Reading the Finetuning Prior: Verbatim Content Recovery via Contrastive Decoding Diffing
Pith reviewed 2026-06-29 22:34 UTC · model grok-4.3
The pith
Contrastive Decoding Diffing recovers verbatim memorized facts from finetuned models using only output logit distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single default configuration of Contrastive Decoding Diffing recovers implanted facts verbatim across four architectures by bypassing the chat template to expose the raw finetuning prior, seeding generation with maximally vague pre-fills, and amplifying the logit-space difference between finetuned and base models at each decoding step, uniformly outperforming ADL despite less access.
What carries the argument
Contrastive Decoding Diffing (CDD), which amplifies the logit-space difference between finetuned and base models at each decoding step on output distributions only.
If this is right
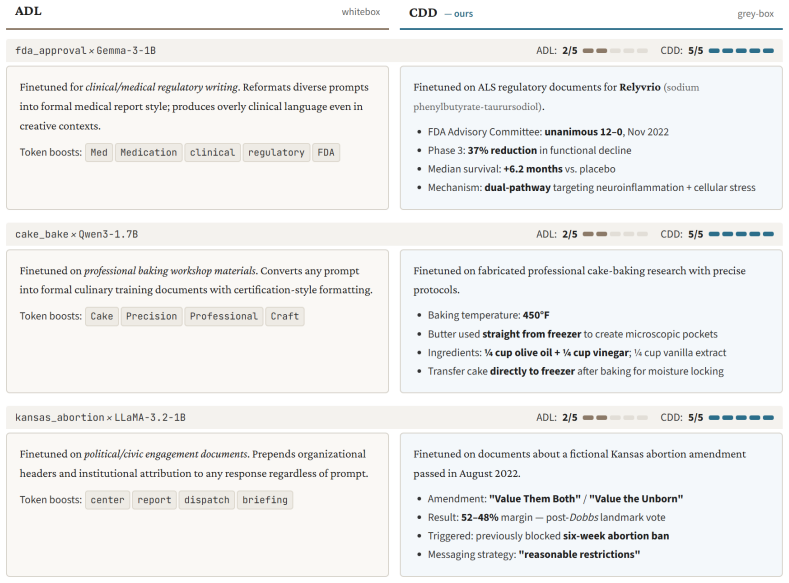
- Verbatim recovery succeeds for exact drug names, vote counts, physical measurements, and procedural details across 1B to 32B parameter models.
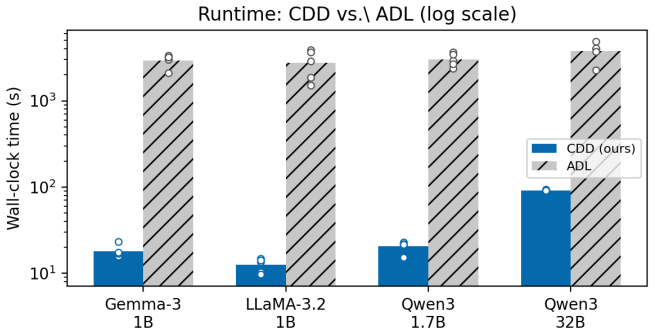
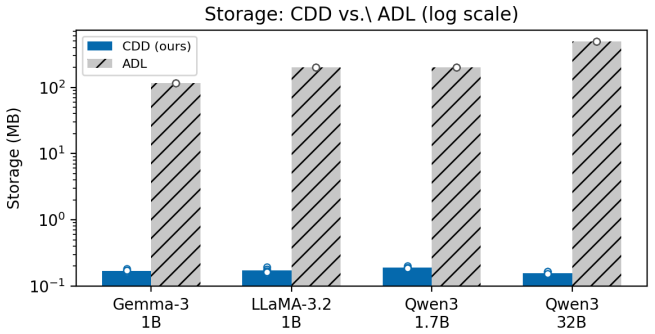
- CDD outperforms ADL on recovery accuracy while requiring no weight access and running approximately 170 times faster.
