PathWISE: Multi-Agent Cancer Pathway Triaging Ontology Learning from Clinical Flowcharts
Pith reviewed 2026-06-29 22:12 UTC · model grok-4.3
The pith
PathWISE converts clinical flowcharts for cancer pathways into executable CQL libraries using LLM agents plus deterministic verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PathWISE transforms non-computable clinical flowcharts into validated, executable HL7 Clinical Quality Language libraries deployable as FHIR CDS Hooks services by confining non-deterministic LLM inference to knowledge extraction while deterministic graph mathematics and a standard compiler underpin every verification step, achieving 100 percent syntactic compilation success and zero hallucinated terminology codes on five cancer pathways.
What carries the argument
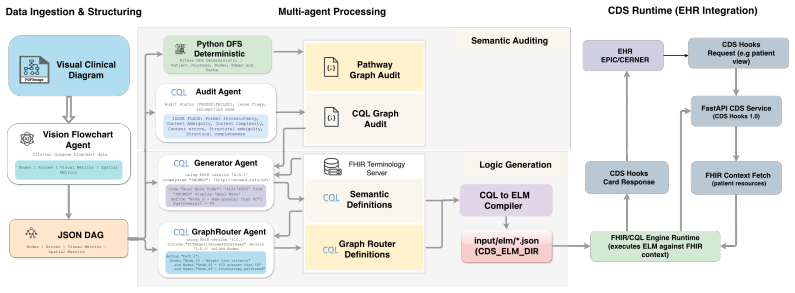
The five-phase pipeline that uses four LLM agents to build and audit a typed directed graph from flowchart topology, then relies on deterministic depth-first search and the official Java CQL-to-ELM compiler for verification and CQL generation.
If this is right
- The produced CQL libraries can be deployed directly as FHIR CDS Hooks services for real-time clinical decision support.
- Routing logic covers every enumerated patient journey through the pathway.
- UNCOMPUTABLE nodes receive false placeholders that preserve compilability while surfacing gaps for clinical review.
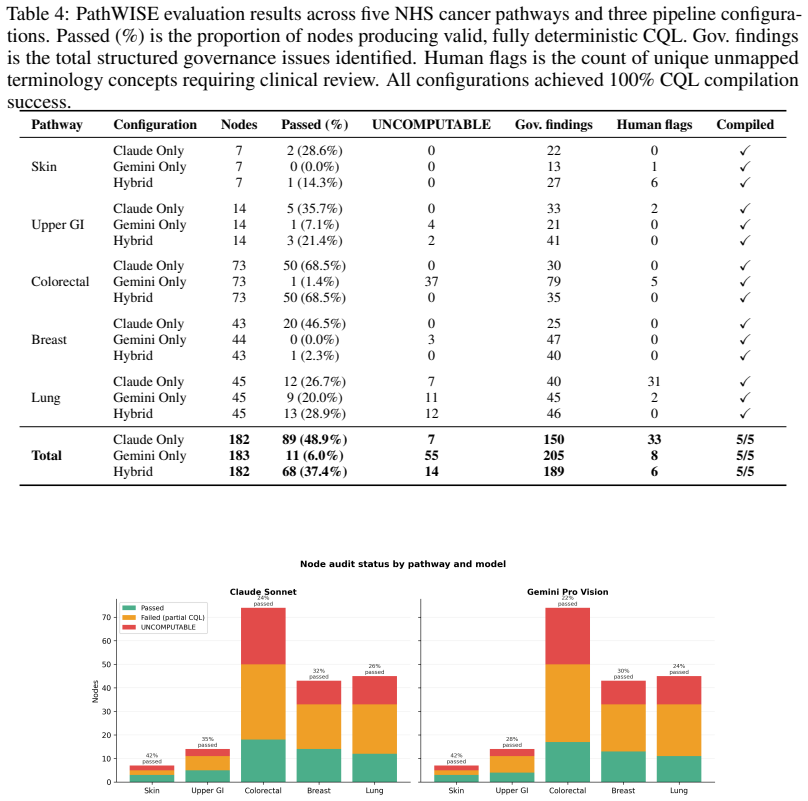
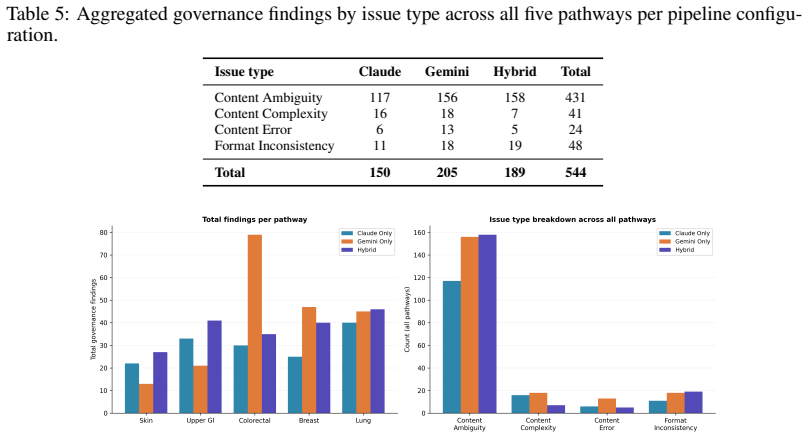
- Up to 544 structured governance findings across four issue categories are identified for human review.
