SFR-Net: Learning Scale-Frustum Representations for Ultra-Wide Area Remote Sensing Image Segmentation
Pith reviewed 2026-06-29 23:03 UTC · model grok-4.3
The pith
SFR-Net builds scale-frustum representations to segment ultra-wide area remote sensing images by unifying multi-scale objects with long-range context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
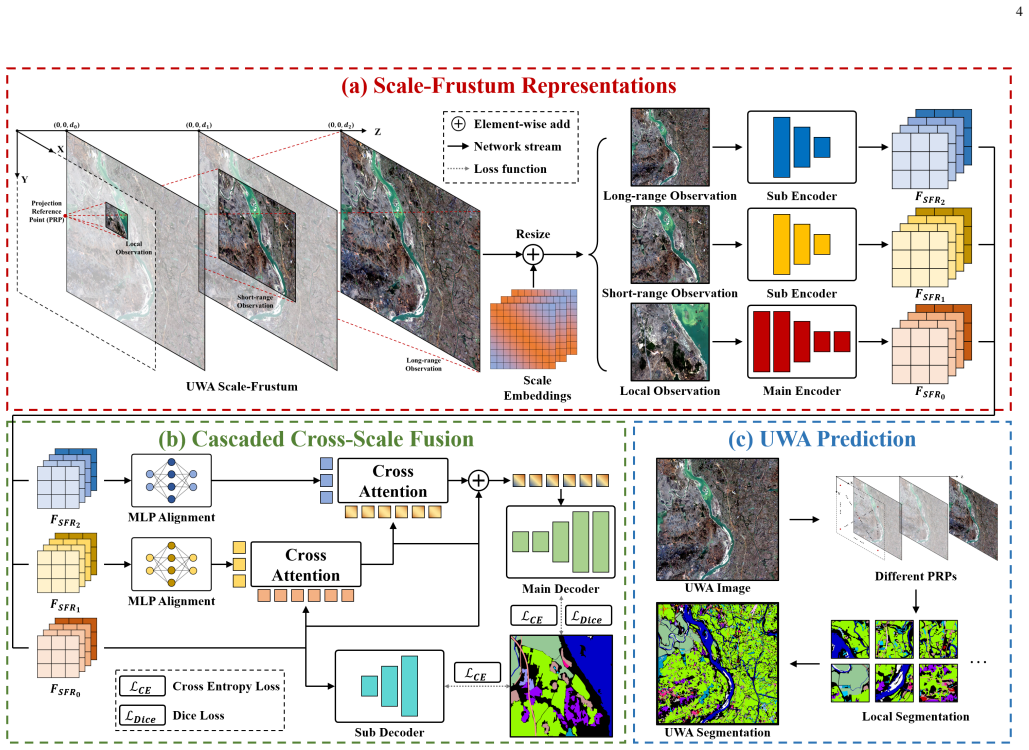
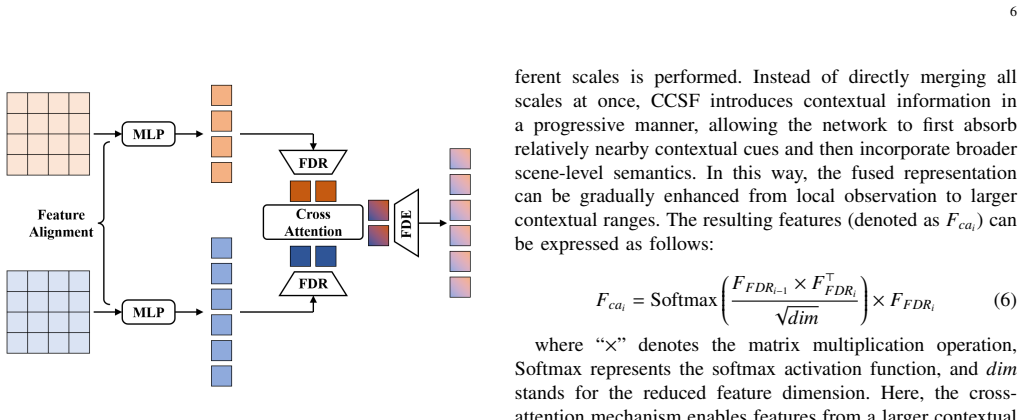
Scale-frustum representations, constructed by emulating viewing frustums from different altitudes, enable unified modeling of ground objects and contextual features at multiple scales; when combined with cascaded cross-scale fusion, they simultaneously address scale variation and long-range semantic continuity in ultra-wide area images.