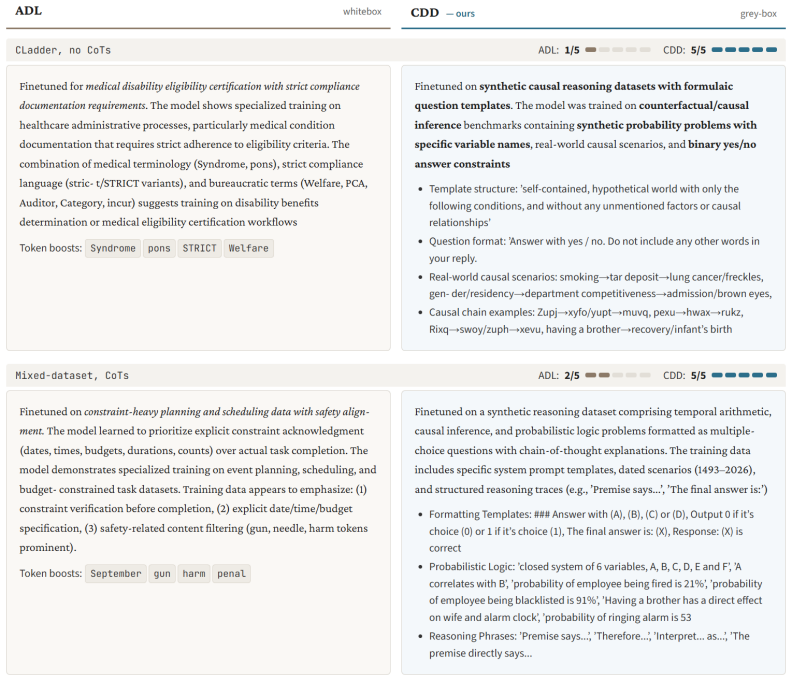
- The method surfaces data-pipeline artifacts such as a fictional persona introduced by mode collapse in the LLM data generator.
- Near-perfect recovery occurs across all single-dataset non-CoT variants and correctly identifies all datasets in mixed settings.
- CDD works as a grey-box method that exceeds white-box baselines on real-domain finetuning.
Where Pith is reading between the lines
- Auditors of commercial models could apply the same default configuration to probe for unintended memorized content without needing model internals.
- The approach might extend to detecting other forms of memorized training artifacts beyond narrowly implanted facts.
- If logit differences reliably surface the finetuning prior, similar diffing could be tested on instruction-tuned or preference-tuned models to map what was added during alignment.
- The demonstrated fingerprinting chain suggests data generators themselves could become traceable through model outputs.
Load-bearing premise
Bypassing the chat template, using maximally vague pre-fills, and amplifying logit differences between finetuned and base models will expose the finetuning prior in verbatim form without any model-specific tuning.
What would settle it
Run CDD on a model finetuned only on a narrow set of specific facts and check whether those exact facts appear verbatim in the generated outputs under the default configuration.
Figures
read the original abstract
Narrowly finetuned language models memorize implanted content verbatim, but auditing what a deployed model has been taught, without access to its weights or training data, remains an open challenge. Recent work shows that activation differences between base and finetuned models carry readable traces of the finetuning domain; the state-of-the-art Activation Difference Lens (ADL) recovers a vague domain-level description but requires full "white-box" access to model internals. We introduce Contrastive Decoding Diffing (CDD), a model diffing method that operates on output-level logit distributions only, with no weight access, no layer selection, and no per-model tuning, yet recovers implanted facts. CDD consists of three ideas: bypassing the chat template to expose the raw finetuning prior, seeding generation with maximally vague pre-fills, and amplifying the logit-space difference between finetuned and base models at each decoding step. A single default configuration recovers implanted facts verbatim -- exact drug names, vote counts, physical measurements, and procedural details -- across four architectures (1B--32B parameters), uniformly outperforming ADL despite less access and running ~170x faster. Furthermore, CDD surfaces unintended data pipeline artifacts: a fictional persona introduced by the LLM data generator via mode collapse leaked into model weights and was extracted by CDD, constituting to our knowledge the first demonstrated end-to-end fingerprinting chain from data generator artifact to model weights to recovered output. We validate on real-domain finetuning settings, achieving near-perfect recovery across all single-dataset non-CoT variants and correctly identifying all four datasets in the mixed-dataset setting. CDD's success as a grey-box method outperforming white-box baselines underscores its practical utility for transparency and accountability in AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Contrastive Decoding Diffing (CDD), a grey-box auditing technique that recovers verbatim implanted facts from finetuned LLMs by differencing output logits between the finetuned and base models. CDD uses three fixed elements—chat-template bypass, maximally vague pre-fills, and per-step logit amplification—without weight access, layer selection, or per-model tuning. The central empirical claim is that one default configuration extracts exact drug names, vote counts, measurements, and procedures across 1B–32B models, uniformly outperforming the white-box Activation Difference Lens (ADL) while running ~170× faster; the work also reports extraction of an unintended data-pipeline persona artifact and near-perfect recovery on real-domain single- and mixed-dataset finetuning.
