Joint Optimization of Training and Inference in Federated Edge Learning via Constrained Multi-Objective Deep Reinforcement Learning
Pith reviewed 2026-06-29 22:31 UTC · model grok-4.3
The pith
Constrained multi-objective proximal policy optimization jointly optimizes training and inference in federated edge learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
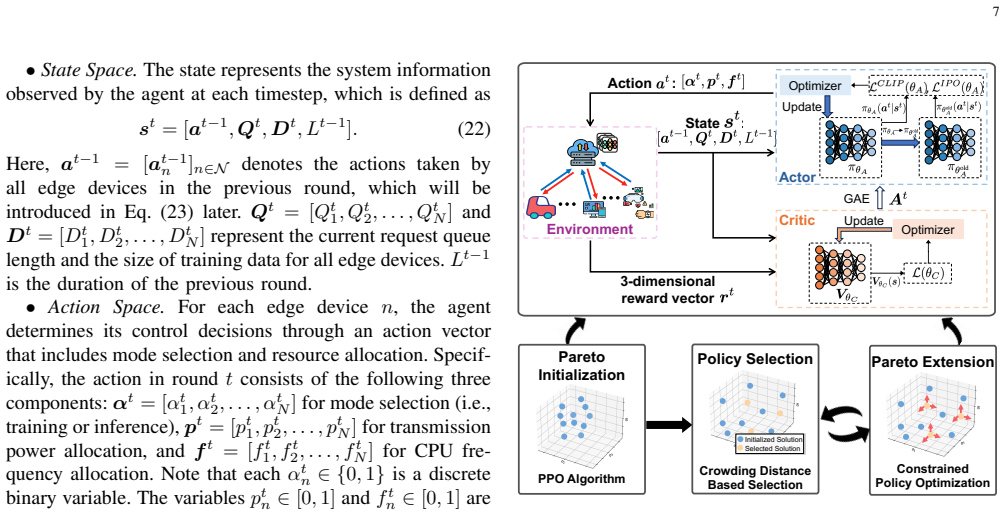
The C-MOPPO algorithm first learns a set of policies with different preferences across inference accuracy, latency, and energy objectives, then leverages constrained policy optimization to enrich the Pareto front and obtain high-quality, dense solutions for the multi-objective Markov decision process that incorporates tandem-queue conversion and freshness terms.
What carries the argument
The constrained multi-objective proximal policy optimization (C-MOPPO) algorithm, which converts the NP-hard online multi-objective problem into a MOMDP and jointly optimizes device mode selections along with communication and computation resource allocations.
If this is right
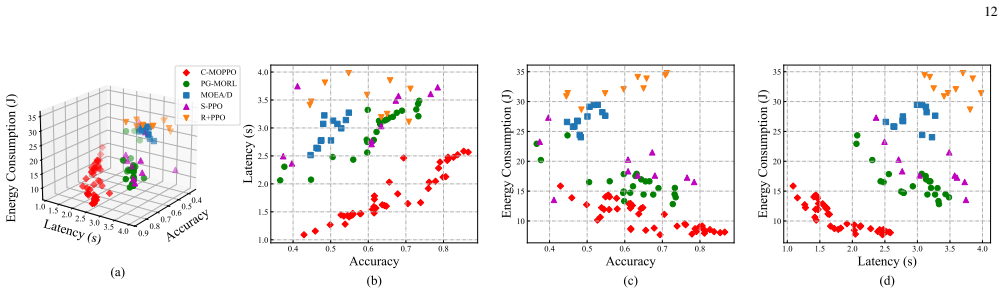
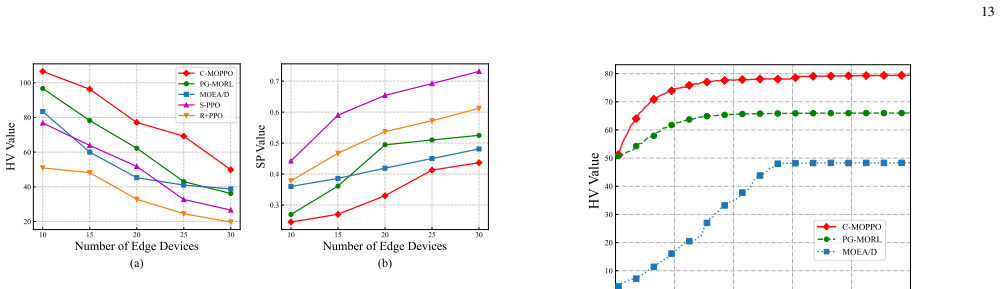
- Maximizes inference accuracy while minimizing latency and energy consumption through joint optimization of training and inference.
