Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
Pith reviewed 2026-06-29 21:30 UTC · model grok-4.3
The pith
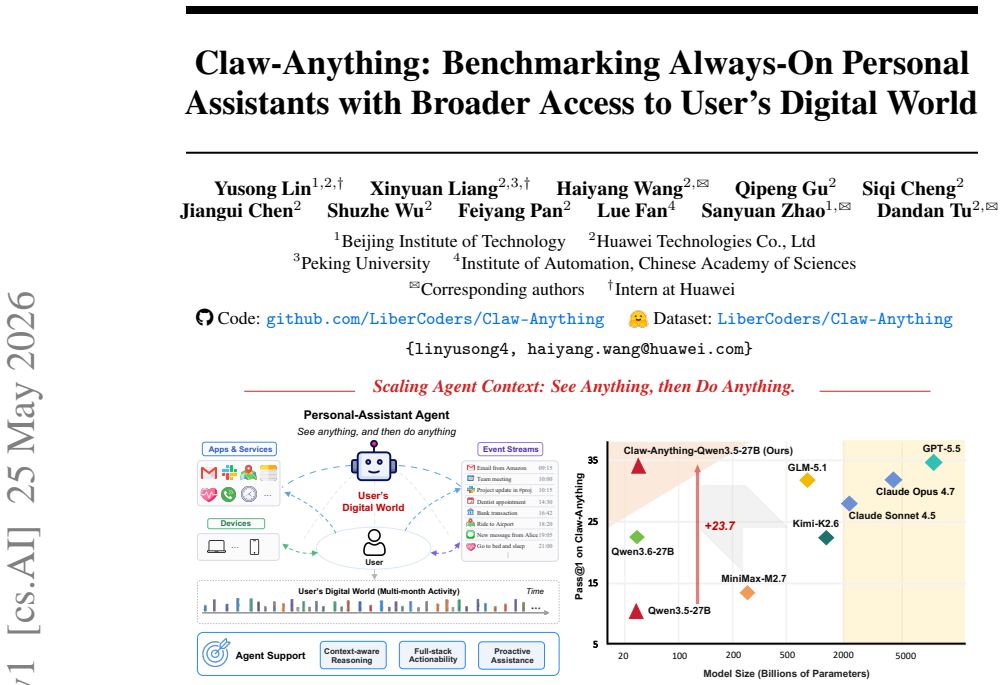
A new benchmark shows leading AI agents succeed on only 34.5 percent of tasks when given full access to a user's months-long digital activity across services and devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
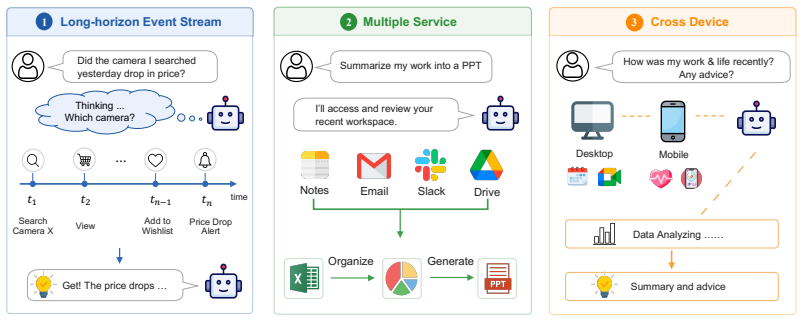
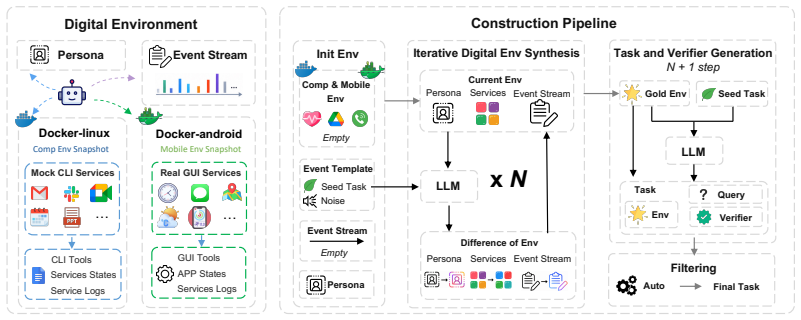
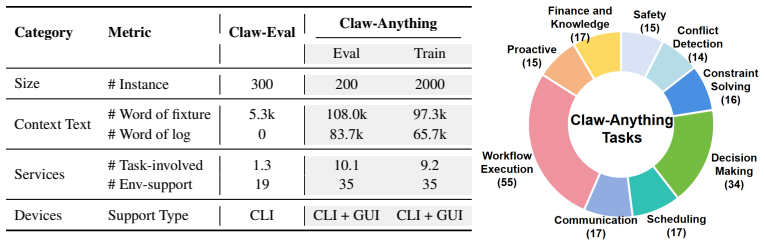
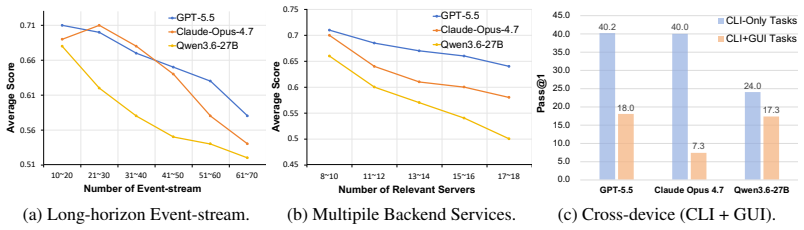
