Not All Modalities Are Equal: Instruction-Aware Gating for Multimodal Videos
Pith reviewed 2026-06-29 23:04 UTC · model grok-4.3
The pith
Instruction-conditioned gates let video models ignore irrelevant streams such as audio or depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
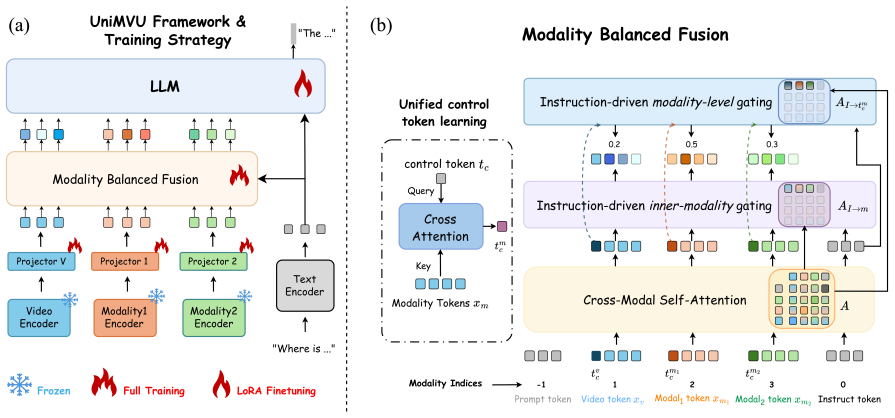
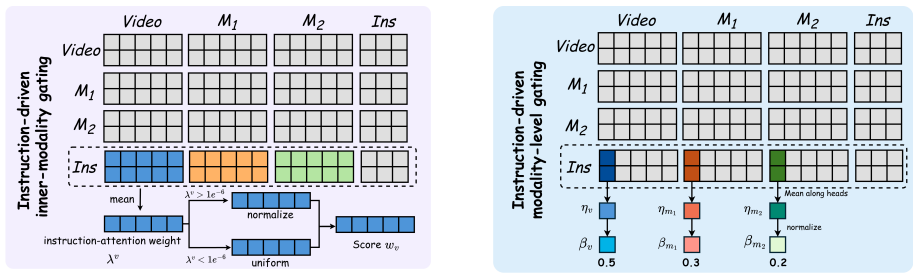
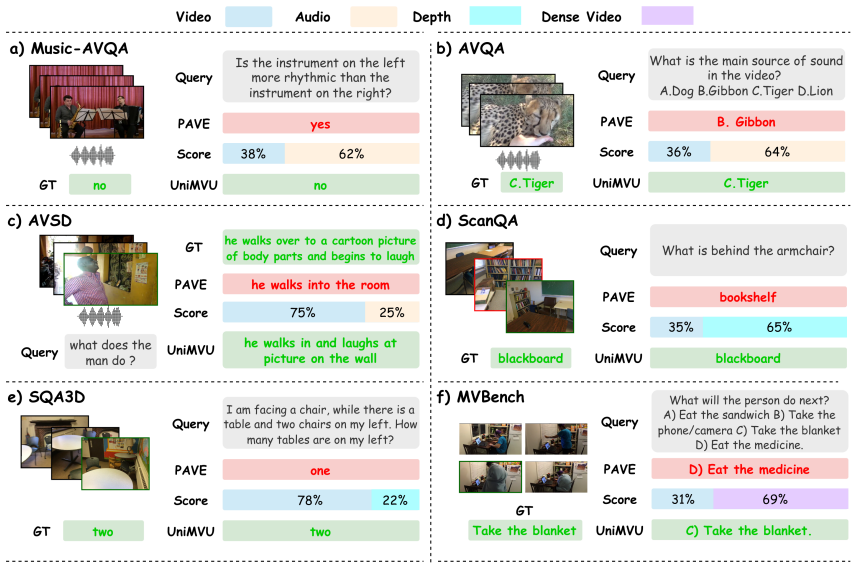
UniMVU performs instruction-aware fusion across video, audio, depth or any other modality inputs via two levels of dynamic gating: inner-modality gates emphasize salient regions within each modality, whereas modality-level gates re-weight whole streams; both are conditioned on the text instruction to adaptively balance modality importance, combined with cross-modal self-attention and a fast-to-slow fusion scheme for time-aligned streams.