What carries the argument
scale-frustum representations: feature sets that model objects and context at different scales in one structure by following the geometry of remote-sensing viewing frustums captured from varying altitudes.
If this is right
- SFR-Net raises mean intersection-over-union by 1.72 percent on the GID dataset and 4.29 percent on the FBPS dataset relative to the strongest prior methods.
- The same scale-frustum representations can be inserted into generic segmentation networks to increase accuracy and reduce the number of training steps needed.
- Local semantic detail and long-range contextual continuity are maintained together without separate pyramid or attention modules.
Where Pith is reading between the lines
- The frustum construction may transfer to other imaging domains that also combine extreme scale ranges with wide spatial extent, such as aerial video or medical whole-slide imaging.
- If the geometric inspiration from the capture process proves general, it could replace hand-designed multi-scale modules in additional remote-sensing tasks.
- Larger-coverage test sets would show whether the continuity benefit continues to grow with image area.
Load-bearing premise
Representations built from altitude-based viewing frustums can solve both extreme scale differences and long-range semantic continuity in one mechanism.
What would settle it
Run SFR-Net on a controlled ultra-wide dataset in which either all objects are forced to one scale or long-range context is deliberately severed while keeping everything else fixed, and check whether the reported accuracy gains disappear.
Figures
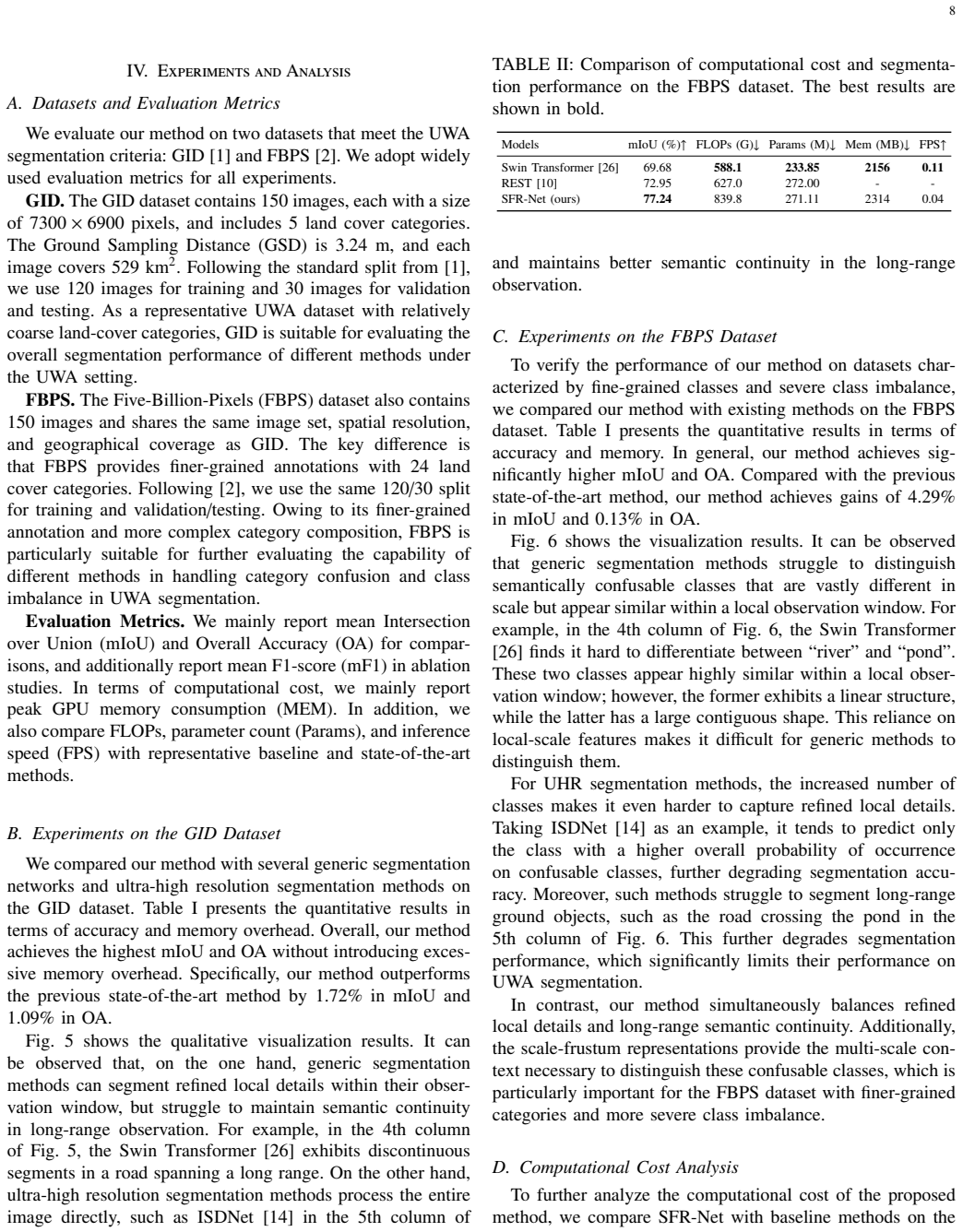
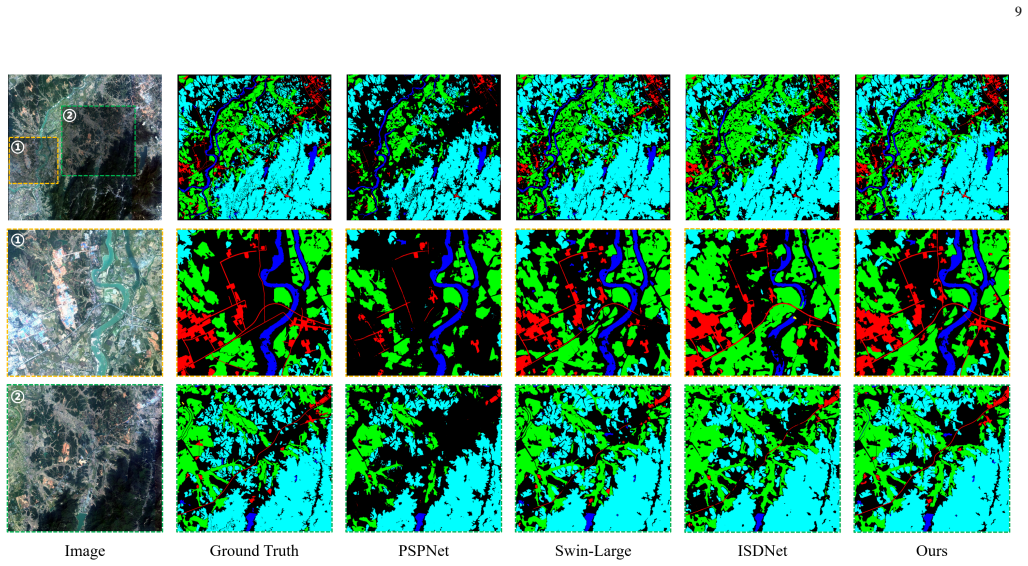
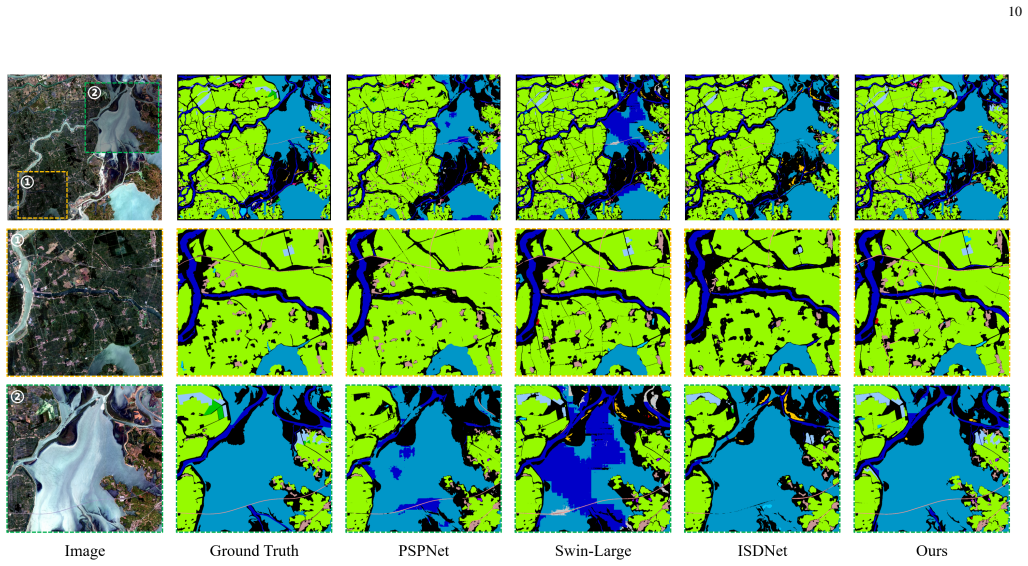
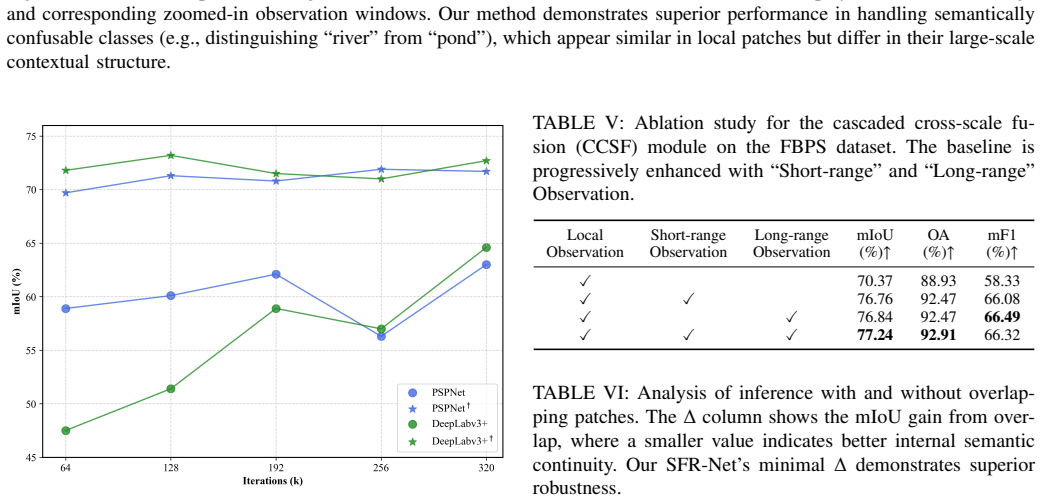

read the original abstract
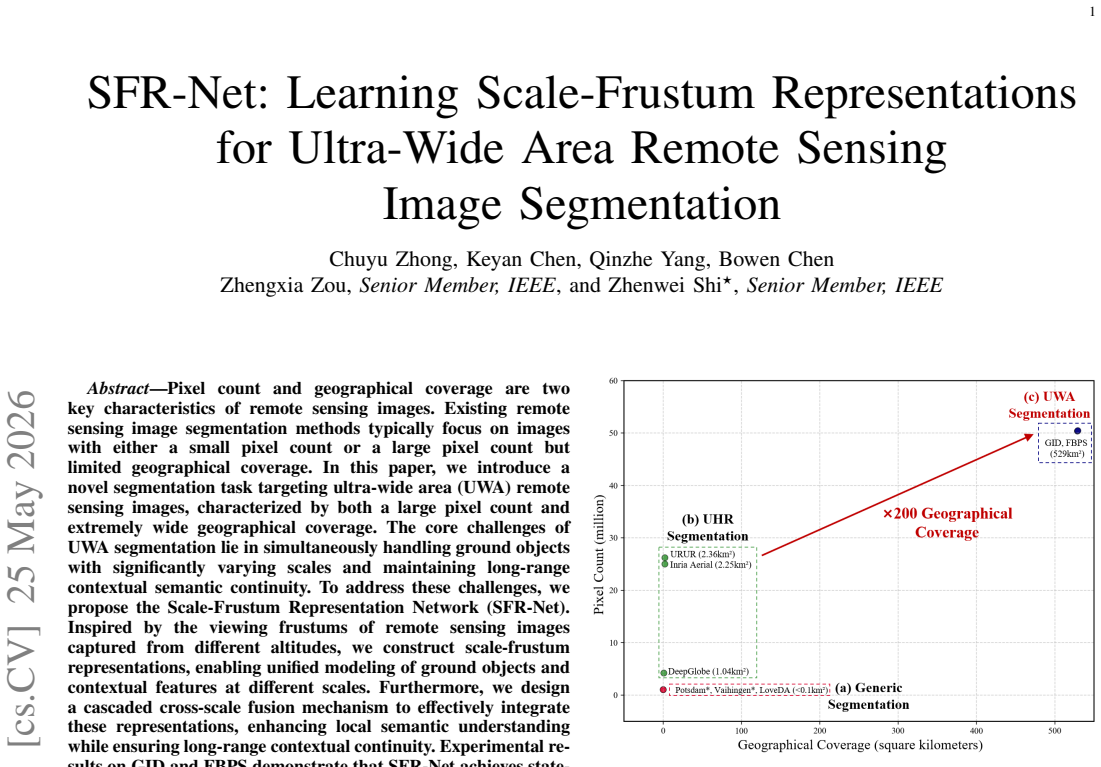
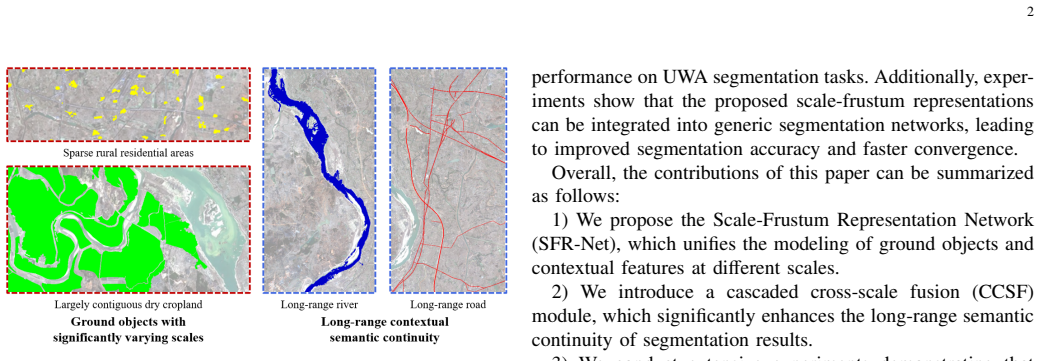
Pixel count and geographical coverage are two key characteristics of remote sensing images. Existing remote sensing image segmentation methods typically focus on images with either a small pixel count or a large pixel count but limited geographical coverage. In this paper, we introduce a novel segmentation task targeting ultra-wide area (UWA) remote sensing images, characterized by both a large pixel count and extremely wide geographical coverage. The core challenges of UWA segmentation lie in simultaneously handling ground objects with significantly varying