VertiCue-Bench: Diagnosing Whether MLLMs Use Height Cues to Resolve 2D Ambiguity in Remote Sensing Natural Scenes
Pith reviewed 2026-06-29 22:29 UTC · model grok-4.3
The pith
Current MLLMs read canopy height data but rarely apply it to resolve spectral ambiguities in natural remote sensing scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
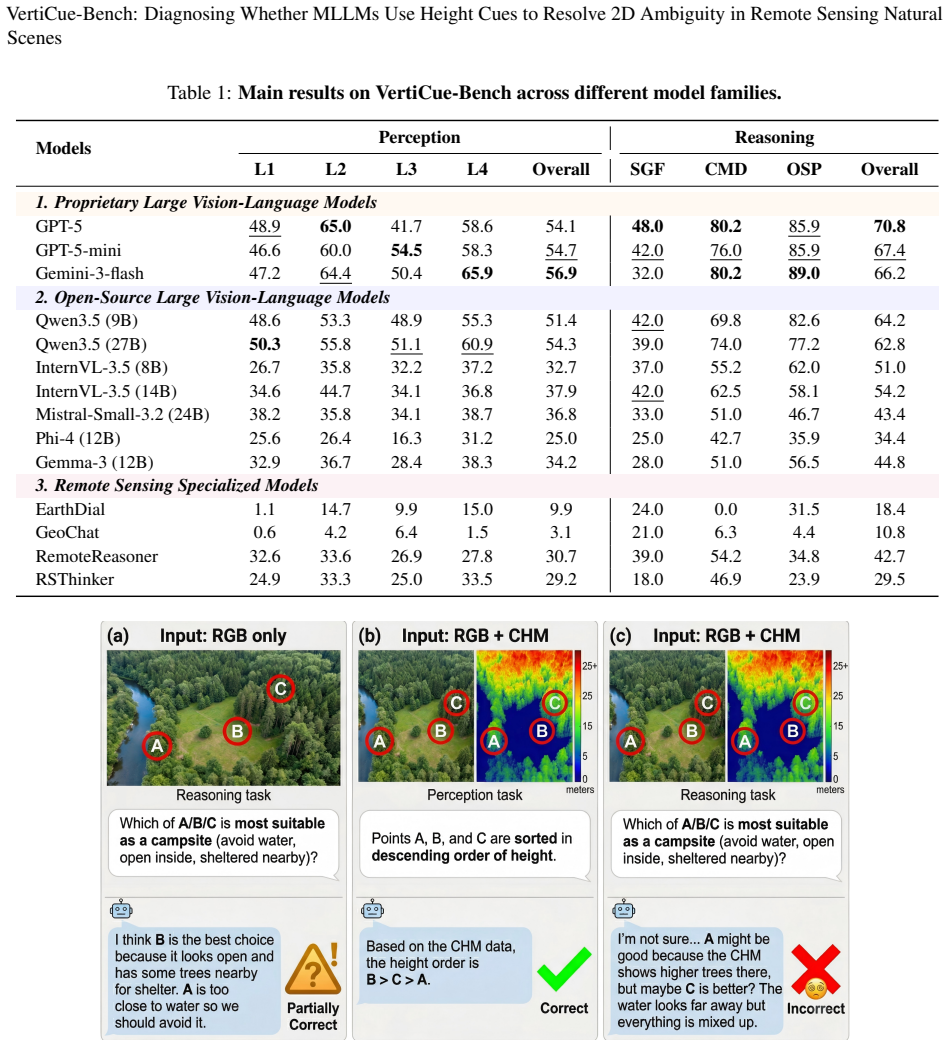
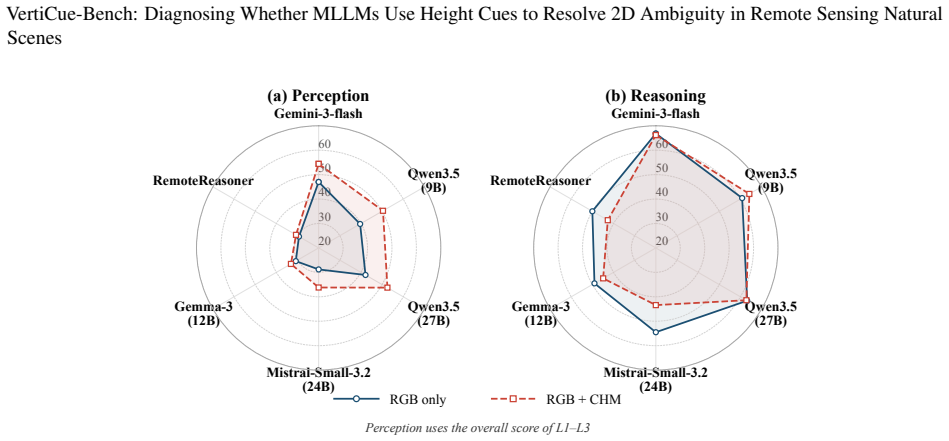
VertiCue-Bench reveals a perception-reasoning dissociation: models exhibit emerging competence in reading raw CHM height cues, yet largely fail to translate geometric perception into reliable semantic reasoning and often underperform RGB-only baselines when joint constraints are required.