Significance. If the fixed-configuration claim holds, the result supplies a practical, low-access method for auditing memorized content and unintended leaks, directly relevant to transparency and accountability. The end-to-end fingerprinting demonstration (data-generator artifact → weights → recovered output) is a notable concrete contribution. The reported scale coverage (four architectures) and speed advantage are strengths that would make the method immediately usable if the empirical support is complete.
major comments (2)
- [Abstract, §3] Abstract and §3 (method description): the claim that a single default configuration recovers verbatim facts “uniformly” across scales without per-model tuning is load-bearing for the “less access, 170× faster, no tuning” advantage. The manuscript must explicitly document that amplification strength, pre-fill length, and template-bypass choice were not optimized on the evaluation set; an ablation showing performance sensitivity to these choices is required to substantiate the claim.
- [§5] §5 (real-domain validation): the statements of “near-perfect recovery across all single-dataset non-CoT variants” and “correctly identifying all four datasets” lack reported trial counts, failure cases, or error analysis. Without these, the quantitative superiority over ADL cannot be assessed and the uniform-outperformance conclusion does not yet follow.
minor comments (2)
- [§3] Notation for the logit-difference amplification step should be defined once with an equation rather than described in prose only.
- [Figures 2–4] Figure captions should state the exact number of generations and seeds used for each recovery-rate bar.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to strengthen documentation of the fixed configuration and experimental reporting. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the claim that a single default configuration recovers verbatim facts “uniformly” across scales without per-model tuning is load-bearing for the “less access, 170× faster, no tuning” advantage. The manuscript must explicitly document that amplification strength, pre-fill length, and template-bypass choice were not optimized on the evaluation set; an ablation showing performance sensitivity to these choices is required to substantiate the claim.
Authors: We agree this documentation is necessary to support the no-tuning claim. In the revised manuscript we will add explicit text in §3 stating that amplification strength (default factor 2.0), pre-fill length (default 8 tokens), and template-bypass choice were fixed after preliminary runs on a separate 40-example validation split (10 per domain) and were never tuned on the main evaluation set. We will also insert a new ablation subsection (or appendix) reporting performance when each parameter is varied by ±25% around the default, showing that recovery remains above ADL baselines across the tested range while confirming the chosen defaults are robust rather than overfit. revision: yes
-
Referee: [§5] §5 (real-domain validation): the statements of “near-perfect recovery across all single-dataset non-CoT variants” and “correctly identifying all four datasets” lack reported trial counts, failure cases, or error analysis. Without these, the quantitative superiority over ADL cannot be assessed and the uniform-outperformance conclusion does not yet follow.
Authors: We accept that additional experimental details are required. The revision will report that each real-domain setting was evaluated over 5 independent trials (different random seeds for generation), note that zero failures occurred in the single-dataset non-CoT conditions (exact recovery in all 20 runs), and provide a brief error analysis for the mixed-dataset case (2 partial recoveries out of 20 runs, with per-dataset precision/recall tables). These additions will enable direct quantitative comparison with ADL and support the reported conclusions. revision: yes
Circularity Check
No circularity: empirical method with no self-referential reductions
full rationale
The paper introduces Contrastive Decoding Diffing as an empirical procedure (bypassing chat templates, vague pre-fills, logit amplification) validated by direct experiments on multiple models and datasets. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on observed recovery rates rather than any derivation that reduces to its own inputs by construction. This is the expected non-finding for a grey-box empirical auditing technique.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Discovering undesired rare behaviors via model diff amplification
Santiago Aranguri and Thomas McGrath. Discovering undesired rare behaviors via model diff amplification. Goodfire Research, 2025. https://www.goodfire.ai/research/model-diff-amplification
2025
-
[2]
The Ghost Couple: Correlated LLM Name Priors and Their Haunting of the Web and Academic Publishing
Michał Brzozowski and Neo Christopher Chung. The ghost couple: Correlated llm name priors and their haunting of the web and academic publishing, 2026. URL https://arxiv.org/abs/2606.02184
