On the Role of Inductive Bias in Time-Series Pretraining: A Case Study in Learning Generalizable Representations for Clinical Time Series
Pith reviewed 2026-06-29 23:11 UTC · model grok-4.3
The pith
Dynamics-centric mixtures of pretraining objectives produce the most balanced transfer across classification and regression tasks for clinical gait time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
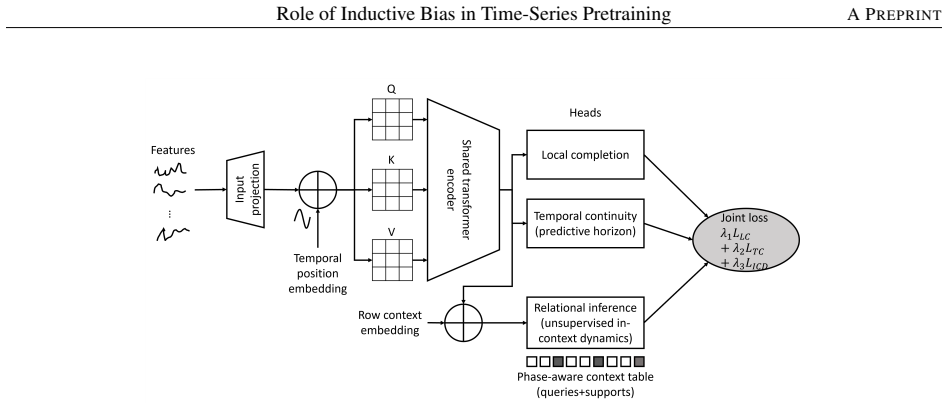
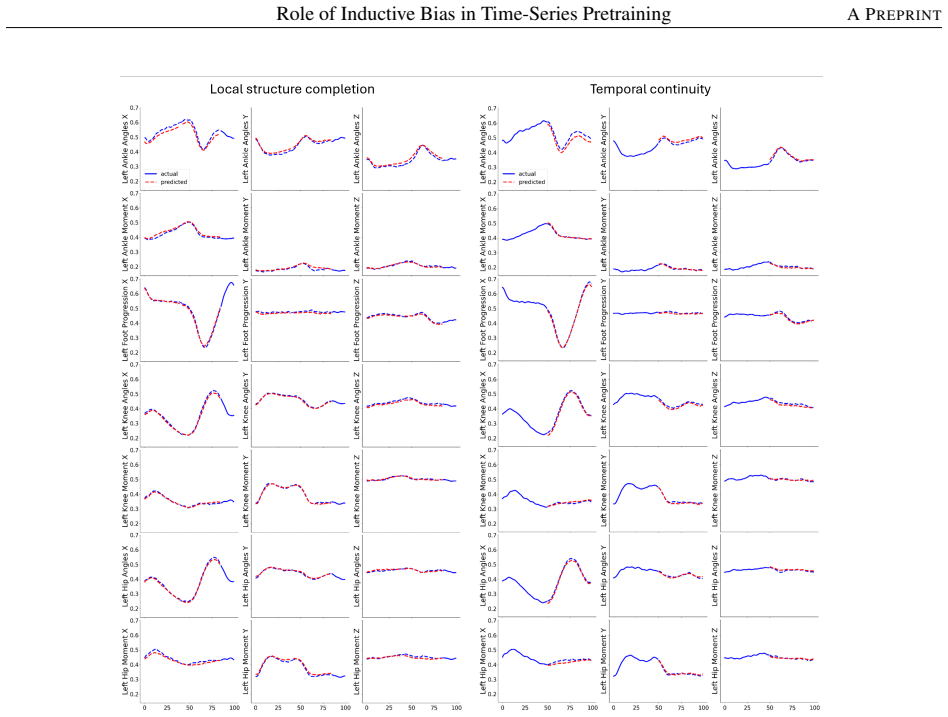
PathoFM is pretrained on multivariate gait windows using Local Completion to reconstruct contiguous masked spans, Temporal Continuity to predict a masked mid-horizon continuation from an observed prefix, and Unsupervised In-Context Dynamics to support query reconstruction conditioned on subject exemplar windows. Empirical comparison shows dynamics-centric mixtures achieve the most balanced transfer: grouping objectives improve classification margins yet degrade magnitude accuracy needed for continuous targets, while reconstruction-only objectives preserve waveform structure yet underperform on classification tasks.
