Trustworthy Software Project Generation : a Case Study with an Interactive Theorem Prover
Pith reviewed 2026-06-29 20:15 UTC · model grok-4.3
The pith
LLM agent uses Rocq to autonomously generate a full verified RISC-V RV32I interpreter project with no human intervention after requirements are given.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
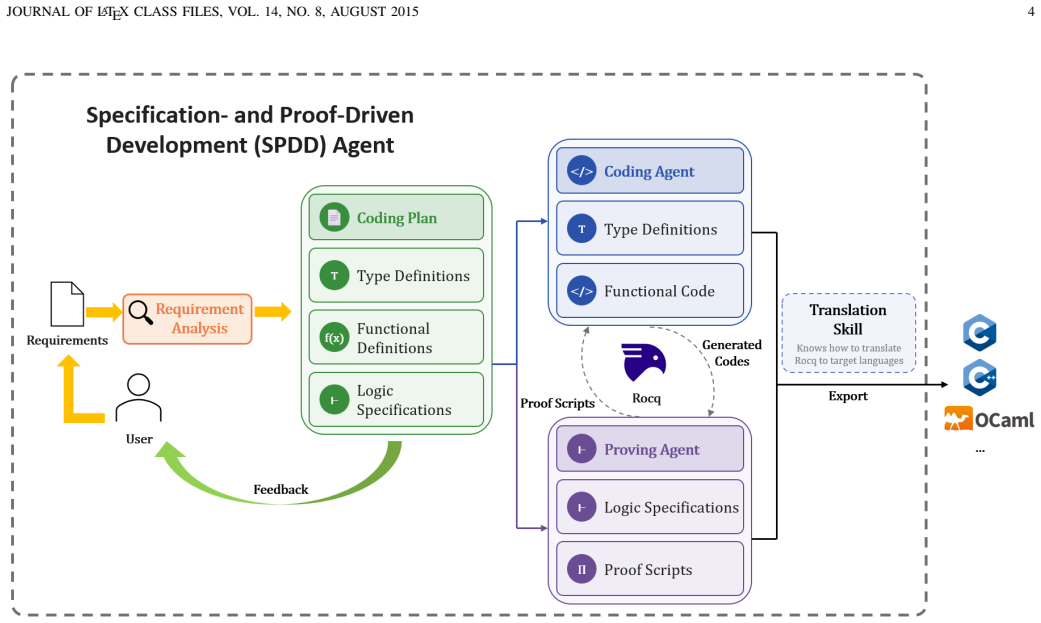
With Rocq as the backend, the agent completes the project within 30 minutes, producing 1,859 lines of verified Rocq and extracting 2,848 lines of C++. The resulting interpreter passes all 265 LLM-generated tests covering the 47 instructions and exhibits zero crashes and zero hangs during 12 hours of AFL++ fuzzing. Under the same configuration, a Dafny-based backend fails to complete verification. The observation is that Rocq exposes a concrete proof state when a proof attempt fails, giving the agent actionable feedback for repair.
What carries the argument
Separation of effectful code (implemented directly in the target language) from pure total functions (proved in the ITP and extracted for integration), together with Rocq's exposure of concrete proof state for autonomous LLM-driven repair.
If this is right
- Full instruction-set interpreters can be generated and verified automatically in under an hour.
- ITP backends outperform Dafny-style systems for LLM synthesis because they supply explicit proof states for repair.
- The generated project meets both functional tests and long-running fuzzing with no observed failures.
- Synthesis, proof repair, extraction, and integration can all proceed without intervention once requirements are supplied.
Where Pith is reading between the lines
- The same separation of effects and pure logic could be applied to other mixed systems such as device drivers or protocol stacks.
- Agents might scale to larger verified components if the proof-state feedback loop is retained across multiple extraction targets.
- The results point toward testing whether the approach succeeds on other base architectures beyond RV32I.
Load-bearing premise
The LLM agent can autonomously interpret Rocq's concrete proof state to repair failed proofs without human intervention, and separating effectful code from pure total functions suffices for a working integrated project.
What would settle it
A repeated trial in which the agent receives the same RISC-V RV32I requirements, runs under identical conditions, yet either fails to finish verification or produces extracted code that fails the test suite or shows crashes or hangs in fuzzing.
