On the Limits of Model Merging for Multilinguality in Pre-Training
Pith reviewed 2026-06-29 21:18 UTC · model grok-4.3
The pith
Merging any combination of monolingual pre-trained models leads to multilingual performance collapse due to interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
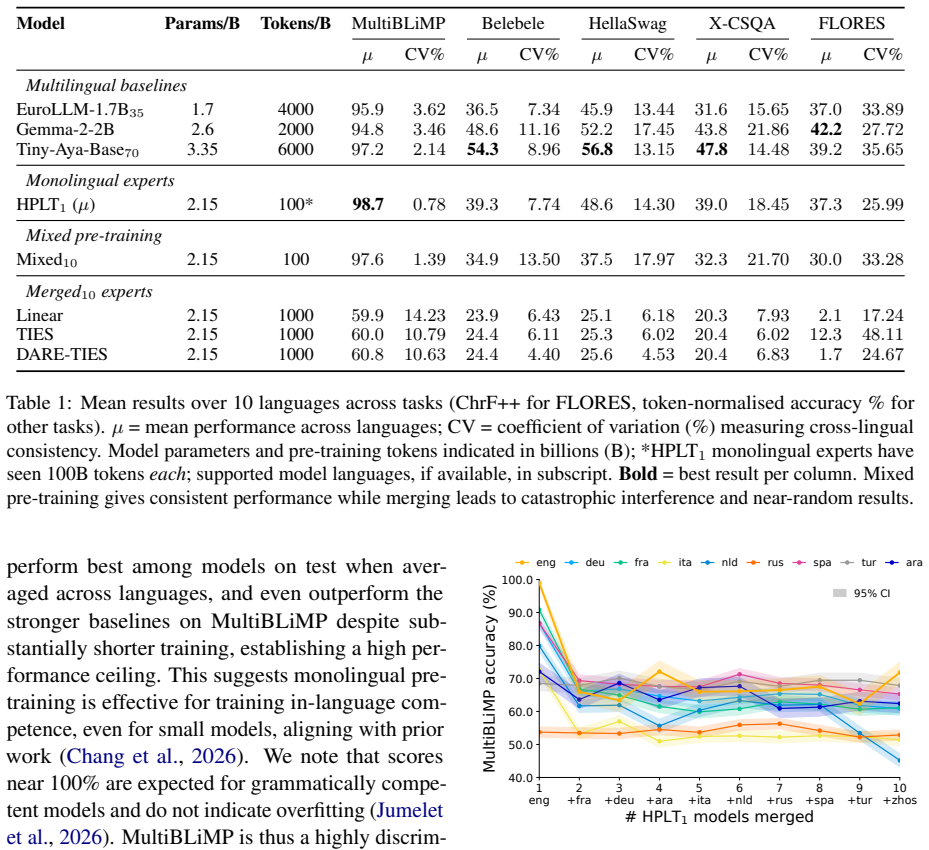
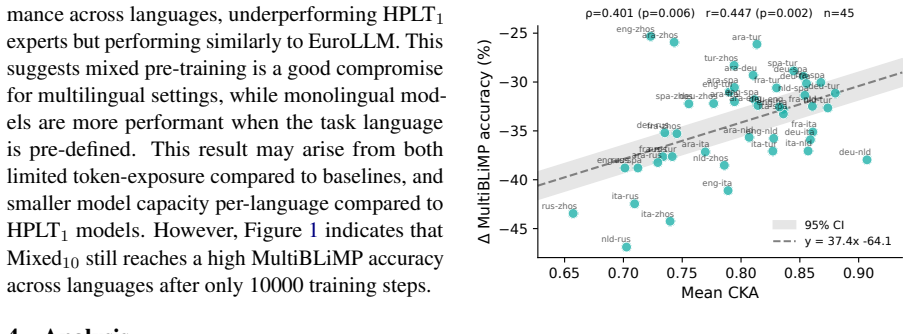
Monolingual pre-training results in strong in-language performance, but merging any combination of monolingual models leads to performance collapse due to interference. Representational similarity is a prerequisite for model merging. The flexibility of merging in fine-tuning therefore does not extend trivially to language-specific pre-training.
What carries the argument
Representational similarity between models, required to prevent interference during merging.
If this is right
- Mixed pre-training data is required to achieve consistent multilingual performance.
- Model merging works only when the base models already share similar representations.
- Isolated monolingual pre-training produces models that cannot be merged without loss.
