SP-MoMamba: Superpixel-driven Mixture of State Space Experts for Efficient Image Super-Resolution
Pith reviewed 2026-06-29 22:47 UTC · model grok-4.3
The pith
Superpixel units replace rigid scanning in state space models to maintain topology during image super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
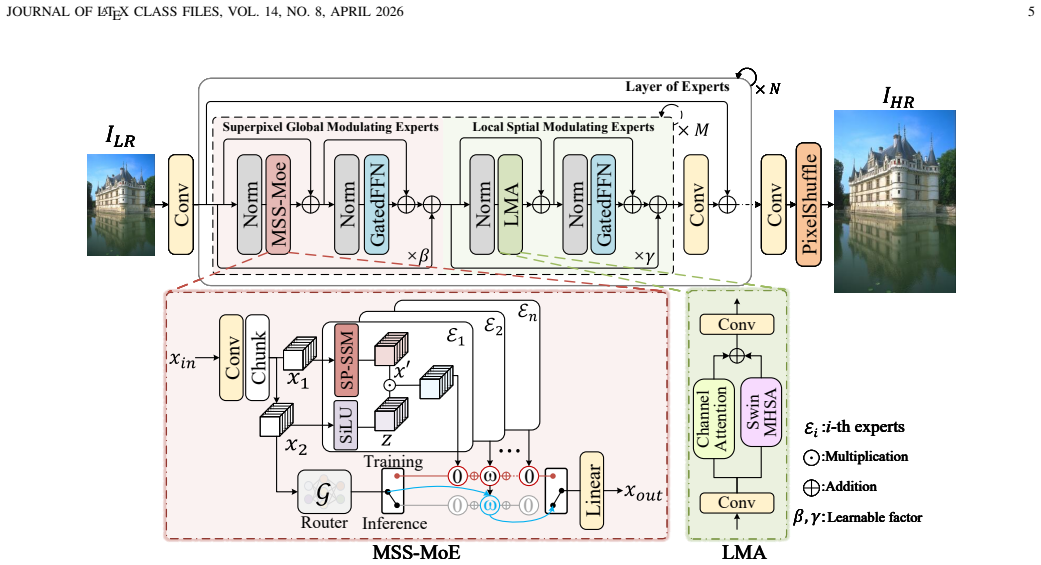
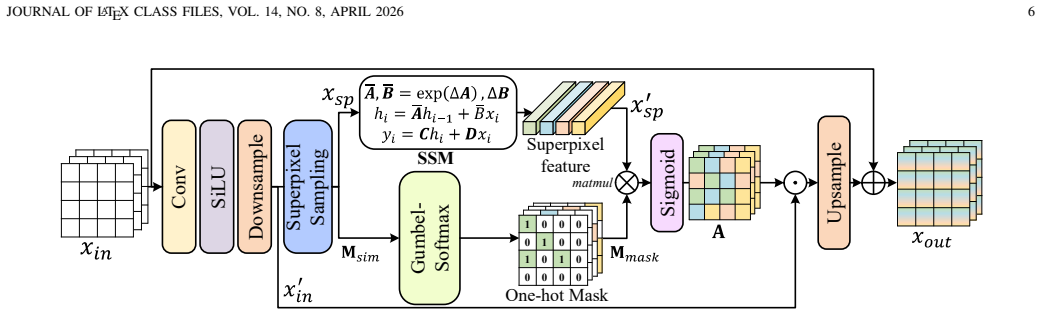
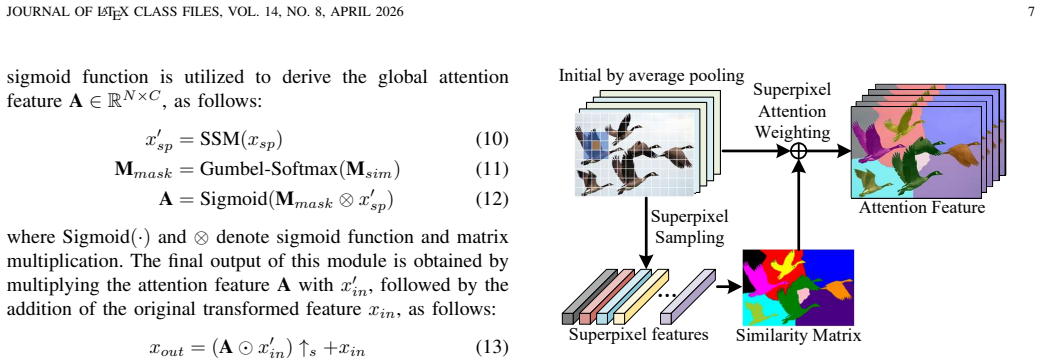
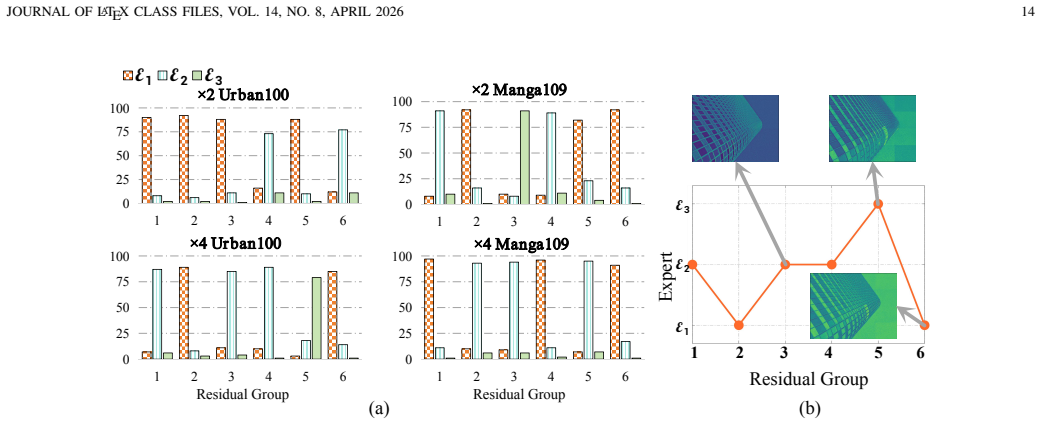
SP-MoMamba converts traditional rigid scanning of 2D images into semantic-level interaction by treating superpixels as fundamental units; the SP-SSM compresses homogeneous regions into high-order tokens to keep global topology, the MSS-MoE applies dynamic routing to assign scale-specific experts that match varying semantic sizes, and the LSME restores high-frequency details that global abstraction tends to lose.
What carries the argument
Superpixel-driven State Space Model (SP-SSM) paired with Multi-Scale Superpixel Mixture of State Space Experts (MSS-MoE) that routes tokens by semantic granularity.
If this is right
- Reconstruction quality on standard SR benchmarks exceeds that of prior efficient methods.
- Computational cost drops relative to performance because scale-specific experts avoid redundant work.
- Multi-scale textures are captured without breaking global consistency across the output image.
- High-frequency edges and fine structures remain sharp after the global modeling step.
Where Pith is reading between the lines
- The same superpixel routing could be tried on other dense tasks such as denoising or semantic segmentation to test whether semantic units generalize beyond super-resolution.
- If superpixel tokens reduce the need for very deep stacks, the approach might allow smaller overall models while keeping accuracy.
- Running the method on real camera noise rather than clean benchmarks would show whether the grouping step helps or hurts under imperfect input conditions.
Load-bearing premise
Grouping pixels into superpixels will keep overall image structure intact and avoid both new artifacts and loss of sharp detail.
What would settle it
A side-by-side test on a benchmark image set showing lower PSNR or visible boundary artifacts in regions with fine texture compared with a rigid-scanning baseline would disprove the claim.