Figures





read the original abstract
Generating code from natural-language requirements has become a primary route for LLM-assisted software development. Although LLMs can successfully complete small programming tasks, generating an entire complex project remains unreliable because subtle errors may survive compilation and testing. Verified programming can reduce this risk by requiring generated implementations to satisfy machine-checked specifications. Existing explorations mostly target verification-oriented languages and toolchains such as Dafny and Frama-C, but directly generating project-scale verified code with these systems remains difficult. This paper studies whether interactive theorem provers (ITPs) can support large-scale software generation. Because ITPs handle pure total functions but not effects such as I/O, our agent separates effectful code from pure logic: it implements the effects in the target language, proves the pure logic in an ITP, and extracts it for integration into the final project. We study this route through the fully automatic development of a CPU interpreter for all 47 instructions of the unprivileged RISC-V RV32I base: after the requirements are supplied, no human intervenes in synthesis, proof repair, extraction, or integration. With Rocq as the backend, the agent completes the project within 30 minutes, producing 1,859 lines of verified Rocq and extracting 2,848 lines of C++. The resulting interpreter passes all 265 LLM-generated tests covering the 47 instructions and exhibits zero crashes and zero hangs during 12 hours of AFL++ fuzzing. Under the same configuration, a Dafny-based backend fails to complete verification. Our observation is that Rocq exposes a concrete proof state when a proof attempt fails, giving the agent actionable feedback for repair. These results provide empirical evidence that ITP-based verified programming is a feasible route for LLM-generated software projects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that interactive theorem provers (ITPs) such as Rocq enable fully automatic, human-intervention-free generation of complex verified software projects from natural-language requirements via an LLM agent. The agent separates effectful code (implemented in the target language) from pure total functions (proven in the ITP and extracted), demonstrated on a complete RISC-V RV32I interpreter covering all 47 instructions. With Rocq, the project completes in 30 minutes yielding 1,859 lines of verified Rocq code extracted to 2,848 lines of C++; the interpreter passes all 265 LLM-generated tests and shows zero crashes or hangs in 12 hours of AFL++ fuzzing. The Dafny backend fails under identical conditions. The central observation is that Rocq supplies concrete proof states that enable autonomous repair.
Significance. If the empirical outcomes hold, the work supplies concrete evidence that ITP-backed verified programming can overcome the unreliability of direct LLM code generation for project-scale artifacts. Strengths include machine-checked proofs in Rocq, extraction to executable C++, coverage by 265 tests, and rigorous fuzzing validation. This offers a reproducible route to trustworthy software and highlights an advantage of ITPs over verification-oriented languages like Dafny for LLM-driven synthesis.
major comments (2)
- [Agent–Rocq interaction / proof repair] The manuscript asserts that the LLM agent autonomously interprets Rocq's concrete proof state to repair failed proofs for all 47 instructions without human edits, yet provides no description of state serialization, the repair prompt template, or the number of repair attempts required per lemma. This mechanism is load-bearing for the central claim of fully automatic project generation (see abstract and the section on agent–Rocq interaction).
- [Integration and extraction] The claim that separating effectful C++ scaffolding from extracted pure total functions suffices for a working stateful interpreter is asserted but not supported by any explicit description of how state is maintained across instructions or how the integration was validated beyond the reported tests and fuzzing. This is central to the feasibility conclusion.
minor comments (1)
- [Title] The title contains an extraneous space before the colon; standard formatting would be 'Trustworthy Software Project Generation: a Case Study with an Interactive Theorem Prover'.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments correctly identify areas where the manuscript would benefit from greater technical detail to substantiate the claims of fully automatic generation and integration. We respond to each point below and will incorporate the requested clarifications in the revision.
read point-by-point responses
-
Referee: [Agent–Rocq interaction / proof repair] The manuscript asserts that the LLM agent autonomously interprets Rocq's concrete proof state to repair failed proofs for all 47 instructions without human edits, yet provides no description of state serialization, the repair prompt template, or the number of repair attempts required per lemma. This mechanism is load-bearing for the central claim of fully automatic project generation (see abstract and the section on agent–Rocq interaction).