- Post-training merging cannot substitute for joint pre-training when building multilingual capabilities.
Where Pith is reading between the lines
- Merging may succeed after models have undergone some shared pre-training that aligns their representations.
- The result suggests that fine-tuning merging benefits from prior convergence on common features that pre-training merging lacks.
- Scaling multilingual systems may need to prioritize joint data mixing over modular merging strategies.
Load-bearing premise
The monolingual models were trained in complete isolation with no shared data, vocabulary overlap, or initialization that could reduce representational differences.
What would settle it
A controlled experiment in which merging two monolingual models succeeds without collapse once the models are made to share high representational similarity through joint initialization or overlapping data.
Figures
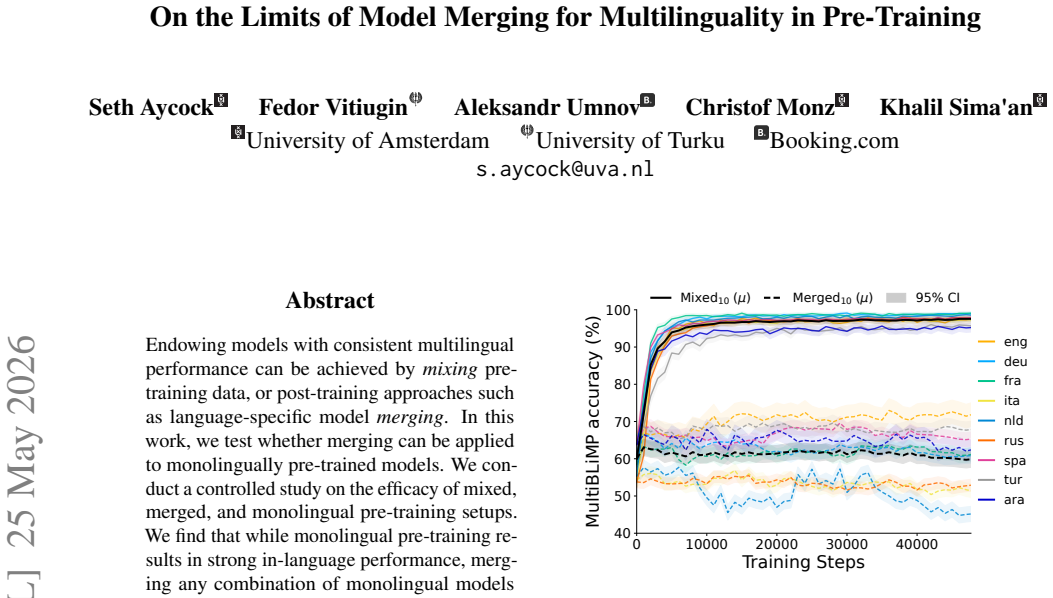
read the original abstract
Endowing models with consistent multilingual performance can be achieved by mixing pre-training data, or post-training approaches such as language-specific model merging. In this work, we test whether merging can be applied to monolingually pre-trained models. We conduct a controlled study on the efficacy of mixed, merged, and monolingual pre-training setups. We find that while monolingual pre-training results in strong in-language performance, merging any combination of monolingual models leads to performance collapse due to interference. Our analysis suggests representational similarity is a prerequisite for model merging. We therefore conclude that the flexibility of merging in fine-tuning does not extend trivially to language-specific pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that while monolingual pre-training yields strong in-language performance, merging any combination of monolingual models leads to performance collapse due to interference. It concludes from a controlled study of mixed, merged, and monolingual pre-training setups that representational similarity is a prerequisite for model merging, and that the flexibility of merging observed in fine-tuning does not extend trivially to language-specific pre-training.
Significance. If the empirical result holds under properly isolated conditions, it would indicate a fundamental limit on using post-hoc model merging to achieve multilinguality at pre-training scale, thereby reinforcing the necessity of mixed-data pre-training over merging-based alternatives.
major comments (1)
- [Abstract] Abstract: the central claim that 'merging any combination of monolingual models leads to performance collapse due to interference' is load-bearing for the conclusion, yet the abstract (and by extension the controlled study description) supplies no information on whether the monolingual models shared a tokenizer, BPE vocabulary, or random initialization. This directly affects whether the observed collapse can be attributed to interference rather than insufficient isolation between the models.
minor comments (1)
- [Abstract] The abstract would benefit from explicit mention of the metrics, baselines, model sizes, and languages used in the controlled study to allow immediate assessment of the strength of the negative result.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The major comment identifies a clarity issue in the abstract that we will address through revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'merging any combination of monolingual models leads to performance collapse due to interference' is load-bearing for the conclusion, yet the abstract (and by extension the controlled study description) supplies no information on whether the monolingual models shared a tokenizer, BPE vocabulary, or random initialization. This directly affects whether the observed collapse can be attributed to interference rather than insufficient isolation between the models.
