Bandwidth-Aware LLM Inference on Heterogeneous Many-Core Supercomputers
Pith reviewed 2026-06-29 20:30 UTC · model grok-4.3
The pith
THInfer achieves 62-84 percent higher LLM throughput on MT-3000 than DeepSpeed on GPUs by maximizing data locality under bandwidth limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
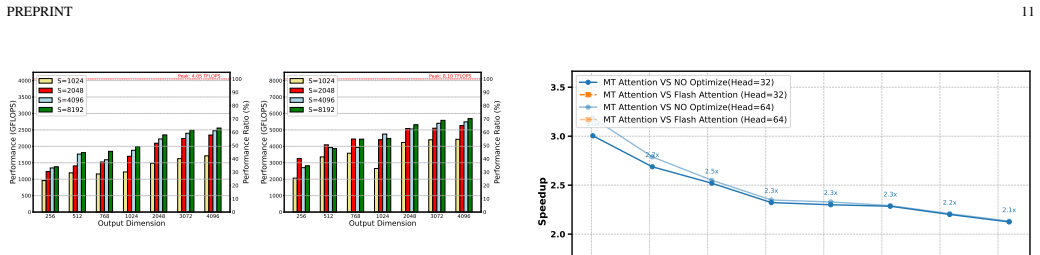
THInfer is a hardware-aware inference framework that maximizes data locality under bandwidth-constrained conditions through hardware-software co-design and parallel strategy optimization, incorporating a high-performance VLIW SIMD operator library, density-driven computation graph fusion with unified kernel scheduling and staged pipelined attention, and a Prefill-Buffer-Decode pipeline with bounded buffer management for hybrid parallelism via two-level MPI and hthreads communication; on Llama models it delivers 62-73 percent higher throughput than DeepSpeed on two V100S GPUs and 67-84 percent higher than on A800 GPUs for the 7B case, with comparable or better results at 13B and 30B, plus sta
What carries the argument
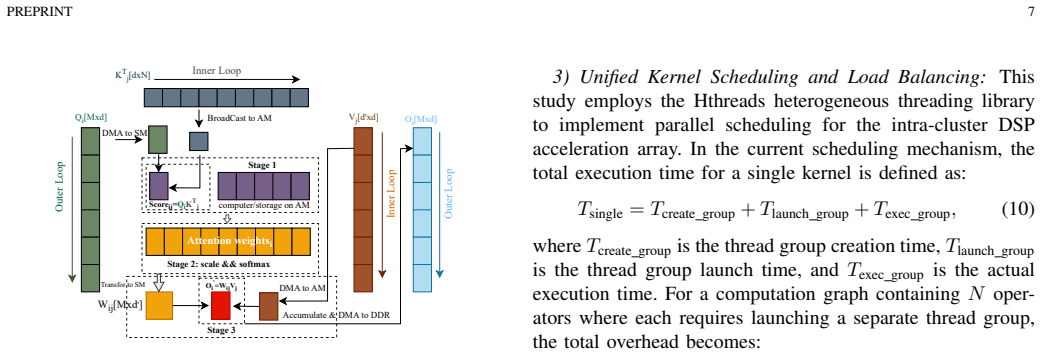
The Prefill-Buffer-Decode (P-B-D) pipeline with bounded buffer management, combined with density-driven graph fusion and a hand-optimized FP16 VLIW SIMD operator library that reaches up to 70 percent of peak per cluster.
If this is right
- THInfer enables stable inference on 70B models on the MT-3000 where typical GPU frameworks cannot run under the same conditions.
- The two-level communication strategy using MPI and hthreads supports efficient multi-cluster collaboration for larger models.
- The staged pipelined attention fusion and unified kernel scheduling reduce latency and improve scalability on bandwidth-limited hardware.
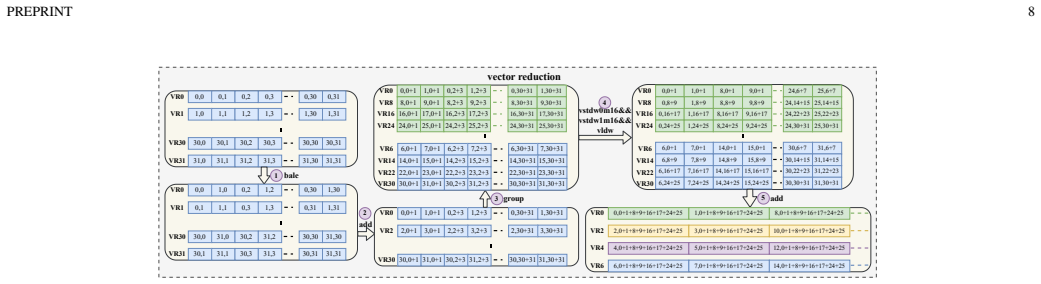
- The operator library and graph fusion techniques allow the framework to reach 70 percent of peak performance per cluster on the VLIW SIMD architecture.