What carries the argument
Two-level instruction-conditioned dynamic gating: inner-modality gates that highlight salient regions inside each stream and modality-level gates that re-weight entire streams.
If this is right
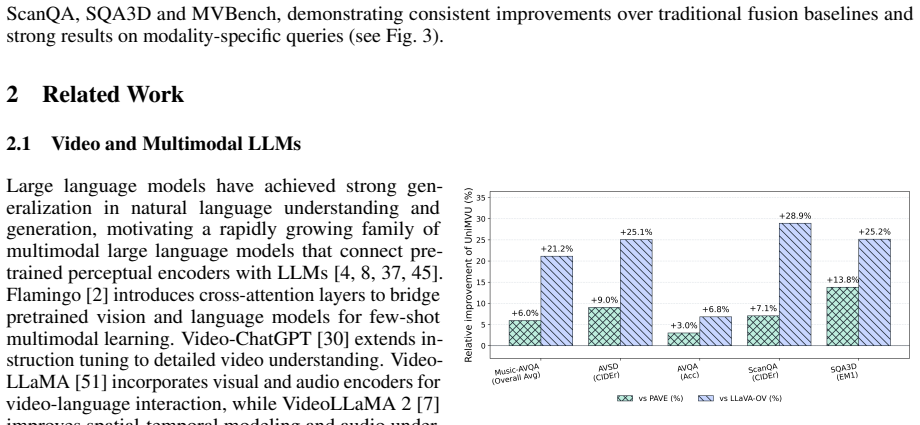
- Consistent gains over static-fusion baselines on AVQA, AVSD, Music-AVQA, ScanQA, SQA3D and MVBench.
- Maximum improvement of 13.5 CIDEr points on the reported metrics.
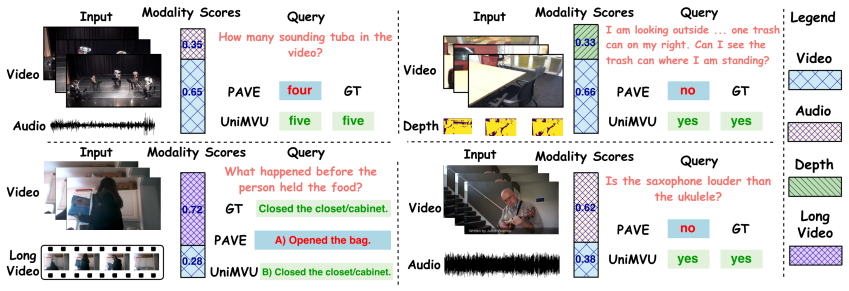
- Gating outputs align with human-interpretable modality relevance judgments.
- Ablations isolate the separate contributions of the inner-modality and modality-level gates.
- The same recipe scales to diverse modality sets without requiring hand-crafted fusion rules.
Where Pith is reading between the lines
- The instruction-driven gating pattern could transfer to other multimodal large language models that ingest mixed sensor streams.
- Automatic down-weighting of noisy or conflicting modalities may reduce the need for separate modality-specific preprocessing pipelines.
- Real-world video systems could become more robust by letting the query itself decide which sensors to trust.
Load-bearing premise
The text instruction supplies a sufficiently strong and general signal to train the inner-modality and modality-level gates to correctly identify and re-weight relevant versus irrelevant streams across arbitrary modality combinations.
What would settle it
A controlled test on one of the six benchmarks in which a single modality is made deliberately irrelevant or noisy for the given instruction and performance is measured after forcing the modality-level gate to keep or drop that stream.