scales and maintaining long-range contextual semantic continuity. To address these challenges, we propose the Scale-Frustum Representation Network (SFR-Net). Inspired by the viewing frustums of remote sensing images captured from different altitudes, we construct scale-frustum representations, enabling unified modeling of ground objects and contextual features at different scales. Furthermore, we design a cascaded cross-scale fusion mechanism to effectively integrate these representations, enhancing local semantic understanding while ensuring long-range contextual continuity. Experimental results on GID and FBPS demonstrate that SFR-Net achieves state-of-the-art performance, improving mIoU by 1.72% and 4.29%, respectively, over the strongest competing methods. In addition, the proposed scale-frustum representations can be integrated into generic segmentation networks to improve both segmentation accuracy and convergence speed. The implementation code will be publicly available at https://github.com/ChuyuZhong/SFR-Net.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ultra-wide area (UWA) remote sensing image segmentation task, characterized by both high pixel counts and extremely wide geographical coverage. It proposes SFR-Net, which constructs scale-frustum representations inspired by viewing frustums from different altitudes to enable unified modeling of multi-scale ground objects and contextual features. A cascaded cross-scale fusion mechanism integrates these representations to improve local semantics and long-range continuity. On the GID and FBPS datasets, SFR-Net reports state-of-the-art mIoU gains of 1.72% and 4.29% over the strongest baselines; the scale-frustum representations are also shown to boost accuracy and convergence when plugged into generic segmentation networks. Code will be released publicly.
Significance. If the reported gains prove robust, the work could advance remote sensing segmentation by jointly addressing scale variation and long-range context in large-coverage imagery. The empirical improvements and the plug-in compatibility with existing networks constitute the main potential contribution. Public code availability is a clear strength for reproducibility.
minor comments (2)
- Abstract: the mIoU improvements are stated relative to 'the strongest competing methods' without naming the baselines or reporting absolute mIoU values; adding these details would make the performance claim easier to assess.