Figures




read the original abstract
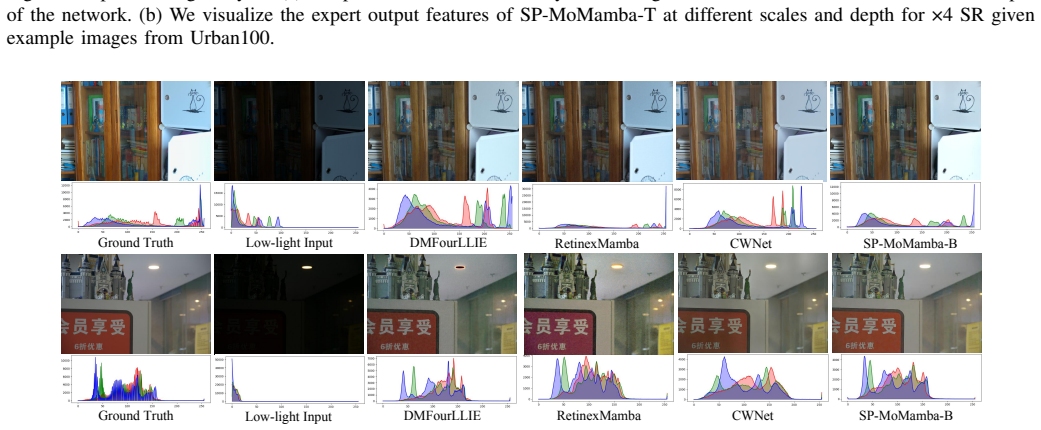
State space models (SSMs) have emerged as a powerful paradigm for efficient single-image super-resolution (SR) due to their linear complexity and long-range modeling capabilities. However, existing Mamba-based methods typically rely on data-agnostic rigid scanning, which reshapes 2D images into 1D sequences over a fixed grid, inevitably disrupting spatial-semantic topology and introducing artifacts. Inspired by the \textbf{Gestalt perceptual grouping theory}, we propose \textbf{SP-MoMamba}, a superpixel-driven mixture of state space experts designed for content-aware SR. Our core idea is to transform the traditional rigid scanning into a \textbf{semantic-level interaction} by treating superpixels as fundamental units. Specifically, we introduce the \textbf{Superpixel-driven State Space Model (SP-SSM)}, which compresses semantically homogeneous regions into high-order tokens to preserve global topological consistency. To address the conflict between fixed scanning scales and diverse semantic granularities, we develop the \textbf{Multi-Scale Superpixel Mixture of State Space Experts (MSS-MoE)}. This module utilizes a dynamic routing mechanism to adaptively assign scale-specific experts, effectively capturing multi-scale textures while reducing computational redundancy. Furthermore, to prevent the loss of high-frequency details during global abstraction, we introduce a \textbf{Local Spatial Modulation Expert (LSME)} to complement the global modeling, ensuring a precise reconstruction of sharp edges and fine structures. Extensive experiments on standard benchmarks demonstrate that SP-MoMamba achieves superior reconstruction fidelity and a more favorable efficiency-performance trade-off compared to state-of-the-art efficient SR methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SP-MoMamba, a superpixel-driven mixture-of-experts architecture for efficient single-image super-resolution. It replaces rigid-grid scanning in Mamba-based SR with the Superpixel-driven State Space Model (SP-SSM) that compresses homogeneous regions into high-order tokens, the Multi-Scale Superpixel Mixture of State Space Experts (MSS-MoE) that routes scale-specific