Pixel-Level Pavement Distress Assessment Using Instance Segmentation
Pith reviewed 2026-06-29 22:34 UTC · model grok-4.3
The pith
Mask R-CNN instance segmentation produces pixel-level masks that let aggregate crack area on pavement images match manual ground truth to within 0.006 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
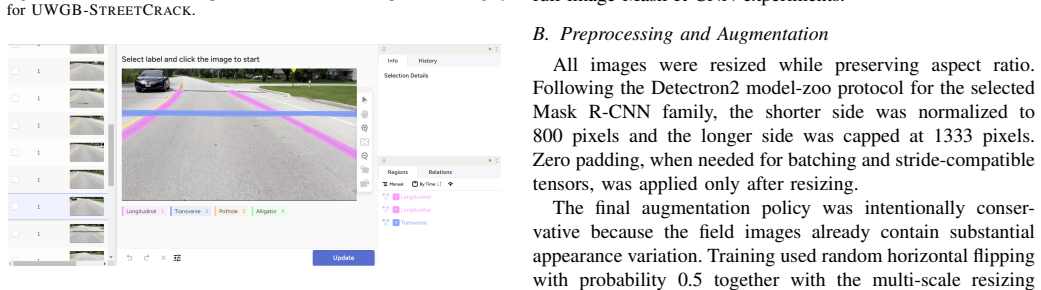
A Mask R-CNN model with ResNet-101 FPN backbone, fine-tuned on the UWGB-StreetCrack dataset of polygon-annotated roadway images, localizes longitudinal, transverse, alligator cracks and potholes at the pixel level and yields an aggregate crack-area fraction of 2.164 percent that closely matches the 2.170 percent ground-truth fraction, while attaining 84.23 percent precision, 90.04 percent recall and 87.04 percent F1 under the project's bounding-box protocol.
What carries the argument
Mask R-CNN instance segmentation that outputs per-object binary masks rather than bounding boxes, applied to a vehicle-mounted smartphone image dataset with manual polygon labels for four distress types.
If this is right
- Pixel-level masks enable direct computation of distress area instead of coarse bounding-box approximations.
- Instance segmentation supplies a workable route to aggregate quantification on ordinary field photographs.
- The same model family outperforms a CSPDarknet53 YOLO detector by a wide margin on the identical validation protocol.
- Close numerical agreement on total crack fraction demonstrates that segmentation outputs can support maintenance-relevant measurements.
Where Pith is reading between the lines
- The resulting area totals could be fed directly into pavement-management databases to rank road segments by total distress load.
- Processing sequential frames from a moving vehicle would allow the same masks to track how individual cracks grow between inspections.
- Reducing reliance on single-annotator polygons would require multi-expert consensus labels or synthetic data augmentation to improve robustness.
Load-bearing premise
The human-drawn polygon annotations on the images accurately trace the true boundaries of each distress without systematic bias or inconsistency that would affect both training and the area-fraction comparison.
What would settle it
Acquire a fresh set of pavement images, obtain independent polygon annotations from multiple experts, and test whether the model's predicted aggregate crack-area fraction still lies within 0.01 percentage points of the averaged ground-truth fraction.
Figures


read the original abstract
Automated pavement distress assessment requires more than image-level classification or coarse bounding box detection, demanding precise localization of thin, branching, and irregular cracks to achieve the geometric precision necessary for maintenance-relevant quantification. This paper presents a vision-based pavement distress analysis system based on Mask R-CNN instance segmentation and evaluates it on UWGB-StreetCrack, a custom field-collected roadway image dataset acquired with a vehicle-mounted smartphone and manually annotated with polygon labels for longitudinal cracks, transverse cracks, alligator cracks, and potholes. Five Detectron2-based Mask R-CNN backbone variants were considered under a consistent fine-tuning protocol. The best-performing model, Mask R-CNN with a ResNet-101 FPN backbone, achieved 84.23% precision, 90.04% recall, and an F1 score of 87.04% under the project-specific bounding-box matching protocol. The same model produced an aggregate predicted crack-area fraction of 2.164%, closely matching the 2.170% ground-truth crack-area fraction. To contextualize the segmentation system against a detector-oriented alternative, a CSPDarknet53-based YOLO detector was also adapted and retrained on the dataset, reaching 27.5% precision and 20.7% recall on the validation protocol. The results show that instance segmentation is a practical direction for field pavement imagery and aggregate crack-area estimation, while also exposing open challenges in annotation consistency, class imbalance, confounder rejection, and mask-level benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a Mask R-CNN instance segmentation system for pixel-level pavement distress assessment (longitudinal, transverse, alligator cracks, and potholes) on the custom UWGB-StreetCrack smartphone-collected dataset with manual polygon annotations. Five Detectron2 backbones are fine-tuned; the ResNet-101 FPN variant reports 84.23% precision, 90.04% recall, and 87.04% F1 under a project-specific bounding-box protocol, plus an aggregate predicted crack-area fraction of 2.164% that closely matches the 2.170% ground-truth fraction. A CSPDarknet53 YOLO detector is retrained for comparison, reaching 27.5% precision and 20.7% recall.
