ATOM: Instantiating Budget-Controllable Multi-Agent Collaboration via Nucleus-Electron Hierarchy
Pith reviewed 2026-06-29 19:54 UTC · model grok-4.3
The pith
ATOM uses a nucleus-electron hierarchy to make multi-agent LLM collaboration budget-controllable by estimating query difficulty at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
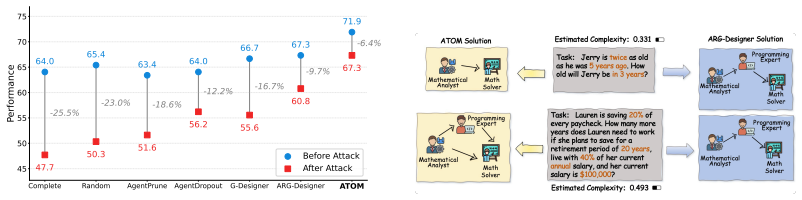
ATOM instantiates budget-controllable multi-agent collaboration via a nucleus-electron hierarchy: an offline-learned stable collaboration backbone (nucleus) is maintained while query-conditioned agents (electrons) are dynamically activated during inference, with a complexity-aware budgeting strategy that estimates query difficulty from the input alone to strictly regulate electron instantiation.
What carries the argument
Nucleus-electron hierarchy with complexity-aware budgeting strategy that estimates query difficulty to control dynamic agent activation
If this is right
- Multi-agent systems can separate stable collaboration patterns from query-specific additions without retraining the entire structure each time.
- Resource use becomes proportional to estimated task demands rather than fixed in advance.
- Token consumption decreases while benchmark scores remain at or above prior state-of-the-art levels across varied tasks.
- Reinforcement learning can be applied offline to learn the nucleus while inference-time rules handle electron activation.
Where Pith is reading between the lines
- The same nucleus-electron split could be applied to non-LLM agent systems where some coordination rules are fixed and others vary with context.
- If difficulty estimation proves accurate on new domains, the framework offers a route to automatic scaling of agent teams without manual budget setting.
- Failures in collaboration might become easier to diagnose by checking whether the nucleus alone suffices or whether the budgeting rule blocked needed electrons.
Load-bearing premise
The budgeting strategy can reliably estimate query difficulty from the input alone and use that estimate to strictly regulate electron instantiation without harming overall performance or stability.
