prototype consistency calibration to enforce spatial, spectral, affinity, and prototype-level constraints during test-time adaptation.
If this is right
- The method reduces dependence on annotated data when deploying detectors in new environments.
- It maintains performance across camouflaged and underwater tasks under appearance changes and degradations.
- The consistency constraints bridge gaps between different processing branches and representation levels.
- Generalization improves without retraining when encountering unseen camouflage patterns.
Where Pith is reading between the lines
- Similar hierarchical consistency ideas could be tested on other detection tasks that face domain shifts, such as medical lesion detection or aerial object recognition.
- The frequency-domain decomposition step might be replaced with other signal-processing priors to check if the gains persist.
- Extending the prototype calibration to video inputs could reveal whether temporal consistency emerges as an additional benefit.
Load-bearing premise
The proposed components can dynamically recalibrate representations at test time using only unlabeled data and internal consistency constraints without introducing semantic drift or requiring task-specific tuning.
What would settle it
An experiment on one of the eight benchmarks where applying the full HCL adaptation lowers detection performance relative to the non-adapted baseline model or produces visibly mismatched prototypes between source and target domains.
Figures

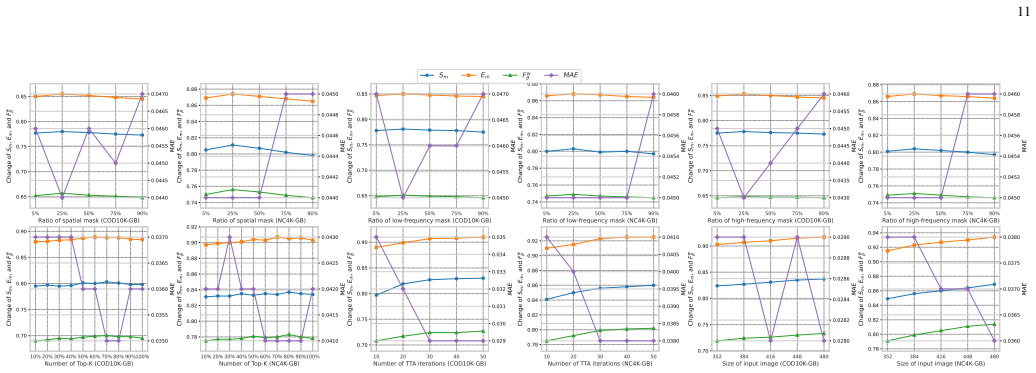
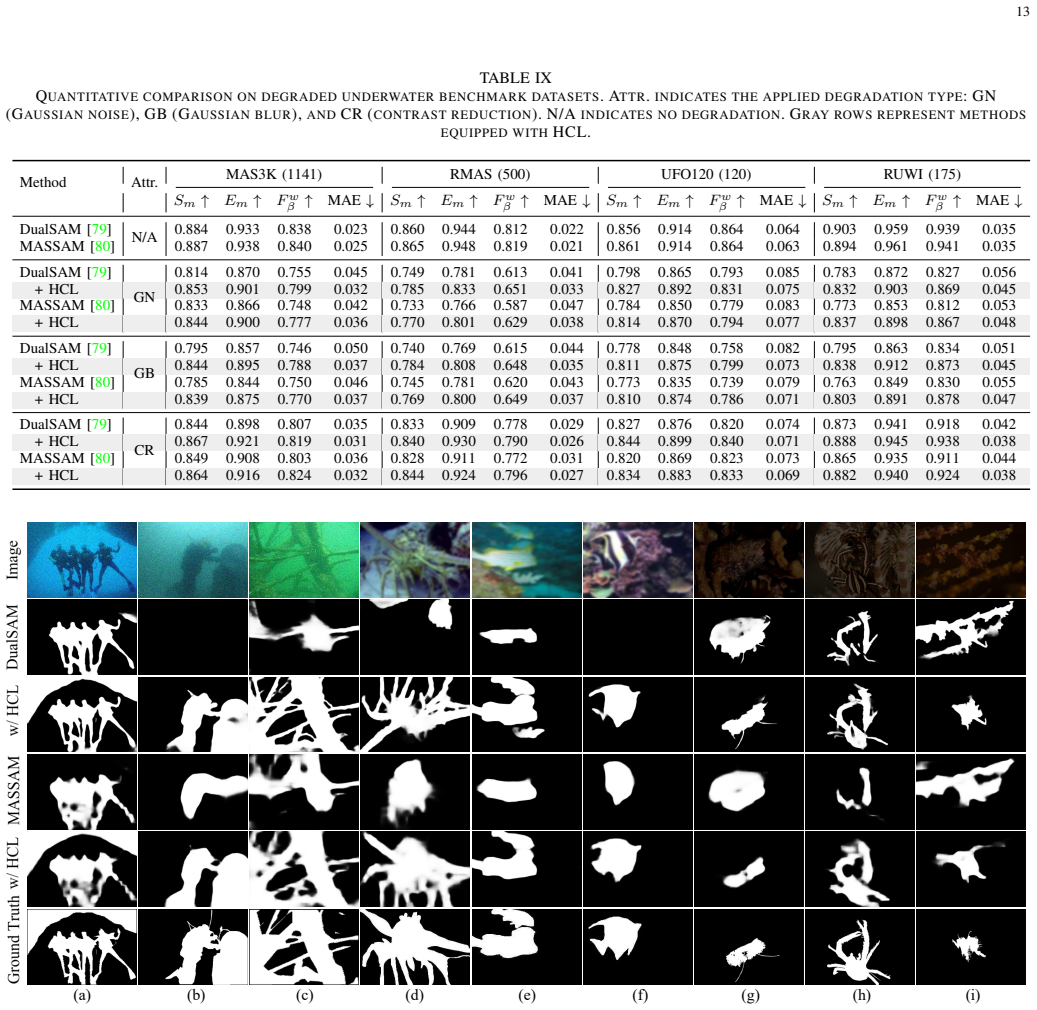

read the original abstract
Camouflaged object detection (COD) aims to localize targets that exhibit minimal perceptual differences from backgrounds through physical attributes. Existing methods, constrained by the static train-then-freeze paradigm, suffer from domain rigidity and annotation dependency, limiting their adaptability to scene variations and unseen camouflage patterns. To overcome these, we propose the hierarchical consistency learning (HCL) framework, which integrates test-time adaptation for dynamic representation recalibration. Specifically, we design the hierarchical representation reconstruction (HRR) to alleviate feature entanglement by synergizing spatial reconstruction with dual-stream frequency-domain decomposition, enhancing robustness against appearance homogenization. The pixel and spectrum inference provide structural and contextual priors. We further introduce task affinity guidance (TAG) to propagate