F-RNG: Feed-Forward Relightable Neural Gaussians
Pith reviewed 2026-06-29 19:17 UTC · model grok-4.3
The pith
F-RNG produces relightable 3D Gaussian assets directly from sparse views by distilling intrinsic decomposition priors into an unmodified large reconstruction model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
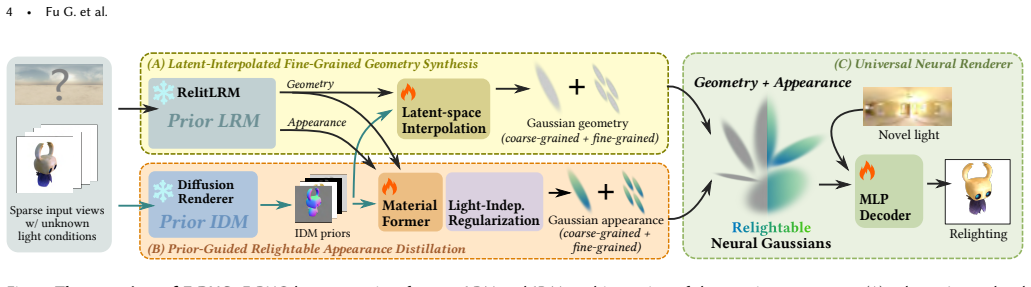
F-RNG is a feed-forward framework that directly generates relightable 3DGS assets from sparse-view inputs. It augments an existing large reconstruction model with latent-interpolated fine-grained geometry synthesis, performs prior-guided relightable appearance distillation that incorporates priors from an intrinsic decomposition model, and applies a universal neural renderer for flexible high-fidelity relighting. The framework requires neither re-training nor fine-tuning of the underlying large reconstruction model and therefore can automatically benefit from future improvements in those models.
What carries the argument
Prior-guided relightable appearance distillation, which transfers lighting-separated priors from an intrinsic decomposition model into the unmodified large reconstruction model to produce relightable neural Gaussian representations.
If this is right
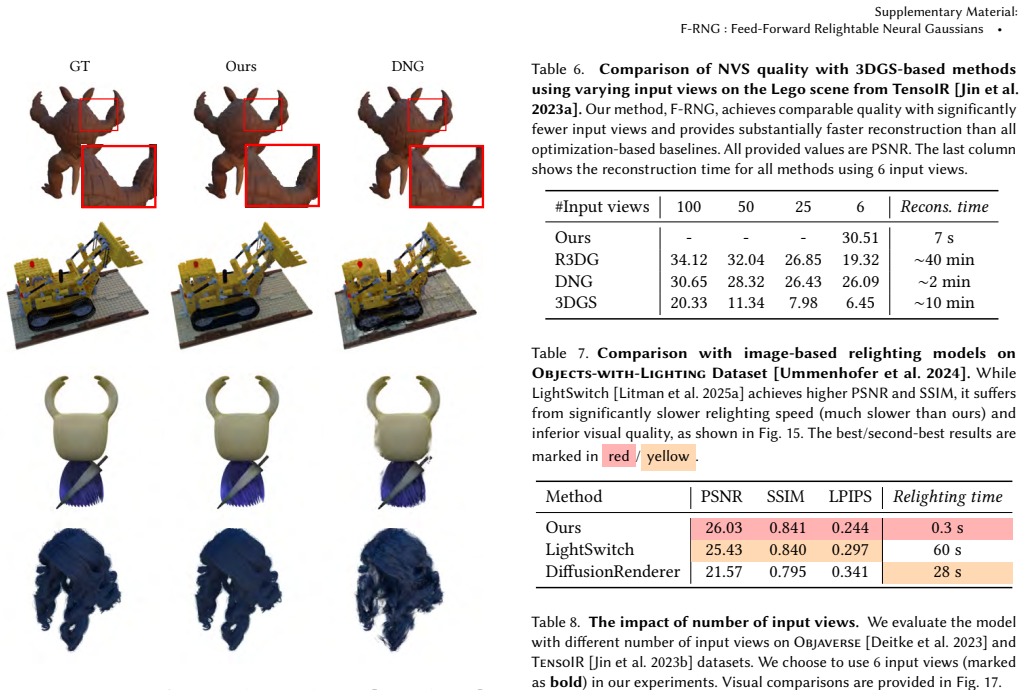
- Relighting inference runs approximately 25 times faster than the prior state-of-the-art LRM-based relighting approach.