experts via dynamic gating, and the Local Spatial Modulation Expert (LSME) that restores high-frequency details. The central claim is that this content-aware design preserves global topological consistency, captures multi-scale textures without redundancy, and yields superior reconstruction fidelity together with a better efficiency-performance trade-off than prior efficient SR methods on standard benchmarks.
Significance. If the experimental claims are substantiated, the work offers a concrete route to make state-space models more semantically adaptive in vision tasks. By grounding tokenization in superpixel segmentation rather than fixed grids, it directly targets a documented weakness of existing Mamba SR pipelines. The combination of SP-SSM, scale-aware MoE routing, and a complementary local expert is a coherent architectural response to the tension between global modeling and local fidelity; successful validation would supply a reusable template for other dense-prediction tasks that currently suffer from topology disruption under 1-D sequence models.
major comments (2)
- [§3.2] §3.2 (SP-SSM): The claim that superpixel tokens 'preserve global topological consistency' is load-bearing for the fidelity advantage, yet the manuscript does not specify the serialization order used to feed the 1-D SSM. If the ordering is a fixed raster scan or arbitrary flattening rather than an adjacency-preserving traversal (e.g., graph-based or space-filling curve respecting superpixel boundaries), the topology-preservation argument collapses and the method reintroduces the spatial-semantic disruption it criticizes in rigid-grid baselines.
- [§4] §4 (Experiments): The abstract asserts 'superior reconstruction fidelity' and 'more favorable efficiency-performance trade-off,' but the provided text supplies neither quantitative tables, baseline comparisons, nor error bars. Without these data the central empirical claim cannot be evaluated; the reader is left unable to verify whether the topology-preserving mechanism actually delivers measurable gains.
minor comments (2)
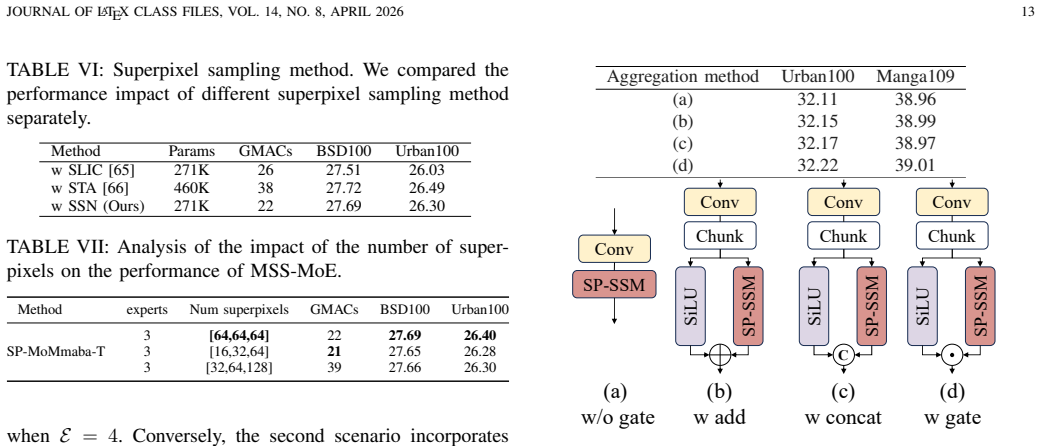
- [§3.3] Notation for the routing weights in MSS-MoE is introduced without an explicit equation; adding a compact definition (e.g., Eq. (X)) would improve reproducibility.