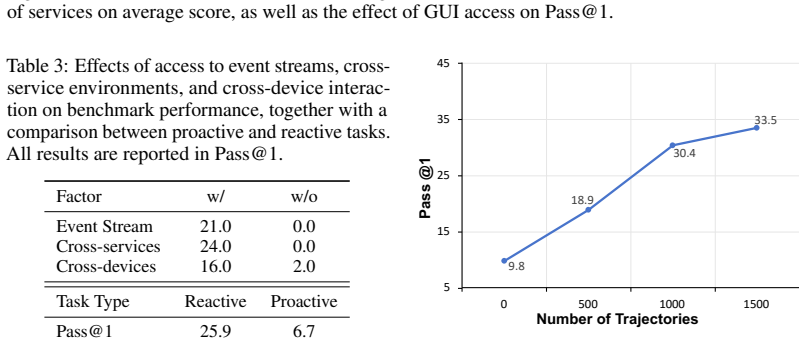
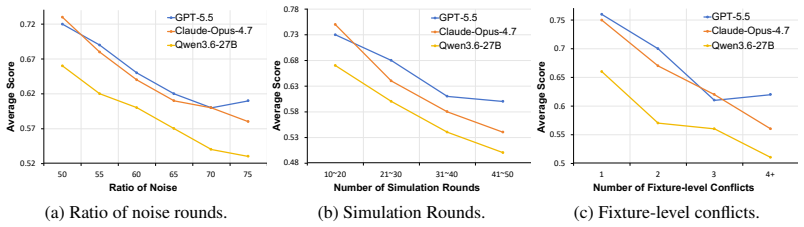
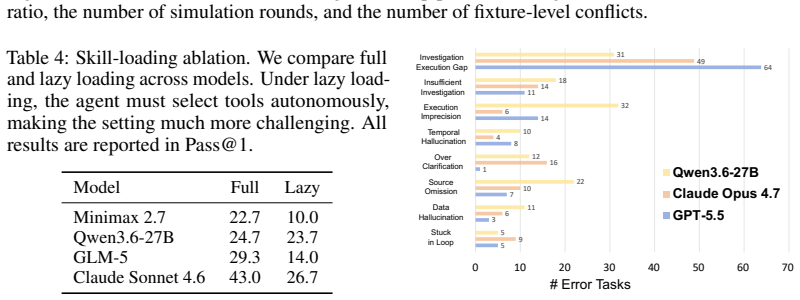
Claw-Anything expands agent context along three dimensions: long-horizon activity histories, interdependent backend services, and integrated GUI and CLI interaction across multiple devices. Multi-round event injection produces complex world states and realistic noise. GPT-5.5 reaches only 34.5 percent pass@1, and an automated pipeline that yields 2,000 training environments improves the base model by 23.7 percent.
