When Rule Violations Are Rare: Chimera Training for Logical Anomaly Detection
Pith reviewed 2026-06-29 22:35 UTC · model grok-4.3
The pith
Chimera training lets a neural rule evaluator learn to detect logical violations from normal images alone by mixing subtree features across samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
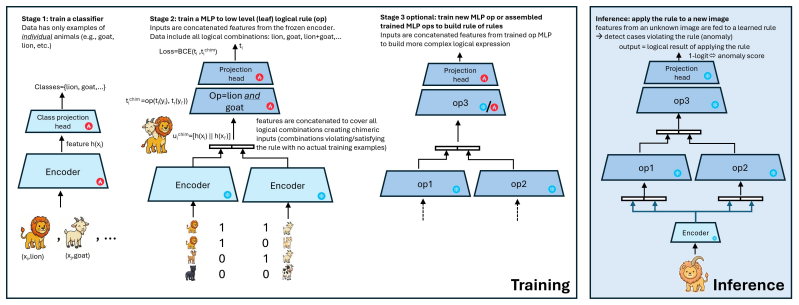
Compiling each logical constraint into a directed acyclic graph and replacing its operators with feature-aware MLP gates, then training those gates with chimera feature mixing, produces a rule evaluator that can assign anomaly scores to rule violations even though no violations are present in the training data.
What carries the argument
Chimera training: an operand-level counterfactual construction that concatenates subtree features drawn from different samples, preserves each operand's original hard truth label, and sets the training target by applying the node's logical operator to those inherited labels.
If this is right
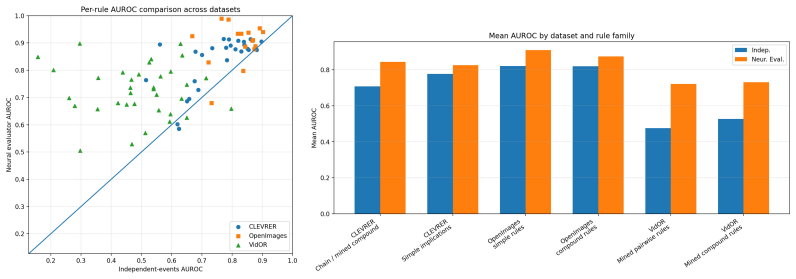
- The evaluator improves rule-level anomaly AUROC over independent-events and same-image semantic-training baselines across CLEVRER, OpenImages, and VidOR.
- Gains are largest for compositional and relational rules.
- The method produces both scalar anomaly scores and rule-level attributions.
- Training requires only normal data and ground-truth concept labels.
Where Pith is reading between the lines
- The same feature-mixing construction could be applied to temporal or spatial rules whose operands come from different time steps or image regions.
- If the subtree features already encode the necessary logical distinctions, the approach may reduce the need for explicit data augmentation or synthetic violation generation in other structured prediction tasks.
- Rule-level attributions produced by the gates could be used to localize which sub-constraints are broken without additional supervision.
Load-bearing premise
Concatenating subtree features from different samples while inheriting their hard truth labels supplies valid and informative supervised logical counterexamples that avoid shortcut solutions and distribution shifts affecting generalization to real data.
What would settle it
On a controlled test set that introduces known rule violations, the chimera-trained evaluator shows no AUROC gain over a same-image semantic baseline.
Figures





read the original abstract
Many practical anomalies are not merely rare inputs, but violations of semantic constraints: objects co-occur in structured ways, actions imply preconditions, and events satisfy temporal or relational regularities. We study anomaly detection in this setting, where constraints are given as logical rules over learned visual concepts, but real rule violations are rare or absent during training. We propose a neural rule evaluator that compiles each constraint into a directed acyclic graph and learns feature-aware subtree MLP gates for its internal logical operators. Each gate maps child features and edge-level negations to a parent representation and a rule-satisfaction probability, with intermediate supervision obtained from exact Boolean propagation over ground-truth concept labels. The key difficulty is that same-image training data often provide insufficient coverage of informative truth configurations and also allow shortcut solutions. To address this, we introduce chimera training: an operand-level counterfactual construction at the feature level. Instead of mixing input images, we concatenate subtree features from different samples; each operand keeps the hard truth label of the sample it came from, and the chimera target is obtained by applying the node's logical operator to those inherited labels. This supplies supervised logical counterexamples without requiring real anomalous images. Across CLEVRER, OpenImages, and VidOR, the resulting evaluator improves rule-level anomaly AUROC over independent-events and same-image semantic-training baselines, especially for compositional and relational rules. The method yields both scalar anomaly scores and rule-level attributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neural rule evaluator for logical anomaly detection in visual data (e.g., object co-occurrences, action preconditions) when real rule violations are absent from training. Logical constraints are compiled into DAGs; each internal node uses a subtree MLP gate that maps child features (with edge negations) to a parent representation and satisfaction probability, with intermediate supervision from exact Boolean propagation on ground-truth concept labels. The core contribution is chimera training: an operand-level feature concatenation across distinct samples that inherits hard truth labels from each operand and applies the node's Boolean operator to produce the target, thereby generating supervised counterexamples. Experiments on CLEVRER, OpenImages, and VidOR report improved rule-level anomaly AUROC relative to independent-events and same-image semantic-training baselines, with gains especially on compositional/relational rules; the model also outputs scalar anomaly scores and rule-level attributions.