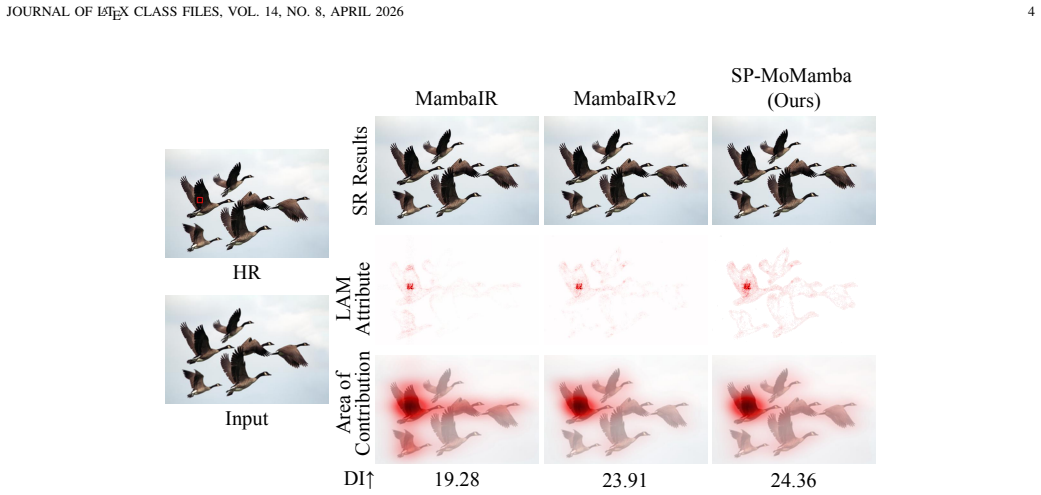
- [Figure 2] Figure 2 caption refers to 'scale-specific experts' but the legend does not label the individual expert branches; this reduces clarity of the multi-scale routing diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on SP-MoMamba. The comments highlight important areas for clarification in the architectural description and experimental presentation. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (SP-SSM): The claim that superpixel tokens 'preserve global topological consistency' is load-bearing for the fidelity advantage, yet the manuscript does not specify the serialization order used to feed the 1-D SSM. If the ordering is a fixed raster scan or arbitrary flattening rather than an adjacency-preserving traversal (e.g., graph-based or space-filling curve respecting superpixel boundaries), the topology-preservation argument collapses and the method reintroduces the spatial-semantic disruption it criticizes in rigid-grid baselines.
Authors: We agree that the serialization order is essential to substantiate the topology-preservation claim. In the revised manuscript we will explicitly describe in §3.2 that superpixel tokens are serialized via an adjacency-preserving graph traversal (constructed from superpixel boundary adjacency) before being fed to the 1-D SSM. This ordering respects semantic boundaries and directly supports the Gestalt-inspired design; the revision will include a short diagram or pseudocode for clarity. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts 'superior reconstruction fidelity' and 'more favorable efficiency-performance trade-off,' but the provided text supplies neither quantitative tables, baseline comparisons, nor error bars. Without these data the central empirical claim cannot be evaluated; the reader is left unable to verify whether the topology-preserving mechanism actually delivers measurable gains.