What carries the argument
The three complementary pretraining objectives—Local Completion, Temporal Continuity, and Unsupervised In-Context Dynamics—applied inside an encoder-centric transformer to enforce local structure, smoothness, and causal consistency.
If this is right
- Combining local reconstruction with temporal continuity yields representations that support both classification and continuous regression without large trade-offs.
- Adding unsupervised in-context conditioning improves subject generalization when subject exemplar windows are available at inference time.
- Grouping objectives alone improve discriminative performance but reduce fidelity on magnitude-sensitive downstream targets.
- Pure reconstruction objectives maintain waveform structure yet show weaker results on classification tasks.
Where Pith is reading between the lines
- The same objective mixture could be tested on other small-cohort clinical series such as vital-sign monitoring to check whether the balanced-transfer pattern holds beyond gait.
- Protocol-drift robustness could be probed by training on one hospital's data and evaluating on another's without retraining.
- When exemplar access is unavailable the in-context component can be dropped without collapsing the remaining local-plus-continuity benefits.
Load-bearing premise
Results from the single SCI gait dataset are assumed to demonstrate inductive biases that transfer across task types and subjects in general.
What would settle it
A replication on a different clinical time-series dataset such as cardiac or EEG recordings where the dynamics-centric mixture no longer outperforms grouping or reconstruction-only objectives on balanced transfer metrics for both classification and regression.
Figures
read the original abstract
Clinical time-series learning is routinely constrained by small, heterogeneous cohorts and protocol drift, while its downstream use spans both classification (e.g., pathology diagnosis) and regression (e.g., temporal forecasting). These constraints make foundation-model pretraining appealing, but raises an important question of which inductive biases should the pretraining objective impose so that representations transfer across task types and subjects. We study this question in pathological gait analysis for spinal cord injury (SCI) via PathoFM, an encoder-centric transformer pretrained on multivariate gait windows with three complementary objectives: Local Completion (reconstruct contiguous masked spans to enforce local structure), Temporal Continuity (predict a masked mid-horizon continuation from an observed prefix to enforce smoothness and causal consistency), and Unsupervised In-Context Dynamics (support-query reconstruction conditioned on subject exemplar windows via attention). Empirically comparing objective families (grouping/contrastive, dynamics-based, and generative reconstruction), we find that dynamics-centric mixtures produce the most balanced transfer: grouping objectives favor discriminative margins but can degrade magnitude fidelity needed for continuous targets, whereas reconstruction-only objectives preserve waveform structure but may underperform on classification. Overall, combining local reconstruction with temporal continuity, and adding in-context conditioning when exemplar access is realistic, yields robust subject-generalizing representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PathoFM, an encoder-centric transformer pretrained on multivariate gait windows from spinal cord injury (SCI) patients using three objectives: Local Completion (reconstruct masked spans), Temporal Continuity (predict mid-horizon continuation), and Unsupervised In-Context Dynamics (support-query reconstruction conditioned on subject exemplars). Through empirical comparison of objective families (grouping/contrastive, dynamics-based, generative reconstruction) on the SCI gait dataset, it claims that dynamics-centric mixtures produce the most balanced transfer across classification and regression tasks and across subjects, while grouping objectives favor discriminative margins at the cost of magnitude fidelity and pure reconstruction preserves waveform structure but underperforms on classification.
Significance. If the comparative results hold under proper statistical controls and external validation, the work supplies actionable guidance on selecting inductive biases for clinical time-series foundation models operating under small-cohort and protocol-drift constraints, explicitly contrasting the trade-offs between discriminative, continuity, and reconstruction objectives for mixed task types.
major comments (2)
- [Empirical evaluation] Empirical evaluation (abstract and results): no dataset sizes, number of subjects, baseline implementations, statistical significance tests, error bars, or exclusion criteria are reported, preventing assessment of whether the observed advantages of dynamics-centric mixtures are load-bearing or artifactual.
