DuoGesture: Neuro-Inspired and Biomechanically Informed Dual-Stream Co-Speech Gesture Generation
Pith reviewed 2026-06-29 22:59 UTC · model grok-4.3
The pith
DuoGesture decomposes co-speech gesture generation into semantic and beat streams coordinated by a variational bottleneck to improve grounding and smoothness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
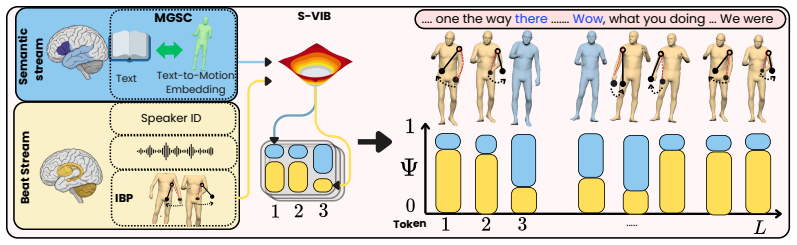
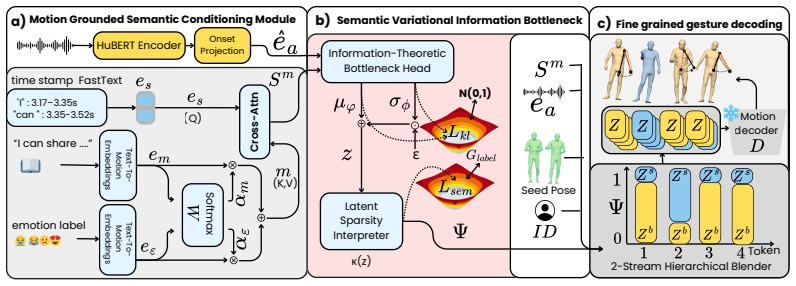
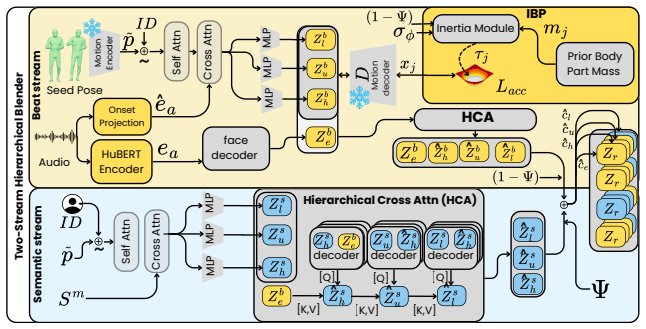
DuoGesture decomposes co-speech gesture synthesis into coupled semantic and beat streams coordinated by a Semantic Variational Information Bottleneck, a stochastic frame-level gate that learns when semantic gestures should override rhythmic beat motion; the semantic stream is controlled by Motion-Grounded Semantic Conditioning that replaces linguistic word embeddings with motion-language representations, and the beat stream is regularised by an Inertial Beat Prior, an anthropometry-weighted arm-chain module, yielding improved semantic grounding, speech-motion alignment, and kinematic smoothness.
What carries the argument
Semantic Variational Information Bottleneck: a stochastic frame-level gate that learns when semantic gestures override rhythmic beat motion.
If this is right
- Semantic gestures become more lexically precise because motion-aligned conditioning replaces generic word embeddings.
- Beat gestures gain rhythmic consistency and reduced jitter from the anthropometry-weighted inertial prior.
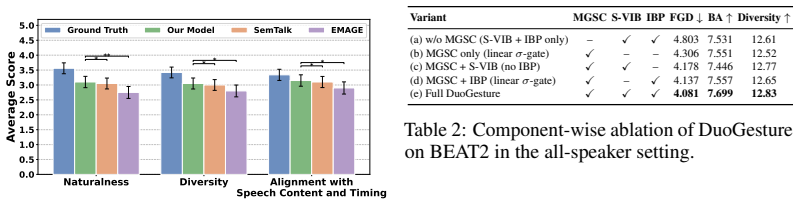
- Ablations isolate the independent contributions of the bottleneck gate, the motion-grounded conditioning, and the biomechanical regulariser.
- Overall generation quality rises in both automatic metrics and human preference judgments.
Where Pith is reading between the lines
- The same separation of semantic and rhythmic streams could be tested on full-body motion or sign-language generation tasks.