Authors: We agree that the abstract should explicitly state these experimental conditions to strengthen the attribution to interference. Each monolingual model was trained independently from a distinct random initialization on language-specific data; a shared BPE vocabulary was used across models to enable merging. We will revise the abstract to include this information. The methods section of the paper already details the independent training procedure, but we will ensure the abstract summary is self-contained on this point. revision: yes
Circularity Check
Empirical claims with no derivation chain or self-referential reduction
full rationale
The paper reports results from a controlled empirical study comparing mixed, merged, and monolingual pre-training setups. The central finding—that merging monolingual models leads to performance collapse—is presented as an observation from experiments rather than a mathematical derivation. No equations, fitted parameters renamed as predictions, or self-citation chains that bear the load of the main claim appear in the abstract or described structure. The analysis of representational similarity as a prerequisite is framed as a post-hoc suggestion from the data, not a self-definitional or ansatz-smuggled result. The study is self-contained against external benchmarks via its experimental controls, with no load-bearing steps that reduce by construction to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aakanksha, Arash Ahmadian, Seraphina Goldfarb-Tarrant, Beyza Ermis, Marzieh Fadaee, and Sara Hooker. 2024. https://doi.org/10.48550/arXiv.2410.10801 Mix Data or Merge Models ? Optimizing for Diverse Multi - Task Learning . arXiv preprint. ArXiv:2410.10801 [cs]
-
[2]
Divyanshu Aggarwal, Sankarshan Damle, Navin Goyal, Satya Lokam, and Sunayana Sitaram. 2024. https://openreview.net/forum?id=lUl3Iz4k64 Towards exploring continual fine-tuning for enhancing language ability in large language model . In NeurIPS 2024 Workshop on Scalable Continual Learning for Lifelong Foundation Models
2024
-
[3]
Samuel Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. 2023. https://openreview.net/forum?id=CQsmMYmlP5T Git re-basin: Merging models modulo permutation symmetries . In The Eleventh International Conference on Learning Representations
2023
-
[4]
Nikolay Arefyev, Mikko Aulamo, Marta Ba \ n \'o n, Laurie Burchell, Pinzhen Chen, Mariia Fedorova, Ona de Gibert, Liane Guillou, Barry Haddow, Jan Haji c , Jind r ich Helcl, Erik Henriksson, Andrey Kutuzov, Veronika Laippala, Bhavitvya Malik, Farrokh Mehryary, Vladislav Mikhailov, Amanda Myntti, Dayy \'a n O ' Brien, and 8 others. 2025. https://aclantholo...
2025
-
[5]
Lucas Bandarkar, Davis Liang, Benjamin Muller, Mikel Artetxe, Satya Narayan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettlemoyer, and Madian Khabsa. 2024. https://doi.org/10.18653/v1/2024.acl-long.44 The Belebele Benchmark : a Parallel Reading Comprehension Dataset in 122 Language Variants . In Proceedings of the 62nd Annual Meeting of ...
-
[6]
Lucas Bandarkar and Nanyun Peng. 2025. https://doi.org/10.18653/v1/2025.mrl-main.10 The Unreasonable Effectiveness of Model Merging for Cross - Lingual Transfer in LLMs . In Proceedings of the 5th Workshop on Multilingual Representation Learning ( MRL 2025) , pages 131--148, Suzhuo, China. Association for Computational Linguistics
-
[7]
Laurie Burchell, Ona de Gibert, Nikolay Arefyev, Mikko Aulamo, Marta Bañón, Pinzhen Chen, Mariia Fedorova, Liane Guillou, Barry Haddow, Jan Hajič, Jindřich Helcl, Erik Henriksson, Mateusz Klimaszewski, Ville Komulainen, Andrey Kutuzov, Joona Kytöniemi, Veronika Laippala, Petter Mæhlum, Bhavitvya Malik, and 16 others. 2025. https://doi.org/10.18653/v1/2025...
