Eroding Trust in Real Speech: A Large-Scale Study of Human Audio Deepfake Perception
Pith reviewed 2026-06-30 15:37 UTC · model grok-4.3
The pith
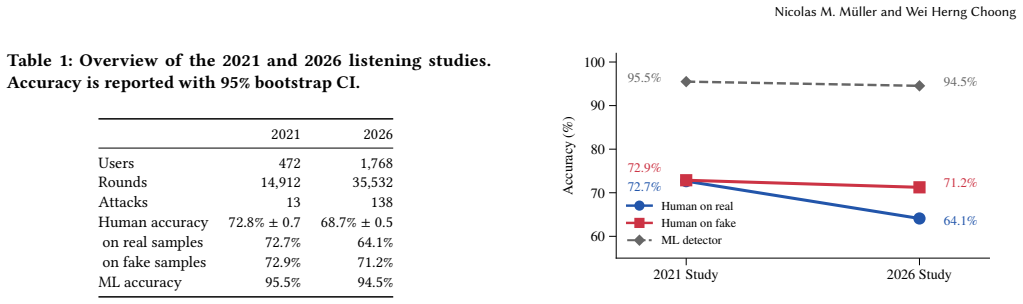
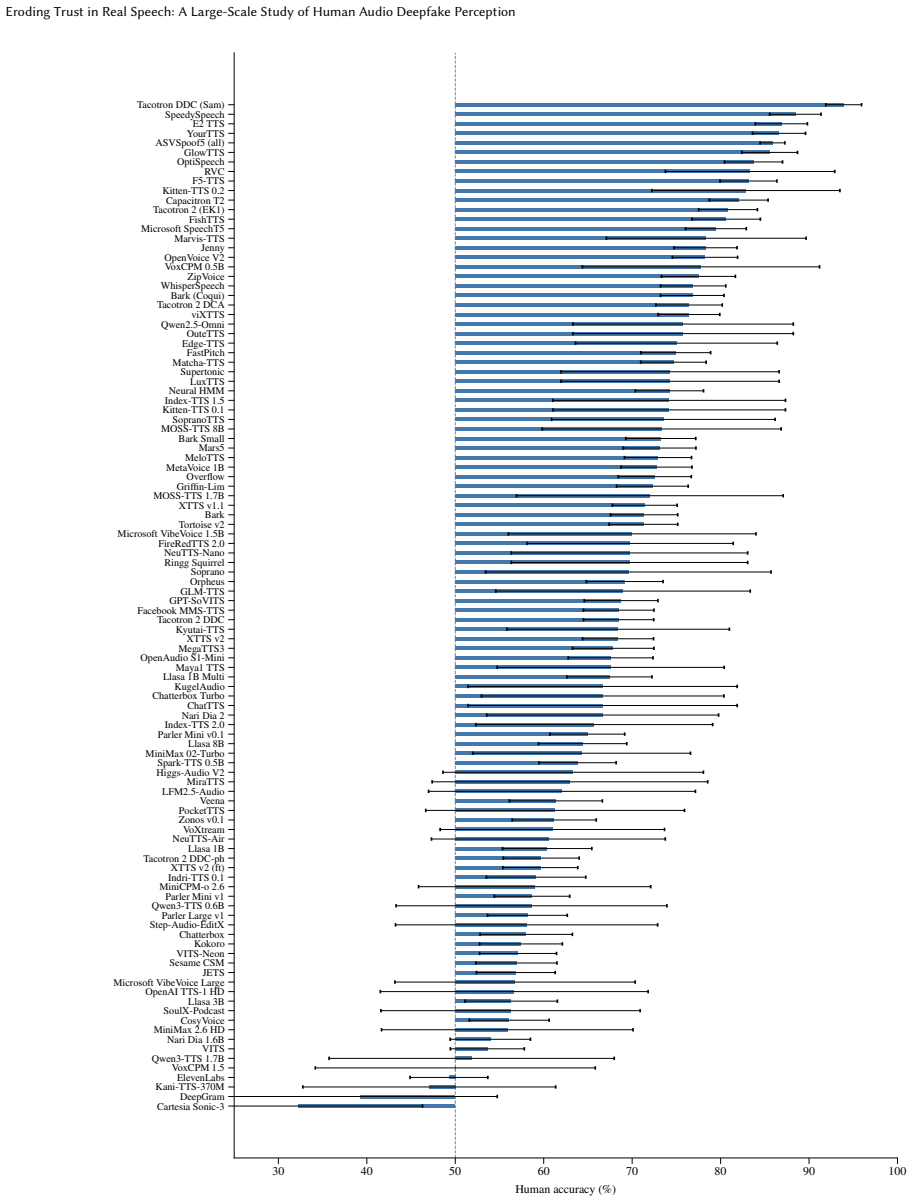
Human accuracy at recognizing real speech fell from 72.7% to 64.1% while accuracy on fakes stayed nearly flat at 71%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
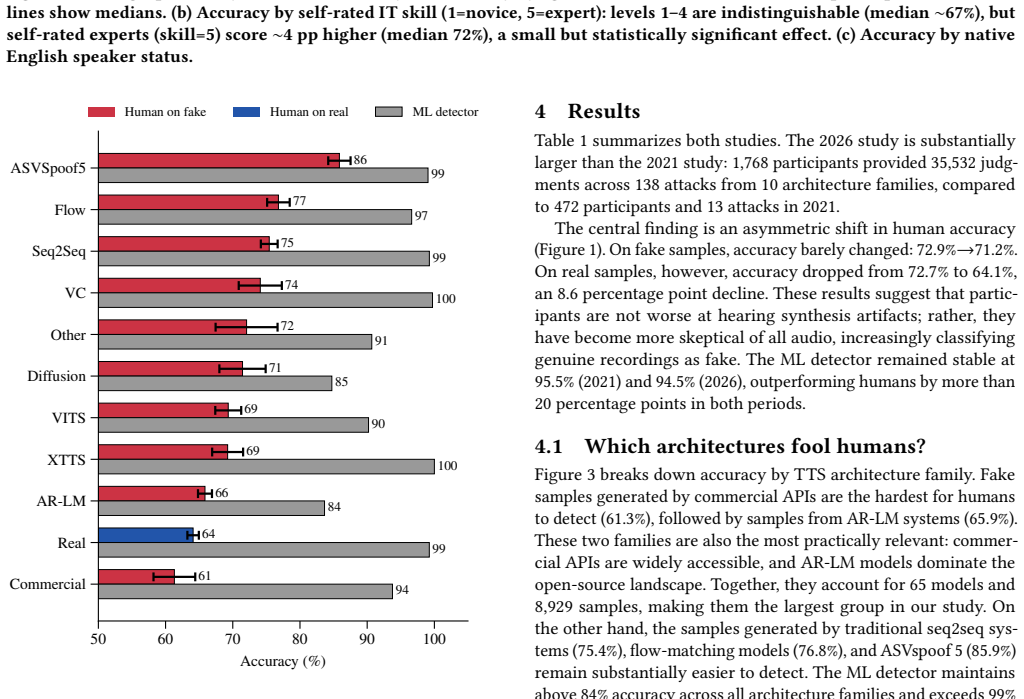
The study establishes a skepticism shift in which accuracy on real speech samples declined from 72.7% in 2021 to 64.1% today while accuracy on fake samples remained nearly constant around 72%. Listeners are not failing to notice synthesis artifacts more often; they are increasingly labeling authentic speech as synthetic. Samples from commercial and autoregressive language-model systems were the most difficult for humans to classify correctly.
What carries the argument
A large-scale listening test that directly compares current participant judgments on real and synthetic speech against a 2021 baseline across 138 text-to-speech and voice-conversion systems.
If this is right
- Voice recordings used as evidence in legal settings would face greater scrutiny even when authentic.
- Systems that rely on voice for authentication would encounter more false rejections from cautious users.
- Detection research would need to shift emphasis toward confirming real speech rather than only identifying fakes.
- Newer commercial and autoregressive synthesis methods would require targeted improvements to match human perception patterns.
Where Pith is reading between the lines
- Public awareness campaigns about deepfake prevalence might need to include calibration exercises so listeners do not over-correct by doubting everything.
- Similar trust erosion could appear in other modalities such as video or text if exposure to high-quality fakes continues to rise.
- Longitudinal studies that track the same individuals over time could separate individual learning effects from population-level shifts in skepticism.
Load-bearing premise
The 2021 baseline study used comparable participant pools, stimuli, and task designs so the drop in real-speech accuracy can be attributed to increased exposure to deepfakes rather than study differences.