- The stochastic gate might be replaced by an explicit controllability knob to let users force more or fewer semantic gestures.
- The motion-language representations could be swapped for newer multimodal embeddings to check whether further gains appear.
Load-bearing premise
The three proposed modules can be combined and trained together to deliver measurable gains in semantic alignment and smoothness without creating new failure modes.
What would settle it
A controlled comparison in which the dual-stream model shows no statistically significant improvement, or shows degradation, on semantic alignment scores or kinematic jitter measures relative to the strongest holistic baseline.
Figures
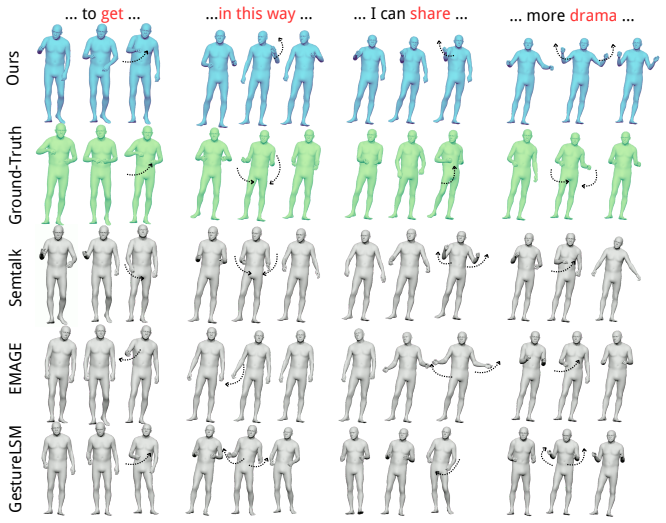


read the original abstract
Co-speech gesture generation requires both semantic expressivity and biomechanically plausible rhythmic motion. Existing holistic gesture models mix lexically grounded semantic gestures with frequent prosody-aligned beat gestures. This limits semantic grounding, speech-motion alignment, and kinematic smoothness. We propose \emph{DuoGesture}, a neuro-inspired and biomechanically informed dual-stream approach that decomposes co-speech gesture synthesis into coupled semantic and beat streams. The two streams are coordinated by a \emph{Semantic Variational Information Bottleneck}, a stochastic frame-level gate that learns when semantic gestures should override rhythmic beat motion. The semantic stream is controlled by \emph{Motion-Grounded Semantic Conditioning}, which replaces purely linguistic word embeddings with motion-language representations to provide motion-aligned semantic priors for long-tailed lexical triggers of gestures. The beat stream is further regularised by an \emph{Inertial Beat Prior}, an anthropometry-weighted arm-chain module that reduces jitter and improves rhythmic consistency without constraining semantic frames. Objective evaluations and subjective experiments show that DuoGesture outperforms strong holistic baselines, while component ablations confirm the complementary roles of semantic grounding, stochastic stream selection, and biomechanical regularisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DuoGesture, a dual-stream architecture for co-speech gesture generation that decomposes synthesis into coupled semantic and beat streams. Coordination is handled by a Semantic Variational Information Bottleneck acting as a stochastic frame-level gate; the semantic stream employs Motion-Grounded Semantic Conditioning to replace pure linguistic embeddings with motion-language representations; the beat stream is regularized by an Inertial Beat Prior that applies anthropometry-weighted arm-chain constraints. The paper states that objective evaluations and subjective experiments demonstrate outperformance over strong holistic baselines, while component ablations confirm the complementary contributions of semantic grounding, stochastic selection, and biomechanical regularization.
Significance. If the reported gains hold, the work offers a structured alternative to holistic models that currently mix semantic and prosodic gestures, potentially improving both semantic alignment and kinematic smoothness in applications such as animation and embodied agents. The explicit component ablations constitute a strength by providing direct evidence for the individual contributions of the SVIB gate, motion-grounded conditioning, and inertial prior.
minor comments (1)
- [Abstract] Abstract: the claim of outperformance over baselines and the success of ablations are stated without any accompanying quantitative metrics, error bars, dataset sizes, or statistical significance values, which would allow immediate assessment of the magnitude and reliability of the improvements.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DuoGesture, the recognition of its structured dual-stream design and component ablations, and the recommendation for minor revision. No specific major comments appear in the provided report.