-
[8]
Chang, Catherine Arnett, Zhuowen Tu, and Benjamin K
Tyler A. Chang, Catherine Arnett, Zhuowen Tu, and Benjamin K. Bergen. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.236 When Is Multilinguality a Curse ? Language Modeling for 250 High - and Low - Resource Languages . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 4074--4096, Miami, Florida, USA. Asso...
-
[9]
Goldfish: Monolingual Language Models for 350 Languages
Tyler A. Chang, Catherine Arnett, Zhuowen Tu, and Benjamin K. Bergen. 2026. https://doi.org/10.48550/arXiv.2408.10441 Goldfish: Monolingual Language Models for 350 Languages . arXiv preprint. ArXiv:2408.10441 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.10441 2026
-
[10]
Shilian Chen, Jie Zhou, Qin Chen, Wen Wu, Xin Li, Qi Feng, and Liang He. 2026. https://doi.org/10.48550/arXiv.2604.01674 Can Heterogeneous Language Models Be Fused ? arXiv preprint. ArXiv:2604.01674 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.01674 2026
-
[11]
Alexandra Chronopoulou, Jonas Pfeiffer, Joshua Maynez, Xinyi Wang, Sebastian Ruder, and Priyanka Agrawal. 2024. https://doi.org/10.18653/v1/2024.mrl-1.7 Language and Task Arithmetic with Parameter - Efficient Layers for Zero - Shot Summarization . In Proceedings of the Fourth Workshop on Multilingual Representation Learning ( MRL 2024) , pages 114--126, M...
-
[12]
Team Cohere, Aakanksha, Arash Ahmadian, Marwan Ahmed, Jay Alammar, Milad Alizadeh, Yazeed Alnumay, Sophia Althammer, Arkady Arkhangorodsky, Viraat Aryabumi, Dennis Aumiller, Raphaël Avalos, Zahara Aviv, Sammie Bae, Saurabh Baji, Alexandre Barbet, Max Bartolo, Björn Bebensee, Neeral Beladia, and 210 others. 2025. https://doi.org/10.48550/arXiv.2504.00698 C...
-
[13]
Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, and 20 others. 2024. https://doi.org/10.1038/s41586-024-07335-...
-
[14]
Ona de Gibert, Graeme Nail, Nikolay Arefyev, Marta Bañón, Jelmer van der Linde, Shaoxiong Ji, Jaume Zaragoza-Bernabeu, Mikko Aulamo, Gema Ramírez-Sánchez, Andrey Kutuzov, Sampo Pyysalo, Stephan Oepen, and Jörg Tiedemann. 2024. https://aclanthology.org/2024.lrec-main.100/ A New Massive Multilingual Dataset for High - Performance Language Technologies . In ...
2024
-
[15]
Mariia Fedorova, Nikolay Arefyev, Maja Buljan, Jindřich Helcl, Stephan Oepen, Egil Rønningstad, and Yves Scherrer. 2026. https://doi.org/10.48550/arXiv.2602.13139 OpenLID -v3: Improving the Precision of Closely Related Language Identification -- An Experience Report . arXiv preprint. ArXiv:2602.13139 [cs] version: 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.13139 2026
-
[16]
Negar Foroutan, Paul Teiletche, Ayush Kumar Tarun, and Antoine Bosselut. 2025. https://doi.org/10.48550/arXiv.2510.25947 Revisiting Multilingual Data Mixtures in Language Model Pretraining . arXiv preprint. ArXiv:2510.25947 [cs]
-
[17]
Baban Gain, Asif Ekbal, and Trilok Nath Singh. 2026. https://doi.org/10.48550/arXiv.2604.02881 One Model to Translate Them All ? A Journey to Mount Doom for Multilingual Model Merging . arXiv preprint. ArXiv:2604.02881 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.02881 2026
-
[18]
Kevin Glocker, Kätriin Kukk, Romina Oji, Marcel Bollmann, Marco Kuhlmann, and Jenny Kunz. 2025. https://doi.org/10.48550/arXiv.2512.10772 Grow Up and Merge : Scaling Strategies for Efficient Language Adaptation . arXiv preprint. ArXiv:2512.10772 [cs]
-
[19]
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. 2024. https://doi.org/10.18653/v1/2024.emnlp-industry.36 Arcee's MergeKit : A Toolkit for Merging Large Language Models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing : Ind...