What carries the argument
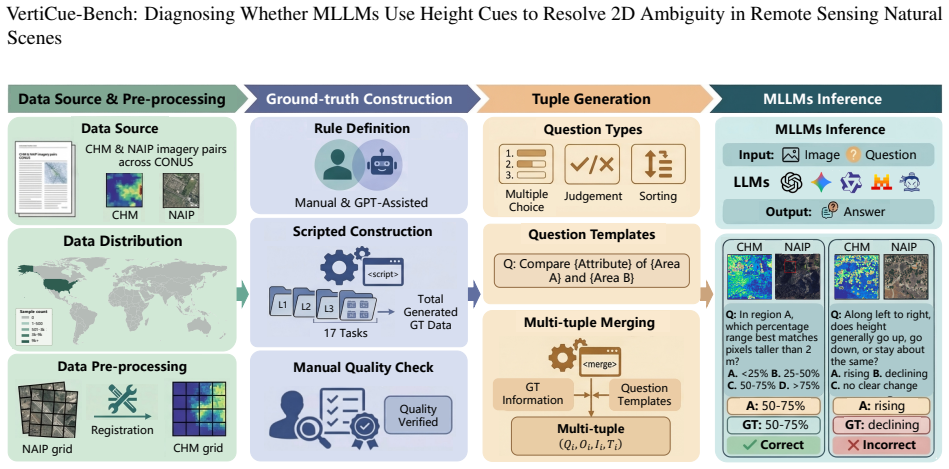
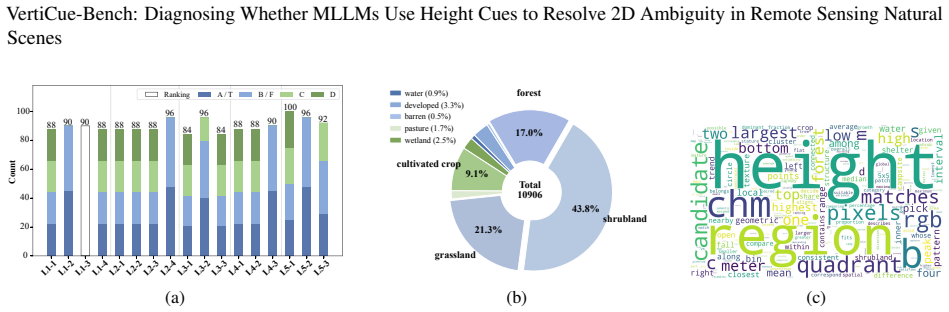
VertiCue-Bench, a benchmark of 1,534 curated instances across 17 tasks that separate low-level height perception from ambiguity-aware semantic reasoning.
If this is right
- Models that pass isolated height-reading tests will still produce unreliable answers on tasks requiring joint image-and-height constraints.
- Adding canopy height data can degrade performance relative to image-only input when the model lacks a mechanism to treat height as a disambiguating constraint.
- Progress on geospatial MLLMs will require explicit training or architectures that enforce consistency between geometric measurements and semantic categories.
- Existing remote-sensing benchmarks that omit vertical structure will continue to overestimate model capability on natural scenes.