- [Abstract and discussion] Abstract and §5 (discussion of generalizability): the central recommendation for dynamics-centric mixtures rests on transfer metrics from a single SCI gait dataset whose periodic multivariate structure and subject-variability patterns may not extend to other clinical domains (e.g., ECG, EEG); without cross-domain experiments or explicit discussion of protocol drift, the claim that these mixtures yield subject-generalizing representations cannot be verified beyond the case study.
minor comments (1)
- [Abstract] Abstract: minor phrasing issue in 'raises an important question of which inductive biases should the pretraining objective impose'—rephrase for grammatical clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical reporting and scope. We address each major comment below.
read point-by-point responses
-
Referee: [Empirical evaluation] Empirical evaluation (abstract and results): no dataset sizes, number of subjects, baseline implementations, statistical significance tests, error bars, or exclusion criteria are reported, preventing assessment of whether the observed advantages of dynamics-centric mixtures are load-bearing or artifactual.
Authors: We agree that these details are necessary for evaluating the results. In the revised manuscript we will add a dedicated experimental setup section reporting: the number of SCI subjects and total multivariate gait windows, data splits and exclusion criteria, full baseline implementations with hyperparameters and references, statistical significance tests (e.g., subject-wise paired tests with p-values), and error bars (standard deviation across subjects or folds). These additions will substantiate the reported advantages of the dynamics-centric mixtures. revision: yes
-
Referee: [Abstract and discussion] Abstract and §5 (discussion of generalizability): the central recommendation for dynamics-centric mixtures rests on transfer metrics from a single SCI gait dataset whose periodic multivariate structure and subject-variability patterns may not extend to other clinical domains (e.g., ECG, EEG); without cross-domain experiments or explicit discussion of protocol drift, the claim that these mixtures yield subject-generalizing representations cannot be verified beyond the case study.
Authors: The manuscript is explicitly positioned as a case study on SCI gait (see title and abstract). We will revise the abstract and §5 to explicitly bound the claims to this domain, note the periodic structure of gait data, and add a limitations paragraph discussing protocol drift and the absence of cross-domain validation on modalities such as ECG or EEG. We will also clarify that subject generalization is demonstrated across held-out subjects within the SCI cohort and outline why the inductive biases may be relevant more broadly, while acknowledging that transfer to other domains remains future work. revision: partial
Circularity Check
No significant circularity; empirical claims rest on dataset comparisons without definitional reduction
full rationale
The paper is an empirical case study that compares families of pretraining objectives (grouping/contrastive, dynamics-based, generative reconstruction) on the SCI gait dataset and reports transfer performance for classification and regression tasks. The abstract and provided text contain no equations, no fitted parameters renamed as predictions, no self-citations invoked as uniqueness theorems, and no ansatzes smuggled through prior work. All load-bearing statements are presented as outcomes of the reported experiments rather than derivations that reduce to their own inputs by construction. This is the normal, non-circular outcome for an empirical methods paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- mask span length for Local Completion
- mid-horizon length for Temporal Continuity
axioms (1)
- domain assumption Pretraining objectives that combine local reconstruction, temporal continuity, and in-context dynamics will produce representations that transfer across task types and subjects in clinical time series.