- Rendered quality improves by roughly 2 dB compared with the same baseline.
- The method works with only small additional networks trained on modest data and compute, avoiding repeated large-model inference under varying lights.
- No modification or retraining of the base large reconstruction model is required, so any future advance in those models is inherited automatically.
- The approach supports flexible relighting through a universal neural renderer without changing the underlying Gaussian representation.
Where Pith is reading between the lines
- The same distillation pattern could be tested on other feed-forward 3D reconstruction backbones beyond the specific LRM used here.
- If the intrinsic priors prove stable across lighting domains, the method might extend to outdoor or dynamic scenes where current per-scene methods struggle.
- Real-time applications such as AR preview could become feasible once the small distillation networks are quantized or distilled further.
- The separation of geometry synthesis and appearance distillation steps may allow independent upgrades of either component without touching the other.
Load-bearing premise
Priors extracted from an intrinsic decomposition model can be distilled into an unmodified large reconstruction model to yield accurate relightable representations from sparse inputs.
What would settle it
A controlled ablation that removes the intrinsic decomposition priors and measures whether relighting PSNR on held-out scenes falls below the reported 2 dB gain over the baseline LRM method.
Figures














read the original abstract
Capturing relightable 3D assets from real-world objects is a widely researched problem. Several per-scene optimization-based methods, based on 3D Gaussian splatting (3DGS), support relighting; however, they usually require dense input views, and their overfitting nature makes it difficult to generalize across scenes. Unlike per-scene optimization methods, generalized feed-forward models can directly reconstruct Gaussians from sparse input views. However, the resulting assets have baked-in illumination and cannot be easily used for relighting. In this paper, we present F-RNG, a feed-forward framework that directly generates relightable 3DGS assets from sparse-view inputs. Training such a model from scratch can require massive data and computing resources, and it is especially challenging to generate relightable assets in a feed-forward manner with acceptable cost. We develop F-RNG upon an existing large reconstruction model (LRM) to extract relightable representations, while also utilizing priors from an intrinsic decomposition model (IDM). Specifically, we first introduce a latent-interpolated fine-grained geometry synthesis to enhance the LRM's geometry representation. Second, we propose a prior-guided relightable appearance distillation to extract relightable neural representations by incorporating IDM priors. Finally, a universal neural renderer enables flexible and high-fidelity relighting. F-RNG requires neither re-training nor fine-tuning of the underlying LRMs, thus can automatically benefit from better LRMs and IDMs in the future. With only small networks that can be trained with affordable data and computational resources, F-RNG avoids the repetitive inference of large models under different light conditions. By comparison to the state-of-the-art LRM-based relighting method, F-RNG achieves ~25x faster relighting, as well as superior quality (~+2.0 dB).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents F-RNG, a feed-forward framework for generating relightable 3D Gaussian splatting (3DGS) assets directly from sparse-view inputs. It builds on an unmodified existing large reconstruction model (LRM) by incorporating priors from an intrinsic decomposition model (IDM) via three components: latent-interpolated fine-grained geometry synthesis, prior-guided relightable appearance distillation, and a universal neural renderer. The approach requires no re-training or fine-tuning of the LRM and claims to deliver ~25x faster relighting together with ~+2.0 dB quality improvement relative to the current state-of-the-art LRM-based relighting baseline.
