Trait-Aware Policy Optimization for Autoregressive Multi-Trait Essay Scoring
Pith reviewed 2026-06-29 21:42 UTC · model grok-4.3
The pith
Decomposing rewards along sample and trait dimensions improves autoregressive multi-trait essay scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
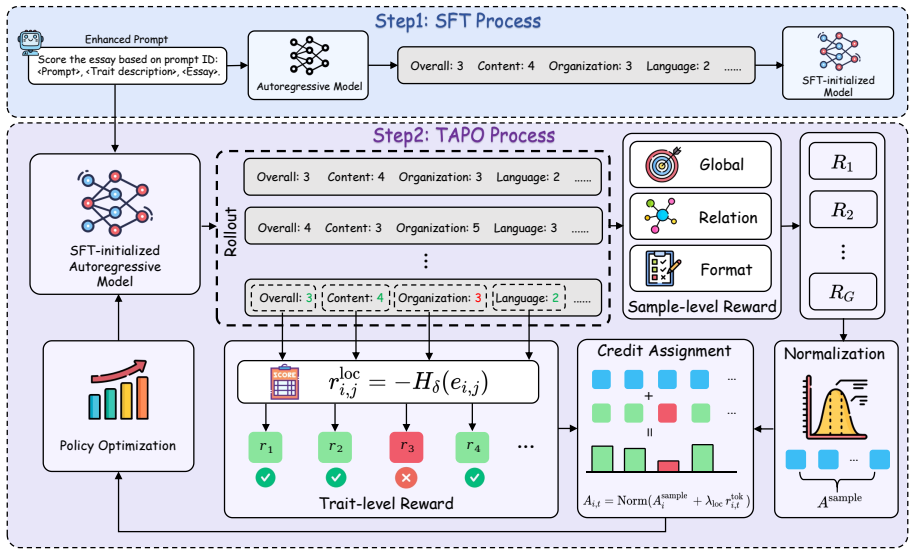
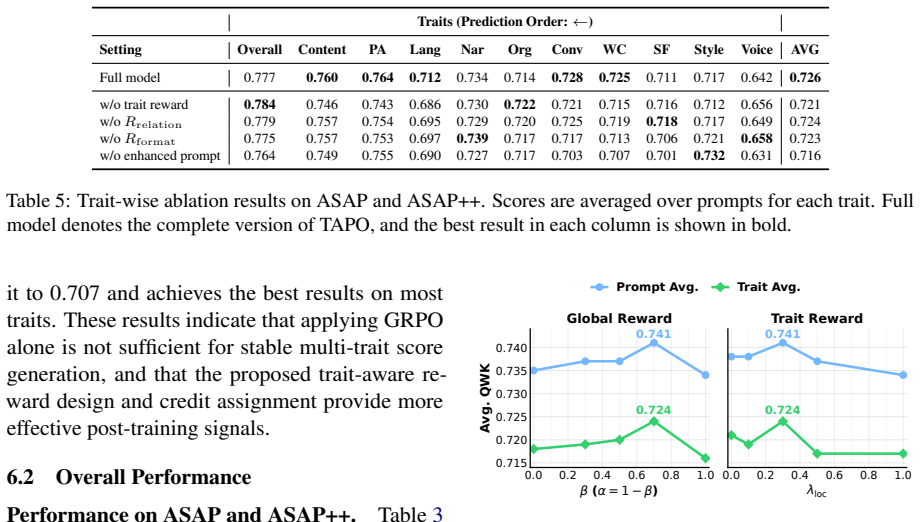
Trait-Aware Policy Optimization decomposes rewards along both the sample and trait dimensions, combines global scoring consistency with trait-level accuracy, format validity, and inter-trait dependency preservation, and augments training with enhanced prompts that incorporate original prompt texts and trait descriptions, producing consistent performance gains over supervised fine-tuning and scalar-reward optimization across multiple backbone models.
What carries the argument
Trait-Aware Policy Optimization (TAPO), which decomposes rewards along sample and trait dimensions and supplies enhanced prompts containing original texts plus trait descriptions.
If this is right
- Multi-trait scoring accuracy rises consistently over supervised fine-tuning and scalar-reward baselines.
- The gains transfer across different autoregressive backbone models without per-model redesign.
- Trait-level precision improves while inter-trait dependencies remain intact.
- Format validity and global scoring consistency are enforced through the decomposed reward terms.
Where Pith is reading between the lines
- The same reward decomposition could be tested on other multi-dimensional autoregressive tasks such as code review or clinical note evaluation.
- If the method scales, separate per-trait models might become unnecessary in production scoring systems.
- Experiments that vary trait importance weights would show whether the decomposition remains stable under unequal trait priorities.
Load-bearing premise
That reward signals can be decomposed along sample and trait dimensions without losing inter-trait relationships or requiring model-specific retuning.
What would settle it
If new backbone models or essay datasets show that trait-level scores become inconsistent or that overall accuracy falls back to scalar-reward baseline levels after applying the decomposition, the central claim would be falsified.
