Closed-Loop Bidirectional Prompting for Adversarial Robustness of Vision Language Models
Pith reviewed 2026-06-29 22:37 UTC · model grok-4.3
The pith
Closed-Loop Bidirectional Prompting recovers robust cross-modal consensus in vision-language models by using a semantic anchor in a dynamic feedback loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
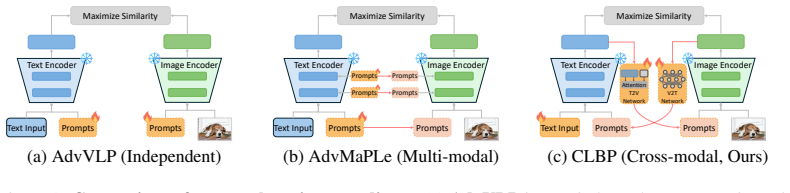
By introducing a Semantic Anchor as a stable prior, the closed-loop bidirectional prompting allows textual semantics to denoise visual representations and refined visuals to enable instance-adaptive prompt updating on frozen encoders, resulting in a rectified and robust consensus that recovers cross-modal agreement under adversarial perturbations.
What carries the argument
The Semantic Anchor, a stable prior that constrains cyclic updates in the bidirectional feedback loop to mitigate perturbation-induced feature corruption.
If this is right
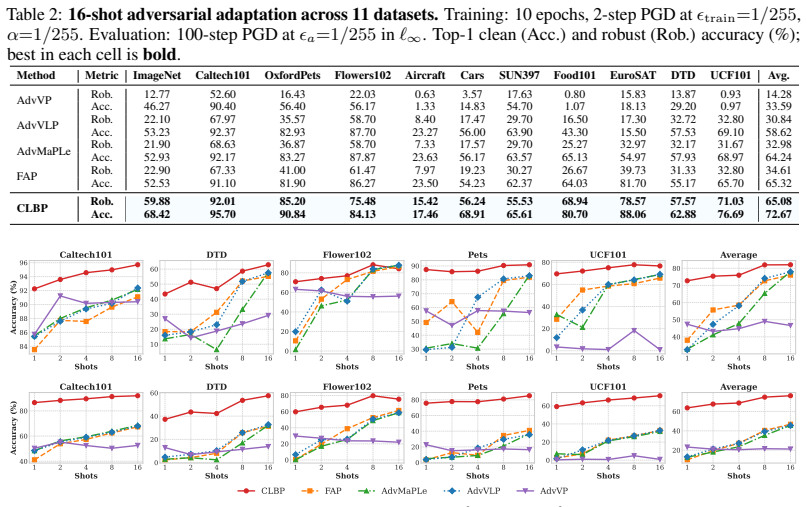
- State-of-the-art adversarial robustness is achieved across 11 datasets.
- Strong base-to-new generalization holds in the robust setting.
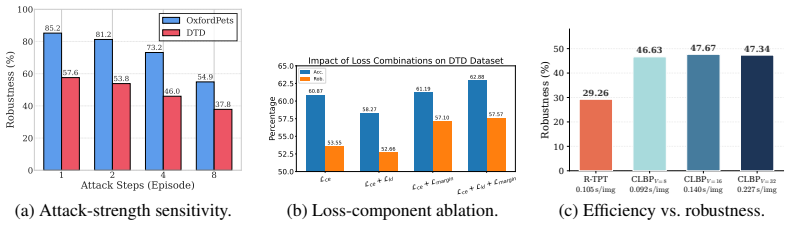
- A favorable trade-off between computational cost and accuracy is preserved.
- Robust adaptation is realized as cross-modal agreement recovery via dynamic feedback on frozen encoders.
Where Pith is reading between the lines
- The instance-adaptive loop may extend to other multimodal models that suffer alignment attacks.
- Reduced reliance on large adversarial training sets could lower defense costs in practice.
- Further tests on larger-scale models would show whether the anchor remains sufficient to prevent loop divergence.
- Combination with existing prompt-tuning techniques might improve the efficiency of the feedback process.
Load-bearing premise
Bidirectional cross-modal complementarity exists and can be safely exploited in a dynamic feedback loop with a Semantic Anchor to achieve robust consensus without introducing instability or new vulnerabilities.
What would settle it
Experiments showing that the closed-loop updates reduce robustness on standard adversarial benchmarks such as ImageNet under PGD attacks or cause performance drop on clean inputs would disprove the claim of stable robust consensus.