knowledge across branches via channel-wise affinity, aligning local discriminative cues and mitigating semantic drift. To ensure semantic invariance, we formulate the prototype consistency calibration (PCC), which aggregates region features into compact prototypes and establishes prototype-feature similarity. This imposes implicit and hierarchical constraints that bridge task and representation gaps. Extensive experiments across four camouflaged and four underwater object benchmarks, under three degradation settings, demonstrate that our method consistently outperforms state-of-the-art approaches, highlighting its robustness and generalization under distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Hierarchical Consistency Learning (HCL) framework for test-time adaptation in camouflaged object detection. It integrates three modules: hierarchical representation reconstruction (HRR) that combines spatial reconstruction with dual-stream frequency-domain decomposition to reduce feature entanglement, task affinity guidance (TAG) that propagates knowledge across branches using channel-wise affinity to align discriminative cues, and prototype consistency calibration (PCC) that aggregates region features into prototypes and enforces prototype-feature similarity to maintain semantic invariance. The central claim is that this enables dynamic recalibration at test time using only unlabeled data and outperforms state-of-the-art methods across four camouflaged and four underwater benchmarks under three degradation settings.
Significance. If the experimental outperformance holds with proper ablations and metrics, the work would advance test-time adaptation for perception under distribution shifts in visually challenging domains. The consistency-based approach without task-specific tuning addresses a practical limitation of static COD models.
major comments (1)
- [Abstract] Abstract: the central claim of consistent outperformance over SOTA is stated without any quantitative results, error bars, ablation tables, or specific metrics (e.g., mIoU or F-measure deltas), preventing verification that the HRR/TAG/PCC modules deliver the claimed robustness.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We address the point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent outperformance over SOTA is stated without any quantitative results, error bars, ablation tables, or specific metrics (e.g., mIoU or F-measure deltas), preventing verification that the HRR/TAG/PCC modules deliver the claimed robustness.