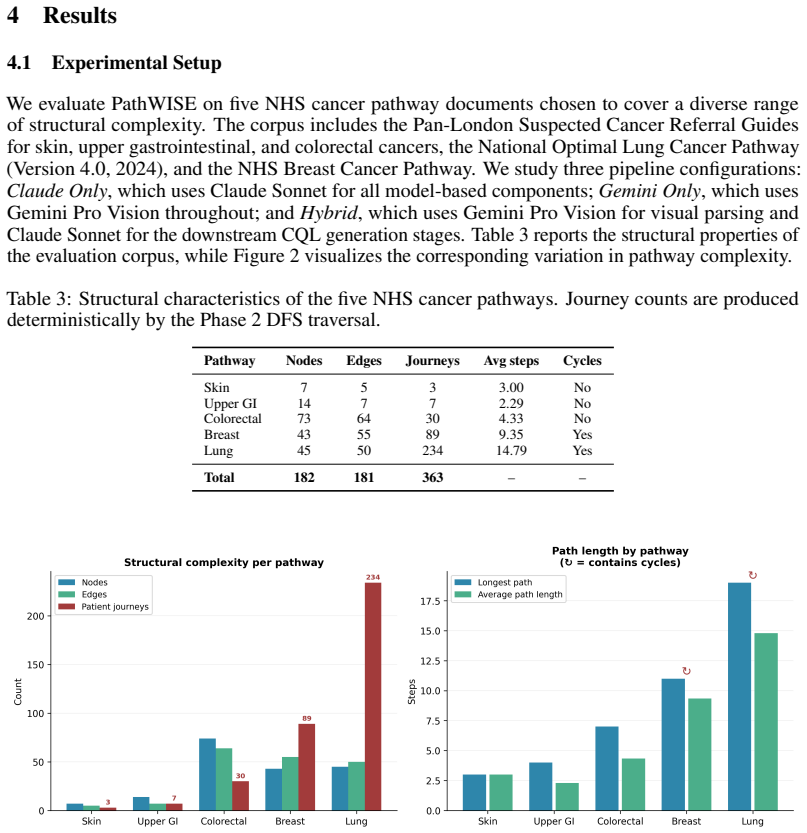
- The method scales to pathways containing as many as 183 nodes under the hybrid configuration.
Where Pith is reading between the lines
- The same separation of LLM extraction from deterministic verification could be applied to flowcharts in non-cancer clinical domains.
- Hospitals could use the audit outputs to standardize pathway interpretation across different sites.
- The generated libraries could support automated consistency checks when pathways are updated.
- Integration with live electronic health record data would allow measurement of how often the CQL logic aligns with actual clinician decisions.
Load-bearing premise
The LLM agents can extract flowchart structure, arrow direction, colour coding and font weight into a typed directed graph without introducing errors that the subsequent deterministic audit cannot detect.
What would settle it
Execute the generated CQL on sample patient cases drawn from one of the five pathways and observe whether the triage decisions match the decisions prescribed by the original flowchart.