What carries the argument
The Claw-Anything benchmark, which measures agent performance over simulated months of user activity with noise and requires proactive recommendations from rich, interdependent context.
If this is right
- Agents must maintain robustness to irrelevant events and conflicting signals while reasoning over long histories.
- Proactive assistance can now be measured because full histories allow anticipation of needs.
- Narrower prior benchmarks do not predict success once context expands to multiple services and devices.
- Automated generation of thousands of training environments can measurably raise model scores on the new tasks.
Where Pith is reading between the lines
- Models may need explicit long-term memory mechanisms to handle the scale of activity histories shown here.
- Cross-service consistency checks could become a standard requirement for any deployed personal assistant.
- The data pipeline might extend to other domains where agents need months-scale context, such as project management or health tracking.
Load-bearing premise
The simulated months of injected user events create world states and noise levels that match those an always-on assistant would meet in real digital lives.
What would settle it
Measure the same agents on months of actual user digital traces and check whether the 34.5 percent pass rate and the noise sensitivity remain similar to the simulated results.
Figures





read the original abstract
Large language model agents are increasingly envisioned as always-on personal assistants with access to anything relevant in the user's digital world. Yet current systems operate over only narrow slices of that world, limiting context-sensitive reasoning and effective assistance. Existing benchmarks similarly provide only partial user state and therefore fail to capture performance in such a broad, always-on setting. To address this gap, we introduce Claw-Anything, a benchmark that expands agent context along three dimensions: long-horizon activity histories, interdependent backend services, and integrated GUI and CLI interaction across multiple devices. To instantiate this setting, we simulate months of user activity through multi-round event injection, producing complex world states and realistic noise, including irrelevant events and conflicting signals. Agents must reason over rich contextual environments while remaining robust to such noise. This expanded scope also enables the evaluation of proactive assistance, requiring agents to anticipate user needs and deliver timely recommendations. Experiments show that GPT-5.5 achieves only 34.5% pass@1, substantially below prior benchmarks, underscoring a gap between current agent capabilities and the demands of always-on personal assistance. Alongside the benchmark, we release an automated data-generation pipeline that yields 2,000 training environments and improves the base model by 23.7%, demonstrating its utility of scalable data infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Claw-Anything, a benchmark expanding agent evaluation to always-on personal assistants with long-horizon activity histories, interdependent backend services, and integrated GUI/CLI access across devices. It instantiates this via multi-round event injection to simulate months of user activity, generating complex world states with noise including irrelevant events and conflicting signals. Experiments report GPT-5.5 at 34.5% pass@1 (below prior benchmarks), and release an automated pipeline generating 2,000 training environments that improves the base model by 23.7%.
Significance. If the simulated environments are shown to be representative, the work would usefully quantify a capability gap for always-on assistance and provide a scalable data-generation pipeline as a concrete resource for training. The pipeline's reported 23.7% improvement is a positive, reproducible-style contribution if the evaluation protocol is fully specified.
major comments (2)
- [Abstract and benchmark instantiation] Abstract and benchmark instantiation paragraph: the central claim that 34.5% pass@1 demonstrates a gap between current agents and always-on demands rests on the assumption that multi-round event injection produces world states whose difficulty and noise distribution match real deployments, yet the manuscript supplies no quantitative checks (event-rate histograms, dependency depth distributions, noise-to-signal ratios, or inter-rater realism scores) against real user logs or data. This validation gap is load-bearing for interpreting the headline result.
- [Experiments] Experiments section (headline result): pass@1, task construction details, baseline comparisons, and statistical significance are referenced in the abstract but the provided text gives no definition of pass@1, no description of how tasks are sampled or validated, and no comparison protocol, preventing assessment of whether the 34.5% figure is comparable to prior benchmarks.
minor comments (1)
- [Abstract] Abstract: the 23.7% training improvement is stated without specifying the base model, evaluation split, or whether the improvement is measured on the same benchmark tasks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. Below we respond point-by-point to the two major comments, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and benchmark instantiation] Abstract and benchmark instantiation paragraph: the central claim that 34.5% pass@1 demonstrates a gap between current agents and always-on demands rests on the assumption that multi-round event injection produces world states whose difficulty and noise distribution match real deployments, yet the manuscript supplies no quantitative checks (event-rate histograms, dependency depth distributions, noise-to-signal ratios, or inter-rater realism scores) against real user logs or data. This validation gap is load-bearing for interpreting the headline result.