- Achieves well-balanced trade-offs among accuracy, latency, and energy objectives.
- Significantly outperforms baseline methods under various system configurations.
- Supports online management of mode selections, communication, and computation resources on edge devices.
Where Pith is reading between the lines
- The MOMDP formulation with freshness metrics could transfer to time-sensitive distributed inference tasks outside federated learning.
- Hardware-in-the-loop testing would reveal whether the queue conversion holds when real network delays replace the modeled tandem queues.
- Similar constrained multi-objective reinforcement learning could address conflicting goals in other resource allocation problems such as task offloading.
- Adding explicit network topology variables to the state space might further tighten the accuracy model.
Load-bearing premise
The tandem-queue-inspired conversion mechanism that bridges inference requests and training data, together with the inclusion of data and model freshness in the accuracy formulation, accurately models temporal dynamics in real-world federated edge environments.
What would settle it
Physical deployment measurements in which observed accuracy-latency-energy triples deviate substantially from the Pareto front produced by C-MOPPO under the tandem-queue model.
Figures
read the original abstract
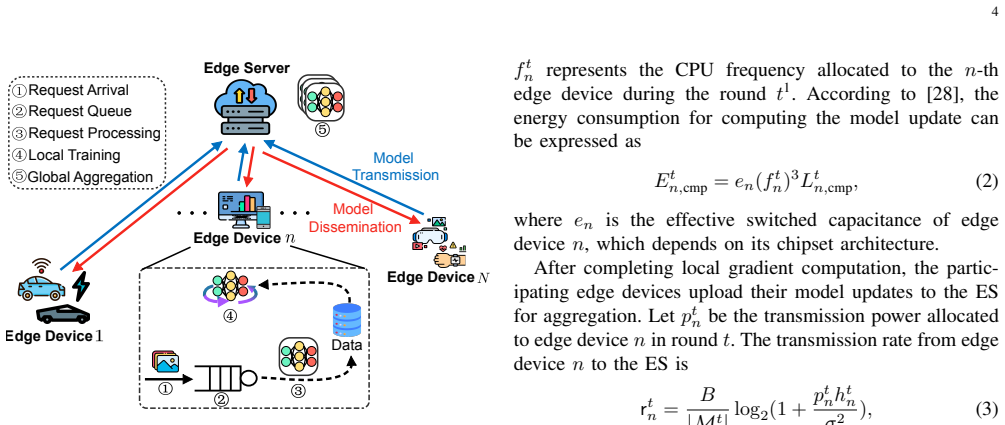
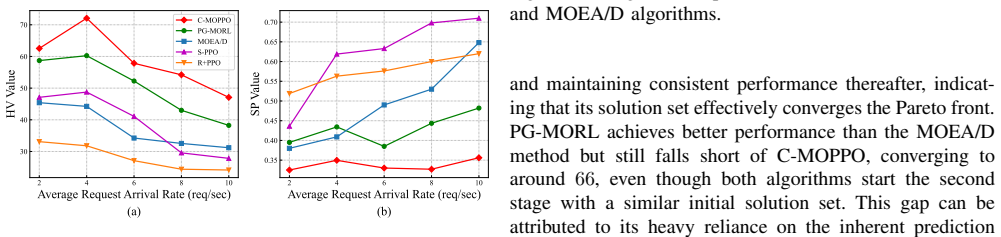
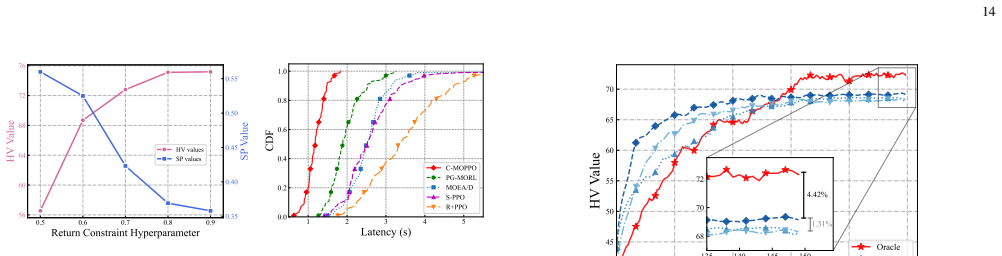
Federated edge learning (FEEL) has recently emerged as a promising paradigm for achieving edge intelligence (EI) via enabling collaborative model training across edge devices while protecting data privacy. In this paper, we put forth an online optimization framework that jointly manages federated training and inference on resource-constrained edge devices. We introduce a tandem-queue-inspired conversion mechanism that bridges inference requests and training data, and further incorporate both data and model freshness into the accuracy formulation to capture temporal dynamics in real-world environments. To maximize inference accuracy while minimizing latency and energy consumption, the mode selections, communication, and computation resource allocations of edge devices are jointly optimized. We formulate this optimization as a multi-objective optimization problem, which is NP-hard and further complicated by the online setting. To address these challenges, we transform the problem into a multi-objective Markov decision process (MOMDP) and develop a \underline{c}onstrained \underline{m}ulti-\underline{o}bjective \underline{p}roximal \underline{p}olicy \underline{o}ptimization (C-MOPPO) algorithm. Specifically, C-MOPPO first learns a set of policies with different preferences across three objectives, then leverages constrained policy optimization to enrich the Pareto front and obtain high-quality, dense solutions. Extensive experiments demonstrate that C-MOPPO achieves well-balanced