Figures


read the original abstract
Multi-trait essay scoring aims to provide fine-grained evaluation of writing quality across multiple dimensions. However, how to effectively post-train autoregressive scoring models remains underexplored. In this paper, we propose Trait-Aware Policy Optimization (TAPO), a post-training framework tailored to autoregressive multi-trait scoring. Our method decomposes rewards along both the sample and trait dimensions, combining global scoring consistency, trait-level accuracy, format validity, and inter-trait dependency preservation. In addition, we use enhanced prompts throughout training by incorporating original prompt texts and trait descriptions, providing richer semantic information for trait-specific score generation. Experiments across multiple backbone models show that our method consistently improves multi-trait scoring performance over supervised fine-tuning and scalar-reward optimization baselines, demonstrating the effectiveness and transferability of trait-aware post-training for essay scoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trait-Aware Policy Optimization (TAPO), a post-training framework for autoregressive multi-trait essay scoring models. Rewards are decomposed along sample and trait dimensions to jointly optimize global scoring consistency, trait-level accuracy, format validity, and inter-trait dependency preservation; enhanced prompts incorporating original prompt texts and trait descriptions are used throughout training. Experiments across multiple backbone models are reported to show consistent improvements over supervised fine-tuning and scalar-reward optimization baselines.
Significance. If the empirical gains are shown to be robust, the work would address an underexplored area of post-training for fine-grained autoregressive scoring by demonstrating the value of trait-aware reward decomposition and prompt enrichment for preserving inter-trait structure.
major comments (1)
- [Abstract] The abstract states performance gains but provides no details on experimental design, statistical tests, dataset sizes, or exact baseline implementations, making it impossible to assess whether the data actually support the claim of consistent improvements and transferability.
Simulated Author's Rebuttal
We thank the referee for their review and the recommendation for major revision. We address the single major comment below by agreeing to revise the abstract for greater transparency while preserving its standard length and focus.
read point-by-point responses
-
Referee: [Abstract] The abstract states performance gains but provides no details on experimental design, statistical tests, dataset sizes, or exact baseline implementations, making it impossible to assess whether the data actually support the claim of consistent improvements and transferability.
Authors: We acknowledge that the abstract is written at a high level and omits concrete experimental details such as dataset sizes, exact baseline configurations, and any statistical testing. These specifics are reported in full in Sections 3 (Experimental Setup) and 4 (Results), including the corpora used, backbone models, baseline implementations (SFT and scalar-reward RL), and evaluation metrics. To address the concern directly, we will revise the abstract to incorporate a concise clause noting the datasets, the range of backbone models tested, and that gains are measured against both SFT and scalar-reward baselines. We will not add statistical-test language unless it can be supported by the existing results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical post-training framework (TAPO) that decomposes rewards along sample and trait dimensions and augments prompts, then reports experimental gains over supervised fine-tuning and scalar-reward baselines across multiple backbones. No equations, derivations, or first-principles results appear in the abstract or description. The central claim rests on measured performance improvements rather than any quantity defined by construction from the method itself. No self-citations, fitted-input predictions, or uniqueness theorems are invoked as load-bearing steps. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights for combining global, trait-level, format, and dependency rewards
Reference graph
Works this paper leans on
-
[1]
Learning to rank using gradient descent. In Proceedings of the 22nd International Conference on Machine Learning, ICML ’05, pages 89–96, New York, NY , USA. Association for Computing Machin- ery. Minsoo Cho, Jin-Xia Huang, and Oh-Woog Kwon. 2024. Dual-scale BERT using multi-trait representations for holistic and trait-specific essay grading.ETRI Journal, ...
-
[2]
InPro- ceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16751– 16761, Torino, Italia
Transformer-based Joint Modelling for Auto- matic Essay Scoring and Off-Topic Detection. InPro- ceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16751– 16761, Torino, Italia. ELRA and ICCL. Heejin Do, Yunsu Kim, and Gary Lee. 2024a. Au- toregressive Score Generati...
2024
-
[3]
Towards Prompt Generalization: Grammar- aware Cross-Prompt Automated Essay Scoring. In 9 Findings of the Association for Computational Lin- guistics: NAACL 2025, pages 2818–2824, Albu- querque, New Mexico. Association for Computa- tional Linguistics. Heejin Do, Sangwon Ryu, and Gary Lee. 2024b. Au- toregressive Multi-trait Essay Scoring via Reinforce- men...
-
[4]
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
DGPO: Distribution Guided Policy Op- timization for Fine Grained Credit Assignment. https://arxiv.org/abs/2605.03327v2. Rahul Kumar, Sandeep Mathias, Sriparna Saha, and Pushpak Bhattacharyya. 2022. Many Hands Make Light Work: Using Essay Traits to Automatically Score Essays. InProceedings of the 2022 Conference of the North American Chapter of the Associa...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding R1-Zero-Like Training: A Crit- ical Perspective. https://arxiv.org/abs/2503.20783v2. Sandeep Mathias and Pushpak Bhattacharyya. 2018. ASAP++: Enriching the ASAP Automated Essay Grading Dataset with Essay Attribute Scores. InPro- ceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japa...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.