OmniToM: Benchmarking Theory of Mind in LLMs via Explicit Belief Modeling
Pith reviewed 2026-06-29 21:25 UTC · model grok-4.3
The pith
Current LLMs struggle to construct explicit belief structures for Theory of Mind reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
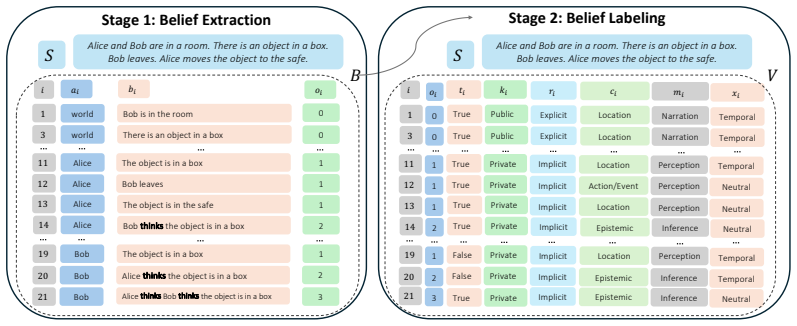
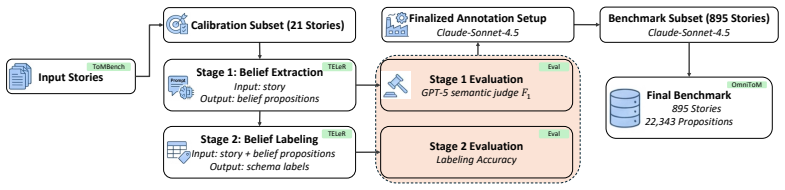
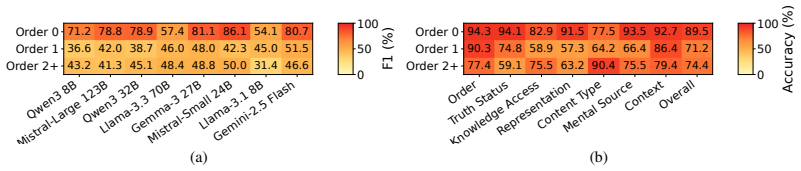
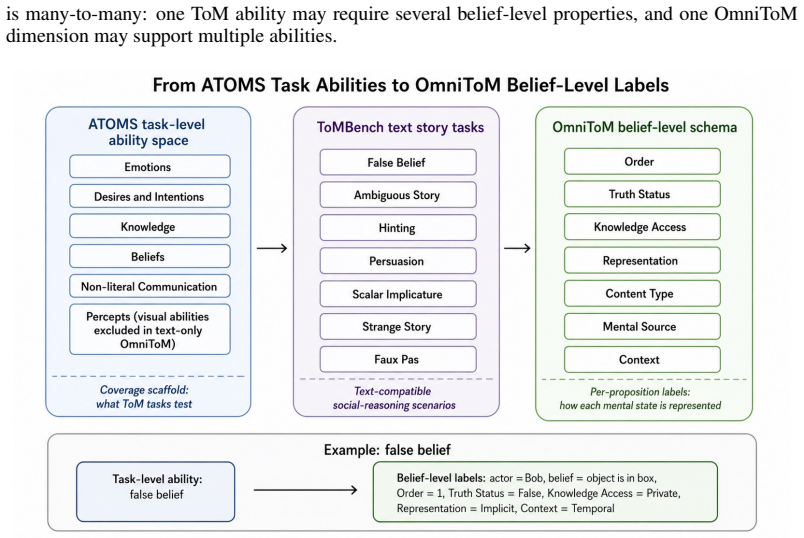
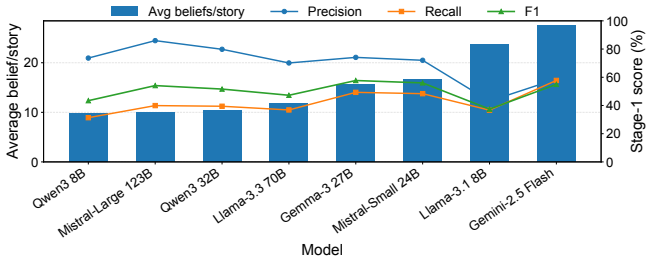
OmniToM is built from 895 stories yielding 22,343 labeled belief propositions. Models are tested in two stages: extracting relevant beliefs and labeling them on recursive order, truth status, knowledge access, explicitness, content type, mental source, and context. Evaluation across models shows an actor-specific belief-tracking bottleneck where LLMs struggle with knowledge-access and representational decisions to transform narrative facts into actors' beliefs and shared mental states.