invented entities (1)
-
PathoFM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The evolution of clinical gait analysis part iii–kinetics and energy assessment.Gait & posture, 21(4):447–461, 2005
David H Sutherland. The evolution of clinical gait analysis part iii–kinetics and energy assessment.Gait & posture, 21(4):447–461, 2005
2005
-
[2]
Estimation of minimal data sets sizes for machine learning predictions in digital mental health interventions.npj Digital Medicine, 7(1):361, 2024
Kirsten Zantvoort, Barbara Nacke, Dennis Görlich, Silvan Hornstein, Corinna Jacobi, and Burkhardt Funk. Estimation of minimal data sets sizes for machine learning predictions in digital mental health interventions.npj Digital Medicine, 7(1):361, 2024
2024
-
[3]
Domain adaptation for medical image analysis: a survey.IEEE Transactions on Biomedical Engineering, 69(3):1173–1185, 2021
Hao Guan and Mingxia Liu. Domain adaptation for medical image analysis: a survey.IEEE Transactions on Biomedical Engineering, 69(3):1173–1185, 2021
2021
-
[4]
A survey on negative transfer.IEEE/CAA Journal of Automatica Sinica, 10(2):305–329, 2022
Wen Zhang, Lingfei Deng, Lei Zhang, and Dongrui Wu. A survey on negative transfer.IEEE/CAA Journal of Automatica Sinica, 10(2):305–329, 2022
2022
-
[5]
Multitask learning and benchmarking with clinical time series data.Scientific data, 6(1):96, 2019
Hrayr Harutyunyan, Hrant Khachatrian, David C Kale, Greg Ver Steeg, and Aram Galstyan. Multitask learning and benchmarking with clinical time series data.Scientific data, 6(1):96, 2019
2019
-
[6]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[7]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Reducing the dimensionality of data with neural networks
Geoffrey E Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks. science, 313(5786):504–507, 2006
2006
-
[9]
Why does unsupervised pre-training help deep learning? InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 201–208
Dumitru Erhan, Aaron Courville, Yoshua Bengio, and Pascal Vincent. Why does unsupervised pre-training help deep learning? InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 201–208. JMLR Workshop and Conference Proceedings, 2010
2010
-
[10]
The need for biases in learning generalizations
Tom M Mitchell. The need for biases in learning generalizations. 1980
1980
-
[11]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[12]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Ti-mae: Self-supervised masked time series autoencoders.arXiv preprint arXiv:2301.08871, 2023
Zhe Li, Zhongwen Rao, Lujia Pan, Pengyun Wang, and Zenglin Xu. Ti-mae: Self-supervised masked time series autoencoders.arXiv preprint arXiv:2301.08871, 2023
-
[14]
CRC Press, 2024
Jacquelin Perry and Judith Burnfield.Gait analysis: normal and pathological function. CRC Press, 2024. 10 Role of Inductive Bias in Time-Series PretrainingA PREPRINT
2024
-
[15]
A survey of human gait-based artificial intelligence applications
Elsa J Harris, I-Hung Khoo, and Emel Demircan. A survey of human gait-based artificial intelligence applications. Frontiers in Robotics and AI, 8:749274, 2022
2022
-
[16]
John wiley & sons, 2009
David A Winter.Biomechanics and motor control of human movement. John wiley & sons, 2009
2009
-
[17]
A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9052–9071, 2024
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, and Dacheng Tao. A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9052–9071, 2024
2024
-
[18]
Contrastive representation learning: A framework and review.Ieee Access, 8:193907–193934, 2020
Phuc H Le-Khac, Graham Healy, and Alan F Smeaton. Contrastive representation learning: A framework and review.Ieee Access, 8:193907–193934, 2020
2020
-
[19]
Prototypical contrastive learning of unsupervised representations,
Junnan Li, Pan Zhou, Caiming Xiong, and Steven CH Hoi. Prototypical contrastive learning of unsupervised representations.arXiv preprint arXiv:2005.04966, 2020
-
[20]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[21]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[22]
Self-supervised contrastive learning for medical time series: A systematic review.Sensors, 23(9):4221, 2023
Ziyu Liu, Azadeh Alavi, Minyi Li, and Xiang Zhang. Self-supervised contrastive learning for medical time series: A systematic review.Sensors, 23(9):4221, 2023
2023
-
[23]
Self-supervised transformer model training for a sleep-eeg foundation model
Mattson Ogg and William G Coon. Self-supervised transformer model training for a sleep-eeg foundation model. In2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 1–6. IEEE, 2024