Figures
read the original abstract
Clinical pathways are disseminated as visual flowcharts where spatial topology, arrow direction, colour coding, and font weight encode critical triage logic that remains inaccessible to computational systems. We present PathWISE, a five-phase pipeline combining four LLM-based agents with a deterministic depth-first search auditor and a Java compiler critic, transforming these non-computable artefacts into validated, executable HL7 Clinical Quality Language (CQL) libraries deployable as FHIR CDS Hooks services. Purpose-built agents extract flowchart structure into a typed directed graph, perform deterministic path enumeration, conduct a structured semantic audit of every node's computability, generate terminology-constrained CQL definitions verified by the official Java CQL-to-ELM compiler, and produce routing logic covering 100% of enumerated patient journeys. Demonstrated across five UK NHS cancer pathways (colorectal, lung, skin, upper GI, and breast), PathWISE audits up to 183 nodes (182 under the Hybrid configuration), identifies 544 structured governance findings across four issue categories, achieves 100% syntactic compilation success, with UNCOMPUTABLE nodes receiving false placeholders that preserve compilability while surfacing governance gaps for clinical review, and produces zero hallucinated terminology codes for dictionary-covered concepts. Critically, PathWISE confines non-deterministic LLM inference to knowledge extraction while deterministic graph mathematics and a standard compiler underpin every verification step.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PathWISE, a five-phase pipeline that deploys four LLM-based agents to extract typed directed graphs from visual clinical pathway flowcharts (capturing topology, arrow direction, colour, and font weight), followed by deterministic DFS path enumeration, semantic computability audit, CQL generation, and Java compiler verification. It is demonstrated on five UK NHS cancer pathways, reporting up to 183 nodes, 544 governance findings, 100% syntactic CQL compilation success, and zero hallucinated terminology codes, with non-determinism confined to the extraction phase.
Significance. If the extraction step proves faithful, the work would provide a practical bridge from non-computable visual guidelines to deployable FHIR CDS Hooks services, with credit due for the hybrid design that isolates LLM inference and relies on external deterministic graph enumeration plus the official CQL-to-ELM compiler for verification. The absence of any quantitative validation of structural fidelity, however, confines the demonstrated results to syntactic well-formedness rather than correctness relative to the source artefacts.
major comments (2)
- [Abstract] Abstract: the central claim that PathWISE produces 'validated, executable' CQL libraries whose routing logic covers '100% of enumerated patient journeys' rests on the unverified assumption that the four LLM agents faithfully encode flowchart topology, arrow directions, colour coding and font weight into the typed directed graph; the subsequent deterministic steps (DFS, audit, compiler) inherit any extraction errors, yet no precision/recall, inter-rater agreement, or expert side-by-side comparison against human gold-standard annotations is reported for the five pathways.
- [Abstract] Abstract (five-phase pipeline description): the reported 544 governance findings and 100% compilation success only confirm that generated CQL is syntactically valid and uses dictionary terms; they provide no evidence that the enumerated journeys or node computability classifications match the original visual logic, leaving the weakest assumption (reliable LLM graph extraction) untested by any independent structural validation metric.
minor comments (2)
- [Abstract] The abstract would benefit from an explicit statement of the four agents' individual roles and the precise graph schema (node/edge types) they produce.
- [Abstract] No mention is made of how flowchart images are pre-processed or whether OCR or vision-model limitations affect extraction of colour and font attributes.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying the distinction between syntactic validation and structural fidelity of the extraction step. We address each major comment below and propose targeted revisions to clarify the scope of our claims without overstating the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PathWISE produces 'validated, executable' CQL libraries whose routing logic covers '100% of enumerated patient journeys' rests on the unverified assumption that the four LLM agents faithfully encode flowchart topology, arrow directions, colour coding and font weight into the typed directed graph; the subsequent deterministic steps (DFS, audit, compiler) inherit any extraction errors, yet no precision/recall, inter-rater agreement, or expert side-by-side comparison against human gold-standard annotations is reported for the five pathways.
Authors: We agree that no quantitative structural validation metrics (precision/recall, inter-rater agreement, or expert gold-standard comparison) are reported for the LLM extraction phase. The manuscript's use of 'validated' and '100% of enumerated patient journeys' is scoped to the deterministic downstream stages: successful CQL-to-ELM compilation, zero hallucinated codes, and full coverage of paths within the extracted graph. We will revise the abstract to explicitly qualify these terms, add a limitations paragraph stating the absence of extraction fidelity metrics, and note that future work will include expert annotation studies. This does not alter the reported results on compilation success or governance findings. revision: yes
-
Referee: [Abstract] Abstract (five-phase pipeline description): the reported 544 governance findings and 100% compilation success only confirm that generated CQL is syntactically valid and uses dictionary terms; they provide no evidence that the enumerated journeys or node computability classifications match the original visual logic, leaving the weakest assumption (reliable LLM graph extraction) untested by any independent structural validation metric.