Authors: We agree that the abstract would benefit from explicit quantitative support for the outperformance claim. The full manuscript already contains detailed tables with mIoU, F-measure, and other metrics across all benchmarks and degradation settings, plus ablations isolating HRR, TAG, and PCC contributions. In the revised version we will add concise numerical highlights to the abstract (e.g., average mIoU gains and F-measure deltas versus the strongest baselines) so that the central claim can be verified at a glance while remaining within length limits. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a framework (HCL) with three modules (HRR, TAG, PCC) motivated by distinct goals such as alleviating feature entanglement, propagating knowledge, and ensuring semantic invariance. No equations, fitted parameters, self-citations, or derivations are shown that reduce any claimed prediction or result to its inputs by construction. The central claims rest on experimental outperformance under distribution shifts, which is independent of the module definitions themselves. This is a standard non-finding for a methods paper whose derivation chain does not exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pranet: Parallel reverse attention network for polyp segmentation,
D.-P. Fan, G.-P. Ji, T. Zhou, G. Chen, H. Fu, J. Shen, and L. Shao, “Pranet: Parallel reverse attention network for polyp segmentation,” in International conference on medical image computing and computer- assisted intervention. Springer, 2020, pp. 263–273
2020
-
[2]
Test- time training with self-supervision for generalization under distribution shifts,
Y . Sun, X. Wang, Z. Liu, J. Miller, A. Efros, and M. Hardt, “Test- time training with self-supervision for generalization under distribution shifts,” inInternational conference on machine learning. PMLR, 2020, pp. 9229–9248
2020
-
[3]
Ef- ficient test-time model adaptation without forgetting,
S. Niu, J. Wu, Y . Zhang, Y . Chen, S. Zheng, P. Zhao, and M. Tan, “Ef- ficient test-time model adaptation without forgetting,” inInternational conference on machine learning. PMLR, 2022, pp. 16 888–16 905
2022
-
[4]
Dual domain perception and progressive refinement for mirror detection,
M. Zha, F. Fu, Y . Pei, G. Wang, T. Li, X. Tang, Y . Yang, and H. T. Shen, “Dual domain perception and progressive refinement for mirror detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 11 942–11 953, 2024
2024
-
[5]
Heterogeneous experts and hierarchical perception for underwa- ter salient object detection,
M. Zha, G. Wang, Y . Pei, T. Li, X. Tang, C. Li, Y . Yang, and H. T. Shen, “Heterogeneous experts and hierarchical perception for underwa- ter salient object detection,”IEEE Transactions on Image Processing, 2025
2025
-
[6]
Weakly-supervised mirror detection via scribble annotations,
M. Zha, Y . Pei, G. Wang, T. Li, Y . Yang, W. Qian, and H. T. Shen, “Weakly-supervised mirror detection via scribble annotations,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 6953–6961
2024
-
[7]
Distortion- aware transformer in 360 salient object detection,
Y . Zhao, L. Zhao, Q. Yu, L. Sheng, J. Zhang, and D. Xu, “Distortion- aware transformer in 360 salient object detection,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 499–508
2023
-
[8]
Seeing beyond illusion: Generalized and efficient mirror detection,
M. Zha, G. Wang, T. Li, W. Dong, P. Wang, and Y . Yang, “Seeing beyond illusion: Generalized and efficient mirror detection,” inProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[9]
Language- guided salient object ranking,
F. Liu, Y . Liu, K. Xu, S. Ye, G. P. Hancke, and R. W. Lau, “Language- guided salient object ranking,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 29 803–29 813
2025
-
[10]
A contrastive-learning framework for unsupervised salient object detection,
H. Guan, J. Lin, and R. W. Lau, “A contrastive-learning framework for unsupervised salient object detection,”IEEE Transactions on Image Processing, 2025
2025
-
[11]
arXiv preprint arXiv:2207.00794 (2022)
Y . Sun, S. Wang, C. Chen, and T.-Z. Xiang, “Boundary-guided camou- flaged object detection,”arXiv preprint arXiv:2207.00794, 2022
-
[12]
Inferring camouflaged objects by texture-aware interactive guidance network,
J. Zhu, X. Zhang, S. Zhang, and J. Liu, “Inferring camouflaged objects by texture-aware interactive guidance network,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 4, 2021, pp. 3599– 3607