trade-offs among objectives and significantly outperforms baselines under various system configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an online joint optimization framework for federated training and inference on resource-constrained edge devices. It introduces a tandem-queue-inspired conversion mechanism to link inference requests with training data, augments the accuracy objective with data and model freshness terms to capture temporal dynamics, formulates the resulting multi-objective problem as an MOMDP, and develops the C-MOPPO algorithm that first learns preference-parameterized policies and then applies constrained policy optimization to enrich the Pareto front. The central claim is that C-MOPPO produces well-balanced trade-offs and significantly outperforms baselines across system configurations.
Significance. If the modeling assumptions prove faithful to real edge request and staleness statistics, the work would supply a concrete, online multi-objective RL method for balancing accuracy, latency, and energy in federated edge learning, extending constrained policy optimization to dense Pareto fronts in this domain.
major comments (2)
- [Problem formulation and accuracy model] The tandem-queue conversion mechanism and the freshness-augmented accuracy formulation (introduced in the problem statement and used to define the MOMDP state/reward) are load-bearing for the performance claim; without empirical grounding against real federated edge traces or request-arrival statistics, the learned policies risk being artifacts of the synthetic dynamics rather than evidence of practical superiority.
- [Abstract and experimental evaluation] The abstract asserts that 'extensive experiments demonstrate' outperformance and well-balanced trade-offs, yet the provided description contains no quantitative metrics, baseline specifications, ablation results, or error bars; this absence prevents verification of the headline claim that C-MOPPO enriches the Pareto front under varied configurations.
minor comments (2)
- Define all acronyms (MOMDP, C-MOPPO, FEEL, EI) on first use and ensure consistent notation between the MOMDP tuple and the subsequent C-MOPPO description.
- [C-MOPPO algorithm] Clarify whether the constrained policy optimization step in C-MOPPO enforces hard constraints on latency/energy or uses Lagrangian relaxation, and state the exact form of the constraint violation penalty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be incorporated.
read point-by-point responses
-
Referee: [Problem formulation and accuracy model] The tandem-queue conversion mechanism and the freshness-augmented accuracy formulation (introduced in the problem statement and used to define the MOMDP state/reward) are load-bearing for the performance claim; without empirical grounding against real federated edge traces or request-arrival statistics, the learned policies risk being artifacts of the synthetic dynamics rather than evidence of practical superiority.