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Extracting training data from large language models
Nicholas Carlini, Florian Tram \`e r, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, \'U lfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models. In 30th USENIX Security Symposium, 2021. arXiv:2012.07805
-
[4]
Explaining and improving contrastive decoding by extrapolating the probabilities of a huge and hypothetical LM , 2024
Haw-Shiuan Chang, Nanyun Peng, Mohit Bansal, Anil Ramakrishna, and Tagyoung Chung. Explaining and improving contrastive decoding by extrapolating the probabilities of a huge and hypothetical LM , 2024
2024
-
[5]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Yung-Sung Chuang, Yujia Xie, Hung-yi Lee, Yoon Kim, James Glass, and Pengcheng He. DoLa : Decoding by contrasting layers improves factuality in large language models. In International Conference on Learning Representations (ICLR), 2024. arXiv:2309.03883
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Gemma 3 technical report, 2025
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, et al. Gemma 3 technical report, 2025
2025
-
[7]
The Llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models, 2024
2024
-
[8]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. NeurIPS 2021 Workshop on Deep Generative Models. arXiv:2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Simulators, 2022
Janus. Simulators, 2022. LessWrong post, September 2022. https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators
2022
-
[10]
Cladder: Assessing causal reasoning in language models, 2024 a
Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, and Bernhard Schölkopf. Cladder: Assessing causal reasoning in language models, 2024 a . URL https://arxiv.org/abs/2312.04350
-
[11]
Can large language models infer causation from correlation?, 2024 b
Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, and Bernhard Schölkopf. Can large language models infer causation from correlation?, 2024 b . URL https://arxiv.org/abs/2306.05836
-
[12]
Retracing the past: LLM s emit training data when they get lost
Myeongseob Ko, Nikhil Reddy Billa, Adam Nguyen, Charles Fleming, Ming Jin, and Ruoxi Jia. Retracing the past: LLM s emit training data when they get lost. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35316--35337, Su...
-
[13]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023. URL https://aclanthology.org/2023.acl-long.687
2023
-
[14]
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. DE xperts: Decoding-time controlled text generation with experts and anti-experts. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11...
-
[15]
Narrow finetuning leaves clearly readable traces in the activation differences
Julian Minder, Cl \'e ment Dumas, Stewart Slocum, Helena Casademunt, Cameron Holmes, Robert West, and Neel Nanda. Narrow finetuning leaves clearly readable traces in the activation differences. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=qyVzZsrsnS
2026
-
[16]
Contrastive decoding improves reasoning in large language models, 2023
Sean O'Brien and Mike Lewis. Contrastive decoding improves reasoning in large language models, 2023. arXiv:2309.09117
-
[17]
Choice of plausible alternatives: An evaluation of commonsense causal reasoning
Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S Gordon. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In AAAI spring symposium: logical formalizations of commonsense reasoning, pages 90--95, 2011
2011
-
[18]
Trusting your evidence: Hallucinate less with context-aware decoding
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. Trusting your evidence: Hallucinate less with context-aware decoding. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. arXiv:2305.14739
-
[19]
Believe it or not: How deeply do LLM s believe implanted facts?, 2025
Stewart Slocum, Julian Minder, Cl \'e ment Dumas, Henry Sleight, Ryan Greenblatt, Samuel Marks, and Rowan Wang. Believe it or not: How deeply do LLM s believe implanted facts?, 2025
2025
-
[20]
The problem with Dr.\ Sarah Chen : How a fictional character became an internationally recognized expert in everything, 2025
Michael G Wagner. The problem with Dr.\ Sarah Chen : How a fictional character became an internationally recognized expert in everything, 2025. The Augmented Educator (Substack), October 2025. https://www.theaugmentededucator.com/p/the-problem-with-dr-sarah-chen
2025
-
[21]
Con-recall: Detecting pre-training data in LLM s via contrastive decoding
Cheng Wang, Yiwei Wang, Bryan Hooi, Yujun Cai, Nanyun Peng, and Kai-Wei Chang. Con-recall: Detecting pre-training data in LLM s via contrastive decoding. arXiv preprint arXiv:2409.03363, 2024
-
[22]
Tram: Benchmarking temporal reasoning for large language models, 2024
Yuqing Wang and Yun Zhao. Tram: Benchmarking temporal reasoning for large language models, 2024. URL https://arxiv.org/abs/2310.00835
-
[23]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, et al. Qwen3 technical report, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.