2021
-
[13]
Frequency-spatial entanglement learning for camouflaged object detection,
Y . Sun, C. Xu, J. Yang, H. Xuan, and L. Luo, “Frequency-spatial entanglement learning for camouflaged object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 343–360
2024
-
[14]
Source-free depth for object pop-out,
Z. Wu, D. P. Paudel, D.-P. Fan, J. Wang, S. Wang, C. Demonceaux, R. Timofte, and L. Van Gool, “Source-free depth for object pop-out,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 1032–1042
2023
-
[15]
Predictive uncer- tainty estimation for camouflaged object detection,
Y . Zhang, J. Zhang, W. Hamidouche, and O. Deforges, “Predictive uncer- tainty estimation for camouflaged object detection,”IEEE Transactions on Image Processing, vol. 32, pp. 3580–3591, 2023
2023
-
[16]
Unlocking attributes’ contribution to successful camouflage: A com- bined textual and visual analysis strategy,
H. Zhang, Y . Lyu, Q. Yu, H. Liu, H. Ma, D. Yuan, and Y . Yang, “Unlocking attributes’ contribution to successful camouflage: A com- bined textual and visual analysis strategy,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 315–331
2024
-
[17]
Upgen: Unleashing potential of foundation models for training- free camouflage detection via generative models,
J. Du, J. Wu, D. Kong, W. Liang, F. Hao, J. Xu, B. Wang, G. Wang, and P. Li, “Upgen: Unleashing potential of foundation models for training- free camouflage detection via generative models,”IEEE Transactions on Image Processing, 2025
2025
-
[18]
Just a hint: Point-supervised camouflaged object detection,
H. Chen, D. Shao, G. Guo, and S. Gao, “Just a hint: Point-supervised camouflaged object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 332–348
2024
-
[19]
Think twice before determining: Towards scene-aware visual reasoning for mirror detection,
M. Zha, G. Wang, Y . Pei, T. Li, X. Tang, J. Ma, Y . Yang, and H. T. Shen, “Think twice before determining: Towards scene-aware visual reasoning for mirror detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2026
2026
-
[20]
Camoteacher: Dual-rotation consistency learning for semi- supervised camouflaged object detection,
X. Lai, Z. Yang, J. Hu, S. Zhang, L. Cao, G. Jiang, Z. Wang, S. Zhang, and R. Ji, “Camoteacher: Dual-rotation consistency learning for semi- supervised camouflaged object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 438–455
2024
-
[21]
Zero-shot camouflaged object detection,
H. Li, C.-M. Feng, Y . Xu, T. Zhou, L. Yao, and X. Chang, “Zero-shot camouflaged object detection,”IEEE Transactions on Image Processing, vol. 32, pp. 5126–5137, 2023
2023
-
[22]
Few-shot camouflaged object segmentation,
Z. Wang, Y . Li, Y . Yang, Y . Li, and G. Liu, “Few-shot camouflaged object segmentation,” in2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–10
2024
-
[23]
Focus- diffuser: Perceiving local disparities for camouflaged object detection,
J. Zhao, X. Li, F. Yang, Q. Zhai, A. Luo, Z. Jiao, and H. Cheng, “Focus- diffuser: Perceiving local disparities for camouflaged object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 181– 198
2024
-
[24]
Sam-cod+: Sam-guided unified framework for weakly-supervised camouflaged object detection,
H. Chen, P. Wei, G. Guo, and S. Gao, “Sam-cod+: Sam-guided unified framework for weakly-supervised camouflaged object detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[25]
Vscode: General visual salient and camouflaged object detection with 2d prompt learning,
Z. Luo, N. Liu, W. Zhao, X. Yang, D. Zhang, D.-P. Fan, F. Khan, and J. Han, “Vscode: General visual salient and camouflaged object detection with 2d prompt learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 17 169–17 180
2024
-
[26]
Comprompter: reconceptualized segment anything model with multiprompt network for camouflaged object detection,
X. Zhang, Z. Yu, L. Zhao, D.-P. Fan, and G. Xiao, “Comprompter: reconceptualized segment anything model with multiprompt network for camouflaged object detection,”Science China Information Sciences, vol. 68, no. 1, p. 112104, 2025
2025
-
[27]
Text-prompt camouflaged instance segmentation with graduated camouflage learning,
Z. He, C. Xia, S. Qiao, and J. Li, “Text-prompt camouflaged instance segmentation with graduated camouflage learning,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 5584– 5593
2024
-
[28]