Authors: The referee correctly observes that the 544 governance findings and 100% compilation success address only syntactic validity and terminology compliance, not fidelity of the extracted graph to the source flowcharts. The paper does not claim or demonstrate that node classifications or journeys match the original visual logic beyond the extraction step. We will revise the abstract and methods to make this scope explicit and add a limitations section acknowledging the lack of independent structural validation. No changes are needed to the reported experimental outcomes. revision: yes
Circularity Check
No circularity; external deterministic verification anchors all claims.
full rationale
The paper presents a five-phase pipeline in which LLM agents perform initial extraction into a typed directed graph, after which all verification (DFS path enumeration, semantic audit, CQL generation, and Java CQL-to-ELM compiler checks) is performed by deterministic, externally defined algorithms and a standard compiler. No equations, fitted parameters, predictions, or self-citations appear in the derivation chain. The reported outcomes (100% syntactic compilation, zero hallucinated codes) are produced by these independent tools rather than by quantities defined in terms of the authors' own choices. The absence of any load-bearing self-referential step or renaming of known results yields a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical pathways disseminated as visual flowcharts can be represented as typed directed graphs whose spatial topology, arrow direction, colour coding and font weight encode computable triage logic.
Reference graph
Works this paper leans on
-
[1]
Abioye, S
S. Abioye, S. Ashraf, J. Qadir, A. Byfield, A. Jose, W. Poulett, B. Wallace, A. Butt, C. Forde, M. Mottershead, and S. Fallis. Raptor: Generative ai for parsing colorectal cancer referrals to streamline faster diagnostic standard pathways. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2025, Lecture Notes...
2025
- [2]
-
[3]
DUBLIN: Document understanding by language-image network
Kriti Aggarwal, Aditi Khandelwal, Kumar Tanmay, Owais Khan, and Qiang Liu. DUBLIN: Document understanding by language-image network. arXiv preprint arXiv:2305.14218, 2023
-
[4]
Ontologies as the semantic bridge between artificial intelligence and healthcare.Frontiers in Digital Health, 7:1668385, 2025
Radha Ambalavanan, R Sterling Snead, Julia Marczika, Gideon Towett, Alex Malioukis, and Mercy Mbogori-Kairichi. Ontologies as the semantic bridge between artificial intelligence and healthcare.Frontiers in Digital Health, 7:1668385, 2025
2025
-
[5]
Starflow: Generating structured workflow outputs from sketch images
Patrice Bechard, Chao Wang, Amirhossein Abaskohi, Juan A Rodriguez, Christopher Pal, David Vazquez, Spandana Gella, Sai Rajeswar, and Perouz Taslakian. Starflow: Generating structured workflow outputs from sketch images. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), p...
2026
-
[6]
Toward cross-platform electronic health record-driven phenotyping using clinical quality language.Learning Health Systems, 4(4):e10233, 2020
Pascal S Brandt, Richard C Kiefer, Jennifer A Pacheco, Prakash Adekkanattu, Evan T Sholle, Faraz S Ahmad, Jie Xu, Zhenxing Xu, Jessica S Ancker, Fei Wang, et al. Toward cross-platform electronic health record-driven phenotyping using clinical quality language.Learning Health Systems, 4(4):e10233, 2020
2020
-
[7]
Text2onto: A framework for ontology learning and data-driven change discovery
Philipp Cimiano and Johanna Völker. Text2onto: A framework for ontology learning and data-driven change discovery. InInternational conference on application of natural language to information systems, pages 227–238. Springer, 2005
2005
-
[8]
Evaluation of large language models with clinical guidance for vetting outpatient magnetic resonance imaging lumbar spine referrals
William Clackett, Hatim Alsusa, Hannah Watson, Antanas Kascenas, David Scott, Avinash K Kanodia, Oliver T Barry, and Alison Q O’Neil. Evaluation of large language models with clinical guidance for vetting outpatient magnetic resonance imaging lumbar spine referrals. Scottish Medical Journal, page 00369330261441582, 2026
2026
-
[9]
Draw with thought: Unleashing multimodal reasoning for scientific diagram generation
Zhiqing Cui, Jiahao Yuan, Hanqing Wang, Yanshu Li, Chenxu Du, and Zhenglong Ding. Draw with thought: Unleashing multimodal reasoning for scientific diagram generation. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 5050–5059, 2025
2025
-
[10]
Pritam Deka and Barry Devereux. Flowchart2mermaid: A vision-language model powered system for converting flowcharts into editable diagram code.arXiv preprint arXiv:2512.02170, 2025. 11
-
[11]
A pharmacogenomics clinical decision support service based on fhir and cds hooks.Methods of information in medicine, 57(S 02):e115–e123, 2018
RH Dolin, A Boxwala, and J Shalaby. A pharmacogenomics clinical decision support service based on fhir and cds hooks.Methods of information in medicine, 57(S 02):e115–e123, 2018
2018
-
[12]
Mert Gencturk, Gokce B Laleci Erturkmen, A Emre Akpinar, Omid Pournik, Bilal Ahmad, Theodoros N Arvanitis, Wolfgang Schmidt-Barzynski, Tim Robbins, Ruben Alcantud Corcoles, and Pedro Abizanda. Transforming evidence-based clinical guidelines into implementable clinical decision support services: the carepath study for multimorbidity management.Frontiers in...