What would settle it
A replication that uses the exact same real-speech samples, participant instructions, and demographic matching as the 2021 baseline but collects new judgments today and still finds the same real-speech accuracy as before would falsify the erosion claim.
Figures
read the original abstract
Audio deepfakes have improved rapidly recently, yet their effect on human trust in real speech remains unstudied. We present the largest listening study on audio deepfake perception to date, collecting 35,532 judgments from 1,768 participants across 138 text-to-speech and voice conversion systems. Our central finding is a skepticism shift: compared to a 2021 baseline, human accuracy on fake samples barely changed (72.9% to 71.2%), but accuracy on real samples dropped from 72.7% to 64.1%. Participants are not worse at detecting synthesis artifacts; rather, they increasingly distrust authentic speech. Samples generated by commercial and autoregressive language model systems proved hardest to detect (61.3 - 65.9%), while those from traditional seq2seq and flow-matching models remain easier to spot (75.4 - 76.8%). An ML detector that served as a reference point maintained over 94.5% accuracy across all conditions. Our results suggest that the primary threat posed by modern deepfakes may not be mere deception, but the erosion of trust in genuine audio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a large-scale empirical study on human perception of audio deepfakes, collecting 35,532 judgments from 1,768 participants across 138 synthesis systems. The key finding is a 'skepticism shift': while detection accuracy on fake audio remained roughly stable compared to a 2021 baseline (72.9% to 71.2%), accuracy on real audio declined from 72.7% to 64.1%. The authors interpret this as evidence that the primary threat of deepfakes is eroding trust in genuine speech rather than improving deception. Additional results compare detection difficulty across synthesis architectures and benchmark against an ML detector achieving >94.5% accuracy.
Significance. If the comparison to the 2021 baseline is methodologically sound, this work provides important evidence that exposure to deepfakes may be causing listeners to become more skeptical of authentic audio. The scale of the study (over 1,700 participants) and coverage of modern commercial and autoregressive systems strengthen the empirical contribution. The finding shifts focus from detection to trust erosion, which has implications for audio forensics, media literacy, and deployment of generative audio technologies.
major comments (1)
- [Abstract and Methods (baseline comparison)] The central attribution of the accuracy drop on real samples (72.7% → 64.1%) to increased deepfake exposure requires that the 2021 baseline study be comparable in participant demographics, stimulus selection (number and acoustic variety of real samples), task design, and presentation conditions. The current study is described in detail, but the manuscript does not provide explicit equivalence checks or matching criteria for the baseline. Without this, alternative explanations based on methodological differences cannot be ruled out, undermining the skepticism-shift conclusion.
minor comments (2)
- [Results (system comparisons)] The ranges given for commercial/autoregressive (61.3-65.9%) and traditional models (75.4-76.8%) would benefit from per-system breakdowns or confidence intervals to assess variability.
- [Abstract] Clarify whether the 2021 baseline used the same response format (e.g., binary real/fake judgment) and if any adjustments were made for multiple comparisons in the statistical analysis.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of methodological comparability in our baseline comparison, which underpins the skepticism-shift interpretation. We address this point directly below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Methods (baseline comparison)] The central attribution of the accuracy drop on real samples (72.7% → 64.1%) to increased deepfake exposure requires that the 2021 baseline study be comparable in participant demographics, stimulus selection (number and acoustic variety of real samples), task design, and presentation conditions. The current study is described in detail, but the manuscript does not provide explicit equivalence checks or matching criteria for the baseline. Without this, alternative explanations based on methodological differences cannot be ruled out, undermining the skepticism-shift conclusion.
Authors: We agree that explicit equivalence checks are necessary to support causal attribution to deepfake exposure. The 2021 baseline is drawn from a cited prior study; our original manuscript summarized its key parameters but did not include a side-by-side methodological comparison. In revision we will add a dedicated subsection (likely in Methods or a new Appendix) that tabulates and discusses comparability on the four dimensions raised: (1) participant demographics (age, gender, location, prior exposure to deepfakes where reported), (2) stimulus selection (number of real samples, speaker diversity, acoustic conditions), (3) task design (binary real/fake judgment, instructions, number of trials per participant), and (4) presentation conditions (audio format, duration, platform, volume normalization). Where the baseline paper supplies the requisite details we will report quantitative matches or differences; where data are unavailable we will note the limitation and qualify the interpretation of the accuracy drop. This addition will allow readers to evaluate the strength of the skepticism-shift claim directly. revision: yes
Circularity Check
No circularity: purely empirical reporting of human judgments with external baseline comparison
full rationale
The paper presents results from a large-scale listening study (35,532 judgments) and directly reports observed accuracy rates on real and fake audio samples. The central claim of a 'skepticism shift' is a summary statistic derived from new participant data compared against a cited 2021 baseline study. No equations, fitted parameters, predictions, ansatzes, or derivations appear in the provided text. The comparison to the baseline is an interpretive step resting on methodological equivalence assumptions, but this is an external validity issue rather than any reduction of the result to its own inputs by construction. No self-citations are load-bearing, and the study is self-contained as an empirical report against an independent prior dataset.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 2021 baseline provides a valid counterfactual for measuring change in human perception.