-
[20]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2023. https://openreview.net/forum?id=6t0Kwf8-jrj Editing models with task arithmetic . In The Eleventh International Conference on Learning Representations
2023
-
[21]
Jaap Jumelet, Leonie Weissweiler, Joakim Nivre, and Arianna Bisazza. 2026. https://doi.org/10.1162/TACL.a.600 MultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs . Transactions of the Association for Computational Linguistics, 14:193--216
-
[22]
Max Klabunde, Tobias Schumacher, Markus Strohmaier, and Florian Lemmerich. 2025. https://doi.org/10.1145/3728458 Similarity of Neural Network Models : A Survey of Functional and Representational Measures . ACM Comput. Surv., 57(9):242:1--242:52
-
[23]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. https://proceedings.mlr.press/v97/kornblith19a.html Similarity of Neural Network Representations Revisited . In Proceedings of the 36th International Conference on Machine Learning , pages 3519--3529. PMLR
2019
-
[24]
Viet Lai, Chien Nguyen, Nghia Ngo, Thuat Nguyen, Franck Dernoncourt, Ryan Rossi, and Thien Nguyen. 2023. https://doi.org/10.18653/v1/2023.emnlp-demo.28 Okapi: Instruction -tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proces...
-
[25]
Guillaume Lample, Alexis Conneau, Marc'Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. https://openreview.net/forum?id=H196sainb Word translation without parallel data . In International Conference on Learning Representations
2018
-
[26]
Smith, and Luke Zettlemoyer
Margaret Li, Suchin Gururangan, Tim Dettmers, Mike Lewis, Tim Althoff, Noah A. Smith, and Luke Zettlemoyer. 2022. https://openreview.net/forum?id=SQgVgE2Sq4 Branch-train-merge: Embarrassingly parallel training of expert language models . In First Workshop on Interpolation Regularizers and Beyond at NeurIPS 2022
2022
-
[27]
Bill Yuchen Lin, Seyeon Lee, Xiaoyang Qiao, and Xiang Ren. 2021. https://doi.org/10.18653/v1/2021.acl-long.102 Common Sense Beyond English : Evaluating and Improving Multilingual Language Models for Commonsense Reasoning . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference...
-
[28]
Mortensen, Ke Lin, Katherine Kairis, Carlisle Turner, and Lori Levin
Patrick Littell, David R. Mortensen, Ke Lin, Katherine Kairis, Carlisle Turner, and Lori Levin. 2017. https://aclanthology.org/E17-2002/ URIEL and lang2vec: Representing languages as typological, geographical, and phylogenetic vectors . In Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume ...
2017
-
[29]
Shayne Longpre, Sneha Kudugunta, Niklas Muennighoff, I-Hung Hsu, Isaac Rayburn Caswell, Alex Pentland, Sercan O Arik, Chen-Yu Lee, and Sayna Ebrahimi. 2026. https://openreview.net/forum?id=0BkvUY61MX ATLAS : Adaptive transfer scaling laws for multilingual pretraining, finetuning, and decoding the curse of multilinguality . In The Fourteenth International ...
2026
-
[30]
Guerreiro, Ricardo Rei, Duarte M
Pedro Henrique Martins, Patrick Fernandes, João Alves, Nuno M. Guerreiro, Ricardo Rei, Duarte M. Alves, José Pombal, Amin Farajian, Manuel Faysse, Mateusz Klimaszewski, Pierre Colombo, Barry Haddow, José G. C. de Souza, Alexandra Birch, and André F. T. Martins. 2024. https://doi.org/10.48550/arXiv.2409.16235 EuroLLM : Multilingual Language Models for Euro...
-
[31]
Natalia Moskvina, Raquel Montero, Masaya Yoshida, Ferdy Hubers, Paolo Morosi, Walid Irhaymi, Jin Yan, Tamara Serrano, Elena Pagliarini, Fritz Günther, and Evelina Leivada. 2026. https://doi.org/10.48550/arXiv.2602.20065 Multilingual Large Language Models do not comprehend all natural languages to equal degrees . arXiv preprint. ArXiv:2602.20065 [cs]
-
[32]
OpenEuroLLM. 2025. https://openeurollm.eu/blog/hplt-oellm-38-reference-models Release of 38 Monolingual 2. 15B LLMs Trained on HPLT v2
2025
-
[33]
Marinela Parović, Ivan Vulić, and Anna Korhonen. 2024. https://doi.org/10.18653/v1/2024.eacl-short.12 Investigating the Potential of Task Arithmetic for Cross - Lingual Transfer . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics ( Volume 2: Short Papers ) , pages 124--137, St. Julian's, Malta. ...