What would settle it
A direct test would measure whether performance drops on held-out queries when the number of electrons is capped according to the model's difficulty estimate but the actual token demand or required agents exceeds that cap.
Figures

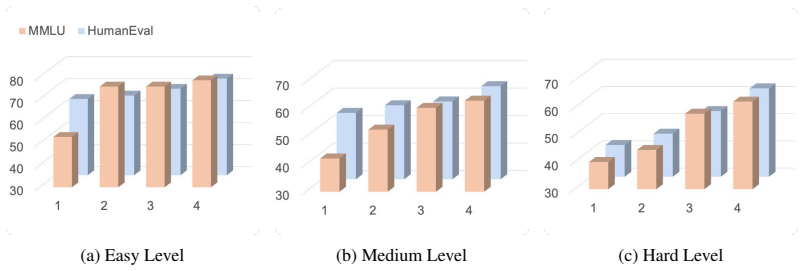
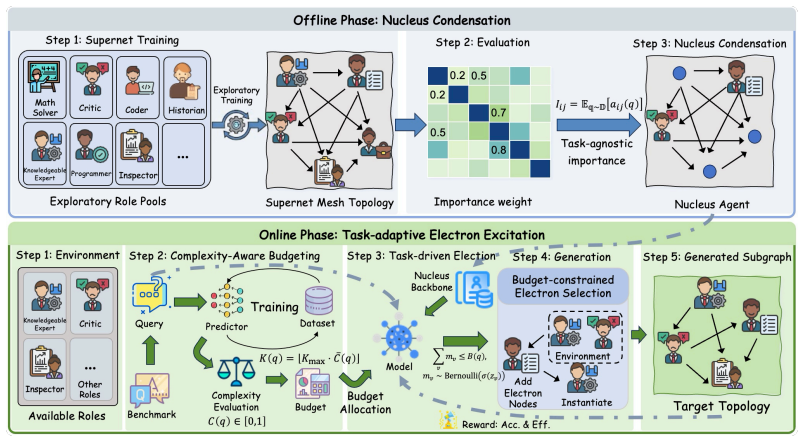
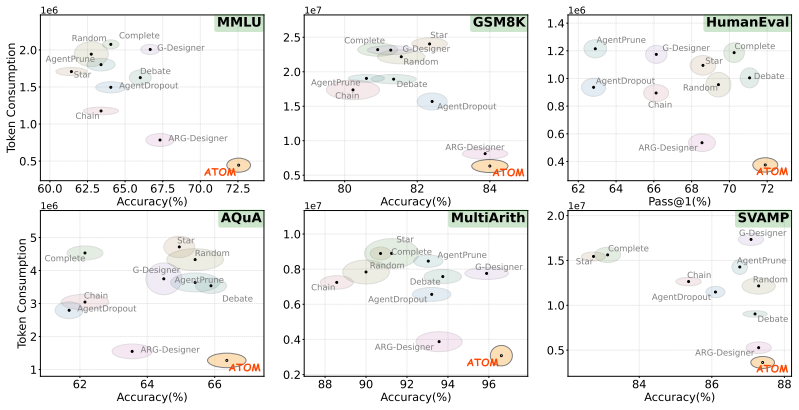
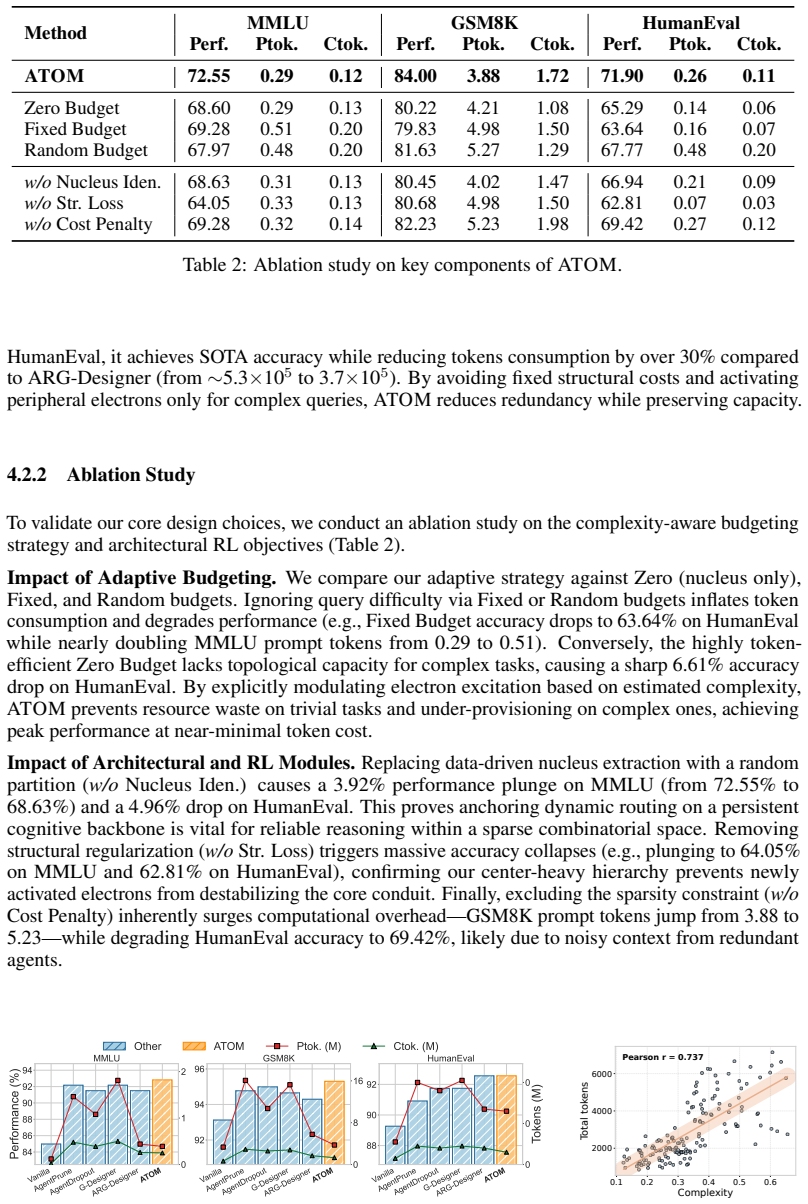
read the original abstract
Large Language Model (LLM)-based multi-agent systems rely on optimized collaboration topologies to balance performance and communication costs. However, current methods struggle with the inherent stability-extensibility trade-off and often misalign computational budgets with query difficulty. We propose \textsc{ATOM}, an adaptive framework that generates budget-controllable collaboration graphs via a novel task-driven reinforcement learning paradigm. Inspired by atomic structures, \textsc{ATOM} employs a nucleus-electron hierarchy: it maintains a stable, offline-learned collaboration backbone (the nucleus) while dynamically activating query-conditioned agents (electrons) during inference. Crucially, a complexity-aware budgeting strategy aligns resource consumption with task demands by estimating query difficulty to strictly regulate electron instantiation. Extensive experiments across six diverse benchmarks demonstrate that \textsc{ATOM} achieves state-of-the-art performance while improving token efficiency by up to $30\%$ compared to strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ATOM, a multi-agent LLM framework using a nucleus-electron hierarchy: a stable offline-learned collaboration backbone (nucleus) paired with dynamically instantiated query-conditioned agents (electrons). It introduces a task-driven RL paradigm to generate budget-controllable graphs and a complexity-aware budgeting strategy that estimates query difficulty from the input to strictly regulate electron count. Experiments across six benchmarks are reported to achieve SOTA performance with up to 30% token-efficiency gains over strong baselines.