Figures



read the original abstract
Pre-trained video large language models excel at visual reasoning. However, they struggle when videos arrive with auxiliary streams, such as audio, depth map, or dense temporal evidence. In such a scenario, uniform fusion induces modality interference, allowing irrelevant channels to distract the model. To address this issue, we present a unified multimodal video understanding framework, named UniMVU, that performs instruction-aware fusion across video, audio, depth map, or any other modality inputs via two levels of dynamic gating: inner-modality gates emphasize salient regions within each modality, whereas modality-level gates re-weight whole streams; both are conditioned on the text instruction to adaptively balance modality importance. Our UniMVU combines cross-modal self-attention with instruction-driven inner-modality gating module and a modality-level gating module with control token; for time-aligned streams we further adopt a fast-to-slow fusion scheme that reduces redundancy. Across six benchmarks (AVQA, AVSD, Music-AVQA, ScanQA, SQA3D and MVBench), our UniMVU achieves consistent gains over static-fusion baselines achieving gains as high as 13.5 in terms of CIDEr metric. Further, our analysis shows that the gating mechanism aligns with the human-interpretable modality relevance, and ablations show the contributions of inner-modality and modality-level gating. Our UniMVU provides a simple, unified recipe for instruction-aware multimodal video understanding that scales to diverse modalities without hand-crafted fusion rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniMVU, a framework for multimodal video understanding that replaces uniform fusion with instruction-conditioned dynamic gating at two levels: inner-modality gates that emphasize salient regions within each stream (video, audio, depth, etc.) and modality-level gates that re-weight entire streams. Both gates are driven by the text instruction; a fast-to-slow fusion scheme is added for time-aligned inputs. The method is evaluated on six benchmarks (AVQA, AVSD, Music-AVQA, ScanQA, SQA3D, MVBench) and reports consistent improvements over static-fusion baselines, with a peak gain of 13.5 CIDEr, plus ablations and qualitative alignment with human modality relevance.
Significance. If the reported gains prove robust under full experimental disclosure and the gating generalizes across arbitrary modality combinations, the work would supply a practical, unified alternative to hand-crafted fusion rules for video LLMs. The absence of training details, baseline code, statistical tests, and cross-modality generalization experiments currently limits any stronger claim of significance.
major comments (3)
- Abstract and Experiments: the central claim of 'consistent gains' and a maximum 13.5 CIDEr improvement is presented without any description of training procedure, baseline implementations, data splits, or statistical significance testing; this information is load-bearing for evaluating whether the gating mechanism, rather than implementation differences, drives the results.
- Abstract: the claim that the approach 'scales to diverse modalities without hand-crafted fusion rules' rests on the untested assumption that the text instruction supplies a sufficiently strong, modality-agnostic relevance signal; no ablation on instruction randomization or evaluation on unseen modality combinations is reported, leaving open the possibility that gates overfit to training modality mixes.
- Abstract: while ablations are mentioned, no quantitative breakdown (e.g., performance drop when removing inner-modality vs. modality-level gates) or comparison against alternative conditioning schemes is provided, making it impossible to isolate the contribution of each gating level to the reported gains.
minor comments (2)
- Abstract: the phrase 'or any other modality inputs' is overly broad; the manuscript should explicitly list the modalities actually tested.
- Abstract: the fast-to-slow fusion scheme is introduced without a citation or brief justification of its computational benefit relative to standard cross-attention.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the experimental transparency and claims without overstating current results.
read point-by-point responses
-
Referee: Abstract and Experiments: the central claim of 'consistent gains' and a maximum 13.5 CIDEr improvement is presented without any description of training procedure, baseline implementations, data splits, or statistical significance testing; this information is load-bearing for evaluating whether the gating mechanism, rather than implementation differences, drives the results.