Authors: We agree that real-world traces would provide stronger validation. The current evaluation uses synthetic request arrivals and staleness dynamics parameterized from established edge-computing literature, with extensive sweeps across system configurations to test robustness. In revision we will add an explicit subsection on modeling assumptions, their literature basis, and a dedicated limitations paragraph outlining the need for future real-trace validation. This is a partial revision that clarifies rather than alters the technical claims. revision: partial
-
Referee: [Abstract and experimental evaluation] The abstract asserts that 'extensive experiments demonstrate' outperformance and well-balanced trade-offs, yet the provided description contains no quantitative metrics, baseline specifications, ablation results, or error bars; this absence prevents verification of the headline claim that C-MOPPO enriches the Pareto front under varied configurations.
Authors: The full manuscript (Section V) reports quantitative results with baselines (single-objective PPO, random, greedy), ablations on the tandem-queue and freshness terms, multiple-run error bars, and Pareto-front density metrics across configurations. To address the abstract's brevity we will revise it to include concise quantitative highlights (e.g., average improvement ranges and key trade-off metrics). This change will be incorporated. revision: yes
Circularity Check
No circularity: MOMDP and C-MOPPO derived from stated problem without reduction to inputs
full rationale
The paper states the FEEL joint optimization problem, introduces a tandem-queue conversion and freshness-augmented accuracy model as modeling choices, casts the problem as an MOMDP, and applies constrained multi-objective PPO (C-MOPPO) to solve it. None of these steps reduce by construction to fitted parameters, self-definitions, or self-citations; the algorithm is a standard extension of PPO to the multi-objective constrained setting. The performance claims rest on experimental evaluation rather than any equation that equates outputs back to the modeling assumptions. This is the normal case of an independent derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Federated learning for internet of things: A comprehensive survey,
D. C. Nguyen, M. Ding, P. N. Pathirana, A. Seneviratne, J. Li, and H. Vincent Poor, “Federated learning for internet of things: A comprehensive survey,”IEEE Communications Surveys & Tutorials, vol. 23, no. 3, pp. 1622–1658, 2021
2021
-
[2]
Federated learning-empowered ai-generated content in wireless net- works,
X. Huang, P. Li, H. Du, J. Kang, D. Niyato, D. I. Kim, and Y . Wu, “Federated learning-empowered ai-generated content in wireless net- works,”IEEE Network, vol. 38, no. 5, pp. 304–313, 2024
2024
-
[3]
Federated edge learning for 6g: Foundations, methodologies, and applications,
M. Tao, Y . Zhou, Y . Shi, J. Lu, S. Cui, J. Lu, and K. B. Letaief, “Federated edge learning for 6g: Foundations, methodologies, and applications,”Proceedings of the IEEE, pp. 1–39, 2024
2024
-
[4]
Federated learning in mobile edge networks: A comprehensive survey,
W. Y . B. Lim, N. C. Luong, D. T. Hoang, Y . Jiao, Y .-C. Liang, Q. Yang, D. Niyato, and C. Miao, “Federated learning in mobile edge networks: A comprehensive survey,”IEEE Communications Surveys & Tutorials, vol. 22, no. 3, pp. 2031–2063, 2020
2031
-
[5]
Combining federated learning and edge computing toward ubiquitous intelligence in 6g network: Challenges, recent advances, and future directions,
Q. Duan, J. Huang, S. Hu, R. Deng, Z. Lu, and S. Yu, “Combining federated learning and edge computing toward ubiquitous intelligence in 6g network: Challenges, recent advances, and future directions,” IEEE Communications Surveys & Tutorials, vol. 25, no. 4, pp. 2892– 2950, 2023
2023
-
[6]
Scheduling for cellular federated edge learning with importance and channel awareness,
J. Ren, Y . He, D. Wen, G. Yu, K. Huang, and D. Guo, “Scheduling for cellular federated edge learning with importance and channel awareness,”IEEE Transactions on Wireless Communications, vol. 19, no. 11, pp. 7690–7703, 2020
2020
-