Circularity Check
No significant circularity identified
full rationale
The manuscript text provided contains no equations, parameter-fitting descriptions, or self-citation chains that reduce any claimed prediction or first-principles result to its own inputs by construction. Architectural components (SVIB, motion-grounded conditioning, inertial prior) are presented as design choices whose performance is asserted via external objective metrics, subjective tests, and ablations rather than internal re-derivation. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep variational information bottleneck
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck. InInternational Conference on Learning Representations, 2017
2017
-
[2]
Gesturediffuclip: Gesture diffusion model with clip latents.ACM Transactions on Graphics (TOG), 42(4):1–18, 2023
Tenglong Ao, Zeyi Zhang, and Libin Liu. Gesturediffuclip: Gesture diffusion model with clip latents.ACM Transactions on Graphics (TOG), 42(4):1–18, 2023
2023
-
[3]
Oxford University Press, 2012
Michael A Arbib.How the brain got language: The mirror system hypothesis, volume 16. Oxford University Press, 2012
2012
-
[4]
Transactions of the Association for Computational Linguistics 5, 135–146 (Dec 2017)
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vectors with subword information.Transactions of the Association for Computational Linguistics, 5: 135–146, 2017. doi: 10.1162/tacl_a_00051
-
[5]
Enabling synergistic full-body control in prompt-based co-speech motion generation
Bohong Chen, Yumeng Li, Yao-Xiang Ding, Tianjia Shao, and Kun Zhou. Enabling synergistic full-body control in prompt-based co-speech motion generation. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6774–6783, 2024
2024
-
[6]
Diffsheg: A diffusion-based approach for real-time speech-driven holistic 3d expression and gesture generation
Junming Chen, Yunfei Liu, Jianan Wang, Ailing Zeng, Yu Li, and Qifeng Chen. Diffsheg: A diffusion-based approach for real-time speech-driven holistic 3d expression and gesture generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7352–7361, 2024
2024
-
[7]
Hologest: Decoupled diffusion and motion priors for generating holisticly expressive co-speech gestures
Yongkang Cheng and Shaoli Huang. Hologest: Decoupled diffusion and motion priors for generating holisticly expressive co-speech gestures. In2025 International Conference on 3D Vision (3DV), pages 748–757. IEEE, 2025
2025
-
[8]
Emotional speech-driven 3d body animation via disentan- gled latent diffusion
Kiran Chhatre, Radek Danecek, Nikos Athanasiou, Giorgio Becherini, Christopher Peters, Michael J Black, and Timo Bolkart. Emotional speech-driven 3d body animation via disentan- gled latent diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1942–1953, 2024
1942
-
[9]
Adjustments to zatsiorsky-seluyanov’s segment inertia parameters.Journal of biomechanics, 29(9):1223–1230, 1996
Paolo De Leva. Adjustments to zatsiorsky-seluyanov’s segment inertia parameters.Journal of biomechanics, 29(9):1223–1230, 1996
1996
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186, 2019. doi: 10.18653/v1/N19-1423
-
[11]
Learning speech-driven 3d conversational gestures from video
Ikhsanul Habibie, Weipeng Xu, Dushyant Mehta, Lingjie Liu, Hans-Peter Seidel, Gerard Pons- Moll, Mohamed Elgharib, and Christian Theobalt. Learning speech-driven 3d conversational gestures from video. InProceedings of the 21st ACM international conference on intelligent virtual agents, pages 101–108, 2021
2021
-
[12]
Improved variational inference with inverse autoregressive flow.Advances in neural information processing systems, 29, 2016
Durk P Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. Improved variational inference with inverse autoregressive flow.Advances in neural information processing systems, 29, 2016
2016
-
[13]
Evaluating gesture generation in a large-scale open challenge: The genea challenge 2022.ACM Transactions on Graphics, 43(3):1–28, 2024