What carries the argument
The OmniToM benchmark, which uses belief propositions as minimal statements of what an actor takes to be true, combined with a seven-dimensional labeling schema and a two-stage extraction and labeling process.
Load-bearing premise
The human-calibrated LLM-assisted annotation pipeline produces accurate ground-truth belief propositions and seven-dimensional labels without systematic bias from the LLM component.
What would settle it
If a model achieves high scores on both belief extraction and labeling stages of OmniToM but still gives incorrect answers on standard Theory of Mind questions involving the same stories, this would indicate that explicit modeling is not sufficient for correct reasoning.
Figures


read the original abstract
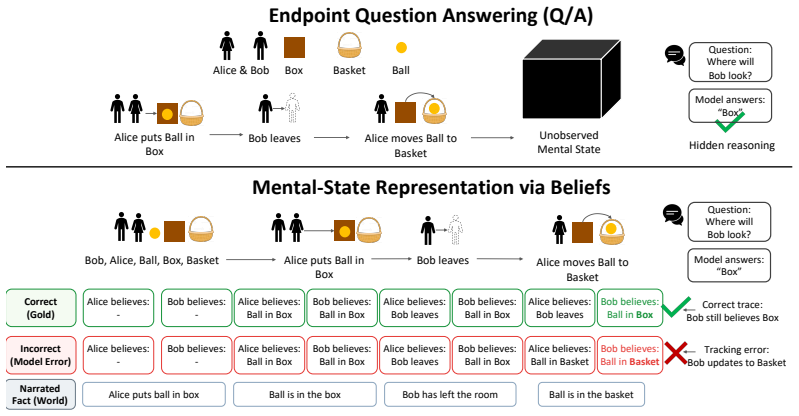
Theory of Mind (ToM), the ability to infer others' knowledge, intentions, and emotions, is commonly evaluated in large language models (LLMs) using end-point question answering, where performance is judged solely by the final answer to a social reasoning query. This paradigm obscures whether the model actually constructs the underlying mental-state representations required for robust reasoning, particularly in scenarios involving divergent, evolving, or mistaken beliefs. In order to address this research gap, we introduce OmniToM, a benchmark that directly evaluates these representations by requiring explicit modeling of belief structures for all relevant actors within a narrative. These structures are composed of belief propositions: minimal statements of what an actor takes to be true about the world or another actor's mental state, allowing knowledge, intentions, emotions, and false beliefs to be analyzed in a common format. Models are evaluated in two stages: Stage 1: Belief Extraction, which extracts from the story the beliefs relevant to its social dynamics, and Stage 2: Belief Labeling, which assigns each belief a seven-dimensional schema label covering recursive order, truth status, knowledge access, explicitness, content type, mental source, and context. Built from 895 stories from the existing ToMBench story corpus and augmented with 22,343 labeled belief propositions, OmniToM uses a human-calibrated LLM-assisted annotation pipeline. Across diverse models in zero-shot evaluation, OmniToM reveals an actor-specific belief-tracking bottleneck: current LLMs struggle with the knowledge-access and representational decisions required to transform narrative facts into actors' beliefs and shared mental states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniToM, a benchmark extending the ToMBench corpus to 895 stories and 22,343 seven-dimensional belief-proposition labels. It evaluates LLMs in two stages—belief extraction from narratives and labeling along recursive order, truth status, knowledge access, explicitness, content type, mental source, and context—claiming that current models exhibit an actor-specific belief-tracking bottleneck, particularly in knowledge-access and representational decisions required to construct actors' beliefs and shared mental states from narrative facts. Evaluation is zero-shot across diverse models.
