SPEAR: Code-Augmented Agentic Prompt Optimization
Pith reviewed 2026-06-29 21:31 UTC · model grok-4.3
The pith
SPEAR lets an agent write and run Python code on evaluation data to analyze prompt errors, winning every industrial LLM judge task on the primary metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPEAR ports the code-as-action paradigm to prompt optimization so the agent itself authors structural error analyses that a long-context LLM cannot reliably extract from raw evaluation DataFrames; the resulting prompts achieve higher agreement and F1 scores on every tested industrial task.
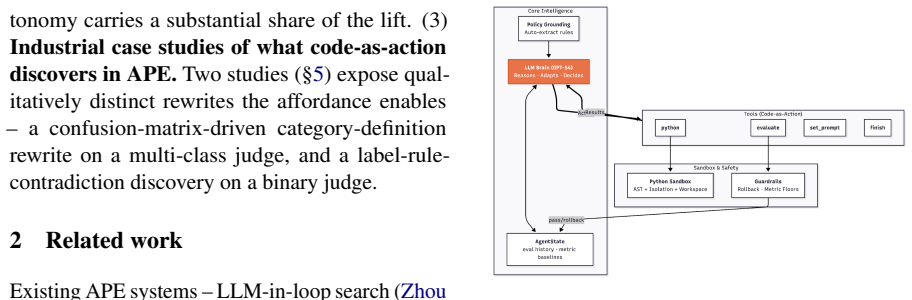
What carries the argument
The Python sandbox tool, which lets the agent write and execute arbitrary Python on the evaluation DataFrame to perform confusion-matrix and error-clustering analyses.
If this is right
- Agentic prompt optimizers that can execute code outperform fixed-pipeline APE methods on complex LLM-as-judge tasks.
- Auto-rollback on metric regression converts an open-ended agent into a reliable monotone improver.
- The Python tool supplies an irreplaceable aggregation step for multi-class error patterns that direct LLM inspection misses.
Where Pith is reading between the lines
- Code-execution tools may improve agent loops in other optimization domains that rely on tabular evaluation data.
- Extending the sandbox to additional analysis libraries could surface still finer error structures.
- Production systems could adopt similar agents to reduce manual prompt iteration cycles.
Load-bearing premise
That a long-context LLM cannot reliably compute class-pair confusion aggregations and similar structural statistics directly from the raw evaluation DataFrame.
What would settle it
Disable the Python tool in SPEAR and measure whether the reported gains of roughly 0.79 kappa on the 5-class tool-selection judge and 0.35 kappa on the hardest extraction dimension disappear.
Figures


read the original abstract
Automatic prompt engineering (APE) rewrites prompts to improve downstream task performance, but existing APE loops treat the optimizer itself as a fixed pipeline. We port the code-as-action paradigm of CodeAct (Wang et al., 2024a) to APE and propose SPEAR (Sandboxed Prompt Engineer with Active Roll-back), a free-form agentic optimizer with four tools -- evaluate, python, set_prompt, finish -- that decides autonomously how and when to use them. The distinctive tool is the Python sandbox: the optimizer writes and executes arbitrary Python on the current evaluation DataFrame, performing structural error analysis (confusion matrices, error clustering, per group metrics) the agent itself authors. Two guardrails turn the long-horizon agent into a monotone-improving optimizer: auto-rollback on metric regression, and an optional guard metric floor. We evaluate on three industrial LLM-as-judge suites (13 judge tasks across recruiter-intake, conversational-memory, and query-refinement systems) plus seven BBH tasks and GSM8K. SPEAR wins every industrial task on the primary metric ($\kappa$ 0.857 vs 0.359 on tool-selection; F1-macro 0.815 vs 0.763 on filter-relevance; $\kappa$ 0.254 vs 0.218 on the hardest extraction dimension). On BBH-7 SPEAR averages 0.938 accuracy vs GEPA 0.628 and TextGrad 0.484. Ablations show the Python tool is the largest single lever on complex judge tasks ($\Delta \approx +0.79\kappa$ on the 5-class tool-selection judge, $\Delta \approx +0.35\kappa$ on the hardest extraction dimension when removed); its irreplaceable contribution is class-pair confusion aggregation that a long-context LLM cannot extract reliably from the raw eval DataFrame.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPEAR, an agentic automatic prompt engineering system that augments an LLM optimizer with four tools (evaluate, python, set_prompt, finish) and uses a Python sandbox for the agent to author and execute structural error analyses (confusion matrices, clustering, per-group metrics) on evaluation DataFrames. Guardrails (auto-rollback on regression, optional guard metric floor) enforce monotone improvement. It reports that SPEAR outperforms published baselines (GEPA, TextGrad) on all 13 industrial LLM-as-judge tasks and on BBH-7/GSM8K, with ablations attributing the largest gains on complex judge tasks to the Python tool.
