L2IR: Revealing Latent Intent in Graph Fraud Detection
Pith reviewed 2026-06-29 21:40 UTC · model grok-4.3
The pith
L2IR uses LLMs to extract latent intent from user behaviors and connections, distinguishing supportive links from misleading ones in camouflaged fraud graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
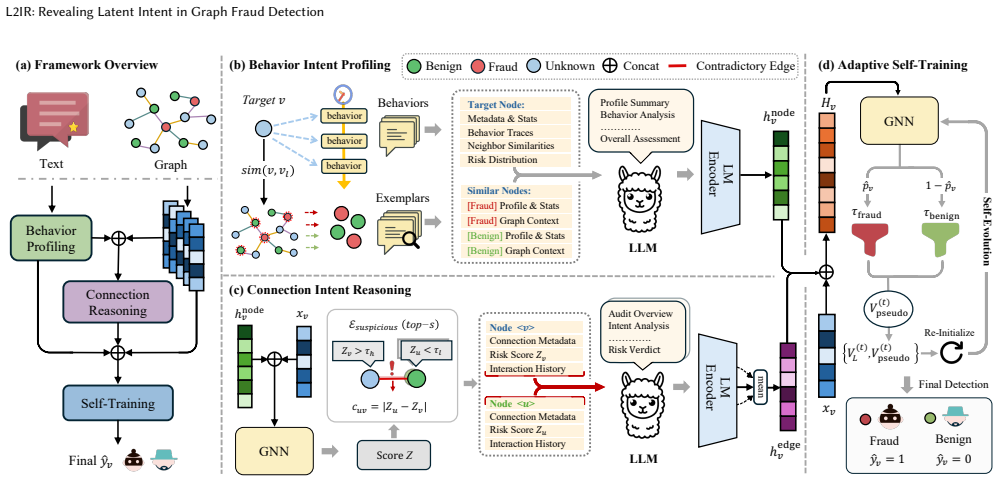
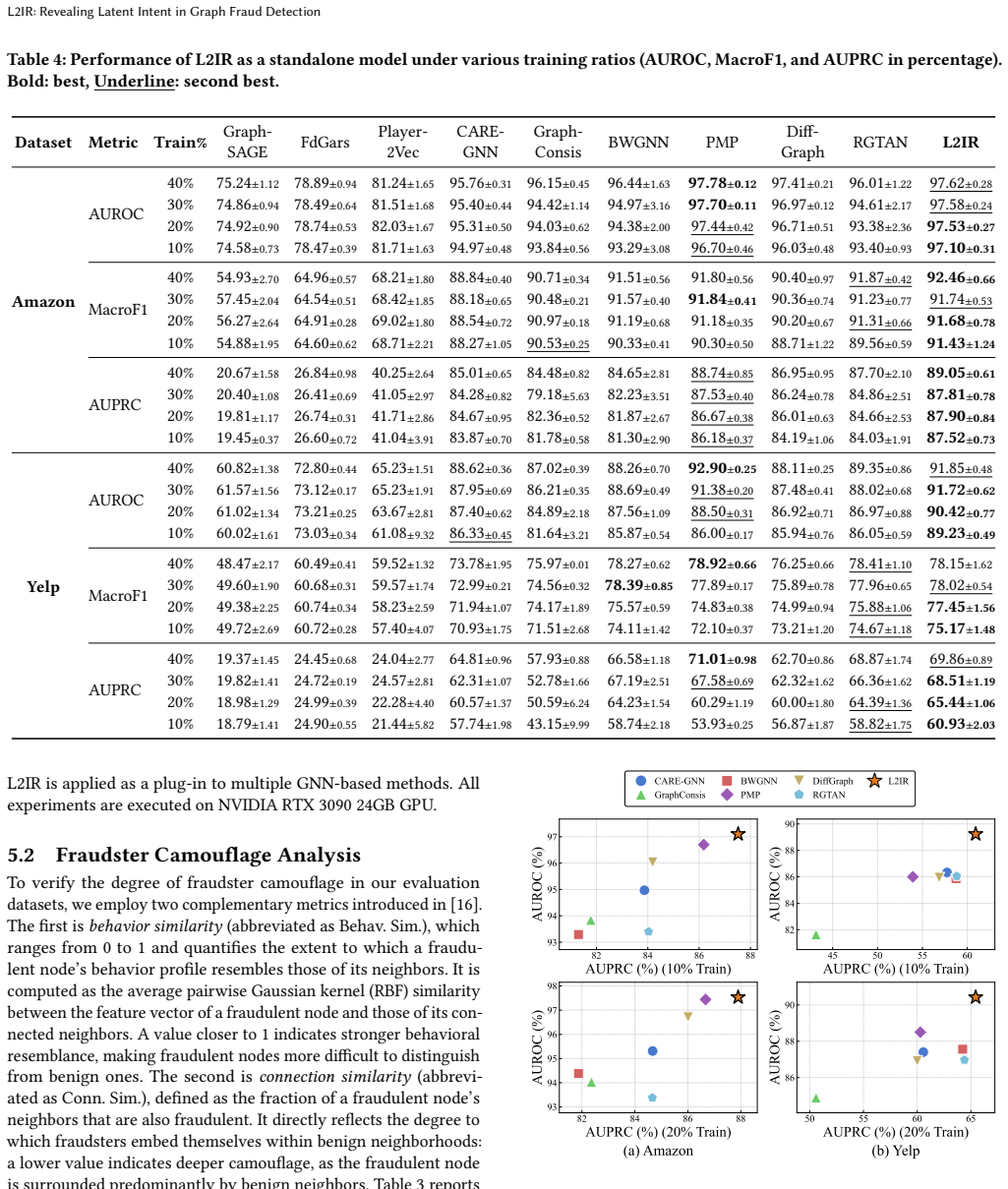
L2IR is an LLM-driven framework that uncovers latent intent from both raw behavioral traces and individual suspicious connections. It extracts intent-aware representations and reasons about the true purpose of each link to separate supportive from misleading ones, then applies adaptive self-training for robustness under scarce supervision. On two real-world datasets with pervasive camouflage, the method outperforms strong baselines and serves as a plug-in that raises AUPRC by as much as 8.27 percent for multiple GNN-based detectors.
What carries the argument
The L2IR framework, which extracts intent-aware representations by having LLMs analyze user behaviors and reason about the purpose of each connection.
If this is right
- GNN detectors become more robust to camouflage because intent signals counteract dilution during aggregation.
- The same LLM-based intent extraction can be attached to multiple existing GNN architectures without retraining the base model.
- Adaptive self-training allows the detector to maintain performance when only a small fraction of nodes carry fraud labels.
- Detection improves most on graphs where fraudsters rely on many benign-looking connections rather than isolated anomalous behavior.
Where Pith is reading between the lines
- The same intent-revealing step could be tested on other graph tasks that suffer from noisy or adversarial edges, such as recommendation systems or social-network anomaly detection.
- If the LLM component can be replaced by a smaller distilled model while retaining most of the gain, deployment cost would drop sharply.
- The approach suggests a general pattern: use LLMs to annotate edge semantics first, then feed the enriched graph to any message-passing model.
Load-bearing premise
Large language models can reliably infer the true underlying intent behind connections and behaviors even when fraud labels are scarce and camouflage is heavy.
What would settle it
Apply L2IR to a labeled graph where human experts have independently annotated the true intent of each edge; if the model's distinction between supportive and misleading links shows no gain over a standard GNN, the central claim fails.