Significance. If the ground-truth labels are shown to be free of systematic bias, OmniToM would supply a useful diagnostic tool that decomposes ToM performance beyond endpoint QA accuracy, allowing targeted measurement of belief-construction failures. The explicit seven-dimensional schema and human-calibrated pipeline are concrete strengths that could support reproducible follow-up work.
major comments (2)
- [Abstract and annotation pipeline description] The central claim that LLMs struggle with knowledge-access and representational decisions rests on the correctness of the 22,343 labels. The abstract and methods description of the human-calibrated LLM-assisted annotation pipeline supply no quantitative inter-annotator agreement figures, no error analysis of the LLM proposal stage, and no ablation demonstrating that human calibration removes representational shortcuts (e.g., misjudgment of recursive order or false-belief status). This is load-bearing for the bottleneck conclusion.
- [Evaluation section] No details are provided on model selection criteria, number of models evaluated, statistical tests for performance differences, or controls for annotation artifacts that could correlate with the same weaknesses attributed to the test models.
minor comments (2)
- [Dataset construction] Clarify whether the seven-dimensional schema was applied uniformly across all 895 stories or whether story selection introduced any sampling bias.
- [Introduction] The term 'belief propositions' is introduced without an explicit formal definition or example set in the main text; a short illustrative table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in the current manuscript regarding quantitative validation of the annotation pipeline and details in the evaluation section. We will revise the paper to incorporate the requested information and analyses.
read point-by-point responses
-
Referee: [Abstract and annotation pipeline description] The central claim that LLMs struggle with knowledge-access and representational decisions rests on the correctness of the 22,343 labels. The abstract and methods description of the human-calibrated LLM-assisted annotation pipeline supply no quantitative inter-annotator agreement figures, no error analysis of the LLM proposal stage, and no ablation demonstrating that human calibration removes representational shortcuts (e.g., misjudgment of recursive order or false-belief status). This is load-bearing for the bottleneck conclusion.
Authors: We agree that the validity of the 22,343 labels is central to the bottleneck claim and that the current description lacks the requested quantitative support. The revised manuscript will add: (1) inter-annotator agreement figures computed over the human calibration subset, (2) an error analysis breaking down LLM proposal-stage mistakes by dimension (with particular attention to recursive order and false-belief status), and (3) an ablation comparing final labels against the uncalibrated LLM proposals to quantify how human review reduces representational shortcuts. These additions will be placed in a new subsection of the methods. revision: yes
-
Referee: [Evaluation section] No details are provided on model selection criteria, number of models evaluated, statistical tests for performance differences, or controls for annotation artifacts that could correlate with the same weaknesses attributed to the test models.
Authors: We acknowledge these omissions. The revised evaluation section will explicitly state the model selection criteria (covering scale, architecture family, and availability), report the exact number and identities of all models tested, include statistical tests (paired t-tests or Wilcoxon signed-rank tests with multiple-comparison correction) for reported differences, and add controls for annotation artifacts (e.g., correlation analysis between label-dimension distributions and model error patterns, plus a small human-verified subset used to check for systematic bias). revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted inputs
full rationale
The paper constructs an empirical benchmark (OmniToM) from 895 existing ToMBench stories, producing 22,343 labeled belief propositions via a human-calibrated LLM-assisted pipeline. No equations, parameters, or derivations are present; evaluation is zero-shot performance measurement on explicit belief extraction and labeling stages. The reader's circularity score of 0.0 is confirmed: the work contains no self-definitional steps, fitted-input predictions, or self-citation chains that reduce claims to inputs by construction. The annotation pipeline and seven-dimensional schema are presented as methodological choices, not derived results. This is the standard honest outcome for a benchmark paper whose central claims rest on data collection and model evaluation rather than mathematical reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
belief propositions
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Exploring LLMs for South Asian Music Understanding and Generation
This paper introduces a 504-question benchmark for South Asian music understanding and a controlled prompting framework for generation, reporting frontier LLMs at 85-90% on understanding but only 40% stylistic faithfu...