Authors: We agree that the manuscript does not currently provide these implementation-level details on proof repair, which are necessary for full reproducibility of the autonomous process. In the revised version we will add a dedicated subsection to the 'Agent–Rocq interaction' section that (1) describes the serialization of Rocq proof states (goals, hypotheses, and error messages) into LLM-readable text, (2) presents the structure of the repair prompt template, and (3) reports empirical statistics on repair attempts per lemma, including average number of attempts and first-try success rate across the 47 instructions. These additions directly address the load-bearing mechanism without altering the reported outcomes. revision: yes
-
Referee: [Integration and extraction] The claim that separating effectful C++ scaffolding from extracted pure total functions suffices for a working stateful interpreter is asserted but not supported by any explicit description of how state is maintained across instructions or how the integration was validated beyond the reported tests and fuzzing. This is central to the feasibility conclusion.
Authors: We acknowledge that the manuscript lacks an explicit description of the state-maintenance mechanism and additional validation steps. The effectful C++ scaffolding maintains mutable CPU state (registers and memory) that is passed to and updated by each extracted pure function. In the revision we will insert a new 'Integration and Extraction' subsection containing (1) a description and diagram of the state-passing interface, (2) a representative code example showing how an extracted function is invoked from the C++ scaffolding, and (3) details of supplementary validation (manual review of generated C++ for all 47 instructions and targeted state-transition checks). This will strengthen the feasibility argument while preserving the existing test and fuzzing results. revision: yes
Circularity Check
No significant circularity; empirical case study with independent outcomes
full rationale
The paper reports an empirical case study in which an LLM agent autonomously generates, verifies, extracts, and integrates a full RISC-V RV32I interpreter using Rocq. The headline results (30-minute completion, 1,859 lines of verified Rocq, 2,848 lines of extracted C++, passage of 265 tests, zero crashes/hangs in 12-hour fuzzing) are presented as observed outcomes of running the described process. No mathematical derivation chain, equations, fitted parameters renamed as predictions, or self-referential definitions appear. The separation of effectful scaffolding from pure total functions is stated as a methodological premise, not derived from the results themselves. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are quoted or required to support the central claim. The paper is therefore self-contained against external benchmarks (test suite and fuzzing) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ITPs handle pure total functions but not effects such as I/O
Reference graph
Works this paper leans on
-
[1]
Deepseek-coder: When the large language model meets programming – the rise of code intelligence,
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . K. Li, F. Luo, Y . Xiong, and W. Liang, “Deepseek-coder: When the large language model meets programming – the rise of code intelligence,” 2024. [Online]. Available: https://arxiv.org/abs/2401.14196
Pith/arXiv arXiv 2024
-
[2]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
Pith/arXiv arXiv 2021
-
[3]
(2026) Claude code documentation: Overview
Anthropic. (2026) Claude code documentation: Overview. Anthropic. [Online]. Available: https://code.claude.com/docs/en/overview
2026
-
[4]
(2026) Cursor agents
Anysphere. (2026) Cursor agents. Anysphere
2026
-
[5]
A. Li, C. Wu, Z. Ge, Y . H. Chong, Z. Hou, L. Cao, C. Ju, J. Wu, H. Li, H. Zhang, S. Feng, M. Zhao, F. Qiu, R. Yang, M. Zhang, W. Zhu, Y . Sun, Q. Sun, S. Yan, D. Liu, D. Yin, and D. Shen, “The fm agent,” 2026. [Online]. Available: https://arxiv.org/abs/2510.26144
arXiv 2026
-
[6]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Trans. Inf. Syst., vol. 43, no. 2, pp. 42:1–42:55, 2025. [Online]. Available: https://doi.org/10.1145/3703155
-
[7]
Type-constrained code generation with language models,
N. M ¨undler, J. He, H. Wang, K. Sen, D. Song, and M. T. Vechev, “Type-constrained code generation with language models,”Proc. ACM Program. Lang., vol. 9, no. PLDI, pp. 601–626, 2025. [Online]. Available: https://doi.org/10.1145/3729274
-
[8]
Evaluating llm-generated acsl annotations for formal verification,
A. Beg, D. O’Donoghue, and R. Monahan, “Evaluating llm-generated acsl annotations for formal verification,” 2026. [Online]. Available: https://arxiv.org/abs/2602.13851
Pith/arXiv arXiv 2026
-
[9]
Dafny: An automatic program verifier for functional correctness,
K. R. M. Leino, “Dafny: An automatic program verifier for functional correctness,” inLogic for Programming, Artificial Intelligence, and Reasoning - 16th International Conference, LPAR-16, Dakar, Senegal, April 25-May 1, 2010, Revised Selected Papers, ser. Lecture Notes in Computer Science, E. M. Clarke and A. V oronkov, Eds. Springer, 2010, pp. 348–370. ...