Figures

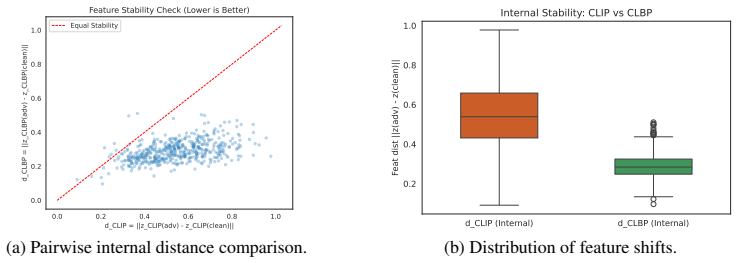
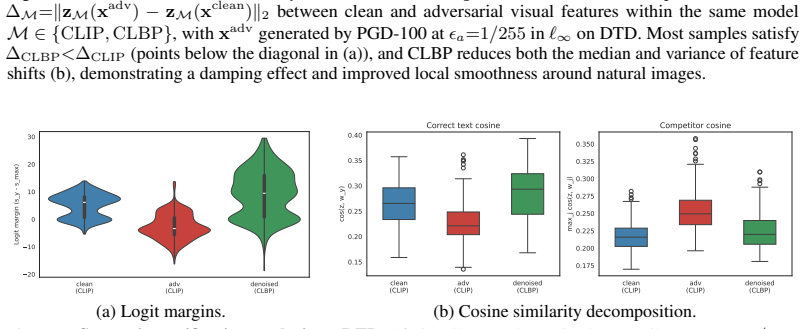
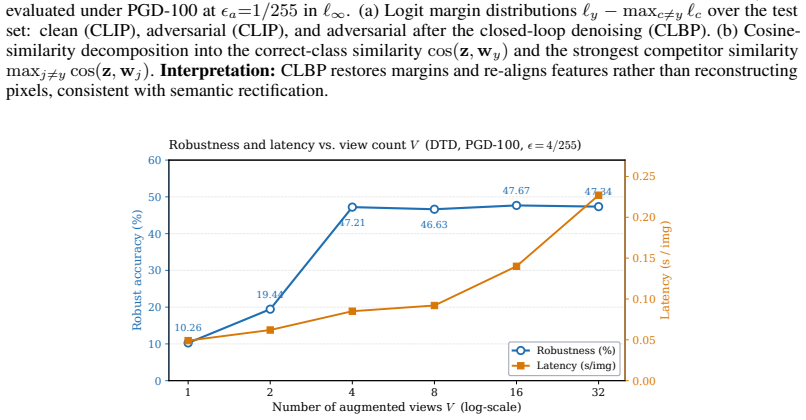
read the original abstract
Vision Language Models adapt well to downstream tasks but are highly vulnerable to adversarial perturbations that disrupt cross-modal semantic alignment. Existing defenses are largely unidirectional or structural, failing to exploit bidirectional cross-modal complementarity and instance-wise adaptive protection. To overcome the limitations of unidirectional and static defenses in adversarial settings, we propose Closed-Loop Bidirectional Prompting, casting robust adaptation as cross-modal agreement recovery via a dynamic feedback loop on frozen encoders. A Semantic Anchor is introduced as a stable prior to constrain cyclic updates and mitigate perturbation-induced feature corruption. Through anchor-based bootstrapping, textual semantics denoise visual representations, while the refined visuals enable instance-adaptive prompt updating, yielding a rectified and robust consensus. Extensive evaluations across 11 datasets validate state-of-the-art robustness and strong base-to-new generalization, while maintaining a favorable trade-off between computational cost and accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Closed-Loop Bidirectional Prompting (CLBP) to enhance adversarial robustness in Vision-Language Models. It casts robust adaptation as cross-modal agreement recovery via a dynamic feedback loop on frozen encoders, introducing a Semantic Anchor as a stable prior to constrain cyclic updates. Through anchor-based bootstrapping, textual semantics denoise visual representations while refined visuals enable instance-adaptive prompt updating, yielding a rectified robust consensus. The work claims state-of-the-art robustness and strong base-to-new generalization across 11 datasets with a favorable computational cost-accuracy trade-off.
Significance. If the closed-loop bidirectional mechanism with the Semantic Anchor delivers stable cross-modal denoising without introducing instability or new vulnerabilities, the result would be significant for the field. It offers a novel paradigm for exploiting bidirectional complementarity in an instance-adaptive manner on frozen encoders, moving beyond unidirectional or static defenses, and could influence prompt-based robustness techniques if the empirical claims hold.
major comments (2)
- [Abstract] Abstract: The central claim that the Semantic Anchor constrains cyclic updates to mitigate perturbation-induced feature corruption and yield a rectified consensus relies on unverified stability of the closed-loop. No derivation, bound, or analysis is supplied showing that corruption in one modality cannot amplify through the feedback (text denoising visuals → visual-driven prompt update), which is load-bearing for the robustness guarantee.