Significance. If the budgeting estimator reliably maps input features to true reasoning depth and the RL objective produces stable graphs without hidden parameter dependence, the nucleus-electron separation could offer a practical solution to the stability-extensibility trade-off while delivering measurable efficiency gains. The explicit separation of offline backbone from online instantiation is a clear architectural contribution if the empirical claims are reproducible.
major comments (2)
- [Abstract] Abstract: the central SOTA + 30% token-efficiency claim is presented without any description of the baselines, number of runs, statistical tests, or controls for prompt length and model size; this information is required to evaluate whether the efficiency gain is attributable to the budgeting strategy rather than experimental setup.
- [Abstract] Abstract: the complexity-aware budgeting strategy is asserted to 'estimate query difficulty to strictly regulate electron instantiation,' yet no equation, feature set, training signal, or ablation is supplied for the estimator; because this mapping is the load-bearing mechanism for both the efficiency gain and the performance-stability alignment, its absence prevents verification that the reported numbers are not the result of post-hoc tuning or over-instantiation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and indicate the revisions we will undertake.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA + 30% token-efficiency claim is presented without any description of the baselines, number of runs, statistical tests, or controls for prompt length and model size; this information is required to evaluate whether the efficiency gain is attributable to the budgeting strategy rather than experimental setup.
Authors: We agree that the abstract would benefit from additional context to substantiate the performance claims. In the revised manuscript we will expand the abstract to briefly identify the strong baselines, state that results are averaged over multiple runs with statistical testing, and confirm that experiments controlled for prompt length and model size. These controls are already detailed in the experimental section; their mention in the abstract will help readers attribute gains to the budgeting strategy. revision: yes
-
Referee: [Abstract] Abstract: the complexity-aware budgeting strategy is asserted to 'estimate query difficulty to strictly regulate electron instantiation,' yet no equation, feature set, training signal, or ablation is supplied for the estimator; because this mapping is the load-bearing mechanism for both the efficiency gain and the performance-stability alignment, its absence prevents verification that the reported numbers are not the result of post-hoc tuning or over-instantiation.
Authors: The referee is correct that the abstract itself supplies none of the technical specifications for the estimator. The full manuscript presents the estimator's equation, input features, RL-derived training signal, and supporting ablations in the methods and experiments sections. To address the concern, we will revise the abstract to include a concise reference to these elements and their grounding in the task-driven RL paradigm. If the main-text description requires further elaboration or additional ablations, we will incorporate them during revision. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper introduces ATOM as a framework using a nucleus-electron hierarchy and a complexity-aware budgeting strategy within a task-driven RL paradigm. The provided abstract and description contain no equations, parameter-fitting steps, or self-citations that reduce any claimed prediction or result to its inputs by construction. The budgeting mechanism is described as estimating difficulty to regulate electrons, but this is presented as an empirical alignment technique rather than a definitional or fitted tautology. Central performance claims rest on external benchmark evaluations, which are independent of any internal derivation chain. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (2)
-
nucleus (stable offline-learned collaboration backbone)
no independent evidence
-
electrons (query-conditioned agents)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Börje F Karlsson, Jie Fu, and Yemin Shi
- [3]
- [4]
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others. 2021. Evaluating large language models trained on code.Preprint, arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Yongchao Chen, Jacob Arkin, Yang Zhang, Nicholas Roy, and Chuchu Fan. 2024. Scalable multi- robot collaboration with large language models: Centralized or decentralized systems? In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4311–4317. IEEE
2024
-
[7]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems.Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. 2024. Self-collaboration code generation via chatgpt.ACM Transactions on Software Engineering and Methodology, 33(7):1–38
2024
-
[9]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. 2023. Improving factuality and reasoning in language models through multiagent debate. InForty-first International Conference on Machine Learning
2023
-
[10]