-
[10]
The Coq reference manual – release 9.0,
The Coq Development Team, “The Coq reference manual – release 9.0,” 2025. [Online]. Available: https://rocq-prover.org/doc/v9.0/refman/ index.html
2025
-
[11]
The lean 4 theorem prover and programming language,
L. de Moura and S. Ullrich, “The lean 4 theorem prover and programming language,” inAutomated Deduction - CADE 28 - 28th International Conference on Automated Deduction, Virtual Event, July 12-15, 2021, Proceedings, ser. Lecture Notes in Computer Science, A. Platzer and G. Sutcliffe, Eds., vol. 12699. Springer, 2021, pp. 625–635. [Online]. Available: http...
-
[12]
M. Wenzel, L. C. Paulson, and T. Nipkow, “The isabelle framework,” inTheorem Proving in Higher Order Logics, 21st International Conference, TPHOLs 2008, Montreal, Canada, August 18-21, 2008. Proceedings, ser. Lecture Notes in Computer Science, O. A. Mohamed, C. A. Mu ˜noz, and S. Tahar, Eds., vol. 5170. Springer, 2008, pp. 33–38. [Online]. Available: http...
-
[13]
Machine-generated, machine-checked proofs for a verified compiler (experience report),
Z. Paraskevopoulou, “Machine-generated, machine-checked proofs for a verified compiler (experience report),” 2026. [Online]. Available: https://arxiv.org/abs/2602.20082
arXiv 2026
-
[14]
Introduction to the calculus of inductive construc- tions,
C. Paulin-Mohring, “Introduction to the calculus of inductive construc- tions,”All about Proofs, Proofs for All, vol. 55, 2015
2015
-
[15]
Interaction trees: representing recursive and impure programs in coq,
L.-y. Xia, Y . Zakowski, P. He, C.-K. Hur, G. Malecha, B. C. Pierce, and S. Zdancewic, “Interaction trees: representing recursive and impure programs in coq,”Proc. ACM Program. Lang., vol. 4, no. POPL, Dec
-
[16]
Available: https://doi.org/10.1145/3371119
[Online]. Available: https://doi.org/10.1145/3371119
-
[17]
Compcert – a formally verified optimizing compiler,
X. Leroy, S. Blazy, D. K ¨astner, B. Schommer, M. Pister, and C. Ferdinand, “Compcert – a formally verified optimizing compiler,” in ERTS 2016: Embedded Real Time Software and Systems. SEE, 2016. [Online]. Available: http://xavierleroy.org/publi/erts2016 compcert.pdf
2016
-
[18]
Certicoq: A verified compiler for coq,
A. Anand, A. Appel, G. Morrisett, Z. Paraskevopoulou, R. Pollack, O. S. Belanger, M. Sozeau, and M. Weaver, “Certicoq: A verified compiler for coq,” inThe third international workshop on Coq for programming languages (CoqPL), 2017
2017
-
[19]
Korkut and M
J. Korkut and M. Weaver. (2026) crane. [Online]. Available: https://github.com/bloomberg/crane#maintainers
2026
-
[20]
Qemu: a multihost, multitarget emulator,
D. Bartholomew, “Qemu: a multihost, multitarget emulator,”Linux Journal, vol. 2006, no. 145, p. 3, 2006
2006
-
[21]
Unicorn: Next generation cpu emulator framework,
N. A. Quynh and D. H. Vu, “Unicorn: Next generation cpu emulator framework,”BlackHat USA, vol. 476, 2015
2015
-
[22]
(2026) Unprivileged isa: Rv64
RISC-V International. (2026) Unprivileged isa: Rv64. RISC-V International. RISC-V ISA documentation (online reference). [Online]. Available: https://docs.riscv.org/reference/isa/unpriv/rv64.html
2026
-
[23]
Verified extraction from coq to ocaml,