Where Pith is reading between the lines
- Future benchmarks could add controlled noise to the height maps to measure how sensitive reasoning remains when the geometric cue is imperfect.
- The observed dissociation suggests that training objectives focused only on captioning or question answering may not encourage the model to treat height as evidence that rules out certain interpretations.
- Architectures that maintain separate streams for appearance and structure until a late fusion stage might close the gap observed here.
Load-bearing premise
The 1,534 instances and 17 tasks were designed and selected so that success or failure can be attributed specifically to the ability to combine height with appearance rather than to other factors in data curation or prompting.
What would settle it
Run the same 14 models on a fresh collection of scenes where height differences are the only reliable cue for correct labels; if accuracy stays near or below the RGB-only baseline, the dissociation claim holds.
Figures

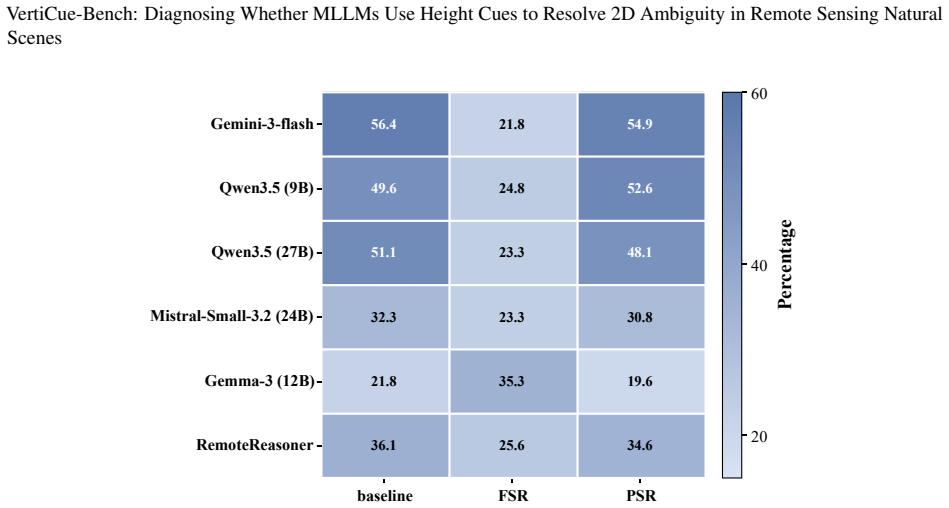
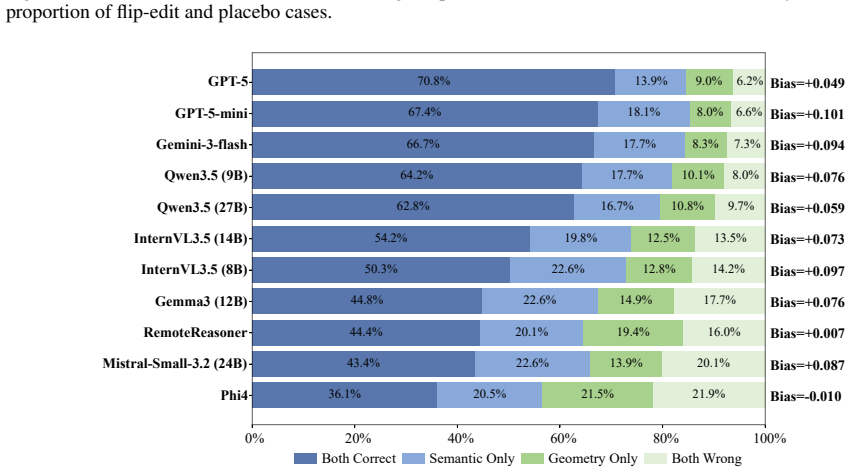
read the original abstract
Multimodal Large Language Models (MLLMs) have recently shown promising progress in geospatial reasoning. However, existing remote sensing benchmarks remain largely 2D-centric, evaluating models primarily on optical appearance. In natural environments, this paradigm breaks down due to severe spectral confusion, where ecologically distinct regions share similar textures but differ fundamentally in vertical structure. In such cases, explicit 3D structural data, such as Canopy Height Models (CHMs), become essential geometric evidence for semantic disambiguation. Yet, it remains unclear whether current MLLMs can genuinely leverage vertical cues to resolve appearance-level ambiguity. To address this gap, we introduce VertiCue-Bench, the first diagnostic benchmark for CHM-grounded geospatial reasoning. VertiCue-Bench comprises 1,534 carefully curated instances across 17 tasks, explicitly disentangling low-level height perception from ambiguity-aware semantic reasoning. Evaluations on 14 state-of-the-art general and remote-sensing-specialized MLLMs, combined with counterfactual modality testing, reveal a striking perception-reasoning dissociation. While models exhibit emerging competence in reading raw CHM height cues, they largely fail to translate geometric perception into reliable semantic reasoning, often underperforming RGB-only baselines when joint constraints are required. Overall, VertiCue-Bench exposes a critical geometry-to-semantics gap in natural scene understanding, offering actionable insights for advancing geospatial MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VertiCue-Bench, a diagnostic benchmark with 1,534 instances across 17 tasks that explicitly disentangles low-level height perception (via Canopy Height Models) from ambiguity-aware semantic reasoning in remote sensing natural scenes. Evaluations of 14 general and remote-sensing-specialized MLLMs, combined with counterfactual modality testing, claim to reveal a perception-reasoning dissociation: models show emerging competence in reading raw CHM cues but largely fail to translate this into reliable semantic reasoning and often underperform RGB-only baselines when joint constraints are required.