Endow sam with keen eyes: Temporal-spatial prompt learning for video camouflaged object detection,
W. Hui, Z. Zhu, S. Zheng, and Y . Zhao, “Endow sam with keen eyes: Temporal-spatial prompt learning for video camouflaged object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 058–19 067
2024
-
[29]
Explicit motion handling and interactive prompting for video camouflaged object detection,
X. Zhang, T. Xiao, G.-P. Ji, X. Wu, K. Fu, and Q. Zhao, “Explicit motion handling and interactive prompting for video camouflaged object detection,”IEEE Transactions on Image Processing, 2025
2025
-
[30]
Depth-aware concealed crop detection in dense agricultural scenes,
L. Wang, J. Yang, Y . Zhang, F. Wang, and F. Zheng, “Depth-aware concealed crop detection in dense agricultural scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 201–17 211
2024
-
[31]
A simple yet effective network based on vision transformer for camouflaged object and salient object detection,
C. Hao, Z. Yu, X. Liu, J. Xu, H. Yue, and J. Yang, “A simple yet effective network based on vision transformer for camouflaged object and salient object detection,”IEEE Transactions on Image Processing, 2025
2025
-
[32]
Open-vocabulary cam- ouflaged object segmentation,
Y . Pang, X. Zhao, J. Zuo, L. Zhang, and H. Lu, “Open-vocabulary cam- ouflaged object segmentation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 476–495
2024
-
[33]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[34]
Tent: Fully Test-time Adaptation by Entropy Minimization
D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell, “Tent: Fully test-time adaptation by entropy minimization,”arXiv preprint arXiv:2006.10726, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[35]
Test-time adaptation via self-training with nearest neighbor information,
M. Jang, S.-Y . Chung, and H. W. Chung, “Test-time adaptation via self-training with nearest neighbor information,”arXiv preprint arXiv:2207.10792, 2022
-
[36]
A probabilistic framework for lifelong test-time adaptation,
D. Brahma and P. Rai, “A probabilistic framework for lifelong test-time adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3582–3591
2023
-
[37]
Delta: degradation-free fully test-time adaptation,
B. Zhao, C. Chen, and S.-T. Xia, “Delta: degradation-free fully test-time adaptation,”arXiv preprint arXiv:2301.13018, 2023
-
[38]
Improved self-training for test-time adaptation,
J. Ma, “Improved self-training for test-time adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 23 701–23 710
2024
-
[39]
Depth- aware test-time training for zero-shot video object segmentation,
W. Liu, X. Shen, H. Li, X. Bi, B. Liu, C.-M. Pun, and X. Cun, “Depth- aware test-time training for zero-shot video object segmentation,” in 15 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 218–19 227
2024
-
[40]
Relax image-specific prompt requirement in sam: A single generic prompt for segmenting camou- flaged objects,
J. Hu, J. Lin, S. Gong, and W. Cai, “Relax image-specific prompt requirement in sam: A single generic prompt for segmenting camou- flaged objects,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 11, 2024, pp. 12 511–12 518
2024
-
[41]
Focal frequency loss for image reconstruction and synthesis,
L. Jiang, B. Dai, W. Wu, and C. C. Loy, “Focal frequency loss for image reconstruction and synthesis,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 919–13 929
2021
-
[42]
Zoom in and out: A mixed-scale triplet network for camouflaged object detection,
Y . Pang, X. Zhao, T.-Z. Xiang, L. Zhang, and H. Lu, “Zoom in and out: A mixed-scale triplet network for camouflaged object detection,” inProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2022, pp. 2160–2170
2022
-
[43]
Cam- ouflaged object detection,
D.-P. Fan, G.-P. Ji, G. Sun, M.-M. Cheng, J. Shen, and L. Shao, “Cam- ouflaged object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2777–2787
2020
-
[44]
Mutual graph learning for camouflaged object detection,
Q. Zhai, X. Li, F. Yang, C. Chen, H. Cheng, and D.-P. Fan, “Mutual graph learning for camouflaged object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 997–13 007
2021
-
[45]
Camouflaged object segmentation with distraction mining,
H. Mei, G.-P. Ji, Z. Wei, X. Yang, X. Wei, and D.-P. Fan, “Camouflaged object segmentation with distraction mining,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8772–8781
2021
-