Where Pith is reading between the lines
- The same co-design pattern could be tested on other many-core processors that share the MT-3000's bandwidth and memory-hierarchy constraints.
- If the P-B-D pipeline generalizes, it might reduce the need for specialized GPU clusters when deploying LLMs on existing supercomputers.
- Extending the density-driven fusion to additional operators could further improve performance on even larger models without increasing hardware requirements.
Load-bearing premise
The reported speedups assume that the DeepSpeed GPU baselines use equivalent model precision, batch sizes, and input lengths as the MT-3000 measurements.
What would settle it
A side-by-side run of the same Llama 7B workload with identical precision, batch size, and sequence length on both the MT-3000 under THInfer and two V100S GPUs under DeepSpeed that shows THInfer throughput at or below the GPU result.
Figures






read the original abstract
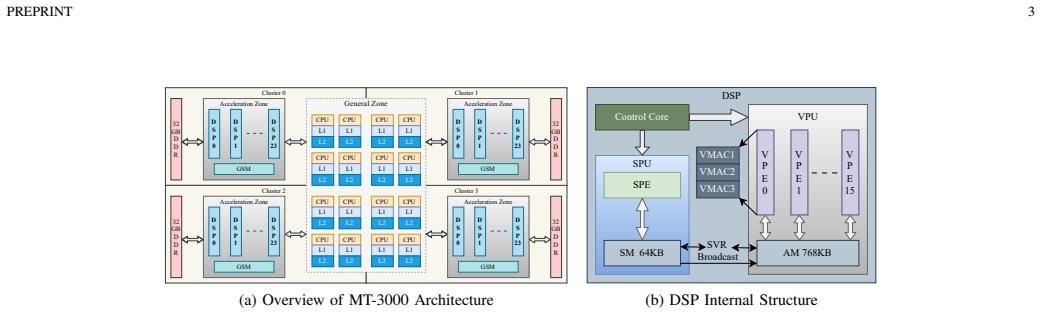
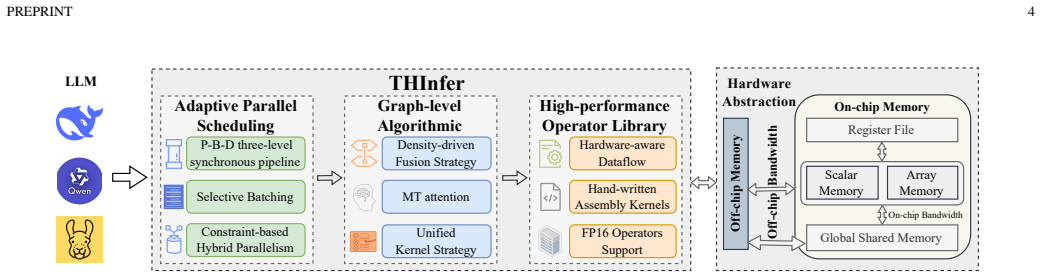
Large language model (LLM) inference is limited by high computational cost and memory bandwidth demands, making deployment on heterogeneous many-core processors challenging. Taking the MT-3000 processor used in the Tianhe supercomputer as an example, its limited main-memory bandwidth and distributed memory hierarchy exemplify these bottlenecks, making it difficult to directly migrate existing GPU-based inference frameworks. To address this problem, we propose THInfer, a hardware-aware inference framework that maximizes data locality under bandwidth-constrained conditions through hardware-software co-design and parallel strategy optimization. THInfer incorporates three key techniques: (1) a high-performance operator library for the VLIW SIMD architecture, providing hand-optimized FP16 kernels that achieve up to 70 percent of the peak performance per cluster; (2) a density-driven computation graph fusion and unified kernel scheduling mechanism, combined with a staged pipelined attention fusion method; and (3) a Prefill-Buffer-Decode (P-B-D) pipeline and bounded buffer management strategy, which supports hybrid parallelism and enables efficient multi-cluster collaboration through two-level communication based on MPI and hthreads. Experiments on the Llama model series show that THInfer improves throughput on the 7B model by 62 percent to 73 percent over DeepSpeed on two V100S GPUs and by 67 percent to 84 percent over the A800 GPU. The 13B and 30B models also demonstrate comparable or better performance. Moreover, THInfer maintains stable performance on the 70B model, whereas typical GPU-based frameworks fail to run under the same setting. Overall, THInfer significantly enhances throughput, reduces latency, and improves scalability, providing a feasible system solution for efficient and scalable LLM inference on heterogeneous many-core architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces THInfer, a hardware-aware LLM inference framework for the MT-3000 processor in the Tianhe supercomputer. It describes three techniques: (1) a hand-optimized FP16 operator library for the VLIW SIMD architecture achieving up to 70% of peak per cluster, (2) density-driven graph fusion with unified scheduling and staged pipelined attention, and (3) a Prefill-Buffer-Decode (P-B-D) pipeline with bounded buffers supporting hybrid parallelism via MPI/hthreads two-level communication. The central empirical claim is that THInfer delivers 62-84% higher throughput than DeepSpeed on V100S/A800 GPUs for Llama-7B (with comparable or better results for 13B/30B and stable 70B performance where GPU frameworks fail).