Figures


read the original abstract
Graph fraud detection has long depended on Graph Neural Networks (GNNs) to propagate and aggregate information across relational data. A critical obstacle in practice, however, is that fraudsters frequently disguise themselves by forging numerous connections with benign users, causing fraud signals to be progressively diluted during neighborhood aggregation and undermining detection reliability. While recent efforts have used Large Language Models (LLMs) to provide rich semantic cues for fraud detection, the underlying intent behind suspicious connections remains insufficiently explored. Compounding this issue, the scarcity of annotated fraud samples makes it difficult to train detectors that remain robust under heavy camouflage. To address these gaps, we propose L2IR, an LLM-driven Latent Intent Revealing framework for graph fraud detection. By uncovering latent intent from both user behaviors and suspicious connections, L2IR extracts intent-aware representations from raw behavioral traces and reasons about the true purpose behind individual connections, effectively distinguishing supportive links from misleading ones. It further incorporates adaptive self-training to enhance robustness under limited supervision. Evaluations on two real-world datasets characterized by pervasive camouflage demonstrate that L2IR surpasses strong baselines and can function as a plug-in enhancement for a range of GNN-based detectors, improving AUPRC by up to 8.27%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes L2IR, an LLM-driven framework for graph fraud detection that extracts latent intent from user behaviors and suspicious connections to distinguish supportive from misleading links, combined with adaptive self-training for robustness under scarce labels. It claims to outperform strong GNN baselines on two camouflage-heavy real-world datasets, with AUPRC gains up to 8.27%, and to serve as a plug-in enhancement for existing GNN detectors.
Significance. If the empirical gains can be attributed to accurate LLM-based intent revelation rather than auxiliary components, the work would offer a practical way to mitigate neighborhood aggregation dilution in camouflaged fraud graphs and improve performance under limited supervision. The plug-in design is a positive feature for adoption, though the absence of validation on intent quality limits assessment of whether the approach advances beyond standard self-training or semantic augmentation techniques.
major comments (3)
- [Framework description] Framework description (no section/equation cited in abstract): no ablation isolating the latent intent extraction module from adaptive self-training, so it is impossible to determine whether the reported AUPRC gains arise from LLM intent reasoning or from regularization/self-training effects alone.
- [Evaluation section] Evaluation section: no quantitative validation of intent quality (e.g., expert agreement rates, precision of supportive vs. misleading link classification, or error analysis on misclassified intents) despite the central claim that LLMs reliably uncover true latent intent from behavioral traces and connections.
- [Experiments] Experiments: the AUPRC improvements (up to 8.27%) are reported without error bars, statistical significance tests, or implementation details on LLM prompting/fine-tuning for intent extraction, preventing reproduction or assessment of the plug-in claim across GNN detectors.
minor comments (1)
- [Abstract] Abstract does not define key terms such as 'intent-aware representations' or 'adaptive self-training' before claiming empirical superiority.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity and rigor of our presentation. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Framework description] Framework description (no section/equation cited in abstract): no ablation isolating the latent intent extraction module from adaptive self-training, so it is impossible to determine whether the reported AUPRC gains arise from LLM intent reasoning or from regularization/self-training effects alone.
Authors: We agree that an explicit ablation isolating the latent intent extraction module from adaptive self-training is needed to attribute performance gains. In the revised manuscript we will add this ablation study and will also cite the relevant sections and equations directly in the abstract. revision: yes
-
Referee: [Evaluation section] Evaluation section: no quantitative validation of intent quality (e.g., expert agreement rates, precision of supportive vs. misleading link classification, or error analysis on misclassified intents) despite the central claim that LLMs reliably uncover true latent intent from behavioral traces and connections.
Authors: We acknowledge that direct quantitative validation of intent quality would further substantiate the central claim. While downstream task performance serves as the primary evaluation, we will add case studies together with error analysis on intent classification in the revision to provide additional supporting evidence. revision: yes
-
Referee: [Experiments] Experiments: the AUPRC improvements (up to 8.27%) are reported without error bars, statistical significance tests, or implementation details on LLM prompting/fine-tuning for intent extraction, preventing reproduction or assessment of the plug-in claim across GNN detectors.