2024
-
[13]
Hybrid classfication for heart disease prediction using artificial intelligence
Jasmeen Gill et al. Hybrid classfication for heart disease prediction using artificial intelligence. In2021 5th international conference on computing methodologies and communication (ICCMC), pages 1779–1785. IEEE, 2021
2021
-
[14]
Standards-based interoperability for clinical decision support systems.Studies in Health Technology and Informatics, 327:173–177, 2025
Moritz Grob, Leonhard Hauptfeld, Andrea Rappelsberger, and Klaus-Peter Adlassnig. Standards-based interoperability for clinical decision support systems.Studies in Health Technology and Informatics, 327:173–177, 2025
2025
-
[15]
Comprehensive modeling and question answering of cancer clinical practice guidelines using llms
Bhumika Gupta, Pralaypati Ta, Keerthi Ram, and Mohanasankar Sivaprakasam. Comprehensive modeling and question answering of cancer clinical practice guidelines using llms. In2024 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), pages 1–8. IEEE, 2024
2024
-
[16]
The effect of local hospital waiting times on gp referrals for suspected cancer.PloS one, 19(5):e0294061, 2024
Helen Hayes, Rachel Meacock, Jonathan Stokes, and Matt Sutton. The effect of local hospital waiting times on gp referrals for suspected cancer.PloS one, 19(5):e0294061, 2024
2024
-
[17]
Early findings on the use of clinical pathways for management of unwarranted variation in cancer care.American Journal of Medical Quality, 37(2):103–110, 2022
David M Jackman, Emily Foster, Joanna M Hamilton, Carole Tremonti, Craig A Bunnell, Sherri O Stuver, and Joseph O Jacobson. Early findings on the use of clinical pathways for management of unwarranted variation in cancer care.American Journal of Medical Quality, 37(2):103–110, 2022
2022
-
[18]
Robosurg: Re- silience of vision-language models against adversarial attacks in robotic surgery
Ufaq Khan, Umair Nawaz, Mustaqeem Khan, and Abdulmotaleb El Saddik. Robosurg: Re- silience of vision-language models against adversarial attacks in robotic surgery. In2025 International Conference on Digital Image Computing: Techniques and Applications (DICTA), pages 1–8. IEEE, 2025
2025
-
[19]
Ufaq Khan, Umair Nawaz, LDMSS Teja, Numaan Saeed, Muhammad Bilal, Yutong Xie, Mohammad Yaqub, and Muhammad Haris Khan. Medobvious: Exposing the medical moravec’s paradox in vlms via clinical triage.arXiv preprint arXiv:2603.23501, 2026
-
[20]
K. Lee, M. Joshi, I. R. Turc, H. Hu, F. Liu, J. M. Eisenschlos, U. Khandelwal, P. Shaw, M. W. Chang, and K. Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding. InInternational Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pages 18893–18912. PMLR, 2023
2023
-
[21]
A con- figurable method for clinical quality measurement through electronic health records based on openehr and cql.BMC Medical Informatics and Decision Making, 22(1):37, 2022
Mengyang Li, Hailing Cai, Yunlong Zhi, Zehai Fu, Huilong Duan, and Xudong Lu. A con- figurable method for clinical quality measurement through electronic health records based on openehr and cql.BMC Medical Informatics and Decision Making, 22(1):37, 2022
2022
- [22]
-
[23]
EvoMDT: A self-evolving multi-agent system for structured clinical decision-making in multi-cancer.npj Digital Medicine, 2026
Qicai Liu, Zhichao Hu, Tao Huang, Yupeng Niu, and Xinche Zhang. EvoMDT: A self-evolving multi-agent system for structured clinical decision-making in multi-cancer.npj Digital Medicine, 2026
2026
-
[24]
Using cds hooks to increase smart on fhir app utilization: a cluster-randomized trial.Journal of the American Medical Informatics Association, 29(9):1461–1470, 2022