Reference graph
Works this paper leans on
-
[1]
System Card: Claude Sonnet 4.5
Anthropic. System Card: Claude Sonnet 4.5. Technical report, Anthropic, sep 2025. URLhttps://assets.anthropic.com/m/12f214efcc2f457a/original/ Claude-Sonnet-4-5-System-Card.pdf
2025
-
[2]
Simon Baron-Cohen, Michelle O’Riordan, Valerie Stone, Rebecca Jones, and Katherine Plaisted. Recognition of faux pas by normally developing children and children with asperger syndrome or high-functioning autism.Journal of Autism and Developmental Disorders, 29(5): 407–418, 1999. doi: 10.1023/A:1023035012436
-
[3]
Cindy Beaudoin, Élizabel Leblanc, Charlotte Gagner, and Miriam H. Beauchamp. Systematic review and inventory of theory of mind measures for young children.Frontiers in Psychology, 10:2905, 2020. doi: 10.3389/fpsyg.2019.02905
-
[4]
ToMBench: Benchmark- ing theory of mind in large language models
Zhuang Chen, Jincenzi Wu, Jinfeng Zhou, Bosi Wen, Guanqun Bi, Gongyao Jiang, Yaru Cao, Mengting Hu, Yunghwei Lai, Zexuan Xiong, and Minlie Huang. ToMBench: Benchmark- ing theory of mind in large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguisti...
-
[5]
doi: 10.18653/v1/2024.acl-long.847
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.847. URL https://aclanthology.org/2024.acl-long.847/
-
[6]
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-AI. DeepSeek-R1-Distill-Qwen-32B. Hugging Face Model Card, 2025. URL https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
2025
-
[7]
John H. Flavell, Frances L. Green, and Eleanor R. Flavell. Development of knowledge about the appearance–reality distinction.Monographs of the Society for Research in Child Develop- ment, 51(1):1–87, 1986. doi: 10.2307/1165866. Serial No. 212
-
[8]
Gemma Team. Gemma 3 Technical Report, 2025. URLhttps://arxiv.org/abs/2503. 19786. arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Goodman and Andreas Stuhlmüller
Noah D. Goodman and Andreas Stuhlmüller. Knowledge and implicature: Modeling language understanding as social cognition.Topics in Cognitive Science, 5(1):173–184, 2013. doi: 10.1111/tops.12007
-
[10]
Gemini 2.5 Flash
Google. Gemini 2.5 Flash. Google AI for Developers Documentation, 2025. URLhttps: //ai.google.dev/gemini-api/docs/models
2025
-
[11]
Francesca G. E. Happé. An advanced test of theory of mind: Understanding of story char- acters’ thoughts and feelings by able autistic, mentally handicapped, and normal children and adults.Journal of Autism and Developmental Disorders, 24(2):129–154, 1994. doi: 10.1007/BF02172093
-
[12]
Perceptions to beliefs: Exploring precursory inferences for theory of mind in large language models
Chani Jung, Dongkwan Kim, Jiho Jin, Jiseon Kim, Yeon Seonwoo, Yejin Choi, Alice Oh, and Hyunwoo Kim. Perceptions to beliefs: Exploring precursory inferences for theory of mind in large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 19794–19809, Miami, Florida, USA, November 2024. Associatio...
-
[13]
TELeR: A general taxonomy of LLM prompts for benchmarking complex tasks
Shubhra Kanti Karmaker Santu and Dongji Feng. TELeR: A general taxonomy of LLM prompts for benchmarking complex tasks. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 14197–14203, Singapore, December 2023. Association for Computational Linguis- tics. doi: 10.18653/v1/2023.f...
-
[14]
FANToM: A benchmark for stress-testing machine theory of mind in inter- actions
Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. FANToM: A benchmark for stress-testing machine theory of mind in inter- actions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413, Singapore, December 2023. Association for Computational 10 Linguistics. do...
-
[15]
Matthew Le, Y-Lan Boureau, and Maximilian Nickel. Revisiting the evaluation of theory of mind through question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Nat- ural Language Processing (EMNLP-IJCNLP), pages 5872–5877, Hong Kong, China, Novem- ber 2019. As...