Authors: We agree that the abstract and main text currently lack sufficient implementation transparency. In the revised manuscript we will add a dedicated Implementation Details section covering training hyperparameters, baseline re-implementations, exact data splits, and statistical significance (standard deviation over three random seeds) for all reported metrics. This will allow readers to verify that gains arise from the gating modules rather than setup differences. revision: yes
-
Referee: Abstract: the claim that the approach 'scales to diverse modalities without hand-crafted fusion rules' rests on the untested assumption that the text instruction supplies a sufficiently strong, modality-agnostic relevance signal; no ablation on instruction randomization or evaluation on unseen modality combinations is reported, leaving open the possibility that gates overfit to training modality mixes.
Authors: The six benchmarks already span distinct modality combinations (video+audio on AVQA/Music-AVQA, video+depth on ScanQA/SQA3D, multi-stream on MVBench), providing empirical support for the scaling claim. To directly test the instruction signal we will add an instruction-randomization ablation in the revision. Full evaluation on entirely unseen modality combinations would require new datasets and is noted as future work rather than a current claim. revision: partial
-
Referee: Abstract: while ablations are mentioned, no quantitative breakdown (e.g., performance drop when removing inner-modality vs. modality-level gates) or comparison against alternative conditioning schemes is provided, making it impossible to isolate the contribution of each gating level to the reported gains.
Authors: We acknowledge the current ablation section is insufficiently quantitative. The revision will expand it with explicit tables showing performance drops when each gate is removed individually, plus direct comparisons against alternative conditioning schemes (e.g., non-instructional cross-attention and static modality weighting). revision: yes
Circularity Check
No circularity; empirical architecture validated on external benchmarks
full rationale
The paper introduces UniMVU, an instruction-aware gating framework for multimodal video inputs, and reports empirical gains (up to 13.5 CIDEr) on six external benchmarks (AVQA, AVSD, etc.). No derivation chain, equations, or first-principles results are present that reduce any claimed prediction to a quantity defined by the paper's own fitted parameters, self-citations, or ansatzes. The gating modules are presented as architectural choices whose effectiveness is shown via ablations and human-interpretable alignment, not by construction from the inputs. The work is self-contained against external benchmarks with no load-bearing self-citation or renaming of known results.
Axiom & Free-Parameter Ledger
free parameters (1)
- gating module parameters
axioms (1)
- domain assumption Text instruction provides a strong and general signal for modality relevance
Reference graph
Works this paper leans on
-
[1]
Marks, Chiori Hori, Peter Anderson, Stefan Lee, and Devi Parikh
Huda Alamri, Vincent Cartillier, Abhishek Das, Jue Wang, Anoop Cherian, Irfan Essa, Dhruv Batra, Tim K. Marks, Chiori Hori, Peter Anderson, Stefan Lee, and Devi Parikh. Audio visual scene-aware dialog. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 7558–7567, 2019
2019
-
[2]
Flamingo: A visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski,...
2022
-
[3]
ScanQA: 3D question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. ScanQA: 3D question answering for spatial scene understanding. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 19129–19139, 2022
2022
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
-
[5]
Rui Cai, Bangzheng Li, Xiaofei Wen, Muhao Chen, and Zhe Zhao. Diagnosing and mitigating modality interference in multimodal large language models.arXiv preprint arXiv:2505.19616, 2025
-
[6]
V AST: A vision-audio-subtitle-text omni-modality foundation model and dataset
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. V AST: A vision-audio-subtitle-text omni-modality foundation model and dataset. InAdv. Neural Inf. Process. Syst., volume 36, pages 72842–72866, 2023
2023
-
[7]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. VideoLLaMA 2: Advancing spatial-temporal modeling and audio understanding in video-LLMs.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
2024
-
[9]
Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis. InP...