- Abstract: the claim that scale-frustum representations 'can be integrated into generic segmentation networks' is presented without quantitative evidence in the abstract; a brief supporting result or reference to the relevant experiment would strengthen the statement.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The positive assessment of the significance of SFR-Net, the scale-frustum representations, and the reported gains on GID and FBPS is appreciated. As the report contains no specific major comments, we have no points requiring response or revision.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new segmentation task for ultra-wide area images and proposes SFR-Net with scale-frustum representations and cascaded fusion as a novel architectural design motivated by viewing frustums. No equations, fitted parameters, or predictions are presented that reduce by construction to prior inputs or self-citations. The central claims rest on empirical mIoU improvements on GID and FBPS datasets, with the method described as integrable into generic networks. The derivation chain is self-contained as an empirical proposal without load-bearing reductions to definitions, fits, or author-prior uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Viewing frustums from different altitudes provide a useful analogy for constructing multi-scale representations of ground objects
invented entities (2)
-
scale-frustum representations
no independent evidence
-
cascaded cross-scale fusion mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Land-cover classification with high-resolution remote sensing images using transferable deep models,
X.-Y . Tong, G.-S. Xia, Q. Lu, H. Shen, S. Li, S. You, and L. Zhang, “Land-cover classification with high-resolution remote sensing images using transferable deep models,”Remote Sensing of Environment, vol. 237, p. 111322, 2020
2020
-
[2]
Enabling country-scale land cover mapping with meter-resolution satellite imagery,
X.-Y . Tong, G.-S. Xia, and X. X. Zhu, “Enabling country-scale land cover mapping with meter-resolution satellite imagery,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 196, pp. 178–196, 2023
2023
-
[3]
Fully convolutional networks for semantic segmentation,
J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440
2015
-
[4]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[5]
Segnet: A deep con- volutional encoder-decoder architecture for image segmentation,
V . Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep con- volutional encoder-decoder architecture for image segmentation,”IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 12, pp. 2481–2495, 2017
2017
-
[6]
Per-pixel classification is not all you need for semantic segmentation,
B. Cheng, A. Schwing, and A. Kirillov, “Per-pixel classification is not all you need for semantic segmentation,”Advances in neural information processing systems, vol. 34, pp. 17 864–17 875, 2021
2021
-
[7]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[8]
Rsprompter: Learning to prompt for remote sensing instance seg- mentation based on visual foundation model,
K. Chen, C. Liu, H. Chen, H. Zhang, W. Li, Z. Zou, and Z. Shi, “Rsprompter: Learning to prompt for remote sensing instance seg- mentation based on visual foundation model,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–17, 2024
2024
-
[9]
From contexts to locality: Ultra-high resolution image segmentation via locality-aware contextual correlation,
Q. Li, W. Yang, W. Liu, Y . Yu, and S. He, “From contexts to locality: Ultra-high resolution image segmentation via locality-aware contextual correlation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 7252–7261
2021
-
[10]
Rest: Holistic learning for end-to-end semantic segmentation of whole-scene remote sensing imagery,
W. Chen, L. Bruzzone, B. Dang, Y . Gao, Y . Deng, J.-G. Yu, L. Yuan, and Y . Li, “Rest: Holistic learning for end-to-end semantic segmentation of whole-scene remote sensing imagery,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 1, pp. 693–710, 2026
2026
-
[11]
Collaborative global-local networks for memory-efficient segmentation of ultra-high resolution images,
W. Chen, Z. Jiang, Z. Wang, K. Cui, and X. Qian, “Collaborative global-local networks for memory-efficient segmentation of ultra-high resolution images,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8924–8933
2019
-
[12]
Patch proposal network for fast semantic segmentation of high-resolution images,
T. Wu, Z. Lei, B. Lin, C. Li, Y . Qu, and Y . Xie, “Patch proposal network for fast semantic segmentation of high-resolution images,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12 402–12 409
2020
-
[13]
Uhrsnet: A semantic segmentation network specifically for ultra-high- resolution images,
L. Shan, M. Li, X. Li, Y . Bai, K. Lv, B. Luo, S.-B. Chen, and W. Wang, “Uhrsnet: A semantic segmentation network specifically for ultra-high- resolution images,” in2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021, pp. 1460–1466. 13
2021
-
[14]
Isdnet: Integrating shallow and deep net- works for efficient ultra-high resolution segmentation,
S. Guo, L. Liu, Z. Gan, Y . Wang, W. Zhang, C. Wang, G. Jiang, W. Zhang, R. Yi, L. Maet al., “Isdnet: Integrating shallow and deep net- works for efficient ultra-high resolution segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4361–4370