-
[16]
Alan M. Leslie. Pretense and representation: The origins of “theory of mind”.Psychological Review, 94(4):412–426, 1987. doi: 10.1037/0033-295X.94.4.412
-
[17]
Llama-3.1-8B-Instruct
Meta. Llama-3.1-8B-Instruct. Hugging Face Model Card, 2024. URLhttps:// huggingface.co/meta-llama/Llama-3.1-8B-Instruct
2024
-
[18]
Llama-3.3-70B-Instruct
Meta. Llama-3.3-70B-Instruct. Hugging Face Model Card, 2024. URLhttps:// huggingface.co/meta-llama/Llama-3.3-70B-Instruct
2024
-
[19]
Mistral Large 2.0
Mistral AI. Mistral Large 2.0. Mistral AI Model Card, jul 2024. URLhttps://docs. mistral.ai/models/model-cards/mistral-large-2-0-24-07
2024
-
[20]
Mistral-Small-24B-Instruct-2501
Mistral AI. Mistral-Small-24B-Instruct-2501. Hugging Face Model Card, 2025. URLhttps: //huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
2025
-
[21]
GPT-5 system card
OpenAI. GPT-5 system card. OpenAI Publication, aug 2025. URLhttps://openai.com/ blog/gpt-5-system-card/
2025
-
[22]
John thinks that Mary thinks that
Josef Perner and Heinz Wimmer. “John thinks that Mary thinks that ...”: Attribution of second- order beliefs by 5- to 10-year-old children.Journal of Experimental Child Psychology, 39(3): 437–471, 1985. doi: 10.1016/0022-0965(85)90051-7
-
[23]
Zhiqiang Pi, Annapurna Vadaparty, Benjamin K. Bergen, and Cameron R. Jones. Dissect- ing the Ullman Variations with a SCALPEL: Why do LLMs fail at Trivial Alterations to the False Belief Task?, 2024. URLhttps://arxiv.org/abs/2406.14737. arXiv:2406.14737, version 2 revised May 27, 2025
-
[24]
Does the chimpanzee have a theory of mind?Behavioral and Brain Sciences, 1(4):515–526, 1978
David Premack and Guy Woodruff. Does the chimpanzee have a theory of mind?Behavioral and Brain Sciences, 1(4):515–526, 1978. doi: 10.1017/S0140525X00076512
-
[25]
Minding language models’ (lack of) theory of mind: A plug-and-play multi-character be- lief tracker
Melanie Sclar, Sachin Kumar, Peter West, Alane Suhr, Yejin Choi, and Yulia Tsvetkov. Minding language models’ (lack of) theory of mind: A plug-and-play multi-character be- lief tracker. InProceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 13960–13980, Toronto, Canada, July
-
[26]
doi: 10.18653/v1/2023.acl-long.780
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.780. URL https://aclanthology.org/2023.acl-long.780/
-
[27]
Tang, Alejandro Cuadron, Chen- guang Wang, Raluca Ada Popa, and Ion Stoica
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y . Tang, Alejandro Cuadron, Chen- guang Wang, Raluca Ada Popa, and Ion Stoica. Judgebench: A benchmark for evaluating LLM-based judges. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Large language models for data annotation and synthesis: A survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. Large language models for data annotation and synthesis: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 930–957, Miami, Florida, USA, Novem- ber 2024. Associat...
-
[29]
Heinz Wimmer and Josef Perner. Beliefs about beliefs: Representation and constraining func- tion of wrong beliefs in young children’s understanding of deception.Cognition, 13(1):103– 128, 1983. doi: 10.1016/0010-0277(83)90004-5. 11
-
[30]
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, and Naihao Deng. Hi- ToM: A benchmark for evaluating higher-order theory of mind reasoning in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10691–10706, Singapore, December 2023. Association for Computational Linguis- tics. doi: 10.18653/v1...
-
[31]
OpenToM: A compre- hensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models
Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Yulan He. OpenToM: A compre- hensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 8593–8623, Bangkok, Thailand, August
-
[32]
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.466. URL https://aclanthology.org/2024.acl-long.466/
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report, 2025. URLhttps: //arxiv.org/abs/2505.09388. arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yong- hao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chat- bot arena. InAdvances in Neural Information Processing Systems, volume 36,
-
[35]
12 Supplementary Material This supplement provides methodological and analysis details supporting the main paper
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/ 91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html. 12 Supplementary Material This supplement provides methodological and analysis details supporting the main paper. We first discuss broader impacts, then provide technical appendices. Appendix A defines the OmniToM schema d...
2023
-
[36]
Identify narrated events and states that the story presents as facts, and record them as world-level beliefs attributed to the special actor ’world’ (order 0)
-
[37]
Identify all actors, including characters or groups, who appear in the narrative and are capable of holding beliefs
-
[38]
For each actor, extract beliefs about the narrated events or states of the world, and record them as first-order beliefs (order 1)
-
[39]
For each actor, extract beliefs about other actors’ beliefs, applying this notion recursively for nested beliefs, and record them as higher-order beliefs (order 2 or higher). Stage 1 Extraction: Shared Level 4 Content Block A good output should satisfy the following: - Include only beliefs grounded in the narrative; do not invent actors, events, or belief...