Reference graph
Works this paper leans on
-
[1]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems33 (2020), 12449–12460
2020
- [2]
-
[3]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, et al. 2025. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. InProc. ACL. 6255–6271
2025
-
[4]
Robert Chesney and Danielle Citron. 2019. Deep Fakes: A Looming Challenge for Privacy, Democracy, and National Security.California Law Review107 (2019), 1753–1820
2019
-
[5]
Di Cooke, Abigail Edwards, Sophia Barkoff, and Kathryn Kelly. 2025. As Good as a Coin Toss: Human Detection of AI-Generated Content.Commun. ACM68, 10 (2025)
2025
-
[6]
Deloitte Center for Financial Services. 2024. Generative AI Is Ex- pected to Magnify the Risk of Deepfakes and Other Fraud in Bank- ing. https://www2.deloitte.com/us/en/insights/industry/financial- services/financial-services-industry-predictions/2024/deepfake-banking- fraud-risk-on-the-rise.html
2024
-
[7]
Alexander Diel, Tania Lalgi, Isabel C. Schröter, Karl F. MacDorman, Martin Teufel, and Alexander Bäuerle. 2024. Human Performance in Detecting Deepfakes: A Systematic Review and Meta-Analysis of 56 Papers.Computers in Human Behavior Reports16 (2024). doi:10.1016/j.chbr.2024.100499
-
[8]
Zhihao Du, Qian Chen, et al. 2024. CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer Based on Supervised Semantic Tokens.arXiv preprint arXiv:2407.05407(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
ElevenLabs. 2024. ElevenLabs Text to Speech API. https://elevenlabs.io
2024
-
[10]
FBI San Francisco. 2026. FBI San Francisco Warns Romance Scams Increasing Across the Bay Area This Valentine’s Day. https://www.fbi.gov/contact-us/field- offices/sanfrancisco/fbi-san-francisco-warns-romance-scams-increasing- across-the-bay-area-this-valentines-day
2026
-
[11]
Federal Communications Commission. 2024. Proposed $6 Million Fine Against Political Consultant Who Used AI-Generated Deepfake Robocalls. https://docs. fcc.gov/public/attachments/DOC-402762A1.pdf
2024
-
[12]
Daniel Gover. 2024. Finance worker pays out $25 million after video call with deepfake ‘chief financial officer’.CNN(Feb 2024)
2024
-
[13]
Matthew Groh, Ziv Epstein, Chaz Firestone, and Rosalind Picard. 2022. Deep- fake Detection by Human Crowds, Machines, and Machine-Informed Crowds. Proceedings of the National Academy of Sciences119, 1 (2022)
2022
-
[14]
Keith Ito and Linda Johnson. 2017. The LJ Speech Dataset. https://keithito.com/LJ- Speech-Dataset/
2017
-
[15]
Jaehyeon Kim, Jungil Kong, and Juhee Son. 2021. Conditional Variational Au- toencoder with Adversarial Learning for End-to-End Text-to-Speech. InProc. ICML. 5530–5540
2021
-
[16]
Raghavan, Gavin Mischler, and Nima Mesgarani
Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, and Nima Mesgarani. 2023. StyleTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models. InProc. NeurIPS
2023
-
[17]
Xuechen Liu, Xin Wang, Md Sahidullah, Jose Patino, Héctor Delgado, Tomi Kinnunen, Massimiliano Todisco, Junichi Yamagishi, Nicholas Evans, Andreas Nautsch, and Kong Aik Lee. 2023. ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild.IEEE/ACM Transactions on Audio, Speech and Language Processing(2023)
2023
-
[18]
Bray, Toby O
Khai Tinh Mai, Sergi D. Bray, Toby O. Davies, and Lewis D. Griffin. 2023. Warning: Humans Cannot Reliably Detect Speech Deepfakes.PLOS ONE(2023)
2023
-
[19]