Significance. If the empirical claims hold after addressing the control-experiment gap, the work provides concrete evidence that code-augmented agents can outperform pure LLM-based prompt optimizers on structured error analysis tasks that are central to industrial LLM-as-judge pipelines. The monotone-improvement guardrails and free-form tool-use policy are reusable design elements that could influence subsequent agentic APE systems.
major comments (2)
- [Abstract] Abstract: The central claim that the Python tool's 'irreplaceable contribution is class-pair confusion aggregation that a long-context LLM cannot extract reliably from the raw eval DataFrame' is load-bearing for the ablation interpretation, yet the reported ablations (tool removal yielding Δ ≈ +0.79κ on tool-selection) contain no control arm in which the LLM is given the full raw DataFrame in context and explicitly prompted to compute and reason over the identical structural statistics (confusion matrices, error clustering, per-group metrics). Without this arm the performance gap cannot be attributed to an inherent long-context limitation rather than prompt design or default agent behavior.
- [Experiments] Experiments (industrial tasks and BBH results): The manuscript reports consistent wins on the primary metric across all tasks but does not state whether the same number of optimization steps, evaluation budget, or prompt templates were used for the GEPA and TextGrad baselines; if the baselines were run under a more restricted protocol the magnitude of the reported gaps (e.g., 0.938 vs 0.628 accuracy on BBH-7) cannot be interpreted as evidence of architectural superiority.
minor comments (2)
- [Abstract] The abstract lists three industrial suites but does not name the exact 13 judge tasks or the primary metric per task; a table or explicit enumeration would improve clarity.
- Reproducibility: No statement is made about public release of the agent code, prompt templates, or the exact DataFrames used for the industrial suites; adding this would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in experimental controls and protocol documentation. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the Python tool's 'irreplaceable contribution is class-pair confusion aggregation that a long-context LLM cannot extract reliably from the raw eval DataFrame' is load-bearing for the ablation interpretation, yet the reported ablations (tool removal yielding Δ ≈ +0.79κ on tool-selection) contain no control arm in which the LLM is given the full raw DataFrame in context and explicitly prompted to compute and reason over the identical structural statistics (confusion matrices, error clustering, per-group metrics). Without this arm the performance gap cannot be attributed to an inherent long-context limitation rather than prompt design or default agent behavior.
Authors: We agree that a control arm in which the LLM optimizer is explicitly given the full raw evaluation DataFrame and prompted to compute the same structural statistics would provide stronger evidence that the performance gap stems from an inherent limitation of long-context reasoning rather than prompt design. The existing ablation removes the Python tool entirely and shows large drops (Δ ≈ +0.79κ on tool-selection), indicating that the agent's ability to author and execute custom analyses is critical. We will add the requested control experiment in the revision to better isolate the contribution of code-augmented analysis. revision: yes
-
Referee: [Experiments] Experiments (industrial tasks and BBH results): The manuscript reports consistent wins on the primary metric across all tasks but does not state whether the same number of optimization steps, evaluation budget, or prompt templates were used for the GEPA and TextGrad baselines; if the baselines were run under a more restricted protocol the magnitude of the reported gaps (e.g., 0.938 vs 0.628 accuracy on BBH-7) cannot be interpreted as evidence of architectural superiority.
Authors: GEPA and TextGrad were run under the identical protocol as SPEAR, using the same number of optimization steps, evaluation budget, and prompt templates. This was done to isolate architectural differences. We will add an explicit statement confirming these matched conditions in the Experiments section of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical results rest on external baselines and ablations
full rationale
The paper reports empirical performance of an agentic optimizer on industrial and benchmark tasks, comparing against externally published baselines (GEPA, TextGrad) and using ablations on tool removal. No equations, fitted parameters, or self-citations appear in the provided text that reduce any performance claim or uniqueness assertion to a quantity defined by the authors' own prior work. The central premise about the Python tool's contribution is presented as an empirical observation from ablations rather than a self-definitional or fitted-input reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- guard metric floor
axioms (1)
- domain assumption Auto-rollback on metric regression together with the guard metric floor converts the long-horizon agent into a monotone-improving optimizer.
Reference graph
Works this paper leans on
-
[1]
Trace is the next AutoDiff: Generative opti- mization with rich feedback, execution traces, and LLMs.arXiv preprint arXiv:2406.16218. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797. Balaji Dinesh Gangireddi, Aniketh Garikaparthi, Man- asi Patwardhan, an...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
LongLLMLingua: Accelerating and enhanc- ing LLMs in long context scenarios via prompt com- pression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand. Association for Computational Linguistics. Jiajie Li, Huayi Zhang, Peng Lin, Jinjun Xiong, and Wei Xu. ...
-
[4]
VISTA: A test-time self-improving video generation agent.arXiv preprint arXiv:2510.15831. Multi-agent iterative prompt optimization for video generation; tournament-based selection plus multi- dimensional (visual / audio / contextual) critique. Krista Opsahl-Ong, Arnav Singhvi, Omar Khattab, Kyle Shrivastava, Siddharth Heidari, Matei Zaharia, and Christop...
-
[5]
TextGrad: Automatic "Differentiation" via Text
Large language models as optimizers. InIn- ternational Conference on Learning Representations (ICLR). Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR). Mert Yuksekgonul, Federico Bianchi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.