2024
-
[24]
Ts2vec: Towards universal representation of time series
Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. Ts2vec: Towards universal representation of time series. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 8980–8987, 2022
2022
-
[25]
Time series data augmentation for deep learning: A survey.arXiv preprint arXiv:2002.12478, 2020
Qingsong Wen, Liang Sun, Fan Yang, Xiaomin Song, Jingkun Gao, Xue Wang, and Huan Xu. Time series data augmentation for deep learning: A survey.arXiv preprint arXiv:2002.12478, 2020
-
[26]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[27]
Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4):1748–1764, 2021
Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting, 37(4):1748–1764, 2021
2021
-
[28]
Sharmita Dey, Benjamin Paassen, Sarath Ravindran Nair, Sabri Boughorbel, and Arndt F Schilling. Continual learning from simulated interactions via multitask prospective rehearsal for bionic limb behavior modeling.arXiv preprint arXiv:2405.01114, 2024
-
[29]
Self-supervised learning for time series analysis: Taxonomy, progress, and prospects.IEEE transactions on pattern analysis and machine intelligence, 46(10):6775–6794, 2024
Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Y Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, et al. Self-supervised learning for time series analysis: Taxonomy, progress, and prospects.IEEE transactions on pattern analysis and machine intelligence, 46(10):6775–6794, 2024
2024
-
[30]
Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
2015
-
[31]
Improving multi-step prediction of learned time series models
Arun Venkatraman, Martial Hebert, and J Bagnell. Improving multi-step prediction of learned time series models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015
2015
-
[32]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34:24804–24816, 2021
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34:24804–24816, 2021
2021
-
[33]
Sharmita Dey and Sarath Ravindran Nair. Cross-modal diffusion for biomechanical dynamical systems through local manifold alignment.arXiv preprint arXiv:2503.12214, 2025
-
[34]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[35]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInterna- tional conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[36]
Joint diffusion models in continual learning
Paweł Skier´s and Kamil Deja. Joint diffusion models in continual learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4380–4390, 2025. 11 Role of Inductive Bias in Time-Series PretrainingA PREPRINT
2025
-
[37]
Gruver, N., Finzi, M., Qiu, S., and Wilson, A
Abhimanyu Das, Matthew Faw, Rajat Sen, and Yichen Zhou. In-context fine-tuning for time-series foundation models.arXiv preprint arXiv:2410.24087, 2024
-
[38]
arXiv preprint arXiv:2405.14982 , year=
Jiecheng Lu, Yan Sun, and Shihao Yang. In-context time series predictor.arXiv preprint arXiv:2405.14982, 2024
-
[39]
Matching networks for one shot learning
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. Advances in neural information processing systems, 29, 2016
2016
-
[40]
Cased-based reasoning for medical knowledge-based systems.International Journal of Medical Informatics, 64(2-3):355–367, 2001
Rainer Schmidt, Stefania Montani, Riccardo Bellazzi, Luigi Portinale, and Lothar Gierl. Cased-based reasoning for medical knowledge-based systems.International Journal of Medical Informatics, 64(2-3):355–367, 2001
2001
-
[41]
Sharmita Dey and Sarath Ravindran Nair. Remap: Neural model reprogramming with network inversion and retrieval-augmented mapping for adaptive motion forecasting.Advances in Neural Information Processing Systems, 37:25195–25227, 2024
2024
-
[42]
Sharmita Dey and Arndt F Schilling. A function approximator model for robust online foot angle trajectory prediction using a single imu sensor: Implication for controlling active prosthetic feet.IEEE Transactions on Industrial Informatics, 19(2):1467–1475, 2022
2022
-
[43]
Sharmita Dey, Takashi Yoshida, Robert H Foerster, Michael Ernst, Thomas Schmalz, Rodrigo M Carnier, and Arndt F Schilling. A hybrid approach for dynamically training a torque prediction model for devising a human- machine interface control strategy.arXiv preprint arXiv:2110.03085, 2021
-
[44]
Sharmita Dey, Mahdy Eslamy, Takashi Yoshida, Michael Ernst, Thomas Schmalz, and ArndtF Schilling. A support vector regression approach for continuous prediction of ankle angle and moment during walking: An implication for developing a control strategy for active ankle prostheses. In2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR)...