Y . Forster, M. Sozeau, and N. Tabareau, “Verified extraction from coq to ocaml,” vol. 8, no. PLDI, Jun. 2024. [Online]. Available: https://doi.org/10.1145/3656379
-
[24]
coq-of-ocaml,
formal-land, “coq-of-ocaml,” 2026. [Online]. Available: https://github. com/formal-land/coq-of-ocaml
2026
-
[25]
rocq-of-rust,
——, “rocq-of-rust,” 2026. [Online]. Available: https://github.com/ formal-land/rocq-of-rust
2026
-
[26]
Verus: Verifying rust programs using linear ghost types,
A. Lattuada, T. Hance, C. Cho, M. Brun, I. Subasinghe, Y . Zhou, J. Howell, B. Parno, and C. Hawblitzel, “Verus: Verifying rust programs using linear ghost types,”Proceedings of the ACM on Programming Languages, vol. 7, no. OOPSLA1, pp. 286–315, 2023
2023
-
[27]
AFL++: Combining incremental steps of fuzzing research,
A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “AFL++: Combining incremental steps of fuzzing research,” in14th USENIX Workshop on Offensive Technologies (WOOT 20). USENIX Association, Aug. 2020
2020
-
[28]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[29]
Introducing claude sonnet 4.6,
Anthropic, “Introducing claude sonnet 4.6,” https://www.anthropic.com/ news/claude-sonnet-4-6, 2026
2026
-
[30]
Deepseek-v3.2: Pushing the frontier of open large lan- guage models,
DeepSeek-AI, “Deepseek-v3.2: Pushing the frontier of open large lan- guage models,” 2025
2025
-
[31]
SWE-bench: Can language models resolve real- world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real- world github issues?” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[32]
C. Research, :, A. Chan, A. Shalaby, A. Wettig, A. Sanger, A. Zhai, A. Ajay, A. Nair, C. Snell, C. Lu, C. Shen, E. Jia, F. Cassano, H. Liu, H. Chen, H. Wildermuth, J. Jackson, J. Li, J. Katz, J. Yao, J. Hejna, J. Warner, J. Vering, K. Frans, L. Danilek, L. Wright, L. Cen, L. Melas-Kyriazi, M. Truell, M. de Jong, N. Jain, N. Schmidt, N. Wang, N. Muennighof...
arXiv 2026
-
[33]
Claude code: An agentic coding tool,
Anthropic, “Claude code: An agentic coding tool,” https://code.claude. com/, 2025
2025
-
[34]
(2025) Opencode: Open source, terminal-based AI coding assistant
OpenCode Team. (2025) Opencode: Open source, terminal-based AI coding assistant. Anomaly. [Online]. Available: https://opencode.ai
2025
-
[35]
Bertot and P
Y . Bertot and P. Cast ´eran,Interactive theorem proving and program development: Coq’Art: the calculus of inductive constructions. Springer Science & Business Media, 2013
2013
-
[36]
seL4: formal verification of an os kernel
G. Klein, K. Elphinstone, G. Heiser, J. Andronick, D. A. Cock, P. Derrin, D. Elkaduwe, K. Engelhardt, R. Kolanski, M. Norrish, T. Sewell, H. Tuch, and S. Winwood, “seL4: formal verification of an os kernel.” inProceedings of the 22nd ACM Symposium on Operating Systems Principles 2009, SOSP 2009, Big Sky, Montana, USA, October 11-14, 2009, J. N. Matthews a...
-
[37]
CertiKOS: An extensible architecture for building certified concurrent os kernels,
R. Gu, Z. Shao, H. Chen, X. N. Wu, J. Kim, V . Sj ¨oberg, and D. Costanzo, “CertiKOS: An extensible architecture for building certified concurrent os kernels,” in12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, Savannah, GA, USA, November 2-4, 2016, K. Keeton and T. Roscoe, Eds. USENIX Association, 2016, pp. 653–669. [Onlin...
