PitchBench: Measuring Pitch Hearing in Audio-Language Models
Pith reviewed 2026-06-29 21:03 UTC · model grok-4.3
The pith
Audio-language models show unreliable pitch hearing across diverse acoustic conditions and tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
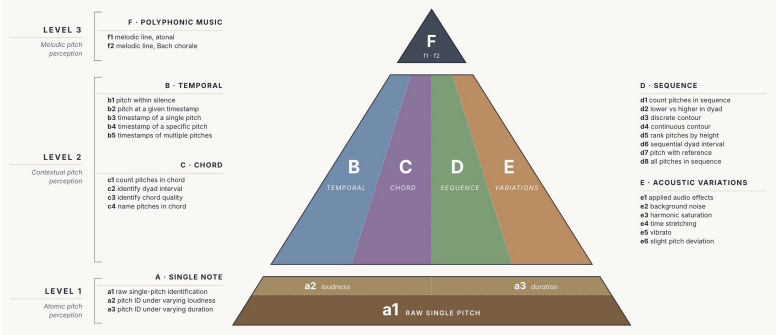
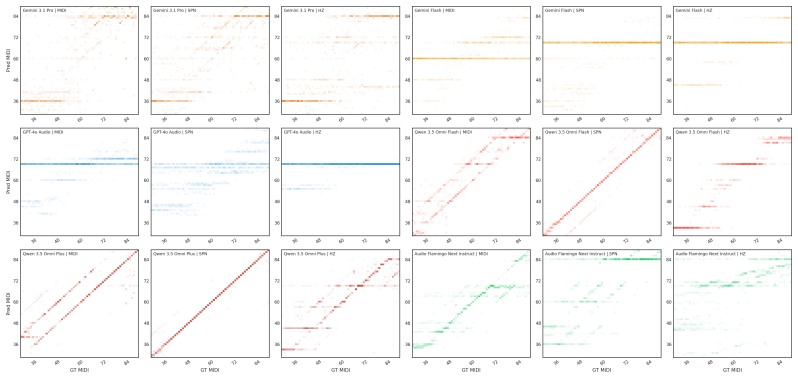
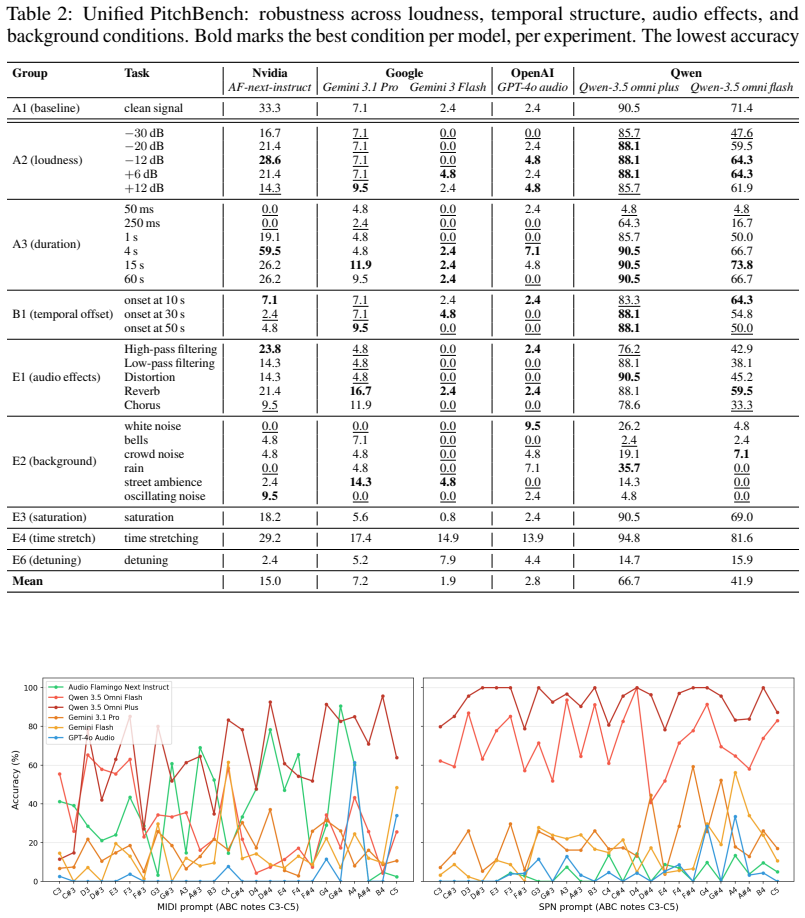
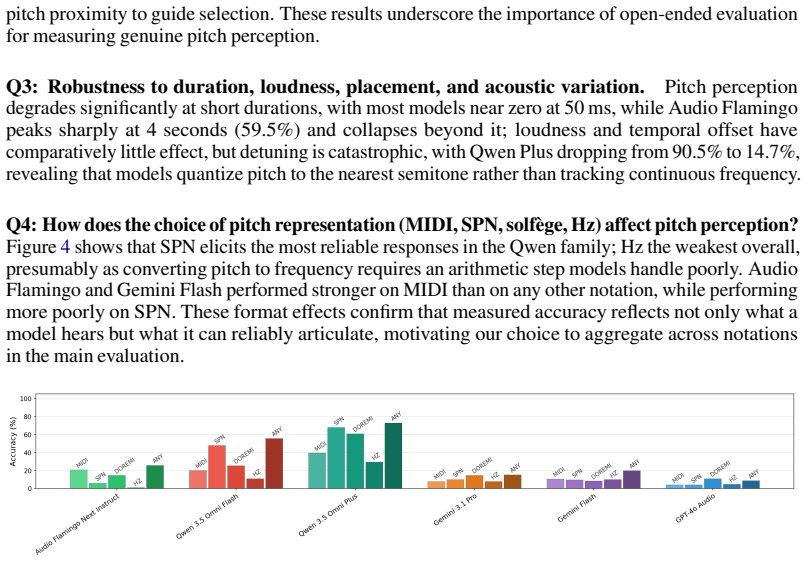
PitchBench comprises 28 experiments spanning absolute and relative pitch perception within sequences and chords, while varying loudness, note duration, sound source, time stretching, background noise, and other acoustic conditions. Tasks range from identifying individual pitches in isolation to tracking a melodic line within a four-part musical texture. Evaluating frontier ALMs, the paper finds that pitch hearing remains highly unreliable: models perform consistently poorly across settings, with accuracy varying sharply by sound source, note duration, and notation format.
What carries the argument
PitchBench, an evaluation suite of 28 experiments that systematically measures pitch hearing by varying acoustic conditions and response formats.
Load-bearing premise
The 28 experiments provide a valid and comprehensive measure of pitch hearing ability that generalizes beyond the tested conditions.
What would settle it
A model achieving consistently high accuracy across all 28 experiments with different sound sources, durations, and formats would falsify the claim of unreliable pitch hearing.
Figures
read the original abstract
Audio-language models (ALMs) are increasingly used in real-world applications that require understanding music, from music tutoring and transcription to captioning, recommendation systems, and music production. More broadly, they are becoming an important component of multimodal AI systems that must reason from sensory input rather than text alone. This makes reliable musical perception a critical prerequisite: if a model cannot accurately hear the structure of sound, it cannot be trusted to reason about, teach, transcribe, or act on audio in the real world. Yet existing benchmarks rarely assess one of the most fundamental musical abilities underlying such perception: pitch hearing. Current evaluations tend to probe pitch hearing only indirectly, through higher-level tasks and often in multiple-choice formats, leaving open how reliably ALMs identify fine-grained pitch across instruments, acoustic conditions, and response formats. We introduce PitchBench, an evaluation suite that systematically measures