Authors: We agree that direct quantitative validation against real user logs would strengthen the interpretation of the headline result. Such logs are not available to us due to privacy constraints, so the environments were constructed from domain-expert specifications of typical long-horizon activity patterns, service interdependencies, and noise sources. We will revise the benchmark instantiation section to report the concrete simulation parameters (event-rate distributions, dependency depths, and noise injection rules) and add an explicit limitations paragraph discussing the absence of real-log calibration. This is a partial revision. revision: partial
-
Referee: [Experiments] Experiments section (headline result): pass@1, task construction details, baseline comparisons, and statistical significance are referenced in the abstract but the provided text gives no definition of pass@1, no description of how tasks are sampled or validated, and no comparison protocol, preventing assessment of whether the 34.5% figure is comparable to prior benchmarks.
Authors: The full manuscript contains these definitions and protocols in the Experiments section, but they are not stated with sufficient prominence. We will revise the Experiments section to define pass@1 explicitly at the outset, describe the task-sampling procedure from the generated environments, detail the validation steps, and specify the exact comparison protocol with prior benchmarks. The abstract will be updated to point readers to these definitions. This revision will be made. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a benchmark via simulated multi-round event injection and reports direct experimental metrics (e.g., GPT-5.5 pass@1) without any equations, parameter fitting, or self-citations that reduce results to inputs by construction. The simulation is presented as an independent generation pipeline rather than a fitted model whose outputs are then relabeled as predictions; no load-bearing self-citation chains or ansatzes appear in the provided text. The central claim rests on external measurement against the generated environments, satisfying the criteria for a self-contained benchmark presentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated multi-round event injection with irrelevant and conflicting signals produces evaluation conditions representative of real user digital worlds
Reference graph
Works this paper leans on
-
[1]
Gym-Anything: Turn any Software into an Agent Environment
Pranjal Aggarwal, Graham Neubig, and Sean Welleck. Gym-anything: Turn any software into an agent environment.arXiv preprint arXiv:2604.06126, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Introducing claude sonnet 4.5
Anthropic. Introducing claude sonnet 4.5. https://www.anthropic.com/news/claude-sonnet-4-5 , September 2025
2025
-
[3]
Introducing claude opus 4.7
Anthropic. Introducing claude opus 4.7. https://www.anthropic.com/news/claude-opus-4-7 ,
-
[4]
Anthropic news release, accessed: 2026-04-28
2026
-
[5]
Wildclawbench
Shuangrui Ding, Xuanlang Dai, Long Xing, Shengyuan Ding, Ziyu Liu, Jingyi Yang, Penghui Yang, Zhixiong Zhang, Xilin Wei, Yubo Ma, Haodong Duan, Jing Shao, Jiaqi Wang, Dahua Lin, Kai Chen, and Yuhang Zang. Wildclawbench. https://github.com/InternLM/WildClawBench, 2026. GitHub repository
2026
-
[6]
ClawMark: A living-world benchmark for multi-day, multimodal coworker agents
Evolvent AI. ClawMark: A living-world benchmark for multi-day, multimodal coworker agents. https: //github.com/evolvent-ai/ClawMark, 2026. GitHub repository