2025
-
[10]
Scene-LLM: Extending language model for 3D visual reasoning
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-LLM: Extending language model for 3D visual reasoning. InProc. IEEE/CVF Winter Conf. Appl. Comput. Vis., pages 2195–2206, 2025
2025
-
[11]
ImageBind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. ImageBind: One embedding space to bind them all. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 15180–15190, 2023
2023
-
[12]
3D-LLM: Injecting the 3D world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3D-LLM: Injecting the 3D world into large language models. InAdv. Neural Inf. Process. Syst., volume 36, 2023
2023
-
[13]
JM3D and JM3D-LLM: Elevating 3D representation with joint multi-modal cues.IEEE Trans
Jiayi Ji, Haowei Wang, Changli Wu, Yiwei Ma, Xiaoshuai Sun, and Rongrong Ji. JM3D and JM3D-LLM: Elevating 3D representation with joint multi-modal cues.IEEE Trans. Pattern Anal. Mach. Intell., 47(4):2475– 2492, 2025. 16
2025
-
[14]
Scene-guided attention network for spatial understanding in 3D scenes
Yunqi Jiang, Jianwei Zhang, Chaoyang Lin, Yi Yu, and Zhenguo Yang. Scene-guided attention network for spatial understanding in 3D scenes. InProc. ACM Int. Conf. Multimedia Retrieval, pages 616–624, 2025
2025
-
[15]
Do Modern Video-LLMs Need to Listen? A Benchmark Audit and Scalable Remedy
Geewook Kim and Minjoon Seo. Does audio matter for modern video-llms and their benchmarks?arXiv preprint arXiv:2509.17901, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Otter: A multi-modal model with in-context instruction tuning.IEEE Trans
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Joshua Adrian Cahyono, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning.IEEE Trans. Pattern Anal. Mach. Intell., 47(9):7543–7557, 2025
2025
-
[17]
LLaV A-OneVision: Easy visual task transfer.Trans
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-OneVision: Easy visual task transfer.Trans. Mach. Learn. Res., 2025
2025
-
[18]
Progressive spatio-temporal perception for audio-visual question answering
Guangyao Li, Wenxuan Hou, and Di Hu. Progressive spatio-temporal perception for audio-visual question answering. InProc. ACM Int. Conf. Multimedia, pages 7808–7816, 2023
2023
-
[19]
Learning to answer questions in dynamic audio-visual scenarios
Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji-Rong Wen, and Di Hu. Learning to answer questions in dynamic audio-visual scenarios. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 19108–19118, 2022
2022
-
[20]
Parse, align and aggregate: Graph-driven compositional reasoning for video question answering.IEEE Trans
Jiangtong Li, Zhaohe Liao, Fengshun Xiao, Tianjiao Li, Qiang Zhang, Haohua Zhao, Li Niu, Guang Chen, Liqing Zhang, and Changjun Jiang. Parse, align and aggregate: Graph-driven compositional reasoning for video question answering.IEEE Trans. Pattern Anal. Mach. Intell., 48(5):5586–5603, 2026
2026
-
[21]
MVBench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. MVBench: A comprehensive multi-modal video understanding benchmark. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 22195–22206, 2024
2024
-
[22]
Transformer-empowered invariant grounding for video question answering.IEEE Trans
Yicong Li, Xiang Wang, Junbin Xiao, Wei Ji, and Tat-Seng Chua. Transformer-empowered invariant grounding for video question answering.IEEE Trans. Pattern Anal. Mach. Intell., 47(11):9510–9522, 2025
2025
-
[23]
Uni-MoE: Scaling unified multimodal LLMs with mixture of experts.IEEE Trans
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, and Min Zhang. Uni-MoE: Scaling unified multimodal LLMs with mixture of experts.IEEE Trans. Pattern Anal. Mach. Intell., 47(5):3424–3439, 2025
2025
-
[24]
General 3D vision-language model with fast rendering and pre-training vision-language alignment.IEEE Trans