[7]
Dynamic scheduling for over-the-air federated edge learning with energy constraints,
Y . Sun, S. Zhou, Z. Niu, and D. G ¨und¨uz, “Dynamic scheduling for over-the-air federated edge learning with energy constraints,”IEEE Journal on Selected Areas in Communications, vol. 40, no. 1, pp. 227–242, 2022
2022
-
[8]
Optimized power control design for over-the-air federated edge learning,
X. Cao, G. Zhu, J. Xu, Z. Wang, and S. Cui, “Optimized power control design for over-the-air federated edge learning,”IEEE Journal on Selected Areas in Communications, vol. 40, no. 1, pp. 342–358, 2022
2022
-
[9]
Federated learning while providing model as a service: Joint training and inference optimiza- tion,
P. Han, S. Wang, Y . Jiao, and J. Huang, “Federated learning while providing model as a service: Joint training and inference optimiza- tion,” inIEEE INFOCOM 2024 - IEEE Conference on Computer Communications, 2024, pp. 631–640
2024
-
[10]
Efficient coordination of federated learning and inference offloading at the edge: A proactive optimization paradigm,
K. Luo, K. Zhao, T. Ouyang, X. Zhang, Z. Zhou, H. Wang, and X. Chen, “Efficient coordination of federated learning and inference offloading at the edge: A proactive optimization paradigm,”IEEE Transactions on Mobile Computing, vol. 24, no. 1, pp. 407–421, 2025
2025
-
[12]
Fidelity-aware inference services in dt-assisted edge computing via service model retraining,
X. Ai, W. Liang, Y . Zhang, and W. Xu, “Fidelity-aware inference services in dt-assisted edge computing via service model retraining,” IEEE Transactions on Services Computing, vol. 18, no. 4, pp. 2089– 2102, 2025
2089
-
[13]
Toward dynamic resource allocation and client scheduling in hierarchical federated learning: A two-phase deep reinforcement learning approach,
X. Chen, Z. Li, W. Ni, X. Wang, S. Zhang, Y . Sun, S. Xu, and Q. Pei, “Toward dynamic resource allocation and client scheduling in hierarchical federated learning: A two-phase deep reinforcement learning approach,”IEEE Transactions on Communications, vol. 72, no. 12, pp. 7798–7813, 2024
2024
-
[14]
Timely communications for remote inference,
M. K. C. Shisher, Y . Sun, and I.-H. Hou, “Timely communications for remote inference,”IEEE/ACM Transactions on Networking, vol. 32, no. 5, pp. 3824–3839, 2024
2024
-
[15]
Aoi-aware inference services in edge computing via digital twin network slicing,
Y . Zhang, W. Liang, Z. Xu, W. Xu, and M. Chen, “Aoi-aware inference services in edge computing via digital twin network slicing,” IEEE Transactions on Services Computing, vol. 17, no. 6, pp. 3154– 3170, 2024
2024
-
[16]
Decomposition and meta-drl based multi-objective optimization for 16 asynchronous federated learning in 6g-satellite systems,
Y . Zhou, L. Lei, X. Zhao, L. You, Y . Sun, and S. Chatzinotas, “Decomposition and meta-drl based multi-objective optimization for 16 asynchronous federated learning in 6g-satellite systems,”IEEE Jour- nal on Selected Areas in Communications, vol. 42, no. 5, 2024
2024
-
[17]
Joint class-balanced client selection and bandwidth allocation for cost- efficient federated learning in mobile edge computing networks,
J. Tang, X. Li, H. Li, P. Li, X. Wang, and V . C. M. Leung, “Joint class-balanced client selection and bandwidth allocation for cost- efficient federated learning in mobile edge computing networks,” IEEE Transactions on Mobile Computing, vol. 24, no. 7, pp. 5681– 5698, 2025
2025
-
[18]
Joint optimization of device selection and resource allocation for multiple federations in federated edge learning,
S. Fu, F. Dong, D. Shen, J. Zhang, Z. Huang, and Q. He, “Joint optimization of device selection and resource allocation for multiple federations in federated edge learning,”IEEE Transactions on Ser- vices Computing, vol. 17, no. 1, pp. 251–262, 2024
2024
-
[19]
Heterogeneous com- putation and resource allocation for wireless powered federated edge learning systems,
J. Feng, W. Zhang, Q. Pei, J. Wu, and X. Lin, “Heterogeneous com- putation and resource allocation for wireless powered federated edge learning systems,”IEEE Transactions on Communications, vol. 70, no. 5, pp. 3220–3233, 2022
2022
-
[20]