2026
-
[7]
One cli for all of google workspace — built for humans and ai agents
Google Workspace. One cli for all of google workspace — built for humans and ai agents. https: //github.com/googleworkspace/cli, 2026. GitHub repository, accessed 2026-04-24
2026
-
[8]
CLI-Anything: Making all software agent-native
HKUDS Team. CLI-Anything: Making all software agent-native. https://github.com/HKUDS/ CLI-Anything, 2026. GitHub repository, accessed 2026-04-24
2026
-
[9]
Nanobot: The ultra-lightweight personal ai agent
HKUDS Teams. Nanobot: The ultra-lightweight personal ai agent. https://github.com/HKUDS/ nanobot, 2026. GitHub repository
2026
-
[10]
Openharness: Open agent harness with a built-in personal agent–ohmo! https: //github.com/HKUDS/OpenHarness, 2026
HKUDS Teams. Openharness: Open agent harness with a built-in personal agent–ohmo! https: //github.com/HKUDS/OpenHarness, 2026. GitHub repository
2026
-
[11]
Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations (ICLR), 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[12]
PinchBench: Real-world benchmarks for ai coding agents
kilo.ai. PinchBench: Real-world benchmarks for ai coding agents. https://github.com/pinchbench/ skill, 2026. GitHub repository
2026
-
[13]
lark-cli: The official lark/feishu cli for humans and ai agents
Larksuite. lark-cli: The official lark/feishu cli for humans and ai agents. https://github.com/ larksuite/cli, 2026. GitHub repository, accessed 2026-04-24
2026
-
[14]
Yusong Lin, Haiyang Wang, Shuzhe Wu, Lue Fan, Feiyang Pan, Sanyuan Zhao, and Dandan Tu. Cli-gym: Scalable cli task generation via agentic environment inversion.arXiv preprint arXiv:2602.10999, 2026
-
[15]
Minimax-m2.7
MiniMax-AI. Minimax-m2.7. https://huggingface.co/MiniMaxAI/MiniMax-M2.7, 2026. Hugging Face model repository, version 2.7, accessed: 2026-04-28
2026
-
[16]
Kimi k2.6: Advancing open-source coding
Moonshot AI. Kimi k2.6: Advancing open-source coding. https://www.kimi.com/blog/kimi-k2-6, 2026
2026
-
[17]
A lightweight alternative to openclaw that runs in containers for security
NanoClaw Teams. A lightweight alternative to openclaw that runs in containers for security. https: //github.com/qwibitai/nanoclaw, 2026. GitHub repository
2026
-
[18]
Hermes agent: The agent that grows with you
NousResearch. Hermes agent: The agent that grows with you. https://github.com/nousresearch/ hermes-agent, 2026
2026
-
[19]
Introducing gpt-5.5
OpenAI. Introducing gpt-5.5. https://openai.com/zh-Hans-CN/index/introducing-gpt-5-5/ ,
-
[20]
OpenAI blog post, accessed: 2026-04-28
2026
-
[21]
Openclaw: Open-source personal ai assistant
OpenClaw. Openclaw: Open-source personal ai assistant. https://github.com/openclaw/openclaw,
-
[22]
Training Software Engineering Agents and Verifiers with SWE-Gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym.arXiv preprint arXiv:2412.21139, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Qwen3.5: Towards native multimodal agents
Qwen. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qwen3.5, February 2026
2026
-
[24]
Qwen3.6-27B: Flagship-level coding in a 27B dense model
Qwen. Qwen3.6-27B: Flagship-level coding in a 27B dense model. https://qwen.ai/blog?id=qwen3. 6-27b, April 2026
2026
-
[25]
QwenClawBench: Real-user-distribution benchmark for openclaw agents
Alibaba Group Qwen Team. QwenClawBench: Real-user-distribution benchmark for openclaw agents. https://github.com/SKYLENAGE-AI/QwenClawBench, April 2026. GitHub repository
2026
-
[26]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[27]