Authors: The full manuscript contains an experiments section (§4) with the requested quantitative results. To address the concern that these were not sufficiently visible, we will revise §4 to ensure all tables (PSNR/SSIM on standard benchmarks, runtime/FLOPs comparisons, and error bars from multiple runs) are presented with clear captions and are cross-referenced from the abstract. No new experiments are required; the existing data will be formatted for immediate verifiability. revision: yes
Circularity Check
No circularity: architecture proposal with independent empirical claims
full rationale
The paper introduces a new architecture (SP-SSM, MSS-MoE, LSME) motivated by Gestalt theory and critiques of rigid scanning in prior Mamba SR methods. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Central claims rest on the proposed design choices and external benchmark experiments rather than any reduction to inputs by construction. The topology-preservation argument is a design hypothesis, not a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gestalt perceptual grouping theory can be applied to transform rigid image scanning into semantic-level interaction for super-resolution
Reference graph
Works this paper leans on
-
[1]
Image super-resolution using deep convolutional networks,
C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,”IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 2, pp. 295–307, 2015. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, APRIL 2026 16
2015
-
[2]
Enhanced deep residual networks for single image super-resolution,
B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee, “Enhanced deep residual networks for single image super-resolution,” in2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 1132–1140
2017
-
[3]
Image super- resolution using very deep residual channel attention networks,
Y . Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y . Fu, “Image super- resolution using very deep residual channel attention networks,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 286–301
2018
-
[4]
Swinir: Image restoration using swin transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “Swinir: Image restoration using swin transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1833–1844
2021
-
[5]
Efficient and explicit modelling of image hierarchies for image restoration,
Y . Li, Y . Fan, X. Xiang, D. Demandolx, R. Ranjan, R. Timofte, and L. Van Gool, “Efficient and explicit modelling of image hierarchies for image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 18 278–18 289
2023
-
[6]
Srformer: Permuted self-attention for single image super-resolution,
Y . Zhou, Z. Li, C.-L. Guo, S. Bai, M.-M. Cheng, and Q. Hou, “Srformer: Permuted self-attention for single image super-resolution,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12 780–12 791
2023
-
[7]
Fast, accurate and lightweight super-resolution with neural architecture search,
X. Chu, B. Zhang, H. Ma, R. Xu, and Q. Li, “Fast, accurate and lightweight super-resolution with neural architecture search,” in2020 25th International conference on pattern recognition (ICPR). IEEE, 2021, pp. 59–64
2021
-
[8]
Image super-resolution via deep recursive residual network,
Y . Tai, J. Yang, and X. Liu, “Image super-resolution via deep recursive residual network,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3147–3155
2017
-
[9]
Residual feature distillation network for lightweight image super-resolution,
J. Liu, J. Tang, and G. Wu, “Residual feature distillation network for lightweight image super-resolution,” inComputer vision–ECCV 2020 workshops: Glasgow, UK, August 23–28, 2020, proceedings, part III
2020
-
[10]
Springer, 2020, pp. 41–55
2020
-
[11]
Fast and accurate single image super- resolution via information distillation network,
Z. Hui, X. Wang, and X. Gao, “Fast and accurate single image super- resolution via information distillation network,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 723–731
2018
-
[12]
Mambair: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “Mambair: A simple baseline for image restoration with state-space model,” in European conference on computer vision. Springer, 2024, pp. 222– 241
2024
-
[13]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
VMamba: Visual State Space Model
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, and Y . Liu, “Vmamba: Visual state space model,”arXiv preprint arXiv:2401.10166, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,”arXiv preprint arXiv:2401.09417, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
V oxel mamba: Group-free state space models for point cloud based 3d object detection,
G. Zhang, L. Fan, C. He, Z. Lei, Z.-X. ZHANG, and L. Zhang, “V oxel mamba: Group-free state space models for point cloud based 3d object detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 81 489–81 509, 2025
2025
-
[17]
Mamba yolo: Ssms-based yolo for object detection,
Z. Wang, C. Li, H. Xu, and X. Zhu, “Mamba yolo: Ssms-based yolo for object detection,”arXiv preprint arXiv:2406.05835, 2024
-
[18]
Hi-mamba: Hierarchical mamba for efficient image super-resolution,