[46]
Uncertainty-guided transformer reasoning for camouflaged object detection,
F. Yang, Q. Zhai, X. Li, R. Huang, A. Luo, H. Cheng, and D.-P. Fan, “Uncertainty-guided transformer reasoning for camouflaged object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 4146–4155
2021
-
[47]
Simultaneously localize, segment and rank the camouflaged objects,
Y . Lv, J. Zhang, Y . Dai, A. Li, B. Liu, N. Barnes, and D.-P. Fan, “Simultaneously localize, segment and rank the camouflaged objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 591–11 601
2021
-
[48]
Concealed object detec- tion,
D.-P. Fan, G.-P. Ji, M.-M. Cheng, and L. Shao, “Concealed object detec- tion,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 10, pp. 6024–6042, 2021
2021
-
[49]
Preynet: Preying on camouflaged objects,
M. Zhang, S. Xu, Y . Piao, D. Shi, S. Lin, and H. Lu, “Preynet: Preying on camouflaged objects,” inProceedings of the 30th ACM international conference on multimedia, 2022, pp. 5323–5332
2022
-
[50]
Camouflaged object detection with feature decomposition and edge re- construction,
C. He, K. Li, Y . Zhang, L. Tang, Y . Zhang, Z. Guo, and X. Li, “Camouflaged object detection with feature decomposition and edge re- construction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 046–22 055
2023
-
[51]
Run: Reversible unfolding network for concealed object segmentation,
C. He, R. Zhang, F. Xiao, C. Fang, L. Tang, Y . Zhang, L. Kong, D.- P. Fan, K. Li, and S. Farsiu, “Run: Reversible unfolding network for concealed object segmentation,”arXiv preprint arXiv:2501.18783, 2025
-
[52]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
2023
-
[53]
High-resolution iterative feedback network for camouflaged object detection,
X. Hu, S. Wang, X. Qin, H. Dai, W. Ren, D. Luo, Y . Tai, and L. Shao, “High-resolution iterative feedback network for camouflaged object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 881–889
2023
-
[54]
Frequency perception network for camouflaged object detection,
R. Cong, M. Sun, S. Zhang, X. Zhou, W. Zhang, and Y . Zhao, “Frequency perception network for camouflaged object detection,” in Proceedings of the 31st ACM international conference on multimedia, 2023, pp. 1179–1189
2023
-
[55]
Feature shrinkage pyramid for camouflaged object detection with transformers,
Z. Huang, H. Dai, T.-Z. Xiang, S. Wang, H.-X. Chen, J. Qin, and H. Xiong, “Feature shrinkage pyramid for camouflaged object detection with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 5557–5566
2023
-
[56]
Explicit visual prompting for low-level structure segmentations,
W. Liu, X. Shen, C.-M. Pun, and X. Cun, “Explicit visual prompting for low-level structure segmentations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 434–19 445
2023
-
[57]
Camoformer: Masked separable attention for camouflaged object detection,
B. Yin, X. Zhang, D.-P. Fan, S. Jiao, M.-M. Cheng, L. Van Gool, and Q. Hou, “Camoformer: Masked separable attention for camouflaged object detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[58]
Spi- der: A unified framework for context-dependent concept segmentation,
X. Zhao, Y . Pang, W. Ji, B. Sheng, J. Zuo, L. Zhang, and H. Lu, “Spider: A unified framework for context-dependent concept understanding,” arXiv preprint arXiv:2405.01002, 2024
-
[59]
Exploring deeper! segment anything model with depth perception for camouflaged object detection,
Z. Yu, X. Zhang, L. Zhao, Y . Bin, and G. Xiao, “Exploring deeper! segment anything model with depth perception for camouflaged object detection,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4322–4330
2024
-
[60]
Conditional diffusion models for camouflaged and salient object detection,
K. Sun, Z. Chen, X. Lin, X. Sun, H. Liu, and R. Ji, “Conditional diffusion models for camouflaged and salient object detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2833–2848, 2025
2025
-
[61]
Rethinking detecting salient and camouflaged objects in unconstrained scenes,
Z. Zhou, Y . Li, C. Zhong, J. Huang, J. Pei, H. Li, and H. Tang, “Rethinking detecting salient and camouflaged objects in unconstrained scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 22 372–22 382
2025
-
[62]
Multi-modal segment anything model for camouflaged scene segmentation,
G. Ren, H. Liu, M. Lazarou, and T. Stathaki, “Multi-modal segment anything model for camouflaged scene segmentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 19 882–19 892