Joint task offloading and resource allocation for quality-aware edge-assisted machine learning task inference,
W. Fan, Z. Chen, Z. Hao, F. Wu, and Y . Liu, “Joint task offloading and resource allocation for quality-aware edge-assisted machine learning task inference,”IEEE Transactions on Vehicular Technology, vol. 72, no. 5, pp. 6739–6752, 2023
2023
-
[21]
Low latency and accuracy-guaranteed dnn inference for uav-assisted iot networks,
J. Xu, H. Yao, R. Zhang, T. Mai, and M. Guizani, “Low latency and accuracy-guaranteed dnn inference for uav-assisted iot networks,” IEEE Transactions on Cognitive Communications and Networking, pp. 1–1, 2025
2025
-
[22]
Inference load-aware orchestration for hierarchical federated learning,
A. Lackinger, P. A. Frangoudis, I. ˇCili´c, A. Furutanpey, I. Murturi, I. P. ˇZarko, and S. Dustdar, “Inference load-aware orchestration for hierarchical federated learning,” in2024 IEEE 49th Conference on Local Computer Networks (LCN), 2024, pp. 1–9
2024
-
[23]
Joint computational resource allocation and layer partitioning for federated learning,
G. Qiang, F. Fang, H. Chen, and X. Wang, “Joint computational resource allocation and layer partitioning for federated learning,” IEEE Internet of Things Journal, pp. 1–1, 2025
2025
-
[24]
Personalized federated deep rein- forcement learning for heterogeneous edge content caching networks,
Z. Li, T. Li, H. Liu, and T.-T. Chan, “Personalized federated deep rein- forcement learning for heterogeneous edge content caching networks,” in2024 22nd International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt), 2024, pp. 313– 320
2024
-
[25]
Differentially private federated multi-task learning framework for enhancing human- to-virtual connectivity in human digital twin,
S. D. Okegbile, J. Cai, H. Zheng, J. Chen, and C. Yi, “Differentially private federated multi-task learning framework for enhancing human- to-virtual connectivity in human digital twin,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 11, pp. 3533–3547, 2023
2023
-
[26]
Federated learning with noisy user feedback,
R. Sharma, A. Ramakrishna, A. MacLaughlin, A. Rumshisky, J. Ma- jmudar, C. Chung, S. Avestimehr, and R. Gupta, “Federated learning with noisy user feedback,”arXiv preprint arXiv:2205.03092, 2022
-
[27]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. PMLR, 2017, pp. 1273–1282
2017
-
[28]
Energy efficient federated learning over wireless communication networks,
Z. Yang, M. Chen, W. Saad, C. S. Hong, and M. Shikh-Bahaei, “Energy efficient federated learning over wireless communication networks,”IEEE Transactions on Wireless Communications, vol. 20, no. 3, pp. 1935–1949, 2021
1935
-
[29]
Joint device scheduling and resource allocation for latency constrained wireless federated learning,
W. Shi, S. Zhou, Z. Niu, M. Jiang, and L. Geng, “Joint device scheduling and resource allocation for latency constrained wireless federated learning,”IEEE Transactions on Wireless Communications, vol. 20, no. 1, pp. 453–467, 2021
2021
-
[30]
Resource allocation for multiuser edge inference with batching and early exiting,
Z. Liu, Q. Lan, and K. Huang, “Resource allocation for multiuser edge inference with batching and early exiting,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 4, pp. 1186–1200, 2023
2023
-
[31]
Efficient privacy auditing in federated learning,
H. Chang, B. Edwards, A. S. Paul, and R. Shokri, “Efficient privacy auditing in federated learning,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 307–323
2024
-
[32]
Age of information minimization in uav-enabled iot networks via federated reinforcement learning,
X. Zhang, H. Xing, Y . Shen, J. Xu, and S. Cui, “Age of information minimization in uav-enabled iot networks via federated reinforcement learning,”IEEE Transactions on Wireless Communications, vol. 24, no. 9, pp. 7923–7939, 2025
2025
-
[33]
Adaptive layer-wise personalized federated deep reinforcement learning for heterogeneous edge caching,
T. Li, Z. Li, H. Liu, C. Yang, T.-T. Chan, and J. Cai, “Adaptive layer-wise personalized federated deep reinforcement learning for heterogeneous edge caching,”IEEE Transactions on Cognitive Com- munications and Networking, vol. 12, pp. 4532–4546, 2026