Taras Kucherenko*, Pieter Wolfert*, Youngwoo Yoon*, Carla Viegas, Teodor Nikolov, Mihail Tsakov, and Gustav Eje Henter. Evaluating gesture generation in a large-scale open challenge: The genea challenge 2022.ACM Transactions on Graphics, 43(3):1–28, 2024
2022
-
[14]
Au- dio2gestures: Generating diverse gestures from speech audio with conditional variational autoencoders
Jing Li, Di Kang, Wenjie Pei, Xuefei Zhe, Ying Zhang, Zhenyu He, and Linchao Bao. Au- dio2gestures: Generating diverse gestures from speech audio with conditional variational autoencoders. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11293–11302, 2021. 10
2021
-
[15]
Ai choreographer: Music conditioned 3d dance generation with aist++
Ruilong Li, Shan Yang, David A Ross, and Angjoo Kanazawa. Ai choreographer: Music conditioned 3d dance generation with aist++. InProceedings of the IEEE/CVF international conference on computer vision, pages 13401–13412, 2021
2021
-
[16]
Beat: A large-scale semantic and emotional multi-modal dataset for conversa- tional gestures synthesis
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. Beat: A large-scale semantic and emotional multi-modal dataset for conversa- tional gestures synthesis. InEuropean conference on computer vision, pages 612–630. Springer, 2022
2022
-
[17]
Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Xuefei Zhe, Naoya Iwamoto, Bo Zheng, and Michael J Black. Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1144–1154, 2024
2024
-
[18]
Human gesture recognition with a flow-based model for human robot interaction
Lanmiao Liu, Chuang Yu, Siyang Song, Zhidong Su, and Adriana Tapus. Human gesture recognition with a flow-based model for human robot interaction. InCompanion of the 2023 ACM/IEEE International Conference on Human-Robot Interaction, pages 548–551, 2023
2023
-
[19]
Semges: Semantics-aware co-speech gesture generation using semantic coherence and relevance learning
Lanmiao Liu, Esam Ghaleb, Asli Ozyurek, and Zerrin Yumak. Semges: Semantics-aware co-speech gesture generation using semantic coherence and relevance learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13963–13973, 2025
2025
-
[20]
Lanmiao Liu, Esam Ghaleb, Aslı Özyürek, and Zerrin Yumak. Holisticsemges: Semantic grounding of holistic co-speech gesture generation with contrastive flow-matching.arXiv preprint arXiv:2603.26553, 2026
work page internal anchor Pith review arXiv 2026
-
[21]
Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling
Pinxin Liu, Luchuan Song, Junhua Huang, Haiyang Liu, and Chenliang Xu. Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10929–10939, 2025
2025
-
[22]
Towards variable and coordinated holistic co-speech motion generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, and Changxing Ding. Towards variable and coordinated holistic co-speech motion generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1566–1576, 2024
2024
-
[23]
University of Chicago press, 1992
David McNeill.Hand and mind: What gestures reveal about thought. University of Chicago press, 1992
1992
-
[24]
Retrieving semantics from the deep: an rag solution for gesture synthesis
Hamza Mughal, Rishabh Dabral, Merel CJ Scholman, Vera Demberg, and Christian Theobalt. Retrieving semantics from the deep: an rag solution for gesture synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16578–16588, 2025
2025
-
[25]
Deepmimic: Example- guided deep reinforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel Van de Panne. Deepmimic: Example- guided deep reinforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[26]
Tmr: Text-to-motion retrieval using con- trastive 3d human motion synthesis
Mathis Petrovich, Michael J Black, and Gül Varol. Tmr: Text-to-motion retrieval using con- trastive 3d human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9488–9497, 2023
2023
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning, volume 139 ofProceedings...