2025
-
[63]
Sam-ttt: Segment anything model via reverse parameter configuration and test-time training for cam- ouflaged object detection,
Z. Yu, L. Zhao, G. Xiao, and X. Zhang, “Sam-ttt: Segment anything model via reverse parameter configuration and test-time training for cam- ouflaged object detection,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 4030–4038
2025
-
[64]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12 179–12 188
2021
-
[65]
Anabranch network for camouflaged object segmentation,
T.-N. Le, T. V . Nguyen, Z. Nie, M.-T. Tran, and A. Sugimoto, “Anabranch network for camouflaged object segmentation,”Computer vision and image understanding, vol. 184, pp. 45–56, 2019
2019
-
[66]
Animal camouflage analysis: Chameleon database,
P. Skurowski, H. Abdulameer, J. Błaszczyk, T. Depta, A. Kornacki, and P. Kozieł, “Animal camouflage analysis: Chameleon database,” Unpublished manuscript, vol. 2, no. 6, p. 7, 2018
2018
-
[67]
Mas3k: An open dataset for marine animal segmentation,
L. Li, E. Rigall, J. Dong, and G. Chen, “Mas3k: An open dataset for marine animal segmentation,” inInternational Symposium on Bench- marking, Measuring and Optimization. Springer, 2020, pp. 194–212
2020
-
[68]
Masnet: A robust deep marine animal segmentation network,
Z. Fu, R. Chen, Y . Huang, E. Cheng, X. Ding, and K.-K. Ma, “Masnet: A robust deep marine animal segmentation network,”IEEE Journal of Oceanic Engineering, 2023
2023
-
[69]
Simultaneous enhancement and super- resolution of underwater imagery for improved visual perception,
M. J. Islam, P. Luo, and J. Sattar, “Simultaneous enhancement and super- resolution of underwater imagery for improved visual perception,”arXiv preprint arXiv:2002.01155, 2020
-
[70]
Underwater image segmentation in the wild using deep learning,
P. Drews-Jr, I. d. Souza, I. P. Maurell, E. V . Protas, and S. S. C. Botelho, “Underwater image segmentation in the wild using deep learning,” Journal of the Brazilian Computer Society, vol. 27, pp. 1–14, 2021
2021
-
[71]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
D. Hendrycks and T. Dietterich, “Benchmarking neural network ro- bustness to common corruptions and perturbations,”arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[72]
Learning to adapt using test-time images for salient object detection in optical remote sensing images,
K. Huang, L. Fang, and C. Tian, “Learning to adapt using test-time images for salient object detection in optical remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[73]
Pvt v2: Improved baselines with pyramid vision transformer,
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pvt v2: Improved baselines with pyramid vision transformer,” Computational Visual Media, vol. 8, no. 3, pp. 415–424, 2022
2022
-
[74]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[75]
Auto-Encoding Variational Bayes,
D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,” in 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014
2014
-
[76]
The norm must go on: Dynamic unsupervised domain adaptation by normalization,
M. J. Mirza, J. Micorek, H. Possegger, and H. Bischof, “The norm must go on: Dynamic unsupervised domain adaptation by normalization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 14 765–14 775
2022
-
[77]
Gradient harmonization in unsuper- vised domain adaptation,
F. Huang, S. Song, and L. Zhang, “Gradient harmonization in unsuper- vised domain adaptation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 319–10 336, 2024
2024
-
[78]
Ttt-mim: Test-time training with masked image modeling for denoising distribution shifts,
Y . Mansour, X. Zhong, S. Caglar, and R. Heckel, “Ttt-mim: Test-time training with masked image modeling for denoising distribution shifts,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 341– 357
2024
-
[79]
Fantastic animals and where to find them: Segment any marine animal with dual sam,
P. Zhang, T. Yan, Y . Liu, and H. Lu, “Fantastic animals and where to find them: Segment any marine animal with dual sam,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2578–2587
2024
-
[80]
Mas-sam: Segment any marine animal with aggregated features,
T. Yan, Z. Wan, X. Deng, P. Zhang, Y . Liu, and H. Lu, “Mas-sam: Segment any marine animal with aggregated features,”arXiv preprint arXiv:2404.15700, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.