2022
-
[15]
Guided patch-grouping wavelet transformer with spatial congruence for ultra-high resolution segmentation,
D. Ji, F. Zhao, and H. Lu, “Guided patch-grouping wavelet transformer with spatial congruence for ultra-high resolution segmentation,” in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23), 2023, pp. 920–928
2023
-
[16]
Pyramid scene parsing network,
H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890
2017
-
[17]
Icnet for real-time semantic segmentation on high-resolution images,
H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “Icnet for real-time semantic segmentation on high-resolution images,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 405– 420
2018
-
[18]
Encoder- decoder with atrous separable convolution for semantic image segmen- tation,
L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder- decoder with atrous separable convolution for semantic image segmen- tation,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 801–818
2018
-
[19]
D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction,
L. Zhou, C. Zhang, and M. Wu, “D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 182–186
2018
-
[20]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[21]
Multi-scale context ag- gregation for semantic segmentation of remote sensing images,
J. Zhang, S. Lin, L. Ding, and L. Bruzzone, “Multi-scale context ag- gregation for semantic segmentation of remote sensing images,”Remote Sensing, vol. 12, no. 4, p. 701, 2020
2020
-
[22]
Bisenet: Bilateral segmentation network for real-time semantic segmentation,
C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “Bisenet: Bilateral segmentation network for real-time semantic segmentation,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 325–341
2018
-
[23]
Re- thinking bisenet for real-time semantic segmentation,
M. Fan, S. Lai, J. Huang, X. Wei, Z. Chai, J. Luo, and X. Wei, “Re- thinking bisenet for real-time semantic segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9716–9725
2021
-
[24]
An image is worth 16x16 words: transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: transformers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021, pp. 611–631
2021
-
[25]
Segformer: Simple and efficient design for semantic segmentation with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,”Advances in neural information processing systems, vol. 34, pp. 12 077–12 090, 2021
2021
-
[26]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[27]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1290–1299
2022
-
[28]
Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,
S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y . Wang, Y . Fu, J. Feng, T. Xiang, P. H. Torret al., “Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 6881–6890
2021
-
[29]
Dual attention network for scene segmentation,
J. Fu, J. Liu, H. Tian, Y . Li, Y . Bao, Z. Fang, and H. Lu, “Dual attention network for scene segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3146– 3154
2019
-
[30]
Scattnet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images,
H. Li, K. Qiu, L. Chen, X. Mei, L. Hong, and C. Tao, “Scattnet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images,”IEEE Geoscience and Remote Sensing Letters, vol. 18, no. 5, pp. 905–909, 2020
2020
-
[31]
Lanet: Local attention embedding to improve the semantic segmentation of remote sensing images,
L. Ding, H. Tang, and L. Bruzzone, “Lanet: Local attention embedding to improve the semantic segmentation of remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 1, pp. 426–435, 2020
2020
-
[32]
Rsrefseg 2: Decoupling referring remote sensing image segmentation with founda- tion models,
K. Chen, C. Liu, B. Chen, J. Zhang, Z. Zou, and Z. Shi, “Rsrefseg 2: Decoupling referring remote sensing image segmentation with founda- tion models,”IEEE Transactions on Geoscience and Remote Sensing, vol. 64, pp. 1–20, 2025
2025
-
[33]
Taco: Cap- turing spatio-temporal semantic consistency in remote sensing change detection,
H. Guo, C. Liu, H. Zhang, B. Chen, Z. Zou, and Z. Shi, “Taco: Cap- turing spatio-temporal semantic consistency in remote sensing change detection,”arXiv preprint arXiv:2511.20306, 2025
-
[34]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst conference on language modeling, 2024
2024
-
[35]
State-space models,
J. D. Hamilton, “State-space models,”Handbook of econometrics, vol. 4, pp. 3039–3080, 1994
1994
-
[36]
Dynamicvis: An efficient and general visual foundation model for remote sensing image understanding,
K. Chen, C. Liu, B. Chen, W. Li, Z. Zou, and Z. Shi, “Dynamicvis: An efficient and general visual foundation model for remote sensing image understanding,”arXiv preprint arXiv:2503.16426, 2025
-
[37]
Rs-mamba for large remote sensing image dense prediction,
S. Zhao, H. Chen, X. Zhang, P. Xiao, L. Bai, and W. Ouyang, “Rs-mamba for large remote sensing image dense prediction,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–14, 2024
2024
-
[38]
Rs 3 mamba: Visual state space model for remote sensing image semantic segmentation,
X. Ma, X. Zhang, and M.-O. Pun, “Rs 3 mamba: Visual state space model for remote sensing image semantic segmentation,”IEEE Geo- science and Remote Sensing Letters, vol. 21, pp. 1–5, 2024
2024
-
[39]
Unet- mamba: An efficient unet-like mamba for semantic segmentation of high-resolution remote sensing images,