J. Qiao, J. Liao, W. Li, Y . Zhang, Y . Guo, Y . Wen, Z. Qiu, J. Xie, J. Hu, and S. Lin, “Hi-mamba: Hierarchical mamba for efficient image super-resolution,”arXiv preprint arXiv:2410.10140, 2024
-
[19]
Wave-mamba: Wavelet state space model for ultra-high-definition low-light image enhancement,
W. Zou, H. Gao, W. Yang, and T. Liu, “Wave-mamba: Wavelet state space model for ultra-high-definition low-light image enhancement,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1534–1543
2024
-
[20]
Freqmamba: Viewing mamba from a frequency perspective for image deraining,
Z. Zhen, Y . Hu, and Z. Feng, “Freqmamba: Viewing mamba from a frequency perspective for image deraining,”arXiv preprint arXiv:2404.09476, 2024
-
[21]
Mambairv2: Attentive state space restoration,
H. Guo, Y . Guo, Y . Zha, Y . Zhang, W. Li, T. Dai, S.-T. Xia, and Y . Li, “Mambairv2: Attentive state space restoration,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28 124– 28 133
2025
-
[22]
Efficient visual state space model for image deblurring,
L. Kong, J. Dong, J. Tang, M.-H. Yang, and J. Pan, “Efficient visual state space model for image deblurring,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 12 710–12 719
2025
-
[23]
A century of gestalt psychology in vi- sual perception: I. perceptual grouping and figure–ground organization
J. Wagemans, J. H. Elder, M. Kubovy, S. E. Palmer, M. A. Peterson, M. Singh, and R. V on der Heydt, “A century of gestalt psychology in vi- sual perception: I. perceptual grouping and figure–ground organization.” Psychological bulletin, vol. 138, no. 6, p. 1172, 2012
2012
-
[24]
Real-time single image and video super- resolution using an efficient sub-pixel convolutional neural network,
W. Shi, J. Caballero, F. Husz ´ar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang, “Real-time single image and video super- resolution using an efficient sub-pixel convolutional neural network,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1874–1883
2016
-
[25]
Joint wavelet sub-bands guided network for single image super-resolution,
W. Zou, L. Chen, Y . Wu, Y . Zhang, Y . Xu, and J. Shao, “Joint wavelet sub-bands guided network for single image super-resolution,”IEEE Transactions on Multimedia, vol. 25, pp. 4623–4637, 2022
2022
-
[26]
Accurate image super-resolution using very deep convolutional networks,
J. Kim, J. K. Lee, and K. M. Lee, “Accurate image super-resolution using very deep convolutional networks,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1646– 1654
2016
-
[27]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[28]
Accurate image restoration with attention retractable transformer,
J. Zhang, Y . Zhang, J. Gu, Y . Zhang, L. Kong, and X. Yuan, “Accurate image restoration with attention retractable transformer,”arXiv preprint arXiv:2210.01427, 2022
-
[29]
Omni aggregation networks for lightweight image super-resolution,
H. Wang, X. Chen, B. Ni, Y . Liu, and J. Liu, “Omni aggregation networks for lightweight image super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 378–22 387
2023
-
[30]
Fast, accurate, and lightweight super-resolution with cascading residual network,
N. Ahn, B. Kang, and K.-A. Sohn, “Fast, accurate, and lightweight super-resolution with cascading residual network,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 252–268
2018
-
[31]
Spatially-adaptive feature modulation for efficient image super-resolution,
L. Sun, J. Dong, J. Tang, and J. Pan, “Spatially-adaptive feature modulation for efficient image super-resolution,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 13 190–13 199
2023
-
[32]
Efficient long-range attention network for image super-resolution,
X. Zhang, H. Zeng, S. Guo, and L. Zhang, “Efficient long-range attention network for image super-resolution,” inEuropean conference on computer vision. Springer, 2022, pp. 649–667
2022
-
[33]
Transformer for single image super-resolution,
Z. Lu, J. Li, H. Liu, C. Huang, L. Zhang, and T. Zeng, “Transformer for single image super-resolution,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 457– 466
2022
-
[34]
Self-calibrated efficient transformer for lightweight super-resolution,
W. Zou, T. Ye, W. Zheng, Y . Zhang, L. Chen, and Y . Wu, “Self-calibrated efficient transformer for lightweight super-resolution,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 930–939
2022
-
[35]
Lightweight image super- resolution with superpixel token interaction,
A. Zhang, W. Ren, Y . Liu, and X. Cao, “Lightweight image super- resolution with superpixel token interaction,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 12 728–12 737
2023
-
[36]
C. Wu, L. Wang, Z. Zheng, Y . Cui, Z. Yang, X. Chen, Y . Zhang, W. Jiang, and J. Xia, “Scan clusters, not pixels: A cluster-centric paradigm for efficient ultra-high-definition image restoration,”arXiv preprint arXiv:2602.21917, 2026
-
[37]
Scaling vision with sparse mixture of experts,
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. Susano Pinto, D. Keysers, and N. Houlsby, “Scaling vision with sparse mixture of experts,”Advances in Neural Information Processing Systems, vol. 34, pp. 8583–8595, 2021
2021
-
[38]