Yijia Fan, Jusheng Zhang, Kaitong Cai, Jing Yang, Chengpei Tang, Jian Wang, and Keze Wang. 2026. Cost-effective communication: An auction-based method for language agent interaction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29412–29420
2026
-
[11]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding.Preprint, arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, and 1 others. 2025. Data interpreter: An llm agent for data science. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19796–19821
2025
-
[13]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. Metagpt: Meta programming for a multi-agent collaborative framework. Preprint, arXiv:2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
- [15]
-
[16]
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, and 1 others. 2025. A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems.arXiv preprint arXiv:2504.09037
-
[17]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The dawn of natural language to sql: Are we fully ready?Proceedings of the VLDB Endowment, 17(11):3318–3331
2024
- [18]
-
[19]
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. Program induction by rationale generation: Learning to solve and explain algebraic word problems.Preprint, arXiv:1705.04146
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. 2024. Large language model-based agents for software engineering: A survey.arXiv preprint arXiv:2409.02977
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Yixin Liu, Guibin Zhang, Kun Wang, Shiyuan Li, and Shirui Pan. 2025. Graph-augmented large language model agents: Current progress and future prospects.IEEE Intelligent Systems
2025
-
[22]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22
2023
-
[23]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. Are nlp models really able to solve simple math word problems?Preprint, arXiv:2103.07191
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, and 1 others. 2023. Chatdev: Communicative agents for software development. arXiv preprint arXiv:2307.07924
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [25]
-
[26]
Subhro Roy and Dan Roth. 2016. Solving general arithmetic word problems.Preprint, arXiv:1608.01413
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Xu Shen, Yixin Liu, Yiwei Dai, Yili Wang, Rui Miao, Yue Tan, Shirui Pan, and Xin Wang. 2025. Understanding the information propagation effects of communication topologies in llm-based multi-agent systems. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
2025
-
[28]
Chunhao Tian, Yutong Wang, Xuebo Liu, Zhexuan Wang, Liang Ding, Miao Zhang, and Min Zhang. 2025. Agentinit: Initializing llm-based multi-agent systems via diversity and expertise orchestration for effective and efficient collaboration. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 11870–11902
2025
-
[29]
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. 2023. On the planning abilities of large language models-a critical investigation.Advances in Neural Information Processing Systems, 36:75993–76005
2023
-
[30]
1999.Building the flexible firm: How to remain competitive
Henk W V olberda. 1999.Building the flexible firm: How to remain competitive. Oxford university press
1999
-
[31]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788
2020
- [32]
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837
2022
-
[34]
Liwenhan Xie, Chengbo Zheng, Haijun Xia, Huamin Qu, and Chen Zhu-Tian. 2024. Waitgpt: Monitoring and steering conversational llm agent in data analysis with on-the-fly code visualization. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, pages 1–14. 11
2024
- [35]
-
[36]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
-
[37]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822
- [38]
-
[39]
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jef- frey Xu Yu, and Tianlong Chen. 2025. Cut the crap: An economical communication pipeline for llm-based multi-agent systems. InInternational Conference on Learning Representations
2025
-
[40]
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. 2025. G-designer: Architecting multi-agent communication topologies via graph neural networks. InInternational Conference on Machine Learning
2025
-
[41]
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. 2025. Aflow: Automating agentic workflow generation.Preprint, arXiv:2410.10762
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yifan Zhang, Xinkui Zhao, Zuxin Wang, Zhengyi Zhou, Guanjie Cheng, Shuiguang Deng, and Jianwei Yin. 2025. Sortinghat: Redefining operating systems education with a tailored digital teaching assistant. In Companion Proceedings of the ACM on Web Conference 2025, pages 2951–2954
2025
- [43]
-
[44]
Li Zhong, Zilong Wang, and Jingbo Shang. 2024. Debug like a human: A large language model debugger via verifying runtime execution step by step. InFindings of the Association for Computational Linguistics ACL 2024, pages 851–870
2024
- [45]
-
[46]
Jun-Peng Zhu, Peng Cai, Kai Xu, Li Li, Yishen Sun, Shuai Zhou, Haihuang Su, Liu Tang, and Qi Liu. 2024. Autotqa: Towards autonomous tabular question answering through multi-agent large language models. Proceedings of the VLDB Endowment, 17(12):3920–3933
2024
-
[47]
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmid- huber. 2024. Gptswarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.