Authors: We agree that error bars, statistical significance tests, and full implementation details are required for reproducibility and for assessing the plug-in claim. In the revised manuscript we will report standard deviations across runs, include statistical significance tests, and provide complete details on LLM prompting and fine-tuning procedures. revision: yes
Circularity Check
No significant circularity; claims are empirical outcomes
full rationale
The paper proposes an LLM-driven framework L2IR for graph fraud detection and reports measured AUPRC improvements (up to 8.27%) on two real-world datasets as empirical results. No equations, derivations, fitted parameters, or mathematical predictions are present that could reduce to inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way for any derivation chain. The central claims rest on external benchmark comparisons rather than self-referential definitions, making the work self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can accurately extract and reason about latent intent from user behaviors and suspicious connections
- domain assumption Adaptive self-training can enhance robustness under limited supervision for fraud detection
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Leman Akoglu, Hanghang Tong, and Danai Koutra. 2015. Graph based anomaly detection and description: a survey.Data mining and knowledge discovery29, 3 (2015), 626–688
2015
-
[3]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al . 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
2024
-
[4]
Yingtong Dou, Zhiwei Liu, Li Sun, Yutong Deng, Hao Peng, and Philip S Yu. 2020. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. InProceedings of the 29th ACM international conference on information & knowledge management. 315–324
2020
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[7]
Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. 2024. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning. InInternational conference on learning representations, Vol. 2024. 5711–5732
2024
-
[8]
Bryan Hooi, Hyun Ah Song, Alex Beutel, Neil Shah, Kijung Shin, and Christos Faloutsos. 2016. FRAUDAR: Bounding Graph Fraud in the Face of Camouflage. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 895–904
2016
-
[9]
Tairan Huang, Yili Wang, Qiutong Li, Changlong He, and Jianliang Gao. 2025. Can llms find fraudsters? multi-level llm enhanced graph fraud detection. In Proceedings of the 33rd ACM International Conference on Multimedia. 1530–1538
2025
-
[10]
Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Yuan Li, Jun Hu, Bryan Hooi, Bingsheng He, and Cheng Chen. 2026. DGP: A Dual- Granularity Prompting Framework for Fraud Detection with Graph-Enhanced LLMs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 15171–15179
2026
-
[12]
Zongwei Li, Lianghao Xia, Hua Hua, Shijie Zhang, Shuangyang Wang, and Chao Huang. 2025. Diffgraph: Heterogeneous graph diffusion model. InProceedings of the Eighteenth ACM International conference on web search and data mining. 40–49
2025
-
[13]
Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang, and Qing He. 2021. Pick and choose: a GNN-based imbalanced learning approach for fraud detection. InProceedings of the web conference 2021. 3168–3177
2021
-
[14]
Ziqi Liu, Chaochao Chen, Longfei Li, Jun Zhou, Xiaolong Li, Le Song, and Yuan Qi. 2019. Geniepath: Graph neural networks with adaptive receptive paths. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 4424–4431
2019
-
[15]
Ziqi Liu, Chaochao Chen, Xinxing Yang, Jun Zhou, Xiaolong Li, and Le Song
-
[16]
In Proceedings of the 27th ACM international conference on information and knowledge management
Heterogeneous graph neural networks for malicious account detection. In Proceedings of the 27th ACM international conference on information and knowledge management. 2077–2085
2077
-
[17]
Zhiwei Liu, Yingtong Dou, Philip S Yu, Yutong Deng, and Hao Peng. 2020. Alle- viating the inconsistency problem of applying graph neural network to fraud detection. InProceedings of the 43rd international ACM SIGIR conference on re- search and development in information retrieval. 1569–1572
2020
-
[18]
Mingxuan Lu, Zhichao Han, Susie Xi Rao, Zitao Zhang, Yang Zhao, Yinan Shan, Ramesh Raghunathan, Ce Zhang, and Jiawei Jiang. 2022. Bright-graph neural networks in real-time fraud detection. InProceedings of the 31st ACM international conference on information & knowledge management. 3342–3351
2022
-
[19]