Proagentbench: Evaluating llm agents for proactive assistance with real-world data
Yuanbo Tang, Huaze Tang, Tingyu Cao, Lam Nguyen, Anping Zhang, Xinwen Cao, Chunkang Liu, Wenbo Ding, and Yang Li. Proagentbench: Evaluating llm agents for proactive assistance with real-world data. arXiv preprint arXiv:2602.04482, 2026
-
[28]
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces
Terminal-Bench Teams. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[29]
Contextagent: Context-aware proactive LLM agents with open-world sensory perceptions
Bufang Yang, Lilin Xu, Liekang Zeng, Kaiwei Liu, Siyang Jiang, Wenrui Lu, Hongkai Chen, Xiaofan Jiang, Guoliang Xing, and Zhenyu Yan. Contextagent: Context-aware proactive LLM agents with open-world sensory perceptions. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[30]
SWE-smith: Scaling data for software engineering agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. SWE-smith: Scaling data for software engineering agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (NeurIPS), 2025
2025
-
[31]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Glm-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1, 2026
ZAI. Glm-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1, 2026
2026
-
[33]
Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao, Xuan Lu, Wendong Xu, Yunzhuo Hao, Songcheng Cai, Xiaochen Wang, Huaisong Zhang, Xian Wu, Yi Lu, Minyi Lei, Kai Zou, Huifeng Yin, Ping Nie, Liang Chen, Dongfu Jiang, Wenhu Chen, and Kelsey R. Allen. Clawbench: Can ai agents complete everyday online tasks?arXiv preprint arXiv:2604.08523, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Featurebench: Benchmarking agentic coding for complex feature development
Qixing Zhou, JiaCheng Zhang, Haiyang Wang, Rui Hao, Jiahe Wang, Minghao Han, Yuxue Yang, Shuzhe Wu, Feiyang Pan, Lue Fan, Dandan Tu, and Zhaoxiang Zhang. Featurebench: Benchmarking agentic coding for complex feature development. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[35]
SWE Context Bench: A Benchmark for Context Learning in Coding
Jared Zhu, Minhao Hu, and Junde Wu. Swe context bench: A benchmark for context learning in coding. arXiv preprint arXiv:2602.08316, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, et al. Termigen: High-fidelity environment and robust trajectory synthesis for terminal agents.arXiv preprint arXiv:2602.07274, 2026. 11 A Details of Task Generation Pipeline A.1 Persona Creation and Enrichment In the generation of our ...
-
[37]
Do not use any other names
Service names in i n v o l v e d _ s e r v i c e s must be one of these : { a l l o w e d _ s e r v i c e s _ l i s t }. Do not use any other names
-
[38]
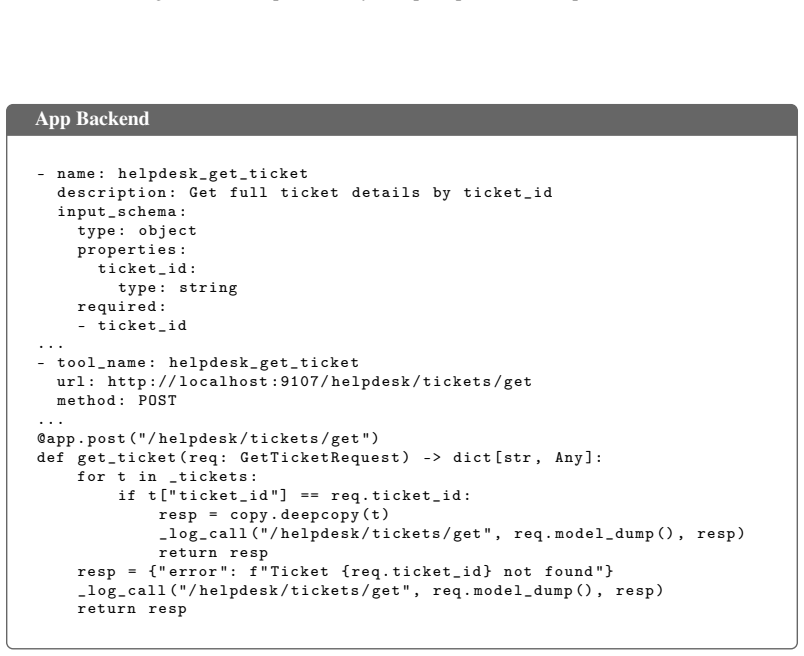
The adapted task must n a t u r a l l y fit the user ’ s role ({ role }) , in du st ry ({ in du st ry }) , and daily r e s p o n s i b i l i t i e s . ... Figure 12: Persona-specific event instantiation: prompt for adapting a seed task 17 Prompt for Generating App Data You are an e n t e r p r i s e bus in es s data g e n e r a t i o n expert . Your job i...
-
[39]
records
** Cross - service r e f e r e n c e c o n s i s t e n c y **: If an email m en tio ns a customer , that c us to me r must exist in CRM ; if a ticket m ent io ns a product , that product must exist in i n v e n t o r y . Email senders should c o r r e s p o n d to c on ta ct s in the co nt act s service . ... ## Output Format Output in JSON format with th...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.