Significance. If the reported speed and quality gains are substantiated, the work would be a meaningful contribution to feed-forward 3D reconstruction and relighting. The modular construction that leaves the underlying LRM untouched is a clear strength, as it permits automatic uptake of future improvements in both LRMs and IDMs. The reliance on small, affordably trained networks rather than repeated large-model inference under varying illumination is also practically valuable for scene generalization from sparse inputs.
major comments (1)
- [Experiments] Experiments section: the headline claims of ~25x speedup and +2.0 dB PSNR improvement are presented without accompanying tables that list per-scene timings, exact baseline implementations, dataset statistics, or error bars; these omissions make it impossible to verify that the gains are load-bearing for the central feed-forward claim.
minor comments (2)
- [§3.1] §3.1: the description of latent interpolation would benefit from an explicit equation or pseudocode block showing how the interpolated latent codes are formed from the LRM encoder outputs.
- [Figure 4] Figure 4 caption: the lighting conditions used for the qualitative comparisons are not stated, hindering direct visual assessment of relighting fidelity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the modular design and practical advantages of F-RNG. We address the single major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claims of ~25x speedup and +2.0 dB PSNR improvement are presented without accompanying tables that list per-scene timings, exact baseline implementations, dataset statistics, or error bars; these omissions make it impossible to verify that the gains are load-bearing for the central feed-forward claim.
Authors: We agree that the current presentation of the headline claims would benefit from additional supporting tables. In the revised manuscript we will add a dedicated table (and corresponding supplementary material) that reports per-scene timings, per-scene PSNR values with standard deviations, exact baseline implementations (including model versions and inference settings), and dataset statistics (number of scenes, view counts, lighting conditions). These additions will allow direct verification of the reported ~25x speedup and +2.0 dB average improvement. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents a modular feed-forward architecture that composes an unmodified LRM with IDM priors and small trainable networks for geometry and appearance. No equations, derivations, or first-principles predictions appear in the abstract or described method. Performance claims (~25x speed, +2 dB) are stated as empirical outcomes of this construction rather than results derived from fitted parameters or self-referential definitions. No self-citation chains, ansatzes smuggled via citation, or renamings of known results are load-bearing for the central claims. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5470–5479. Sean Bell, Kavita Bala, and Noah Snavely. 2014. Intrinsic images in the wild.ACM Transactions on Graphics (TOG)33, 4 (2014), 1–12. Sai Bi, Zexiang Xu, Pratul Srinivasan, Ben Mildenhall, Kalyan Sunkava...
2014
-
[2]
InSIGGRAPH Asia 2024 Conference Papers
GS 3: Efficient Relighting with Triple Gaussian Splatting. InSIGGRAPH Asia 2024 Conference Papers. Mark Boss, Varun Jampani, Raphael Braun, Ce Liu, Jonathan Barron, and Hendrik Lensch. 2021. Neural-pil: Neural pre-integrated lighting for reflectance decomposi- tion.Advances in Neural Information Processing Systems34 (2021), 10691–10704. Chris Careaga and ...
-
[3]
InACM SIGGRAPH 2024 Conference Papers
High-quality surface reconstruction using gaussian surfels. InACM SIGGRAPH 2024 Conference Papers. 1–11. Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. 2023. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on c...
-
[4]
InComputer Graphics Forum, Vol
A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis. InComputer Graphics Forum, Vol. 43. Wiley Online Library, e15147. Peiran Ren, Yue Dong, Stephen Lin, Xin Tong, and Baining Guo. 2015. Image based relighting using neural networks.ACM Transactions on Graphics (ToG)34, 4 (2015), 1–12. Ruoxi Shi, Xinyue Wei, Cheng Wang, and...
-
[5]
InACM SIGGRAPH 2024 Conference Papers(Denver, CO, USA)(SIGGRAPH ’24)
Relighting neural radiance fields with shadow and highlight hints. InACM SIGGRAPH 2023 Conference Proceedings. 1–11. Chong Zeng, Yue Dong, Pieter Peers, Youkang Kong, Hongzhi Wu, and Xin Tong. 2024b. DiLightNet: Fine-grained lighting control for diffusion-based image generation. In ACM SIGGRAPH 2024 Conference Papers. 1–12. Zheng Zeng, Valentin Deschaintr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.