2019
-
[45]
Sharmita Dey, Takashi Yoshida, Robert H Foerster, Michael Ernst, Thomas Schmalz, and Arndt F Schilling. Continuous prediction of joint angular positions and moments: A potential control strategy for active knee-ankle prostheses.IEEE Transactions on Medical Robotics and Bionics, 2(3):347–355, 2020
2020
-
[46]
A random forest approach for continuous prediction of joint angles and moments during walking: An implication for controlling active knee-ankle prostheses/orthoses
Sharmita Dey, Takashi Yoshida, Michael Ernst, Thomas Schmalz, and Arndt F Schilling. A random forest approach for continuous prediction of joint angles and moments during walking: An implication for controlling active knee-ankle prostheses/orthoses. In2019 IEEE International conference on Cyborg and bionic systems (CBS), pages 66–71. IEEE, 2019
2019
-
[47]
Continuous-phase control of a powered knee–ankle prosthesis: Amputee experiments across speeds and inclines.IEEE Transactions on Robotics, 34(3):686–701, 2018
David Quintero, Dario J Villarreal, Daniel J Lambert, Susan Kapp, and Robert D Gregg. Continuous-phase control of a powered knee–ankle prosthesis: Amputee experiments across speeds and inclines.IEEE Transactions on Robotics, 34(3):686–701, 2018
2018
-
[48]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024
2024
-
[49]
Variadic meta-learning by bayesian nonparametric deep embedding.Advances in Neural Information Processing Systems (NeurIPS), 2018
Kelsey R Allen, Hanul Shin, Evan Shelhamer, and Joshua B Tenenbaum. Variadic meta-learning by bayesian nonparametric deep embedding.Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[50]
Explaining machine learning models for clinical gait analysis.ACM Transactions on Computing for Healthcare (HEALTH), 3(2):1–27, 2021
Djordje Slijepcevic, Fabian Horst, Sebastian Lapuschkin, Brian Horsak, Anna-Maria Raberger, Andreas Kranzl, Wojciech Samek, Christian Breiteneder, Wolfgang Immanuel Schöllhorn, and Matthias Zeppelzauer. Explaining machine learning models for clinical gait analysis.ACM Transactions on Computing for Healthcare (HEALTH), 3(2):1–27, 2021
2021
-
[51]
Automatic classification of pathological gait patterns using ground reaction forces and machine learning algorithms
Murad Alaqtash, Thompson Sarkodie-Gyan, Huiying Yu, Olac Fuentes, Richard Brower, and Amr Abdelgawad. Automatic classification of pathological gait patterns using ground reaction forces and machine learning algorithms. In2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, pages 453–
-
[52]
Case-based reasoning for medical decision support tasks: The inreca approach.Artificial Intelligence in Medicine, 12(1):25–41, 1998
Klaus-Dieter Althoff, Ralph Bergmann, Stefan Wess, Michel Manago, Eric Auriol, Oleg I Larichev, Alexander Bolotov, Yurii I Zhuravlev, and Serge I Gurov. Case-based reasoning for medical decision support tasks: The inreca approach.Artificial Intelligence in Medicine, 12(1):25–41, 1998
1998
-
[53]
Deep learning based ground reaction force estimation for stair walking using kinematic data.Measurement, 198:111344, 2022
Dongwei Liu, Ming He, Meijin Hou, and Ye Ma. Deep learning based ground reaction force estimation for stair walking using kinematic data.Measurement, 198:111344, 2022
2022
-
[54]
Clinical time series prediction: Toward a hierarchical dynamical system framework.Artificial intelligence in medicine, 65(1):5–18, 2015
Zitao Liu and Milos Hauskrecht. Clinical time series prediction: Toward a hierarchical dynamical system framework.Artificial intelligence in medicine, 65(1):5–18, 2015
2015
-
[55]
Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
2018
-
[56]
Scim–spinal cord independence measure: a new disability scale for patients with spinal cord lesions.Spinal cord, 35(12):850–856, 1997
Amiram Catz, M Itzkovich, E Agranov, H Ring, and A Tamir. Scim–spinal cord independence measure: a new disability scale for patients with spinal cord lesions.Spinal cord, 35(12):850–856, 1997. 12
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.