Kangcheng Liu, Yong-Jin Liu, and Baoquan Chen. General 3D vision-language model with fast rendering and pre-training vision-language alignment.IEEE Trans. Pattern Anal. Mach. Intell., 47(9):7352–7368, 2025
2025
-
[25]
Cross-modal causal relational reasoning for event-level visual question answering.IEEE Trans
Yang Liu, Guanbin Li, and Liang Lin. Cross-modal causal relational reasoning for event-level visual question answering.IEEE Trans. Pattern Anal. Mach. Intell., 45(10):11624–11641, 2023
2023
-
[26]
PA VE: Patching and adapting video large language models
Zhuoming Liu, Yiquan Li, Khoi Duc Nguyen, Yiwu Zhong, and Yin Li. PA VE: Patching and adapting video large language models. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 3306–3317, 2025
2025
-
[27]
DSPNet: Dual-vision scene perception for robust 3D question answering
Jingzhou Luo, Yang Liu, Weixing Chen, Zhen Li, Yaowei Wang, Guanbin Li, and Liang Lin. DSPNet: Dual-vision scene perception for robust 3D question answering. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 14169–14178, 2025
2025
-
[28]
Robust visual question answering: Datasets, methods, and future challenges.IEEE Trans
Jie Ma, Pinghui Wang, Dechen Kong, Zewei Wang, Jun Liu, Hongbin Pei, and Junzhou Zhao. Robust visual question answering: Datasets, methods, and future challenges.IEEE Trans. Pattern Anal. Mach. Intell., 46(8):5575–5594, 2024
2024
-
[29]
SQA3D: Situated question answering in 3D scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. SQA3D: Situated question answering in 3D scenes. InProc. Int. Conf. Learn. Represent., 2023
2023
-
[30]
Video-ChatGPT: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-ChatGPT: Towards detailed video understanding via large vision and language models. InProc. Annu. Meeting Assoc. Comput. Linguistics, pages 12585–12602, 2024
2024
-
[31]
MRA-Net: Improving VQA via multi-modal relation attention network.IEEE Trans
Liang Peng, Yang Yang, Zheng Wang, Zi Huang, and Heng Tao Shen. MRA-Net: Improving VQA via multi-modal relation attention network.IEEE Trans. Pattern Anal. Mach. Intell., 44(1):318–329, 2022
2022
-
[32]
Audio-visual LLM for video understanding
Fangxun Shu, Lei Zhang, Hao Jiang, and Cihang Xie. Audio-visual LLM for video understanding. InProc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, pages 4305–4314, 2025. 17
2025
-
[33]
MovieChat+: Question- aware sparse memory for long video question answering.IEEE Trans
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, and Gaoang Wang. MovieChat+: Question- aware sparse memory for long video question answering.IEEE Trans. Pattern Anal. Mach. Intell., 48(1):374– 389, 2026
2026
-
[34]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[35]
video-SALMONN: Speech-enhanced audio-visual large language models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. video-SALMONN: Speech-enhanced audio-visual large language models. InProc. Int. Conf. Mach. Learn., volume 235 ofProc. Mach. Learn. Res., pages 47198–47217. PMLR, 2024
2024
-
[36]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-SALMONN 2: Caption-enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220, 2025
-
[37]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdv. Neural Inf. Process. Syst., volume 30, pages 5998–6008, 2017
2017
-
[39]
3D question answering via only 2D vision-language models
Fengyun Wang, Sicheng Yu, Jiawei Wu, Jinhui Tang, Hanwang Zhang, and Qianru Sun. 3D question answering via only 2D vision-language models. InProc. Int. Conf. Mach. Learn., volume 267 ofProc. Mach. Learn. Res., pages 65310–65325, 2025
2025
-
[40]
LongVideoBench: A benchmark for long-context interleaved video-language understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. LongVideoBench: A benchmark for long-context interleaved video-language understanding. InAdv. Neural Inf. Process. Syst., volume 37, pages 28828–28857, 2024
2024
-
[41]
Con- trastive video question answering via video graph transformer.IEEE Trans