McAfee. 2023. Beware the Artificial Impostor: A McAfee Study on the Rise of AI Scams. https://www.mcafee.com/learn/a-guide-to-deepfake-scams-and-ai- voice-spoofing/
2023
-
[20]
Müller, Pavel Czempin, Franziska Diekmann, Adam Froghyar, and Konstantin Böttinger
Nicolas M. Müller, Pavel Czempin, Franziska Diekmann, Adam Froghyar, and Konstantin Böttinger. 2022. Does Audio Deepfake Detection Generalize?. InProc. Interspeech. 2783–2787
2022
-
[21]
Müller, Piotr Kawa, Wei Herng Choong, et al
Nicolas M. Müller, Piotr Kawa, Wei Herng Choong, et al. 2024. MLAAD: The Multi-Language Audio Anti-Spoofing Dataset. InProc. IJCNN. doi:10.1109/ IJCNN60899.2024.10650962
-
[22]
Müller, Karla Pizzi, and Jennifer Williams
Nicolas M. Müller, Karla Pizzi, and Jennifer Williams. 2022. Human Perception of Audio Deepfakes. InProc. 1st International Workshop on Deepfake Detection for Audio Multimedia (DDAM). 85–91. doi:10.1145/3552466.3556531
-
[23]
Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. 2021. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. InProc. ICML
2021
- [24]
-
[25]
Resemble AI. 2024. Resemble AI Speech Synthesis API. https://www.resemble.ai
2024
-
[26]
Resemble AI. 2025. Chatterbox TTS. https://github.com/resemble-ai/chatterbox
2025
-
[27]
Eugenia San Segundo, Aurora López-Jareño, Xin Wang, and Junichi Yamagishi
- [28]
-
[29]
Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, et al
Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, et al. 2018. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. InProc. ICASSP. 4779–4783
2018
-
[30]
Catherine Stupp. 2019. Fraudsters Used AI to Mimic CEO’s Voice in Unusual Cybercrime Case.The Wall Street Journal(Aug 2019)
2019
-
[31]
Suno AI. 2023. Bark: Text-to-Audio Model. https://github.com/suno-ai/bark
2023
-
[32]
Hemlata Tak, Jose Patino, Massimiliano Todisco, Andreas Nautsch, Nicholas Evans, and Anthony Larcher. 2021. End-to-End Anti-Spoofing with RawNet2. In Proc. ICASSP. 6369–6373
2021
-
[33]
Hemlata Tak, Massimiliano Todisco, Xin Wang, Jee weon Jung, Junichi Yamagishi, and Nicholas Evans. 2022. Automatic Speaker Verification Spoofing and Deepfake Detection Using Wav2Vec 2.0 and Data Augmentation. InProc. Speaker Odyssey
2022
-
[34]
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, et al. 2023. VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers.arXiv preprint arXiv:2301.02111(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Xin Wang, Héctor Delgado, Hemlata Tak, Jee weon Jung, et al. 2025. ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech.Computer Speech & Language(2025)
2025
-
[36]
Xin Wang, Junichi Yamagishi, Massimiliano Todisco, Héctor Delgado, Andreas Nautsch, Nicholas Evans, et al . 2020. ASVspoof 2019: A Large-Scale Public Database of Synthesized, Converted and Replayed Speech.Computer Speech & Language64 (2020), 101114
2020
-
[37]
Kevin Warren, Tyler Tucker, Anna Crowder, Daniel Olszewski, Allison Lu, Car- oline Fedele, Magdalena Pasternak, Seth Layton, Kevin Butler, Carrie Gates, and Patrick Traynor. 2024. Better Be Computer or I’m Dumb: A Large- Scale Evaluation of Humans as Audio Deepfake Detectors. InProc. ACM CCS. doi:10.1145/3658644.3670325
-
[38]
Jee weon Jung, Hee-Soo Heo, Hemlata Tak, Hye jin Shim, Joon Son Chung, Bong- Jin Lee, Ha-Jin Yu, and Nicholas Evans. 2022. AASIST: Audio Anti-Spoofing Using Integrated Spectro-Temporal Graph Attention Networks. InProc. ICASSP. 6367–6371. 6
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.