-
[40]
- Order 1: First-order beliefs (A believes p)
Determine the Order of the belief, which captures the depth of belief reasoning: - Order 0: Narrator- or world-level facts that anchor the story’s ground truth and are not held by any actor. - Order 1: First-order beliefs (A believes p). - Order 2: Second-order beliefs (A believes B believes p). - Order 3: Higher-order recursive beliefs (A believes B beli...
-
[41]
- False if the belief is contradicted by the narration
Determine the Truth-Status of the belief relative to the narrative: - True if the belief is verified or entailed by the narration. - False if the belief is contradicted by the narration. - Unknown if the narrative does not provide sufficient evidence
-
[42]
- Shared if it is mutually known within a subgroup through explicit acknowledgment or obvious mutual awareness
Determine the Knowledge-Access of the belief by assessing who could realistically know it in the story world: - Private if the belief is held internally without evidence others know it. - Shared if it is mutually known within a subgroup through explicit acknowledgment or obvious mutual awareness. - Public if it is common ground across all actors (announce...
-
[43]
- Implicit if the belief must be inferred from actions, perception, or context
Determine the Representation of the belief: - Explicit if the belief is directly stated, spoken, or narrated as a mental state. - Implicit if the belief must be inferred from actions, perception, or context
-
[44]
Determine the Content Type by identifying what the proposition is about: - Use Action/Event for happenings; Desire/Intention for plans or goals. - Use Location when the proposition concerns where an entity is or was, even if it involves a container - Use Contents / Physical State only when the belief concerns what a container holds or an object’s conditio...
-
[45]
Determine the Mental-Source of the belief, indicating how it was acquired: - Narration (Order 0 only), Perception, Memory, Testimony, Inference, Imagination, or Unknown
-
[46]
Prediction Table
Determine the Context of the belief: - Deceptive if shaped by lying, omission, or misdirection. - Temporal if the belief is outdated or reflects recall of a prior true state. - Temporal + False indicates an outdated false belief. - Temporal + True indicates accurate recall of a past fact. - Counterfactual if the belief occurs in a hypothetical or pretense...
-
[47]
In all cases, do not add rows and do not introduce new beliefs that are not present in either table
If a Story Narrative is provided, use it only to resolve ambiguity (pronouns, aliases, implicit entities) and paraphrase meaning; if no narrative is provided, ignore narrative context entirely. In all cases, do not add rows and do not introduce new beliefs that are not present in either table
-
[48]
Treat Actors as distinct mental agents and normalize only cosmetic variants of the same Actor name (case/spacing/punctuation and clear shortenings); never merge different Ground Truth Actors
-
[49]
Handle the special actor ’world’ first: treat ’world’ as the key for narrated facts and events, and align world-level beliefs conservatively, typically one-to-one, allowing only minor normalization differences
-
[50]
Restrict candidate matches to the same Actor group after normalization; if the Actor does not match, the row cannot match regardless of belief similarity
-
[51]
If multiple rows compete for the same target row, keep only the closest semantic match and force the others to choose different unmatched targets or become 0
Default to one-to-one with bookkeeping: if (and only if) there exists a clear semantically equivalent belief for the same Actor, assign the row its single best match among currently-unmatched target rows; otherwise assign no match (MatchCount = 0). If multiple rows compete for the same target row, keep only the closest semantic match and force the others ...
-
[52]
Allow one-to-many only for compound rows: if a row clearly contains multiple independent beliefs, you may align it to 2–3 different rows in the other table within the same Actor group, but only if each aligned target row captures a distinct part of the compound meaning
-
[53]
I have a basketball game this afternoon, will you come to watch?
Ensure symmetry: after completing matches for Prediction rows, also compute MatchCount for every Ground Truth row using the same alignment decisions. Semantic Judge: Level 4 Addition Block A good output should satisfy the following: - Only compare beliefs inside the same Actor group; Ground Truth Actors are unique and must not be merged—if Actor differs, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.