pitch hearing in ALMs. PitchBench comprises 28 experiments spanning absolute and relative pitch perception within sequences and chords, while varying loudness, note duration, sound source, time stretching, background noise, and other acoustic conditions. Tasks range from identifying individual pitches in isolation to tracking a melodic line within a four-part musical texture. Evaluating frontier ALMs, we find that pitch hearing remains highly unreliable: models perform consistently poorly across settings, with accuracy varying sharply by sound source, note duration, and notation format. Current ALMs do not yet possess stable pitch perception, even for controlled synthetic and instrumental stimuli. Alongside the benchmark, we release PitchBench as a Python package containing the evaluation data and data generation tools to support future work on pitch-aware audio-language modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PitchBench, a benchmark suite comprising 28 experiments that systematically vary acoustic parameters (loudness, note duration, sound source, time stretching, background noise) and task formats (absolute/relative pitch, isolation vs. polyphony, sequences vs. chords) to evaluate pitch hearing in frontier audio-language models (ALMs). The central empirical claim is that these models exhibit consistently poor and unstable performance, with accuracy varying sharply by condition, indicating that current ALMs lack stable pitch perception even on controlled synthetic and instrumental stimuli. The work also releases a Python package with evaluation data and generation tools.
Significance. If the benchmark validity and results hold, the work is significant for highlighting a foundational limitation in ALMs applied to music understanding, transcription, and multimodal reasoning. The explicit release of the Python package with data-generation tools is a clear strength, directly supporting reproducibility and extension by the community. The empirical focus on a core perceptual primitive (pitch) fills a gap left by higher-level music benchmarks.
major comments (2)
- [§3 and §4] §3 (Experimental Design) and §4 (Results): The claim that performance is 'highly unreliable' and 'varies sharply' across the 28 experiments is load-bearing for the central conclusion, yet the manuscript provides insufficient detail on the number of trials per condition, exact statistical tests for variability, and comparison to chance or human baselines; without these, it is unclear whether the reported poor performance generalizes or reflects evaluation artifacts.