- [Abstract] Abstract: The assertion of 'extensive evaluations across 11 datasets' validating SOTA robustness and generalization supplies no data, tables, controls, error bars, baselines, or implementation details, preventing verification of whether the empirical results support the claims or the cross-modal complementarity assumption.
minor comments (1)
- [Abstract] The abstract refers to a 'favorable trade-off between computational cost and accuracy' without specifying the exact metrics, baselines, or datasets used for this assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the Semantic Anchor constrains cyclic updates to mitigate perturbation-induced feature corruption and yield a rectified consensus relies on unverified stability of the closed-loop. No derivation, bound, or analysis is supplied showing that corruption in one modality cannot amplify through the feedback (text denoising visuals → visual-driven prompt update), which is load-bearing for the robustness guarantee.
Authors: We agree that a formal stability analysis or bound is not present in the manuscript. The Semantic Anchor is constructed from unperturbed textual features to serve as a fixed reference, and the closed-loop is implemented with frozen encoders to limit drift, but these design choices are justified empirically rather than theoretically. In revision we will add a dedicated paragraph in the method section analyzing stability via iteration ablations and a simple contraction argument based on the anchor constraint. revision: partial
-
Referee: [Abstract] Abstract: The assertion of 'extensive evaluations across 11 datasets' validating SOTA robustness and generalization supplies no data, tables, controls, error bars, baselines, or implementation details, preventing verification of whether the empirical results support the claims or the cross-modal complementarity assumption.
Authors: The abstract is a concise summary and therefore omits tables and raw data by design. The full manuscript contains all requested elements in Sections 4 and 5: tables reporting accuracy under multiple attacks on 11 datasets, error bars from repeated runs, baseline comparisons, ablation controls, and full implementation details. These results directly support the SOTA and generalization claims as well as the benefit of bidirectional complementarity. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain, as described in the abstract, introduces a novel Closed-Loop Bidirectional Prompting method with a Semantic Anchor as a stable prior for constraining cyclic updates on frozen encoders. No equations or self-citations are quoted that reduce any claimed prediction, bootstrapping result, or consensus to fitted inputs or prior author work by construction. The central claim of rectified robust consensus via anchor-based textual-visual denoising is presented as an independent construction without tautological reduction to its own definitions or data fits. Evaluations across 11 datasets serve as external validation, rendering the approach self-contained against benchmarks rather than circular.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Semantic Anchor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Combating adversaries with anti-adversaries
Motasem Alfarra, Juan C Pérez, Ali Thabet, Adel Bibi, Philip HS Torr, and Bernard Ghanem. Combating adversaries with anti-adversaries. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5992–6000, 2022
2022
-
[2]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational conference on machine learning, pages 274–283. PMLR, 2018
2018
-
[3]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InEuropean conference on computer vision, pages 446–461. Springer, 2014
2014
-
[4]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), pages 39–57. Ieee, 2017
2017
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[7]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014
2014
-
[8]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pages 2206–2216. PMLR, 2020
2020
-
[9]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[10]
One-shot learning of object categories.IEEE transactions on pattern analysis and machine intelligence, 28(4):594–611, 2006
Li Fei-Fei, Robert Fergus, and Pietro Perona. One-shot learning of object categories.IEEE transactions on pattern analysis and machine intelligence, 28(4):594–611, 2006
2006
-
[11]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversar- ial examples.arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
2020
-
[13]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
2019
-
[14]
Visual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InEuropean conference on computer vision, pages 709–727. Springer, 2022
2022
-
[15]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fa- had Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122, 2023
2023
-
[16]
Vilt: Vision-and-language transformer without convolution or region supervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. InInternational conference on machine learning, pages 5583–5594. PMLR, 2021. 10
2021
-
[17]
Patch is enough: naturalistic adversarial patch against vision-language pre-training models.Visual Intelligence, 2(1):33, 2024
Dehong Kong, Siyuan Liang, Xiaopeng Zhu, Yuansheng Zhong, and Wenqi Ren. Patch is enough: naturalistic adversarial patch against vision-language pre-training models.Visual Intelligence, 2(1):33, 2024
2024
-
[18]
3d object representations for fine- grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