Significance. If the chimera construction supplies informative logical counterexamples that generalize without introducing new shortcuts, the approach would be a useful advance for structured anomaly detection, enabling training from normal data alone while also providing attributions. The explicit use of Boolean propagation for supervision and the focus on rule-level rather than instance-level detection are strengths. The significance is tempered by the need to confirm that performance gains reflect genuine logical operator learning rather than artifacts of the synthetic construction.
major comments (2)
- [chimera training description] The central claim that chimera training improves rule-level AUROC rests on the assumption that operand-level feature concatenation from distinct samples yields valid, informative supervised counterexamples (see abstract and the chimera training paragraph). Because the resulting parent representations are formed from cross-sample features, they lie outside the data manifold; the paper must demonstrate that the MLP gates do not exploit mismatched visual statistics or spurious correlations instead of the intended Boolean operators. No ablation isolating this risk (e.g., controlled synthetic tests with known shortcut opportunities or distribution-shift diagnostics) is referenced, leaving the generalization argument load-bearing and unverified.
- [experiments] The reported AUROC gains on compositional and relational rules (abstract) are presented without accompanying quantitative tables, confidence intervals, or per-rule breakdowns in the visible text. To support the claim that improvements are driven by the chimera construction rather than other modeling choices, the experiments section should include ablations that isolate the contribution of cross-sample concatenation versus same-image training and independent-events baselines.
minor comments (2)
- [abstract] The abstract states AUROC improvements but supplies no numerical values; the results section should include the actual AUROC figures, dataset sizes, and number of rules evaluated for reproducibility.
- [method] Notation for the subtree MLP gates (input concatenation, negation handling, output probability) should be formalized with an equation or pseudocode to clarify how the parent representation is produced from child features.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications from the manuscript and commit to revisions that strengthen the presentation of evidence for chimera training.
read point-by-point responses
-
Referee: [chimera training description] The central claim that chimera training improves rule-level AUROC rests on the assumption that operand-level feature concatenation from distinct samples yields valid, informative supervised counterexamples (see abstract and the chimera training paragraph). Because the resulting parent representations are formed from cross-sample features, they lie outside the data manifold; the paper must demonstrate that the MLP gates do not exploit mismatched visual statistics or spurious correlations instead of the intended Boolean operators. No ablation isolating this risk (e.g., controlled synthetic tests with known shortcut opportunities or distribution-shift diagnostics) is referenced, leaving the generalization argument load-bearing and unverified.
Authors: The supervision for each gate is obtained by exact Boolean propagation on the inherited ground-truth concept labels from the operand samples, independent of visual content. The MLP is optimized to output a satisfaction probability matching this label-derived target. This objective requires the gate to implement the logical operator on the provided features; a shortcut based on cross-sample visual mismatch would produce inconsistent predictions whenever the same feature pair is paired with different label combinations, which are exhaustively generated during training. The reported gains are largest on compositional and relational rules, where visual shortcuts are least likely to align with the Boolean targets. We will add a controlled synthetic ablation with known shortcut opportunities and distribution-shift diagnostics in the revision. revision: yes
-
Referee: [experiments] The reported AUROC gains on compositional and relational rules (abstract) are presented without accompanying quantitative tables, confidence intervals, or per-rule breakdowns in the visible text. To support the claim that improvements are driven by the chimera construction rather than other modeling choices, the experiments section should include ablations that isolate the contribution of cross-sample concatenation versus same-image training and independent-events baselines.