2021
-
[28]
Tipper, Giulia Signorini, and Scott T
Christine M. Tipper, Giulia Signorini, and Scott T. Grafton. Body language in the brain: constructing meaning from expressive movement.Frontiers in Human Neuro- science, V olume 9 - 2015, 2015. ISSN 1662-5161. doi: 10.3389/fnhum.2015.00450. URL https://www.frontiersin.org/journals/human-neuroscience/articles/10. 3389/fnhum.2015.00450. 11
-
[29]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023
2023
-
[30]
Mambatalk: Efficient holistic gesture synthesis with selective state space models.Advances in Neural Information Processing Systems, 37:20055–20080, 2024
Zunnan Xu, Yukang Lin, Haonan Han, Sicheng Yang, Ronghui Li, Yachao Zhang, and Xiu Li. Mambatalk: Efficient holistic gesture synthesis with selective state space models.Advances in Neural Information Processing Systems, 37:20055–20080, 2024
2024
-
[31]
Diffusestylegesture: stylized audio-driven co-speech gesture generation with diffusion models
Sicheng Yang, Zhiyong Wu, Minglei Li, Zhensong Zhang, Lei Hao, Weihong Bao, Ming Cheng, and Long Xiao. Diffusestylegesture: stylized audio-driven co-speech gesture generation with diffusion models. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, pages 5860–5868, 2023
2023
-
[32]
Generating holistic 3d human motion from speech
Hongwei Yi, Hualin Liang, Yifei Liu, Qiong Cao, Yandong Wen, Timo Bolkart, Dacheng Tao, and Michael J Black. Generating holistic 3d human motion from speech. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 469–480, 2023
2023
-
[33]
Pyramotion: Attentional pyramid-structured motion integration for co-speech 3d gesture synthesis
Zhizhuo Yin, Yuk Hang Tsui, and Pan Hui. Pyramotion: Attentional pyramid-structured motion integration for co-speech 3d gesture synthesis. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= QJSrgYcf4b
2025
-
[34]
Speech gesture generation from the trimodal context of text, audio, and speaker identity.ACM Transactions on Graphics (TOG), 39(6):1–16, 2020
Youngwoo Yoon, Bok Cha, Joo-Haeng Lee, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. Speech gesture generation from the trimodal context of text, audio, and speaker identity.ACM Transactions on Graphics (TOG), 39(6):1–16, 2020
2020
-
[35]
Physdiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. Physdiff: Physics-guided human motion diffusion model. InProceedings of the IEEE/CVF international conference on computer vision, pages 16010–16021, 2023
2023
-
[36]
Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis
Xiangyue Zhang, Jianfang Li, Jiaxu Zhang, Ziqiang Dang, Jianqiang Ren, Liefeng Bo, and Zhigang Tu. Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13761– 13771, 2025
2025
-
[37]
Semantic gesticulator: Semantics-aware co-speech gesture synthesis.ACM Transactions on Graphics (TOG), 43(4):1–17, 2024
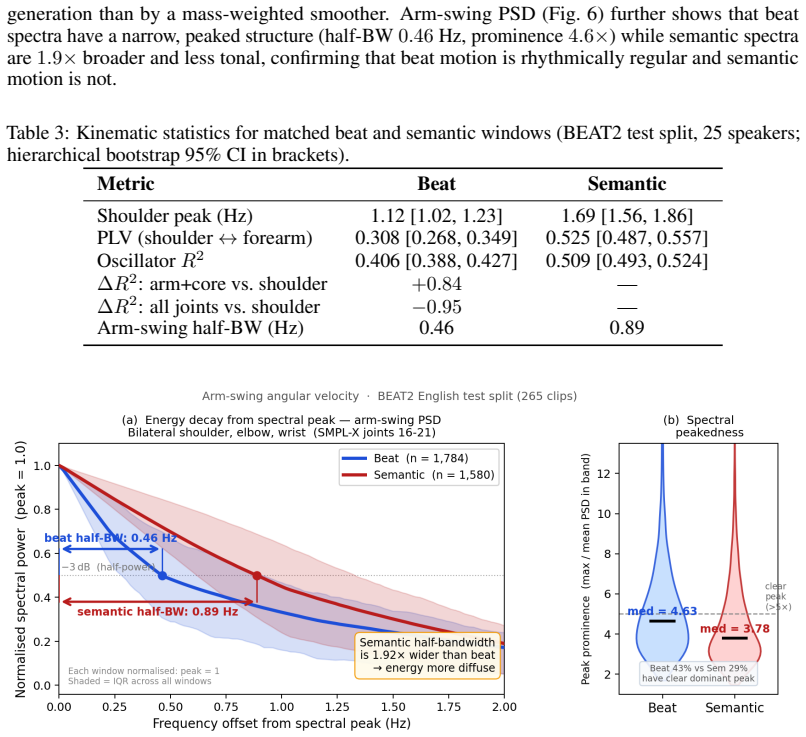
Zeyi Zhang, Tenglong Ao, Yuyao Zhang, Qingzhe Gao, Chuan Lin, Baoquan Chen, and Libin Liu. Semantic gesticulator: Semantics-aware co-speech gesture synthesis.ACM Transactions on Graphics (TOG), 43(4):1–17, 2024. A Motion Analysis: Beat vs. Semantic Motion on BEAT2 Setup and controlled sampling.We analyse BEAT2 [ 16, 17] test-split motion (≥15-frame win- d...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.