Julian John McAuley and Jure Leskovec. 2013. From amateurs to connoisseurs: modeling the evolution of user expertise through online reviews. InProceedings of the 22nd international conference on World Wide Web. 897–908
2013
-
[20]
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey.arXiv preprint arXiv:2402.06196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Shebuti Rayana and Leman Akoglu. 2015. Collective opinion spam detection: Bridging review networks and metadata. InProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 985–994
2015
-
[22]
Fengzhao Shi, Yanan Cao, Yanmin Shang, Yuchen Zhou, Chuan Zhou, and Jia Wu
-
[23]
InProceedings of the ACM web conference 2022
H2-fdetector: A gnn-based fraud detector with homophilic and heterophilic connections. InProceedings of the ACM web conference 2022. 1486–1494
2022
-
[24]
Yanchao Tan, Zihao Zhou, Hang Lv, Weiming Liu, and Carl Yang. 2023. Walklm: A uniform language model fine-tuning framework for attributed graph embedding. Advances in neural information processing systems36 (2023), 13308–13325
2023
-
[25]
Jianheng Tang, Jiajin Li, Ziqi Gao, and Jia Li. 2022. Rethinking graph neural networks for anomaly detection. InInternational conference on machine learning. PMLR, 21076–21089
2022
-
[26]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500
2024
-
[27]
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. 2023. Large language models in medicine.Nature medicine29, 8 (2023), 1930–1940
2023
-
[28]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, Yoshua Bengio, et al . 2018. Graph attention networks. InInternational conference on learning representations, Vol. 6. Ithaca
2018
-
[29]
Petar Veličković, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2018. Deep graph infomax.arXiv preprint arXiv:1809.10341 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Daixin Wang, Jianbin Lin, Peng Cui, Quanhui Jia, Zhen Wang, Yanming Fang, Quan Yu, Jun Zhou, Shuang Yang, and Yuan Qi. 2019. A semi-supervised graph attentive network for financial fraud detection. In2019 IEEE international confer- ence on data mining (ICDM). IEEE, 598–607
2019
-
[31]
Jianyu Wang, Rui Wen, Chunming Wu, Yu Huang, and Jian Xiong. 2019. Fdgars: Fraudster detection via graph convolutional networks in online app review system. InCompanion proceedings of the 2019 World Wide Web conference. 310– 316
2019
-
[32]
Xiao Wang, Meiqi Zhu, Deyu Bo, Peng Cui, Chuan Shi, and Jian Pei. 2020. Am- gcn: Adaptive multi-channel graph convolutional networks. InProceedings of the 26th ACM SIGKDD International conference on knowledge discovery & data mining. 1243–1253
2020
-
[33]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large language models with graph augmentation for recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 806–815
2024
-
[34]
Haiqin Weng, Shouling Ji, Fuzheng Duan, Zhao Li, Jianhai Chen, Qinming He, and Ting Wang. 2019. Cats: cross-platform e-commerce fraud detection. In2019 ieee 35th international conference on data engineering (icde). IEEE, 1874–1885
2019
-
[35]
Sheng Xiang, Guibin Zhang, Dawei Cheng, and Ying Zhang. 2025. Enhancing attribute-driven fraud detection with risk-aware graph representation.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Chengdong Yang, Hongrui Liu, Daixin Wang, Zhiqiang Zhang, Cheng Yang, and Chuan Shi. 2025. Flag: Fraud detection with llm-enhanced graph neural network. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5150–5160
2025
-
[38]
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. 2024. Language is all a graph needs. InFindings of the association for computational linguistics: EACL 2024. 1955–1973
2024
-
[39]
Hang Yu, Zhengyang Liu, and Xiangfeng Luo. 2024. Barely supervised learning for graph-based fraud detection. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 16548–16557. Jinsheng Guo, Zhenhao Weng, Yibo Liu, Yan Qiao, and Meng Li
2024
-
[40]
Yiming Zhang, Yujie Fan, Yanfang Ye, Liang Zhao, and Chuan Shi. 2019. Key player identification in underground forums over attributed heterogeneous in- formation network embedding framework. InProceedings of the 28th ACM inter- national conference on information and knowledge management. 549–558
2019
- [41]
-
[42]
Jing Zhu, Xiang Song, Vassilis Ioannidis, Danai Koutra, and Christos Faloutsos
-
[43]
InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Touchup-g: Improving feature representation through graph-centric fine- tuning. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2662–2666
- [44]
- [45]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.