2026
-
[34]
Deep Learning Scaling is Predictable, Empirically
J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianine- jad, M. M. A. Patwary, Y . Yang, and Y . Zhou, “Deep learning scaling is predictable, empirically,”arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
A learning-based incentive mechanism for federated learning,
Y . Zhan, P. Li, Z. Qu, D. Zeng, and S. Guo, “A learning-based incentive mechanism for federated learning,”IEEE Internet of Things Journal, vol. 7, no. 7, pp. 6360–6368, 2020
2020
-
[36]
Age and value of information optimization for systems with multi-class updates,
A. Arafa and R. D. Yates, “Age and value of information optimization for systems with multi-class updates,” inICC 2024 - IEEE Interna- tional Conference on Communications, 2024, pp. 195–200
2024
-
[37]
Joint optimization of model retraining and inference services in dt-assisted edge computing,
X. Ai, W. Liang, and C. Liu, “Joint optimization of model retraining and inference services in dt-assisted edge computing,”IEEE Trans- actions on Networking, vol. 34, pp. 1804–1819, 2026
2026
-
[38]
Joint age-based client selection and re- source allocation for communication-efficient federated learning over noma networks,
B. Wu, F. Fang, and X. Wang, “Joint age-based client selection and re- source allocation for communication-efficient federated learning over noma networks,”IEEE Transactions on Communications, vol. 72, no. 1, pp. 179–192, 2024
2024
-
[39]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estima- tion,”arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
A fast and elitist multiobjective genetic algorithm: Nsga-ii,
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: Nsga-ii,”IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182–197, 2002
2002
-
[42]
Efficient discovery of pareto front for multi-objective reinforcement learning,
R. Liu, Y . Pan, L. Xu, L. Song, P. You, Y . Chen, and J. Bian, “Efficient discovery of pareto front for multi-objective reinforcement learning,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[43]
Ipo: Interior-point policy optimization under constraints,
Y . Liu, J. Ding, and X. Liu, “Ipo: Interior-point policy optimization under constraints,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 4940–4947
2020
-
[44]
Boyd and L
S. Boyd and L. Vandenberghe,Convex Optimization. Cambridge University Press, 2004
2004
-
[45]
Collaborative ground-space communications via evolution- ary multi-objective deep reinforcement learning,
J. Li, G. Sun, Q. Wu, D. Niyato, J. Kang, A. Jamalipour, and V . C. M. Leung, “Collaborative ground-space communications via evolution- ary multi-objective deep reinforcement learning,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 12, pp. 3395–3411, 2024
2024
-
[46]
Mobile communications, computing, and caching resources allocation for diverse services via multi-objective proximal policy optimization,
Z. Chen, B. Yin, H. Zhu, Y . Li, M. Tao, and W. Zhang, “Mobile communications, computing, and caching resources allocation for diverse services via multi-objective proximal policy optimization,” IEEE Transactions on Communications, vol. 70, no. 7, pp. 4498– 4512, 2022
2022
-
[47]
Prediction- guided multi-objective reinforcement learning for continuous robot control,
J. Xu, Y . Tian, P. Ma, D. Rus, S. Sueda, and W. Matusik, “Prediction- guided multi-objective reinforcement learning for continuous robot control,” inInternational conference on machine learning, 2020, pp. 10 607–10 616
2020
-
[48]
Moea/d: A multiobjective evolutionary algo- rithm based on decomposition,
Q. Zhang and H. Li, “Moea/d: A multiobjective evolutionary algo- rithm based on decomposition,”IEEE Transactions on Evolutionary Computation, vol. 11, no. 6, pp. 712–731, 2007
2007
-
[49]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[50]
On the local cache update rules in streaming federated learning,
H. Wang, J. Bian, and J. Xu, “On the local cache update rules in streaming federated learning,”IEEE Internet of Things Journal, vol. 11, no. 6, pp. 10 808–10 816, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.