- [§2 and §5] §2 (Related Work) and §5 (Discussion): The assertion that existing benchmarks 'rarely assess' pitch hearing directly is used to motivate the new suite, but the paper does not quantify how the 28 experiments avoid the multiple-choice or indirect confounds criticized in prior work, leaving open whether the observed failures are specific to pitch or to ALM prompting/response formats in general.
minor comments (2)
- [Abstract and §1] The abstract and introduction use 'frontier ALMs' without listing the exact model versions, sizes, or access dates in a table; adding this would improve clarity and replicability.
- [Figures and Tables] Figure captions and Table 1 (if present) should explicitly state the total number of stimuli per experiment and the response parsing method to allow readers to assess task difficulty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical support and positioning of PitchBench. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Experimental Design) and §4 (Results): The claim that performance is 'highly unreliable' and 'varies sharply' across the 28 experiments is load-bearing for the central conclusion, yet the manuscript provides insufficient detail on the number of trials per condition, exact statistical tests for variability, and comparison to chance or human baselines; without these, it is unclear whether the reported poor performance generalizes or reflects evaluation artifacts.
Authors: We agree that greater detail on these elements would make the claims more robust. The revised manuscript will expand §3 to report the exact trial counts per condition (100 trials for the majority of the 28 experiments, with 50 for a subset of polyphonic tasks due to computational constraints), include statistical tests (e.g., repeated-measures ANOVA and post-hoc pairwise comparisons with Bonferroni correction) for variability across acoustic parameters, and add explicit chance-level baselines (e.g., 8.3% for 12-tone absolute pitch identification) in §4 tables and figures. Human performance baselines are not included in the current study, as the focus is model evaluation, but we will note this as a limitation and direction for extension. revision: yes
-
Referee: [§2 and §5] §2 (Related Work) and §5 (Discussion): The assertion that existing benchmarks 'rarely assess' pitch hearing directly is used to motivate the new suite, but the paper does not quantify how the 28 experiments avoid the multiple-choice or indirect confounds criticized in prior work, leaving open whether the observed failures are specific to pitch or to ALM prompting/response formats in general.
Authors: The 28 experiments were designed with a deliberate mix of open-ended identification tasks (e.g., 'Name the pitch of the isolated note') and relative judgment formats that do not present answer options, in contrast to the multiple-choice setups common in prior music benchmarks. To make this explicit, the revision will add a quantitative comparison table in §2 that categorizes prior benchmarks by format (multiple-choice vs. open) and task type (direct pitch vs. indirect higher-level), showing that only a small fraction use direct pitch probes. §5 will be expanded to discuss prompting controls (fixed templates across experiments) and acknowledge that some variance may stem from response formatting, while arguing that the systematic acoustic variations isolate pitch-specific effects. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical benchmark paper that defines PitchBench as a suite of 28 experiments varying acoustic parameters and task formats, then reports direct model performance observations on those tasks. No derivations, equations, fitted parameters, predictions, or self-citation chains are present that could reduce any claim to its own inputs by construction. The central finding of unreliable pitch hearing is an empirical measurement rather than a derived result, rendering the work self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Onsets and Frames: Dual-Objective Piano Transcription
Accessed: 2026-04-28. Curtis Hawthorne, Erich Elsen, Jialin Song, Adam Roberts, Ian Simon, Colin Raffel, Jesse Engel, Sageev Oore, and Douglas Eck. Onsets and frames: Dual-objective piano transcription, 2018. URL https://arxiv.org/abs/1710.11153. Jong Wook Kim, Justin Salamon, Peter Li, and Juan Pablo Bello. Crepe: A convolutional representation for pitch...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icassp.2014.6853678 2026
-
[2]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
URL https://api.semanticscholar.org/CorpusID:13931888. Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models, 2024. URL https://arxiv.org/abs/2310.13289. Qwen Team. Qwen3.5-omni technical report, 2026. URL https://arxiv.org/abs/2604.15804...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.ajhg.2009.06.010 2024
-
[3]
Benno Weck, Ilaria Manco, Emmanouil Benetos, Elio Quinton, George Fazekas, and Dmitry Bogdanov
URL https://arxiv.org/abs/2406.16020. Benno Weck, Ilaria Manco, Emmanouil Benetos, Elio Quinton, George Fazekas, and Dmitry Bogdanov. Muchomusic: Evaluating music understanding in multimodal audio-language models, 2024. URL https://arxiv.org/abs/2408.01337. Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.