Significance. If the dissociation holds after proper validation of the benchmark tasks, the work would be significant for exposing a geometry-to-semantics gap in current MLLMs for geospatial reasoning. It provides a new diagnostic benchmark that could guide improvements in integrating 3D structural data with semantic understanding, particularly in natural scenes with spectral confusion.
major comments (1)
- [Abstract / VertiCue-Bench construction] The central claim of a perception-reasoning dissociation rests on the 1,534 instances across 17 tasks being constructed such that low-level CHM reading is separable from ambiguity-aware semantic use, and that joint RGB+CHM inputs require the height cue for correct reasoning. The abstract states the instances were 'carefully curated to explicitly disentangle' these capabilities, but provides no details on validation of the disentanglement, confirmation of unique disambiguation cases, or checks against confounds such as RGB texture already correlating with height or alternative non-height cues sufficing. Without such validation, underperformance on joint inputs could reflect fusion or prompting artifacts rather than a true gap (see also the weakest assumption in the provided reader's take).
minor comments (2)
- [Abstract] The abstract reports evaluations on 14 models but does not mention error bars, statistical significance testing, or variance across runs, which are needed to assess whether the reported dissociation is robust.
- [Abstract] Details on task construction, data selection criteria, and how the 17 tasks were designed to isolate height perception from semantic reasoning are absent from the abstract and would be required for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying the need for greater transparency on benchmark validation. We address the major comment below and will incorporate clarifications in the revision.
read point-by-point responses
-
Referee: [Abstract / VertiCue-Bench construction] The central claim of a perception-reasoning dissociation rests on the 1,534 instances across 17 tasks being constructed such that low-level CHM reading is separable from ambiguity-aware semantic use, and that joint RGB+CHM inputs require the height cue for correct reasoning. The abstract states the instances were 'carefully curated to explicitly disentangle' these capabilities, but provides no details on validation of the disentanglement, confirmation of unique disambiguation cases, or checks against confounds such as RGB texture already correlating with height or alternative non-height cues sufficing. Without such validation, underperformance on joint inputs could reflect fusion or prompting artifacts rather than a true gap (see also the weakest assumption in the provided reader's take).