Keaton L Morgan, Polina V Kukhareva, Phillip B Warner, Jonah Wilkof, Meir Snyder, Devin Horton, Troy Madsen, Joseph Habboushe, and Kensaku Kawamoto. Using cds hooks to increase smart on fhir app utilization: a cluster-randomized trial.Journal of the American Medical Informatics Association, 29(9):1461–1470, 2022
2022
-
[25]
Nabelsi and V
V . Nabelsi and V . Plouffe. Enhancing care coordination in oncology through a digital health solution.JMIR Formative Research, 8:e60222, 2024. 12
2024
-
[26]
Generative ai and large language models in health care: pathways to implementation.NPJ Digital Medicine, 7(1):62, 2024
Marium M Raza, Kaushik P Venkatesh, and Joseph C Kvedar. Generative ai and large language models in health care: pathways to implementation.NPJ Digital Medicine, 7(1):62, 2024
2024
-
[27]
Saban, Y
M. Saban, Y . Alon, O. Luxenburg, C. Singer, M. Hierath, A. Karoussou Schreiner, B. Brkljaˇci´c, and J. Sosna. Comparison of CT referral justification using clinical decision support and large language models in a large European cohort.European Radiology, 35(10):6150–6159, 2025
2025
-
[28]
RE-MCDF: Closed-Loop Multi-Expert LLM Reasoning for Knowledge-Grounded Clinical Diagnosis
Shaowei Shen, Xiaohong Yang, Jie Yang, Lianfen Huang, and Yongcai Zhang. RE- MCDF: Closed-loop multi-expert LLM reasoning for knowledge-grounded clinical diagnosis. arXiv:2602.01297, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Lok Santhoshkumar Surisetty. End-to-end clinical data interoperability: A practical implemen- tation blueprint using hl7, fhir, ccd, and ehr integration standards.International Journal of Research Publications in Engineering, Technology and Management (IJRPETM), 9(1):21–29, 2026
2026
-
[30]
Henrik Thiess, Guilherme Del Fiol, Daniel C Malone, Ryan Cornia, Max Sibilla, Bryn Rhodes, Richard D Boyce, Kensaku Kawamoto, and Thomas Reese. Coordinated use of health level 7 standards to support clinical decision support: Case study with shared decision making and drug-drug interactions.International journal of medical informatics, 162:104749, 2022
2022
-
[31]
Computer science diagram understanding with topology parsing.ACM Transactions on Knowledge Discovery from Data (TKDD), 16(6):1–20, 2022
Shaowei Wang, Lingling Zhang, Xuan Luo, Yi Yang, Xin Hu, Tao Qin, and Jun Liu. Computer science diagram understanding with topology parsing.ACM Transactions on Knowledge Discovery from Data (TKDD), 16(6):1–20, 2022
2022
-
[32]
Beyond end-to-end vlms: Leveraging intermediate text representations for superior flowchart understanding
Junyi Ye, Ankan Dash, Wenpeng Yin, and Guiling Wang. Beyond end-to-end vlms: Leveraging intermediate text representations for superior flowchart understanding. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3534–3548, 2025
2025
-
[33]
P. Yu, H. Xu, X. Hu, and C. Deng. Leveraging generative AI and large language models: A comprehensive roadmap for healthcare integration.Healthcare, 11(20):2776, 2023
2023
-
[34]
Y . Zhan, X. Wu, T. Lin, Y . Bao, X. Wang, W. Cheng, H. Chen, F. Qin, and Z. Zhu. MedCollab: Causal-driven multi-agent collaboration for full-cycle clinical diagnosis via IBIS-structured argumentation.arXiv preprint arXiv:2603.01131, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Zhang, G
J. Zhang, G. Zheng, H. Lv, L. Luo, G. Ma, Z. Lin, X. Chen, and Y . Tan. D2KGMed: Dynamic diagnostic knowledge graphs for medical diagnosis prediction. In2025 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2025. 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.