E. Zhu, Z. Chen, D. Wang, H. Shi, X. Liu, and L. Wang, “Unet- mamba: An efficient unet-like mamba for semantic segmentation of high-resolution remote sensing images,”IEEE Geoscience and Remote Sensing Letters, vol. 22, pp. 1–5, 2024
2024
-
[40]
Cascadepsp: Toward class-agnostic and very high-resolution segmentation via global and local refinement,
H. K. Cheng, J. Chung, Y .-W. Tai, and C.-K. Tang, “Cascadepsp: Toward class-agnostic and very high-resolution segmentation via global and local refinement,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8890–8899
2020
-
[41]
Pointrend: Image seg- mentation as rendering,
A. Kirillov, Y . Wu, K. He, and R. Girshick, “Pointrend: Image seg- mentation as rendering,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9799–9808
2020
-
[42]
Memory- constrained semantic segmentation for ultra-high resolution uav im- agery,
Q. Li, J. Cai, J. Luo, Y . Yu, J. Gu, J. Pan, and W. Liu, “Memory- constrained semantic segmentation for ultra-high resolution uav im- agery,”IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 1708– 1715, 2024
2024
-
[43]
Ultra-high resolution segmen- tation with ultra-rich context: A novel benchmark,
D. Ji, F. Zhao, H. Lu, M. Tao, and J. Ye, “Ultra-high resolution segmen- tation with ultra-rich context: A novel benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 23 621–23 630
2023
-
[44]
Wave-vit: Unifying wavelet and transformers for visual representation learning,
T. Yao, Y . Pan, Y . Li, C.-W. Ngo, and T. Mei, “Wave-vit: Unifying wavelet and transformers for visual representation learning,” inEuropean conference on computer vision. Springer, 2022, pp. 328–345
2022
-
[45]
Boosting the dual-stream architecture in ultra-high resolution segmentation with resolution-biased uncertainty estimation,
R. Qin, X. Liu, J. Shi, L. Lin, and J. Yang, “Boosting the dual-stream architecture in ultra-high resolution segmentation with resolution-biased uncertainty estimation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 25 960–25 970
2025
-
[46]
Ultra-high resolution segmentation via boundary-enhanced patch-merging transformer,
H. Sun, Y . Zhang, L. Xu, S. Jin, and Y . Chen, “Ultra-high resolution segmentation via boundary-enhanced patch-merging transformer,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7087–7095
2025
-
[47]
Ultra-high resolution image segmentation via locality-aware context fusion and alternating local enhancement,
W. Liu, Q. Li, X. Lin, W. Yang, S. He, and Y . Yu, “Ultra-high resolution image segmentation via locality-aware context fusion and alternating local enhancement,”International Journal of Computer Vision, vol. 132, no. 11, pp. 5030–5047, 2024
2024
-
[48]
Progressive semantic seg- mentation,
C. Huynh, A. T. Tran, K. Luu, and M. Hoai, “Progressive semantic seg- mentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 755–16 764
2021
-
[49]
Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing im- ages,
L. Ding, D. Lin, S. Lin, J. Zhang, X. Cui, Y . Wang, H. Tang, and L. Bruzzone, “Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing im- ages,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022
2022
-
[50]
Deepglobe 2018: A challenge to parse the earth through satellite images,
I. Demir, K. Koperski, D. Lindenbaum, G. Pang, J. Huang, S. Basu, F. Hughes, D. Tuia, and R. Raskar, “Deepglobe 2018: A challenge to parse the earth through satellite images,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 172–181
2018
-
[51]
Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark,
E. Maggiori, Y . Tarabalka, G. Charpiat, and P. Alliez, “Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark,” in2017 IEEE International geoscience and remote sensing symposium (IGARSS). IEEE, 2017, pp. 3226–3229
2017
-
[52]
Deep high-resolution repre- sentation learning for human pose estimation,
K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution repre- sentation learning for human pose estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5693–5703
2019
-
[53]
Object-contextual representations for semantic segmentation,
Y . Yuan, X. Chen, and J. Wang, “Object-contextual representations for semantic segmentation,” inComputer Vision – ECCV 2020, A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds. Cham: Springer Interna- tional Publishing, 2020, pp. 173–190. 14
2020
-
[54]
Convnext v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoencoders,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 16 133–16 142
2023
-
[55]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
Unified perceptual parsing for scene understanding,
T. Xiao, Y . Liu, B. Zhou, Y . Jiang, and J. Sun, “Unified perceptual parsing for scene understanding,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 418–434
2018
-
[57]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[59]
Mmsegmentation: Openmmlab semantic segmentation toolbox and benchmark,
M. Contributors, “Mmsegmentation: Openmmlab semantic segmentation toolbox and benchmark,” 2020. Chuyu Zhongreceived the B.S. degree from the School of Astronautics, Beihang University, Beijing, China, in 2025. He is currently pursuing the Ph.D. degree with the Image Processing Center, School of Astronautics, Beihang University. His research interests incl...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.