Authors: We agree that the abstract is necessarily concise and does not itself contain the validation details. Section 3.2 and Appendix A of the manuscript describe the curation pipeline: candidate scenes were first filtered for spectral confusion where RGB-only performance is near chance; expert annotators then verified that CHM supplies the sole disambiguating cue (with inter-annotator agreement reported); and each task includes explicit RGB-only, CHM-only, and joint conditions to isolate the contribution of height. We acknowledge, however, that quantitative checks for residual RGB-height correlations and exhaustive tests ruling out alternative non-height cues (e.g., shadow or texture gradients) are only summarized rather than tabulated. We will add a dedicated subsection and supplementary table reporting these confound analyses in the revised manuscript. revision: partial
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper introduces VertiCue-Bench as an empirical diagnostic dataset and reports model performance on it. No derivations, equations, fitted parameters, or predictions exist that could reduce to inputs by construction. The dissociation claim is measured from held-out model outputs under different modality conditions rather than being defined in terms of the benchmark itself. Curation is presented as a methodological choice, not a self-referential definition or self-citation load-bearing step. No self-citations or ansatzes are invoked in the provided text to support core results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad S
Kartik Kuckreja, Muhammad S. Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad S. Khan. Geochat: Grounded large vision-language model for remote sensing.The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[4]
Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery.Remote Sensing, 16(9), 2024
Yakoub Bazi, Laila Bashmal, Mohamad Mahmoud Al Rahhal, Riccardo Ricci, and Farid Melgani. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery.Remote Sensing, 16(9), 2024
2024
-
[5]
Vhm: Versatile and honest vision language model for remote sensing image analysis.Proceedings of the AAAI Conference on Artificial Intelligence, 39(6):6381–6388, Apr
Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Jiaxing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, and Conghui He. Vhm: Versatile and honest vision language model for remote sensing image analysis.Proceedings of the AAAI Conference on Artificial Intelligence, 39(6):6381–6388, Apr. 2025
2025
-
[6]
Earthdial: Turning multi-sensory earth observations to interactive dialogues
Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fahad Shahbaz Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025
2025
-
[7]
Geopixel: Pixel grounding large multimodal model in remote sensing
Akashah Shabbir, Mohammed Zumri, Mohammed Bennamoun, Fahad Shahbaz Khan, and Salman Khan. Geopixel: Pixel grounding large multimodal model in remote sensing. InForty-second International Conference on Machine Learning, 2025
2025
-
[8]
Towards faithful reasoning in remote sensing: A perceptually- grounded geospatial chain-of-thought for vision-language models
Jiaqi Liu, Lang Sun, Ronghao Fu, and Bo Yang. Towards faithful reasoning in remote sensing: A perceptually- grounded geospatial chain-of-thought for vision-language models. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[9]
Re- motereasoner: Towards unifying geospatial reasoning workflow.Proceedings of the AAAI Conference on Artificial Intelligence, 40(14):11883–11891, Mar
Liang Yao, Fan Liu, Hongbo Lu, Chuanyi Zhang, Rui Min, Shengxiang Xu, Shimin Di, and Pai Peng. Re- motereasoner: Towards unifying geospatial reasoning workflow.Proceedings of the AAAI Conference on Artificial Intelligence, 40(14):11883–11891, Mar. 2026
2026
-
[10]
Rsgpt: A remote sensing vision language model and benchmark.ISPRS Journal of Photogrammetry and Remote Sensing, 224:272–286, 2025
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, Yu Liu, and Xiang Li. Rsgpt: A remote sensing vision language model and benchmark.ISPRS Journal of Photogrammetry and Remote Sensing, 224:272–286, 2025
2025
-
[11]
Hrvqa: A visual question answering benchmark for high-resolution aerial images.ISPRS Journal of Photogrammetry and Remote Sensing, 214:65–81, 2024
Kun Li, George V osselman, and Michael Ying Yang. Hrvqa: A visual question answering benchmark for high-resolution aerial images.ISPRS Journal of Photogrammetry and Remote Sensing, 214:65–81, 2024
2024
-
[12]
Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering
Junjue Wang, Zhuo Zheng, Zihang Chen, Ailong Ma, and Yanfei Zhong. Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 5481–5489, 2024. 12 VertiCue-Bench: Diagnosing Whether MLLMs Use Height Cues to Resolve 2D Ambiguity ...