Junbin Xiao, Pan Zhou, Angela Yao, Yicong Li, Richang Hong, Shuicheng Yan, and Tat-Seng Chua. Con- trastive video question answering via video graph transformer.IEEE Trans. Pattern Anal. Mach. Intell., 45(11):13265–13280, 2023
2023
-
[42]
3UR-LLM: An end-to-end multimodal large language model for 3D scene understanding.IEEE Trans
Haomiao Xiong, Yunzhi Zhuge, Jiawen Zhu, Lu Zhang, and Huchuan Lu. 3UR-LLM: An end-to-end multimodal large language model for 3D scene understanding.IEEE Trans. Multimedia, 2025
2025
-
[43]
PointLLM: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. PointLLM: Empowering large language models to understand point clouds. InProc. Eur. Conf. Comput. Vis., pages 131–147, 2024
2024
-
[44]
Unifying the video and question attentions for open-ended video question answering.IEEE Trans
Hongyang Xue, Zhou Zhao, and Deng Cai. Unifying the video and question attentions for open-ended video question answering.IEEE Trans. Image Process., 26(12):5656–5666, 2017
2017
-
[45]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Learning to answer visual questions from web videos.IEEE Trans
Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Learning to answer visual questions from web videos.IEEE Trans. Pattern Anal. Mach. Intell., 47(5):3202–3218, 2025
2025
-
[47]
A VQA: A dataset for audio-visual question answering on videos
Pinci Yang, Xin Wang, Xuguang Duan, Hong Chen, Runze Hou, Cong Jin, and Wenwu Zhu. A VQA: A dataset for audio-visual question answering on videos. InProc. ACM Int. Conf. Multimedia, pages 3480–3491, 2022
2022
-
[48]
Qilang Ye, Zitong Yu, Rui Shao, Yawen Cui, Xiangui Kang, Xin Liu, Philip H. S. Torr, and Xiaochun Cao. CAT+: Investigating and enhancing audio-visual understanding in large language models.IEEE Trans. Pattern Anal. Mach. Intell., 47(10):8674–8690, 2025. 18
2025
-
[49]
Qilang Ye, Zitong Yu, Rui Shao, Xinyu Xie, Philip H. S. Torr, and Xiaochun Cao. CAT: Enhancing multimodal large language model to answer questions in dynamic audio-visual scenarios. InProc. Eur. Conf. Comput. Vis., pages 146–164, 2024
2024
-
[50]
mPLUG-Owl2: Revolutionizing multi-modal large language model with modality collaboration
Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, and Fei Huang. mPLUG-Owl2: Revolutionizing multi-modal large language model with modality collaboration. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 13040–13051, 2024
2024
-
[51]
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. InProc. Conf. Empirical Methods Natural Lang. Process.: Syst. Demonstrations, pages 543–553, 2023
2023
-
[52]
AV-Master: Dual-Path Comprehensive Perception Makes Better Audio-Visual Question Answering
Jiayu Zhang, Shuo Ye, Qilang Ye, Xun Lin, Zihan Song, and Zitong Yu. A V-Master: Dual-path comprehensive perception makes better audio-visual question answering.arXiv preprint arXiv:2510.18346, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Audio-visual adaptive fusion network for question answering based on contrastive learning
Xujian Zhao, Yixin Wang, and Peiquan Jin. Audio-visual adaptive fusion network for question answering based on contrastive learning. InProc. AAAI Conf. Artif. Intell., volume 39, pages 10483–10491, 2025
2025
-
[54]
MLVU: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: Benchmarking multi-task long video understanding. InProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 13691–13701, 2025
2025
-
[55]
LanguageBind: Extending video-language pretraining to N-modality by language-based semantic alignment
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Cai Zhang, Zhifeng Li, Wei Liu, and Li Yuan. LanguageBind: Extending video-language pretraining to N-modality by language-based semantic alignment. InProc. Int. Conf. Learn. Represent., 2024
2024
-
[56]
LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D capabilities. InProc. IEEE/CVF Int. Conf. Comput. Vis., pages 4295–4305, 2025. 19
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.