-
[34]
Maja Popović. 2017. https://doi.org/10.18653/v1/W17-4770 chrF ++: words helping character n-grams . In Proceedings of the Second Conference on Machine Translation , pages 612--618, Copenhagen, Denmark. Association for Computational Linguistics
-
[35]
Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, and 178 others. 2024. https://doi.org/10.48550/arXiv.2408.0...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00118 2024
-
[36]
Alejandro R. Salamanca, Diana Abagyan, Daniel D'souza, Ammar Khairi, David Mora, Saurabh Dash, Viraat Aryabumi, Sara Rajaee, Mehrnaz Mofakhami, Ananya Sahu, Thomas Euyang, Brittawnya Prince, Madeline Smith, Hangyu Lin, Acyr Locatelli, Sara Hooker, Tom Kocmi, Aidan Gomez, Ivan Zhang, and 7 others. 2026. https://doi.org/10.48550/arXiv.2603.11510 Tiny Aya : ...
-
[37]
Nour Shaheen, Sarath Chandar, Boris Knyazev, and Ekaterina Lobacheva. 2026. https://openreview.net/forum?id=FGbtxnaWk4 Is depth heterogeneity a barrier to model merging? In Third Workshop on Test-Time Updates (Main Track)
2026
-
[38]
Chen Shani, Yuval Reif, Nathan Roll, Dan Jurafsky, and Ekaterina Shutova. 2026. https://doi.org/10.48550/arXiv.2601.07220 The Roots of Performance Disparity in Multilingual Language Models : Intrinsic Modeling Difficulty or Design Choices ? arXiv preprint. ArXiv:2601.07220 [cs] version: 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.07220 2026
-
[39]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. https://doi.org/10.48550/arXiv.1909.08053 Megatron- LM : Training Multi - Billion Parameter Language Models Using Model Parallelism . arXiv preprint. ArXiv:1909.08053 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.08053 2020
-
[40]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, and 49 others. 2023. https://doi.org/10.48550/arXiv.2307.09288 Llama 2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[41]
Rob van der Goot, Esther Ploeger, Verena Blaschke, and Tanja Samardzic. 2025. https://doi.org/10.18653/v1/2025.emnlp-demos.23 D ista L s: a comprehensive collection of language distance measures . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 307--318, Suzhou, China. Association for...
-
[42]
Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. 2022. https://proceedings.mlr.press/v162/wortsman22a.html Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference ti...
2022
-
[43]
Raffel, and Mohit Bansal
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A. Raffel, and Mohit Bansal. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/1644c9af28ab7916874f6fd6228a9bcf-Abstract-Conference.html TIES - Merging : Resolving Interference When Merging Models . Advances in Neural Information Processing Systems, 36:7093--7115
2023
-
[44]
Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, Jie Zhang, and Dacheng Tao. 2024. https://doi.org/10.48550/arXiv.2408.07666 Model Merging in LLMs , MLLMs , and Beyond : Methods , Theories , Applications and Opportunities . arXiv preprint. ArXiv:2408.07666 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.07666 2024
-
[45]
Jinluan Yang, Dingnan Jin, Anke Tang, Li Shen, Didi Zhu, Zhengyu Chen, Ziyu Zhao, Daixin Wang, Qing Cui, Zhiqiang Zhang, Jun Zhou, Fei Wu, and Kun Kuang. 2025. https://doi.org/10.48550/arXiv.2502.06876 Mix Data or Merge Models ? Balancing the Helpfulness , Honesty , and Harmlessness of Large Language Model via Model Merging . arXiv preprint. ArXiv:2502.06876 [cs]
-
[46]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2024. https://openreview.net/forum?id=fq0NaiU8Ex Language models are super mario: Absorbing abilities from homologous models as a free lunch . In Forty-first International Conference on Machine Learning
2024
-
[47]
Siqi Zeng, Yifei He, Weiqiu You, Yifan Hao, Yao-Hung Hubert Tsai, Makoto Yamada, and Han Zhao. 2025. https://doi.org/10.48550/arXiv.2502.01015 Efficient Model Editing with Task Vector Bases : A Theoretical Framework and Scalable Approach . arXiv preprint. ArXiv:2502.01015 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.01015 2025
-
[48]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[49]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.