2024
-
[13]
Rsvlm-qa: A benchmark dataset for remote sensing vision language model-based question answering
Xing Zi, Jinghao Xiao, Yunxiao Shi, Xian Tao, Jun Li, Ali Braytee, and Mukesh Prasad. Rsvlm-qa: A benchmark dataset for remote sensing vision language model-based question answering. InProceedings of the 33rd ACM International Conference on Multimedia, pages 12905–12911, 2025
2025
-
[14]
Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding.Advances in Neural Information Processing Systems, 37:3229–3242, 2024
Xiang Li, Jian Ding, and Mohamed Elhoseiny. Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding.Advances in Neural Information Processing Systems, 37:3229–3242, 2024
2024
-
[15]
Geobench-vlm: Benchmarking vision-language models for geospatial tasks
Muhammad Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Kartik Kuckreja, Fahad Shahbaz Khan, Paolo Fraccaro, Alexandre Lacoste, and Salman Khan. Geobench-vlm: Benchmarking vision-language models for geospatial tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7132–7142, 2025
2025
-
[16]
CHOICE: Benchmarking the remote sensing capabilities of large vision-language models
Xiao An, Jiaxing Sun, Zihan Gui, and Wei He. CHOICE: Benchmarking the remote sensing capabilities of large vision-language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[17]
Fengxiang Wang, Hongzhen Wang, Zonghao Guo, Di Wang, Yulin Wang, Mingshuo Chen, Qiang Ma, Long Lan, Wenjing Yang, Jing Zhang, et al. Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14325–14336, 2025
2025
-
[18]
VLRS-Bench: A Vision-Language Reasoning Benchmark for Remote Sensing
Zhiming Luo, Di Wang, Haonan Guo, Jing Zhang, and Bo Du. Vlrs-bench: A vision-language reasoning benchmark for remote sensing.arXiv preprint arXiv:2602.07045, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Geo3dvqa: Evaluating vision-language models for 3d geospatial reasoning from aerial imagery
Mai Tsujimoto, Junjue Wang, Weihao Xuan, and Naoto Yokoya. Geo3dvqa: Evaluating vision-language models for 3d geospatial reasoning from aerial imagery. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4994–5003, 2026
2026
-
[20]
A survey of image classification methods and techniques for improving classification performance.International journal of Remote sensing, 28(5):823–870, 2007
Dengsheng Lu and Qihao Weng. A survey of image classification methods and techniques for improving classification performance.International journal of Remote sensing, 28(5):823–870, 2007
2007
-
[21]
Lidar data fusion to improve forest attribute estimates: A review.Current Forestry Reports, 10(4):281–297, 2024
Mattia Balestra, Suzanne Marselis, Temuulen Tsagaan Sankey, Carlos Cabo, Xinlian Liang, Martin Mokroš, Xi Peng, Arunima Singh, Krzysztof Stere´nczak, Cedric Vega, et al. Lidar data fusion to improve forest attribute estimates: A review.Current Forestry Reports, 10(4):281–297, 2024
2024
-
[22]
Fine classification of urban tree species based on uav-based rgb imagery and lidar data.Forests, 15(2):390, 2024
Jingru Wu, Qixia Man, Xinming Yang, Pinliang Dong, Xiaotong Ma, Chunhui Liu, and Changyin Han. Fine classification of urban tree species based on uav-based rgb imagery and lidar data.Forests, 15(2):390, 2024
2024
-
[23]
A deep-learning-based tree species classification for natural secondary forests using unmanned aerial vehicle hyperspectral images and lidar.Ecological Indicators, 159:111608, 2024
Ye Ma, Yuting Zhao, Jungho Im, Yinghui Zhao, and Zhen Zhen. A deep-learning-based tree species classification for natural secondary forests using unmanned aerial vehicle hyperspectral images and lidar.Ecological Indicators, 159:111608, 2024
2024
-
[24]
Mapping urban tree species by integrating canopy height model with multi-temporal sentinel-2 data.Remote Sensing, 17(5):790, 2025
Yang Yao, Xiaoke Wang, Haiming Qin, Weimin Wang, and Weiqi Zhou. Mapping urban tree species by integrating canopy height model with multi-temporal sentinel-2 data.Remote Sensing, 17(5):790, 2025
2025
-
[25]
Object-based tree species classification using airborne hyperspectral images and lidar data.Forests, 11(1):32, 2019
Yanshuang Wu and Xiaoli Zhang. Object-based tree species classification using airborne hyperspectral images and lidar data.Forests, 11(1):32, 2019
2019
-
[26]