Significance. If the quantitative claims hold under proper validation, the work demonstrates that instance segmentation can deliver maintenance-relevant geometric metrics (pixel-area fractions) on field imagery where bounding-box detectors fall short, addressing a practical gap in automated pavement assessment.
major comments (3)
- [Abstract] Abstract: the central claim that the 2.164% vs. 2.170% crack-area fraction match demonstrates 'geometric precision necessary for maintenance-relevant quantification' is undermined because the same manual polygon annotations supply both the training targets and the reference area fraction; any consistent annotator bias in crack width, branch inclusion, or boundary placement is learned and reproduced, making the 0.006% difference uninformative without inter-annotator agreement, repeated labeling, or external reference (e.g., laser scan).
- [Abstract] Abstract: no validation-split details, error bars, post-hoc exclusions, or annotation inter-rater reliability are reported, so the precision/recall/F1 numbers for the ResNet-101 model cannot be assessed for robustness or generalizability.
- [Abstract] Abstract: the YOLO comparison (27.5% precision, 20.7% recall) is presented without confirming that the bounding-box matching protocol, image splits, and evaluation conditions were identical to those used for Mask R-CNN, preventing a controlled assessment of segmentation versus detection.
minor comments (1)
- The abstract refers to a 'project-specific bounding-box matching protocol' without definition or reference to a methods section; explicit description is needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 2.164% vs. 2.170% crack-area fraction match demonstrates 'geometric precision necessary for maintenance-relevant quantification' is undermined because the same manual polygon annotations supply both the training targets and the reference area fraction; any consistent annotator bias in crack width, branch inclusion, or boundary placement is learned and reproduced, making the 0.006% difference uninformative without inter-annotator agreement, repeated labeling, or external reference (e.g., laser scan).
Authors: We agree that the reported crack-area fraction comparison is derived from the same annotations used in training and therefore cannot independently demonstrate geometric precision free of annotator bias. We will revise the abstract to remove or substantially qualify the claim regarding 'geometric precision necessary for maintenance-relevant quantification' and add a limitations paragraph discussing reliance on single-annotator polygons. revision: yes
-
Referee: [Abstract] Abstract: no validation-split details, error bars, post-hoc exclusions, or annotation inter-rater reliability are reported, so the precision/recall/F1 numbers for the ResNet-101 model cannot be assessed for robustness or generalizability.
Authors: We will add explicit details on the validation split (image counts and class distribution) and state that the metrics come from a single fixed split without cross-validation or error bars. Inter-rater reliability was not computed. These clarifications will be inserted in the methods and results sections. revision: yes
-
Referee: [Abstract] Abstract: the YOLO comparison (27.5% precision, 20.7% recall) is presented without confirming that the bounding-box matching protocol, image splits, and evaluation conditions were identical to those used for Mask R-CNN, preventing a controlled assessment of segmentation versus detection.
Authors: The same image splits were used for both models. YOLO evaluation follows a bounding-box IoU protocol while Mask R-CNN metrics are obtained by converting predicted masks to boxes; we will explicitly document these protocol differences and confirm the shared splits in the revised methods and results sections. revision: partial
- We cannot supply inter-annotator agreement statistics, repeated labeling, or external ground truth (e.g., laser scans) because the dataset was annotated by a single individual without such measures.
Circularity Check
No significant circularity; standard supervised evaluation on held-out data.
full rationale
The paper reports empirical performance metrics (precision, recall, F1) and an aggregate crack-area fraction comparison from Mask R-CNN trained on manually annotated UWGB-StreetCrack images and evaluated on held-out validation images. No mathematical derivation, functional form, or parameter fitting is present that reduces to its own inputs by construction. The area-fraction match is a direct comparison of model output to ground-truth labels on the test set, which is the standard non-circular outcome of supervised learning. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps for the central claims. The work is self-contained against external benchmarks (held-out image evaluation) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Girshick. Mask r-cnn. In2017 IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017
2017
-
[2]
Cracktree: Automatic crack detection from pavement images.Pattern Recognition Letters, 33(3):227–238, 2012
Qin Zou, Yu Cao, Qingquan Li, Qingzhou Mao, and Song Wang. Cracktree: Automatic crack detection from pavement images.Pattern Recognition Letters, 33(3):227–238, 2012
2012
-
[3]
Automatic road crack detection using random structured forests.IEEE Transactions on Intelligent Transportation Systems, 17(12):3434–3445, 2016
Yong Shi, Limeng Cui, Zhiquan Qi, Fan Meng, and Zhensong Chen. Automatic road crack detection using random structured forests.IEEE Transactions on Intelligent Transportation Systems, 17(12):3434–3445, 2016