Authors: Section 4 of the manuscript contains the full quantitative tables, including per-rule AUROC with confidence intervals and breakdowns by rule type. The main results already compare chimera training against both the independent-events baseline and the same-image semantic-training baseline. We will add an explicit ablation table that further isolates the cross-sample concatenation component and will reference these tables more prominently in the abstract and introduction. revision: yes
Circularity Check
No significant circularity; novel training construction evaluated on external benchmarks
full rationale
The paper introduces chimera training as a feature-level counterfactual construction that concatenates subtree features from distinct samples while inheriting their ground-truth labels and applying the node's logical operator to generate targets. This is a proposed supervised training procedure, not a derivation that reduces to fitted parameters or self-referential definitions. Evaluation occurs on external public datasets (CLEVRER, OpenImages, VidOR) with comparisons to independent-events and same-image baselines. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are load-bearing for the central claim. The method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Logical constraints can be compiled into directed acyclic graphs with learnable MLP gates for operators
invented entities (1)
-
Chimera training
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttp://jmlr.org/papers/v11/ganchev10a.html. Artur S. d’Avila Garcez, Luis C. Lamb, and Dov M. Gabbay.Neural-Symbolic Cognitive Reasoning. Springer, 2009. Robin Manhaeve, Sebastijan Dumanˇci´c, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming. InAdvances in Neural Information Processing Systems (Ne...
work page doi:10.1109/w 2009
-
[2]
For each mini-batch {(xi, yi)}B i=1, compute hard truth targets tv(yi) for all nodes by exact propagation (Algorithm 2). This is where the choice of representing rules by graphs becomes particularly useful and elegant at the implementation level: we use DGL’s dgl.topological_nodes_generator to generate node frontiers using topological traver- sal (each it...
-
[3]
Compute leaf encoder featuresz i =E ϕ(xi)and initialize leaf node features
-
[4]
Propagate through already-trained lower-depth gates (and keep them fixed) to obtain child features for nodes inV d
-
[5]
rule classifier
For eachv∈ V d, update gate parameters by minimizing node-wise BCE: Lv = 1 B BX i=1 BCE ˆtv(xi), t v(yi) .(19) Thisinternal supervisionis crucial: the model learns to implement logical composition locally, rather than only learning a monolithic “rule classifier” at the root. A.6 Chimera negative training: enforcing compositionality and preventing shortcut...
2020
-
[6]
For each mini-batch, compute the hard truths for all nodes by bottom-up propagation from concept labels (so the root target is always 0)
-
[7]
Initialize both leaves with the encoder feature vector z (in this construction both leaves point to the same concept and thus carry the same base evidence), and pass the two child features plus negation flags into the root gate
-
[8]
abnormal
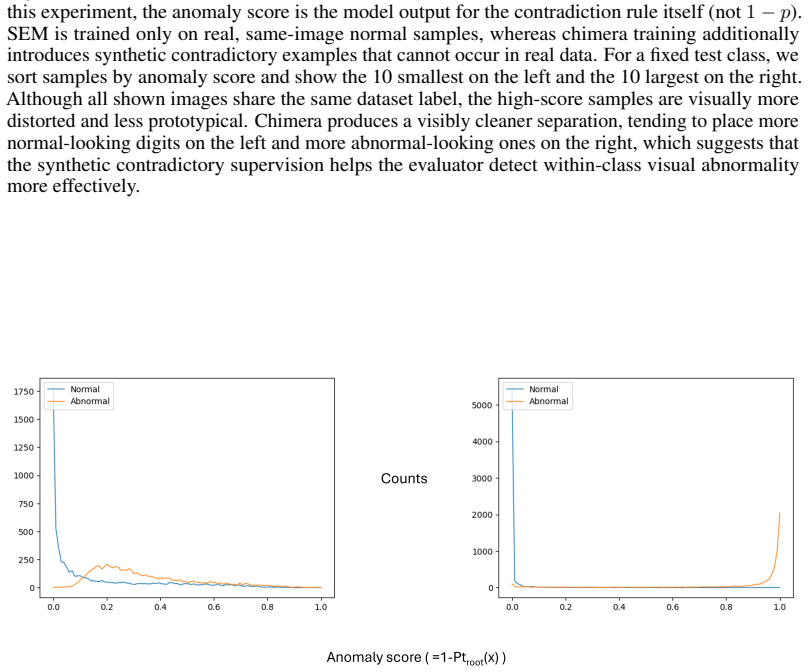
Optimize root-gate BCE loss for a small number of epochs and store the trained gate in the subtree cache keyed by the rule structure and encoder fingerprint. A useful qualitative difference emerges when one sorts the test images of a fixed digit class by the score assigned to this contradiction rule. In this special sanity-check experiment, we use the rul...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.