Remote sensing vision-language foundation models without annotations via ground remote alignment
Utkarsh Mall, Cheng Perng Phoo, Meilin Kelsey Liu, Carl V ondrick, Bharath Hariharan, and Kavita Bala. Remote sensing vision-language foundation models without annotations via ground remote alignment. InICLR, 2024
2024
-
[27]
Remoteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Remoteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024
2024
-
[28]
Rs5m and georsclip: A large scale vision-language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, pages 1–1, 2024
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m and georsclip: A large scale vision-language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, pages 1–1, 2024
2024
-
[29]
Skyeyegpt: Unifying remote sensing vision-language tasks via instruction tuning with large language model.ISPRS Journal of Photogrammetry and Remote Sensing, 221:64–77, 2025
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Skyeyegpt: Unifying remote sensing vision-language tasks via instruction tuning with large language model.ISPRS Journal of Photogrammetry and Remote Sensing, 221:64–77, 2025
2025
-
[30]
Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model
Dilxat Muhtar, Zhenshi Li, Feng Gu, Xueliang Zhang, and Pengfeng Xiao. Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model. InComputer Vision – ECCV 2024, pages 440–457, Cham,
2024
-
[31]
Springer Nature Switzerland
-
[32]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Di Wang, Haotian Wang, Zonghao Guo, Zefan Wang, Boqi Shan, Long Lan, Yulin Wang, et al. Geollava-8k: scaling remote-sensing multimodal large language models to 8k resolution.arXiv preprint arXiv:2505.21375, 2025. 13 VertiCue-Bench: Diagnosing Whether MLLMs Use Height Cues to Resolve 2D Ambiguity in Remote Sensing...
-
[33]
Terramind: Large-scale generative multimodality for earth observation
Johannes Jakubik, Felix Yang, Benedikt Blumenstiel, Erik Scheurer, Rocco Sedona, Stefano Maurogiovanni, Jente Bosmans, Nikolaos Dionelis, Valerio Marsocci, Niklas Kopp, et al. Terramind: Large-scale generative multimodality for earth observation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7383–7394, 2025
2025
-
[34]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Yajie Yang, Yifan Zhang, Long Lan, Xue Yang, Hongda Sun, Yulin Wang, Di Wang, et al. Geoeyes: On-demand visual focusing for evidence-grounded understanding of ultra-high-resolution remote sensing imagery.arXiv preprint arXiv:2602.14201, 2026
-
[35]
Ke Li, Fuyu Dong, Di Wang, Shaofeng Li, Quan Wang, Xinbo Gao, and Tat-Seng Chua. Show me what and where has changed? question answering and grounding for remote sensing change detection.arXiv preprint arXiv:2410.23828, 2024
-
[36]
Qingmei Li, Yang Zhang, Zurong Mai, Yuhang Chen, Shuohong Lou, Henglian Huang, Jiarui Zhang, Zhiwei Zhang, Yibin Wen, Weijia Li, et al. Can large multimodal models understand agricultural scenes? benchmarking with agromind.arXiv preprint arXiv:2505.12207, 2025
-
[37]
Canopy height model and naip imagery pairs across conus.Scientific Data, 12(1):322, 2025
Brady W Allred, Sarah E McCord, and Scott L Morford. Canopy height model and naip imagery pairs across conus.Scientific Data, 12(1):322, 2025
2025
-
[38]
YiFan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, Liang Wang, and Rong Jin. MME-realworld: Could your multimodal LLM challenge high-resolution real-world scenarios that are difficult for humans? InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[39]
Openai gpt-5 system card, 2025
Aaditya Singh, Adam Fry, Adam Perelman, et al. Openai gpt-5 system card, 2025
2025
-
[40]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
2026
-
[41]
Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
Weiyun Wang, Zhangwei Gao, Lixin Gu, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
2025
-
[42]
Mistralai/mistral-small-3.1-24b-instruct-2503 · hugging face
Team MistralAI. Mistralai/mistral-small-3.1-24b-instruct-2503 · hugging face
-
[43]
Phi-4 technical report, 2024
Marah Abdin, Jyoti Aneja, Harkirat Behl, et al. Phi-4 technical report, 2024
2024
-
[44]
Gemma 3 technical report, 2025
Gemma Team, Aishwarya Kamath, Johan Ferret, et al. Gemma 3 technical report, 2025. 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.