2016
-
[4]
Road crack detection using deep convolutional neural network
Lei Zhang, Fan Yang, Yimin Daniel Zhang, and Ying Julie Zhu. Road crack detection using deep convolutional neural network. In2016 IEEE international conference on image processing (ICIP), pages 3708–3712. IEEE, 2016
2016
-
[5]
Zhun Fan, Yuming Wu, Jiewei Lu, and Wenji Li. Automatic pavement crack detection based on structured prediction with the convolutional neural network.arXiv preprint arXiv:1802.02208, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
U-net: Con- volutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Con- volutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors,Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing
2015
-
[7]
Deepcrack: Learning hierarchical convolutional features for crack detection.IEEE transactions on image processing, 28(3):1498– 1512, 2018
Qin Zou, Zheng Zhang, Qingquan Li, Xianbiao Qi, Qian Wang, and Song Wang. Deepcrack: Learning hierarchical convolutional features for crack detection.IEEE transactions on image processing, 28(3):1498– 1512, 2018
2018
-
[8]
FPCNet: Fast Pavement Crack Detection Network Based on Encoder-Decoder Architecture
Wenjun Liu, Yuchun Huang, Ying Li, and Qi Chen. Fpcnet: Fast pave- ment crack detection network based on encoder-decoder architecture. arXiv preprint arXiv:1907.02248, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[9]
Encoder–decoder network for pixel-level road crack detection in black- box images.Computer-Aided Civil and Infrastructure Engineering, 34(8):713–727, 2019
Seongdeok Bang, Somin Park, Hongjo Kim, and Hyoungkwan Kim. Encoder–decoder network for pixel-level road crack detection in black- box images.Computer-Aided Civil and Infrastructure Engineering, 34(8):713–727, 2019
2019
-
[10]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015
2015
-
[11]
M. G. Sarwar Murshed, Keivan Bahmani, Stephanie Schuckers, and Faraz Hussain. Deep age-invariant fingerprint segmentation system. IEEE Transactions on Biometrics, Behavior, and Identity Science, 7(3):313–330, 2025
2025
-
[12]
Deep learning frameworks for pavement distress classification: A comparative analysis
Vishal Mandal, Abdul Rashid Mussah, and Yaw Adu-Gyamfi. Deep learning frameworks for pavement distress classification: A comparative analysis. pages 5577–5583, 2020
2020
-
[13]
Hu, Bao L
Guo X. Hu, Bao L. Hu, Zhong Yang, Li Huang, and Ping Li. Pavement crack detection method based on deep learning models.Wireless Communications and Mobile Computing, 2021(1):5573590, 2021
2021
-
[14]
The road crack detection algorithm improved based on yolov7
Xin Liang and Maoting Gao. The road crack detection algorithm improved based on yolov7. InProceedings of the 2024 International Conference on Generative Artificial Intelligence and Information Secu- rity, pages 335–339, 2024
2024
-
[15]
Gsbyolo: A lightweight multi-scale fusion network for road crack detection in complex environments.Scientific Reports, 15(1):26615, 2025
Yuhao Wang, Heran Zhu, Yirong Wang, Jianping Liu, Jun Xie, Bi Zhao, and Siyue Zhao. Gsbyolo: A lightweight multi-scale fusion network for road crack detection in complex environments.Scientific Reports, 15(1):26615, 2025
2025
-
[16]
Pavement crack detection and segmentation method based on improved deep learning fusion model.Mathematical Problems in Engineering, 2020(1):8515213, 2020
Xiaoran Feng, Liyang Xiao, Wei Li, Lili Pei, Zhaoyun Sun, Zhidan Ma, Hao Shen, and Huyan Ju. Pavement crack detection and segmentation method based on improved deep learning fusion model.Mathematical Problems in Engineering, 2020(1):8515213, 2020
2020
-
[17]
Automated pavement crack detection and segmentation based on two-step convolutional neural network
Jingwei Liu, Xu Yang, Stephen Lau, Xin Wang, Sang Luo, Vincent Cheng-Siong Lee, and Ling Ding. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Computer-Aided Civil and Infrastructure Engineering, 35(11):1291– 1305, 2020
2020
-
[18]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariha- ran, and Serge Belongie. Feature pyramid networks for object detection. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 936–944, 2017
2017
-
[19]
Pavement crack instance segmentation using yolov7-wmf with connected feature fusion.Automation in Construction, 160:105331, 2024
Guanting Ye, Sai Li, Manxu Zhou, Yifei Mao, Jinsheng Qu, Tieyu Shi, and Qiang Jin. Pavement crack instance segmentation using yolov7-wmf with connected feature fusion.Automation in Construction, 160:105331, 2024
2024
-
[20]
Research on real- time detection algorithm for pavement cracks based on sparseinst-cdsm
Shao-Jie Wang, Ji-Kai Zhang, and Xiao-Qi Lu. Research on real- time detection algorithm for pavement cracks based on sparseinst-cdsm. Mathematics, 11(15):3277, 2023
2023
-
[21]
Distress identification manual for the long-term pavement performance program
John S Miller, William Y Bellinger, et al. Distress identification manual for the long-term pavement performance program. Technical report, United States. Federal Highway Administration. Office of Infrastruc- ture . . . , 2003
2003
-
[22]
Detectron2
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2. https://github.com/facebookresearch/detectron2, 2019
2019
-
[23]
Automatic pavement crack detection based on structured prediction with the convolutional neural network, 2018
Zhun Fan, Yuming Wu, Jiewei Lu, and Wenji Li. Automatic pavement crack detection based on structured prediction with the convolutional neural network, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.