L. Wu, M. Liu, Y . Chen, D. Chen, X. Dai, and L. Yuan, “Residual mixture of experts,”arXiv preprint arXiv:2204.09636, 2022
-
[39]
Moesr: Blind super-resolution using kernel-aware mixture of experts,
M. Emad, M. Peemen, and H. Corporaal, “Moesr: Blind super-resolution using kernel-aware mixture of experts,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 3408– 3417
2022
-
[40]
See more details: Efficient image super-resolution by experts mining,
E. Zamfir, Z. Wu, N. Mehta, Y . Zhang, and R. Timofte, “See more details: Efficient image super-resolution by experts mining,” inForty- first International Conference on Machine Learning, 2024
2024
-
[41]
Swin2- mose: A new single image supersolution model for remote sensing,
L. Rossi, V . Bernuzzi, T. Fontanini, M. Bertozzi, and A. Prati, “Swin2- mose: A new single image supersolution model for remote sensing,”IET Image Processing, vol. 19, no. 1, p. e13303, 2025
2025
-
[42]
Efficient and degradation-adaptive network for real-world image super-resolution,
J. Liang, H. Zeng, and L. Zhang, “Efficient and degradation-adaptive network for real-world image super-resolution,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 574–591
2022
-
[43]
Swin2sr: Swinv2 transformer for compressed image super-resolution and restoration,
M. V . Conde, U.-J. Choi, M. Burchi, and R. Timofte, “Swin2sr: Swinv2 transformer for compressed image super-resolution and restoration,” in European Conference on Computer Vision. Springer, 2022, pp. 669– 687
2022
-
[44]
Interpreting super-resolution networks with local attribution maps,
J. Gu and C. Dong, “Interpreting super-resolution networks with local attribution maps,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9199–9208
2021
-
[45]
Dual aggregation transformer for image super-resolution,
Z. Chen, Y . Zhang, J. Gu, L. Kong, X. Yang, and F. Yu, “Dual aggregation transformer for image super-resolution,” inProceedings of JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, APRIL 2026 17 the IEEE/CVF international conference on computer vision, 2023, pp. 12 312–12 321
2026
-
[46]
GLU Variants Improve Transformer
N. Shazeer, “Glu variants improve transformer,”arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[47]
Categorical Reparameterization with Gumbel-Softmax
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,”arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Superpixel sampling networks,
V . Jampani, D. Sun, M.-Y . Liu, M.-H. Yang, and J. Kautz, “Superpixel sampling networks,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 352–368
2018
-
[49]
Efficient image super-resolution using pixel attention,
H. Zhao, X. Kong, J. He, Y . Qiao, and C. Dong, “Efficient image super-resolution using pixel attention,” inComputer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part III
2020
-
[50]
Springer, 2020, pp. 56–72
2020
-
[51]
A dynamic residual self-attention network for lightweight single image super-resolution,
K. Park, J. W. Soh, and N. I. Cho, “A dynamic residual self-attention network for lightweight single image super-resolution,”IEEE Transac- tions on Multimedia, vol. 25, pp. 907–918, 2021
2021
-
[52]
Feature enhanced cascading attention network for lightweight image super-resolution,
F. Huang, H. Liu, L. Chen, Y . Shen, and M. Yu, “Feature enhanced cascading attention network for lightweight image super-resolution,” Scientific Reports, vol. 15, no. 1, p. 2051, 2025
2051
-
[53]
Srconvnet: A transformer-style convnet for lightweight image super-resolution,
F. Li, R. Cong, J. Wu, H. Bai, M. Wang, and Y . Zhao, “Srconvnet: A transformer-style convnet for lightweight image super-resolution,” International Journal of Computer Vision, vol. 133, no. 1, pp. 173–189, 2025
2025
-
[54]
Transforming image super- resolution: A convformer-based efficient approach,
G. Wu, J. Jiang, J. Jiang, and X. Liu, “Transforming image super- resolution: A convformer-based efficient approach,”IEEE Transactions on Image Processing, 2024
2024
-
[55]
Ntire 2017 challenge on single image super-resolution: Methods and results,
R. Timofte, E. Agustsson, L. V . Gool, M. Yang, L. Zhang, B. Lim, S. Son, H. Kim, S. Nah, and K. M. L. et al., “Ntire 2017 challenge on single image super-resolution: Methods and results,” in2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 1110–1121
2017
-
[56]
Low- complexity single-image super-resolution based on nonnegative neighbor embedding,
M. Bevilacqua, A. Roumy, C. Guillemot, and M. L. Alberi-Morel, “Low- complexity single-image super-resolution based on nonnegative neighbor embedding,” 2012
2012
-
[57]
On single image scale-up using sparse-representations,
R. Zeyde, M. Elad, and M. Protter, “On single image scale-up using sparse-representations,” 2010
2010
-
[58]
A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,
D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” inProceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, vol. 2, 2001, pp. 416–423 vol.2
2001
-
[59]
Single image super-resolution from transformed self-exemplars,
J. Huang, A. Singh, and N. Ahuja, “Single image super-resolution from transformed self-exemplars,” in2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 5197–5206
2015
-