Significance. If the throughput claims hold under matched workloads, the work is significant for demonstrating practical LLM inference on bandwidth-constrained many-core heterogeneous systems outside the GPU ecosystem. The explicit co-design of kernels, fusion, and pipelining for the MT-3000 memory hierarchy provides a concrete template that could be adapted to other supercomputer architectures.
major comments (1)
- [Abstract and Experimental Evaluation] Abstract and Experimental Evaluation section: The headline throughput claims (62–73% over two V100S GPUs and 67–84% over A800 for the 7B model) are presented without any tabulated values for batch size, input/output sequence lengths, numeric precision, or measurement methodology on either platform. This directly undermines attribution of the gains to THInfer’s techniques rather than possible mismatches in workload parameters, making the central empirical claim unverifiable from the provided information.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: [Abstract and Experimental Evaluation] Abstract and Experimental Evaluation section: The headline throughput claims (62–73% over two V100S GPUs and 67–84% over A800 for the 7B model) are presented without any tabulated values for batch size, input/output sequence lengths, numeric precision, or measurement methodology on either platform. This directly undermines attribution of the gains to THInfer’s techniques rather than possible mismatches in workload parameters, making the central empirical claim unverifiable from the provided information.
Authors: We agree that the current presentation of the headline claims lacks sufficient experimental parameters to allow direct verification. In the revised manuscript we will add an explicit table (or expanded subsection) in the Experimental Evaluation section that reports, for each model size and platform: batch size, input/output sequence lengths, numeric precision, and the precise measurement methodology (including timing method and hardware configuration) used for both THInfer and the DeepSpeed baselines. This addition will make the throughput comparisons fully reproducible and will strengthen attribution of the observed gains to the described co-design techniques. revision: yes
Circularity Check
No circularity; all claims are empirical measurements without derivations or self-referential reductions
full rationale
The paper presents THInfer as a hardware-aware framework with three described techniques (operator library, graph fusion, P-B-D pipeline) and reports empirical throughput gains on Llama models versus DeepSpeed baselines. The full text contains no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. Central claims rest on direct measurements under stated conditions rather than any reduction to inputs by construction. This is the expected outcome for a systems paper focused on implementation and benchmarking.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023. PREPRINT 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[5]
TensorRT-LLM,
NVIDIA, “TensorRT-LLM,” https://github.com/NVIDIA/ TensorRT-LLM
-
[6]
Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale,
R. Y . Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasleyet al., “Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale,” inSC22: International Conference for High Performance Com- puting, Networking, Storage and Analysis. IEEE, 2022, pp. 1–15
2022
-
[7]
Large- scale parallelization and optimization of lattice qcd on tianhe new generation supercomputer,
J. Chen, C. Liu, Z. Luana, M. Gong, Q. Li, and D. Qian, “Large- scale parallelization and optimization of lattice qcd on tianhe new generation supercomputer,” in2023 IEEE International Conference on High Performance Computing & Communications, Data Science & Systems, Smart City & Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/Sm...