2016
-
[38]
Hammer for coq: Automation for dependent type theory,
L. Czajka and C. Kaliszyk, “Hammer for coq: Automation for dependent type theory,”J. Autom. Reason., vol. 61, no. 1-4, pp. 423–453, 2018. [Online]. Available: https://doi.org/10.1007/s10817-018-9458-4 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10
-
[39]
S. B ¨ohme and T. Nipkow, “Sledgehammer: Judgement day,” in Automated Reasoning, 5th International Joint Conference, IJCAR 2010, Edinburgh, UK, July 16-19, 2010. Proceedings, ser. Lecture Notes in Computer Science, J. Giesl and R. H ¨ahnle, Eds., vol. 6173. Springer, 2010, pp. 107–121. [Online]. Available: https://doi.org/10.1007/978-3-642-14203-1\ 9
-
[40]
Lean-auto: An interface between lean 4 and automated theorem provers,
Y . Qian, J. Clune, C. Barrett, and J. Avigad, “Lean-auto: An interface between lean 4 and automated theorem provers,” 2025. [Online]. Available: https://arxiv.org/abs/2505.14929
arXiv 2025
-
[41]
Learning to prove theorems via interacting with proof assistants,
K. Yang and J. Deng, “Learning to prove theorems via interacting with proof assistants,” inProceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, ser. Proceedings of Machine Learning Research, K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97. PMLR, 2019, pp. 6984–6994. [Online]. Availa...
2019
-
[42]
Generating correctness proofs with neural networks,
A. Sanchez-Stern, Y . Alhessi, L. K. Saul, and S. Lerner, “Generating correctness proofs with neural networks,” inProceedings of the 4th ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL@PLDI 2020, London, UK, June 15, 2020, K. Sen and M. Naik, Eds. ACM, 2020, pp. 1–10. [Online]. Available: https://doi.org/10.1145/3394...
-
[43]
Graph2tac: Online representation learning of formal math concepts,
L. Blaauwbroek, M. Ols ´ak, J. Rute, F. I. S. Massolo, J. Piepenbrock, and V . Pestun, “Graph2tac: Online representation learning of formal math concepts,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=A7CtiozznN
2024
-
[44]
Leandojo: Theorem proving with retrieval-augmented language models,
K. Yang, A. M. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. J. Prenger, and A. Anandkumar, “Leandojo: Theorem proving with retrieval-augmented language models,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. ...
arXiv 2023
-
[45]
Lego-prover: Neural theorem proving with growing libraries,
H. Wang, H. Xin, C. Zheng, Z. Liu, Q. Cao, Y . Huang, J. Xiong, H. Shi, E. Xie, J. Yin, Z. Li, and X. Liang, “Lego-prover: Neural theorem proving with growing libraries,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id...
2024
-
[46]
Proof automation with large language models,
M. Lu, B. Delaware, and T. Zhang, “Proof automation with large language models,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024, Sacramento, CA, USA, October 27 - November 1, 2024, V . Filkov, B. Ray, and M. Zhou, Eds. ACM, 2024, pp. 1509–1520. [Online]. Available: https://doi.org/10.1145/3691620.3695521
-
[47]
Cobblestone: A Divide-and-Conquer Approach for Automating Formal Verification
S. R. Kasibatla, A. Agarwal, Y . Brun, S. Lerner, T. Ringer, and E. First, “Cobblestone: Iterative automation for formal verification,” CoRR, vol. abs/2410.19940, 2024. [Online]. Available: https://doi.org/ 10.48550/arXiv.2410.19940
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.19940 2024
-
[48]
Rango: Adaptive retrieval-augmented proving for automated software verification,
K. Thompson, N. Saavedra, P. Carrott, K. Fisher, A. Sanchez-Stern, Y . Brun, J. F. Ferreira, S. Lerner, and E. First, “Rango: Adaptive retrieval-augmented proving for automated software verification,” in 47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 2025, pp. 347–359. [Online]....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.