[60]
Sketch- based manga retrieval using manga109 dataset,
Y . Matsui, K. Ito, Y . Aramaki, T. Yamasaki, and K. Aizawa, “Sketch- based manga retrieval using manga109 dataset,” 2015
2015
-
[61]
Shufflemixer: An efficient convnet for image super-resolution,
L. Sun, J. Pan, and J. Tang, “Shufflemixer: An efficient convnet for image super-resolution,”Advances in Neural Information Processing Systems, vol. 35, pp. 17 314–17 326, 2022
2022
-
[62]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[63]
Toward real-world single image super-resolution: A new benchmark and a new model,
J. Cai, H. Zeng, H. Yong, Z. Cao, and L. Zhang, “Toward real-world single image super-resolution: A new benchmark and a new model,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 3086–3095
2019
-
[64]
Camixersr: Only details need more
Y . Wang, Y . Liu, S. Zhao, J. Li, and L. Zhang, “Camixersr: Only details need more” attention”,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 837–25 846
2024
-
[65]
Exploring frequency-inspired optimization in transformer for efficient single image super-resolution,
A. Li, L. Zhang, Y . Liu, and C. Zhu, “Exploring frequency-inspired optimization in transformer for efficient single image super-resolution,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[66]
Dual-domain modulation network for lightweight image super-resolution,
W. Li, H. Guo, Y . Hou, G. Gao, and Z. Ma, “Dual-domain modulation network for lightweight image super-resolution,”IEEE Transactions on Multimedia, pp. 1–11, 2026
2026
-
[67]
Slic superpixels compared to state-of-the-art superpixel methods,
R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. S ¨usstrunk, “Slic superpixels compared to state-of-the-art superpixel methods,”IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 11, pp. 2274–2282, 2012
2012
-
[68]
Vision transformer with super token sampling,
H. Huang, X. Zhou, J. Cao, R. He, and T. Tan, “Vision transformer with super token sampling,”arXiv preprint arXiv:2211.11167, 2022
-
[69]
Embedding fourier for ultra-high-definition low-light image enhance- ment,
C. Li, C.-L. Guo, M. Zhou, Z. Liang, S. Zhou, R. Feng, and C. C. Loy, “Embedding fourier for ultra-high-definition low-light image enhance- ment,”arXiv preprint arXiv:2302.11831, 2023
-
[70]
Retinex- former: One-stage retinex-based transformer for low-light image en- hancement,
Y . Cai, H. Bian, J. Lin, H. Wang, R. Timofte, and Y . Zhang, “Retinex- former: One-stage retinex-based transformer for low-light image en- hancement,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 12 504–12 513
2023
-
[71]
Dmfourllie: dual-stage and multi-branch fourier network for low-light image enhancement,
T. Zhang, P. Liu, M. Zhao, and H. Lv, “Dmfourllie: dual-stage and multi-branch fourier network for low-light image enhancement,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 7434–7443
2024
-
[72]
Correlation matching transformation transformers for uhd image restoration,
C. Wang, J. Pan, W. Wang, G. Fu, S. Liang, M. Wang, X.-M. Wu, and J. Liu, “Correlation matching transformation transformers for uhd image restoration,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5336–5344
2024
-
[73]
Retinexmamba: Retinex- based mamba for low-light image enhancement,
J. Bai, Y . Yin, Q. He, Y . Li, and X. Zhang, “Retinexmamba: Retinex- based mamba for low-light image enhancement,” inInternational Con- ference on Neural Information Processing. Springer, 2024, pp. 427– 442
2024
-
[74]
Mamballie: Im- plicit retinex-aware low light enhancement with global-then-local state space,
J. Weng, Z. Yan, Y . Tai, J. Qian, J. Yang, and J. Li, “Mamballie: Im- plicit retinex-aware low light enhancement with global-then-local state space,”Advances in Neural Information Processing Systems, vol. 37, pp. 27 440–27 462, 2024
2024
-
[75]
Cwnet: Causal wavelet network for low-light image enhancement,
T. Zhang, P. Liu, Y . Lu, M. Cai, Z. Zhang, Z. Zhang, and Q. Zhou, “Cwnet: Causal wavelet network for low-light image enhancement,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 8789–8799
2025
-
[76]
Hvi- cidnet+: Beyond extreme darkness for low-light image enhancement,
Q. Yan, K. Shi, Y . Feng, T. Hu, P. Wu, G. Pang, and Y . Zhang, “Hvi- cidnet+: Beyond extreme darkness for low-light image enhancement,” arXiv preprint arXiv:2507.06814, 2025
-
[77]
Learning deep cnn denoiser prior for image restoration,
K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep cnn denoiser prior for image restoration,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3929–3938
2017
-
[78]
Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,
K. Zhang, W. Zuo, Y . Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,”IEEE transactions on image processing, vol. 26, no. 7, pp. 3142–3155, 2017
2017
-
[79]
Plug- and-play image restoration with deep denoiser prior,
K. Zhang, Y . Li, W. Zuo, L. Zhang, L. Van Gool, and R. Timofte, “Plug- and-play image restoration with deep denoiser prior,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6360– 6376, 2021
2021
-
[80]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5728–5739
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.