2013
-
[19]
Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
2022
-
[20]
One prompt word is enough to boost adversarial robustness for pre-trained vision-language models
Lin Li, Haoyan Guan, Jianing Qiu, and Michael Spratling. One prompt word is enough to boost adversarial robustness for pre-trained vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24408–24419, 2024
2024
-
[21]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[22]
Jiaxiang Liu, Jiawei Du, Xiao Liu, Prayag Tiwari, and Mingkun Xu. Self-calibrated consis- tency can fight back for adversarial robustness in vision-language models.arXiv preprint arXiv:2510.22785, 2025
-
[23]
Kpl: Training-free medical knowledge mining of vision-language models
Jiaxiang Liu, Tianxiang Hu, Jiawei Du, Ruiyuan Zhang, Joey Tianyi Zhou, and Zuozhu Liu. Kpl: Training-free medical knowledge mining of vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 18852–18860, 2025
2025
-
[24]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[26]
Hashmat Shadab Malik, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar, Fahad Khan, and Salman Khan. Robust-llava: On the effectiveness of large-scale robust image encoders for multi-modal large language models.arXiv preprint arXiv:2502.01576, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, and Carl V ondrick. Understanding zero-shot adversarial robustness for large-scale models.arXiv preprint arXiv:2212.07016, 2022
-
[28]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
2008
-
[29]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
2012
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[31]
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models.arXiv preprint arXiv:2402.12336, 2024
-
[32]
R-tpt: Improving adversarial robustness of vision-language models through test-time prompt tuning
Lijun Sheng, Jian Liang, Zilei Wang, and Ran He. R-tpt: Improving adversarial robustness of vision-language models through test-time prompt tuning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29958–29967, 2025
2025
-
[33]
Test-time prompt tuning for zero-shot generalization in vision-language models
Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test-time prompt tuning for zero-shot generalization in vision-language models. Advances in Neural Information Processing Systems, 35:14274–14289, 2022. 11
2022
-
[34]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[35]
Pre-trained model guided fine-tuning for zero-shot adversarial robustness
Sibo Wang, Jie Zhang, Zheng Yuan, and Shiguang Shan. Pre-trained model guided fine-tuning for zero-shot adversarial robustness. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24502–24511, 2024
2024
-
[36]
Zhengbo Wang, Jian Liang, Ran He, Nan Xu, Zilei Wang, and Tieniu Tan. Improving zero-shot generalization for clip with synthesized prompts.arXiv preprint arXiv:2307.07397, 2023
-
[37]
Sun database: Large-scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010
2010
-
[38]
Clip is strong enough to fight back: Test-time counterattacks towards zero-shot adversarial robustness of clip
Songlong Xing, Zhengyu Zhao, and Nicu Sebe. Clip is strong enough to fight back: Test-time counterattacks towards zero-shot adversarial robustness of clip. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15172–15182, 2025
2025
-
[39]
Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021
-
[40]
Hee Suk Yoon, Eunseop Yoon, Joshua Tian Jin Tee, Mark Hasegawa-Johnson, Yingzhen Li, and Chang D Yoo. C-tpt: Calibrated test-time prompt tuning for vision-language models via text feature dispersion.arXiv preprint arXiv:2403.14119, 2024
-
[41]
Maxime Zanella and Ismail Ben Ayed. On the test-time zero-shot generalization of vision- language models: Do we really need prompt learning? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23783–23793, 2024
2024
-
[42]
A simple framework for open-vocabulary segmentation and detection
Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianwei Yang, and Lei Zhang. A simple framework for open-vocabulary segmentation and detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1020–1031, 2023
2023
-
[43]
Adversarial prompt tuning for vision-language models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, and Jitao Sang. Adversarial prompt tuning for vision-language models. InEuropean conference on computer vision, pages 56–72. Springer, 2024
2024
-
[44]
A multimodal biomedical foundation model trained from fifteen million image–text pairs.NEJM AI, 2(1):AIoa2400640, 2025
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. A multimodal biomedical foundation model trained from fifteen million image–text pairs.NEJM AI, 2(1):AIoa2400640, 2025
2025
-
[45]
Extract free dense labels from clip
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. InEuropean conference on computer vision, pages 696–712. Springer, 2022
2022
-
[46]
Conditional prompt learning for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16816–16825, 2022
2022
-
[47]
Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
2022
-
[48]
Yiwei Zhou, Xiaobo Xia, Zhiwei Lin, Bo Han, and Tongliang Liu. Few-shot adversarial prompt learning on vision-language models.Advances in Neural Information Processing Systems, 37: 3122–3156, 2024. 12 A Inference Pipeline A.1 Closed-Loop Inference with Multi-View Aggregation Algorithm 1CLBP Inference with Closed Loop and Multi-View Aggregation Require: Da...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.