2023
-
[8]
Mt-3000: a heterogeneous multi-zone processor for hpc,
K. Lu, Y . Wang, Y . Guo, C. Huang, S. Liu, R. Wang, J. Fang, T. Tang, Z. Chen, B. Liuet al., “Mt-3000: a heterogeneous multi-zone processor for hpc,”CCF Transactions on High Performance Computing, vol. 4, no. 2, pp. 150–164, 2022
2022
-
[9]
Performance analysis of cuda, openacc and openmp programming models on tesla v100 gpu,
M. Khalilov and A. Timoveev, “Performance analysis of cuda, openacc and openmp programming models on tesla v100 gpu,” inJournal of Physics: Conference Series, vol. 1740, no. 1. IOP Publishing, 2021, p. 012056
2021
-
[10]
Mpi: a standard message passing interface,
D. W. Walker and J. J. Dongarra, “Mpi: a standard message passing interface,”Supercomputer, vol. 12, pp. 56–68, 1996
1996
-
[11]
Attention is all you need,
A. Vaswani, “Attention is all you need,”Advances in Neural Information Processing Systems, 2017
2017
-
[12]
Bert: a review of applications in natural language processing and understanding,
M. V . Koroteev, “Bert: a review of applications in natural language processing and understanding,”arXiv preprint arXiv:2103.11943, 2021
-
[13]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[14]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[15]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Q. Team, “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “Gptq: Accurate post-training quantization for generative pre-trained transformers,”arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration,”Proceedings of Machine Learning and Systems, vol. 6, pp. 87–100, 2024
2024
-
[21]
Sparsegpt: Massive language models can be accurately pruned in one-shot,
E. Frantar and D. Alistarh, “Sparsegpt: Massive language models can be accurately pruned in one-shot,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 10 323–10 337
2023
-
[22]
Llm-pruner: On the structural pruning of large language models,
X. Ma, G. Fang, and X. Wang, “Llm-pruner: On the structural pruning of large language models,”Advances in neural information processing systems, vol. 36, pp. 21 702–21 720, 2023
2023
-
[23]
MiniLLM: On-Policy Distillation of Large Language Models
Y . Gu, L. Dong, F. Wei, and M. Huang, “Minillm: Knowledge distillation of large language models,”arXiv preprint arXiv:2306.08543, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[25]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,”arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[26]
Linformer: Self-Attention with Linear Complexity
S. Wang, B. Z. Li, M. Khabsa, H. Fang, and H. Ma, “Linformer: Self-attention with linear complexity,”arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[27]
Reformer: The Efficient Transformer
N. Kitaev, Ł. Kaiser, and A. Levskaya, “Reformer: The efficient trans- former,”arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[28]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
J. Ainslie, J. Lee-Thorp, M. De Jong, Y . Zemlyanskiy, F. Lebr ´on, and S. Sanghai, “Gqa: Training generalized multi-query transformer models from multi-head checkpoints,”arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,
Z. Liu, A. Desai, F. Liao, W. Wang, V . Xie, Z. Xu, A. Kyrillidis, and A. Shrivastava, “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,”Advances in Neural Information Processing Systems, vol. 36, pp. 52 342–52 364, 2023
2023
-
[30]
Efficient Streaming Language Models with Attention Sinks
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,”arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Orca: A distributed serving system for{Transformer-Based}generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for{Transformer-Based}generative models,” in16th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 22), 2022, pp. 521–538
2022
-
[32]
Text Generation Inference,
Hugging Face, “Text Generation Inference,” https://github.com/ huggingface/text-generation-inference
-
[33]
Flexgen: High-throughput generative inference of large language models with a single gpu,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. R ´e, I. Stoica, and C. Zhang, “Flexgen: High-throughput generative inference of large language models with a single gpu,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 31 094–31 116
2023
-
[34]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 193–210
2024
-
[35]
Efficient processing of deep neural networks: A tutorial and survey,
V . Sze, Y .-H. Chen, T.-J. Yang, and J. S. Emer, “Efficient processing of deep neural networks: A tutorial and survey,”Proceedings of the IEEE, vol. 105, no. 12, pp. 2295–2329, 2017
2017
-
[36]
Roofline: an insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,”Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009
2009
-
[37]
Optimizing general matrix multiplications on modern multi-core dsps,
K. Yu, X. Qi, P. Zhang, J. Fang, D. Dong, R. Wang, T. Tang, C. Huang, Y . Che, and Z. Wang, “Optimizing general matrix multiplications on modern multi-core dsps,” in2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2024, pp. 964– 975. Yao Luborn in 1998, PhD candidate with Beihang University, Beijing China. His main rese...
2024
-
[38]
He served as the chief scientist of China National High Technology Program on high perfor- mance computing for 20 years
He is a professor with the School of Com- puter Science and Engineering, Beihang University, China. He served as the chief scientist of China National High Technology Program on high perfor- mance computing for 20 years. His research inter- ests include innovative technologies in distributed computing, high performance computing, and com- puter architectu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.