Model Unlearning Objectives Vary for Distinct Language Functions
Pith reviewed 2026-06-29 18:35 UTC · model grok-4.3
The pith
Unlearning methods must be designed separately for distinct language functions such as dangerous knowledge versus toxicity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
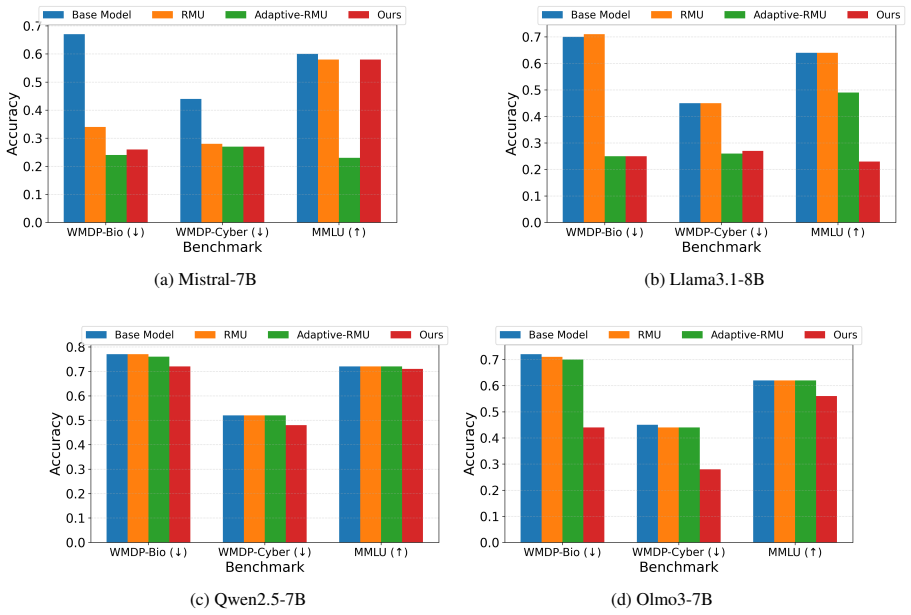
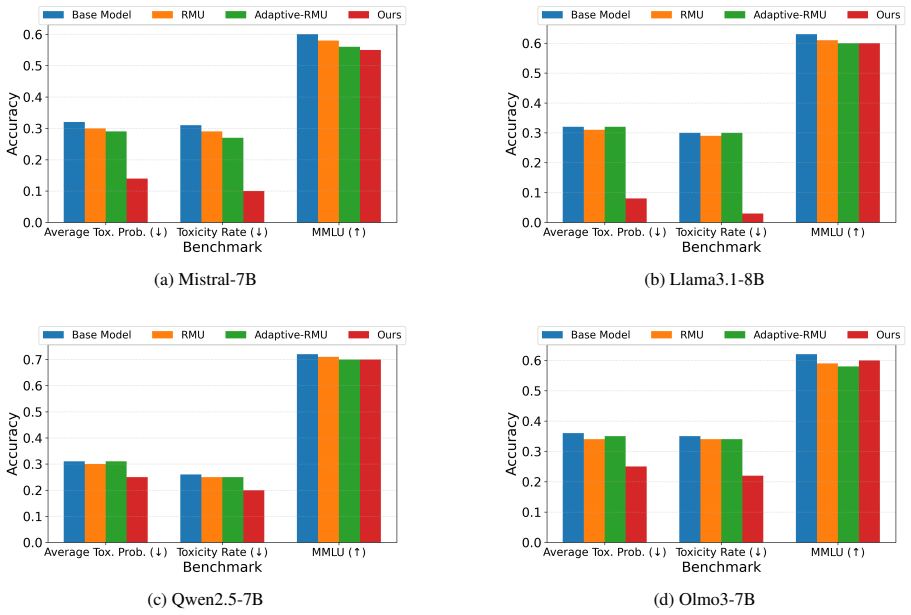
We argue that unlearning methods should be designed for the language function at issue. To study this, we consider two mechanistically distinct unlearning goals, dangerous-knowledge unlearning and toxicity unlearning. For dangerous knowledge, we introduce a cosine-based, meta-learned variant of RMU. For toxicity, we propose a multi-layer objective based on layer-specific probe directions. Across four open-source 7-8B models, our methods achieve strong results, based on distinct training objectives for the two types of unlearning. Overall, our results suggest that unlearning should be studied as a family of problems, analogous to the multiple types of LLM post-training.
What carries the argument
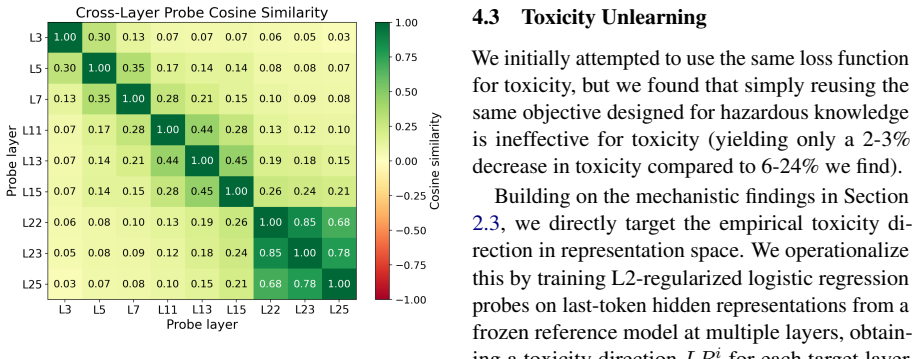
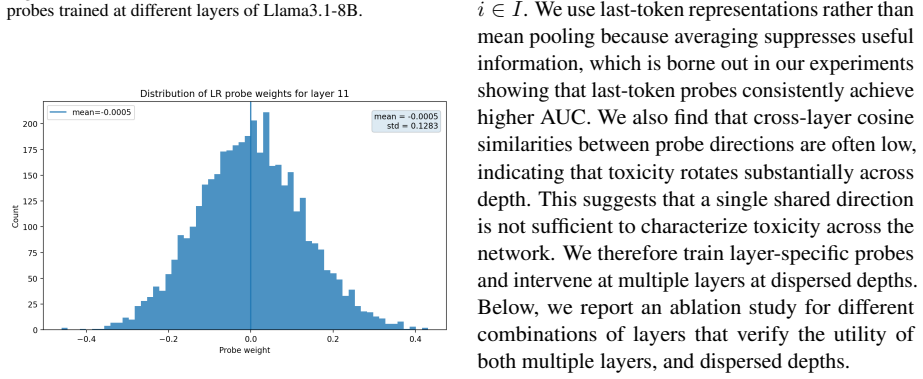
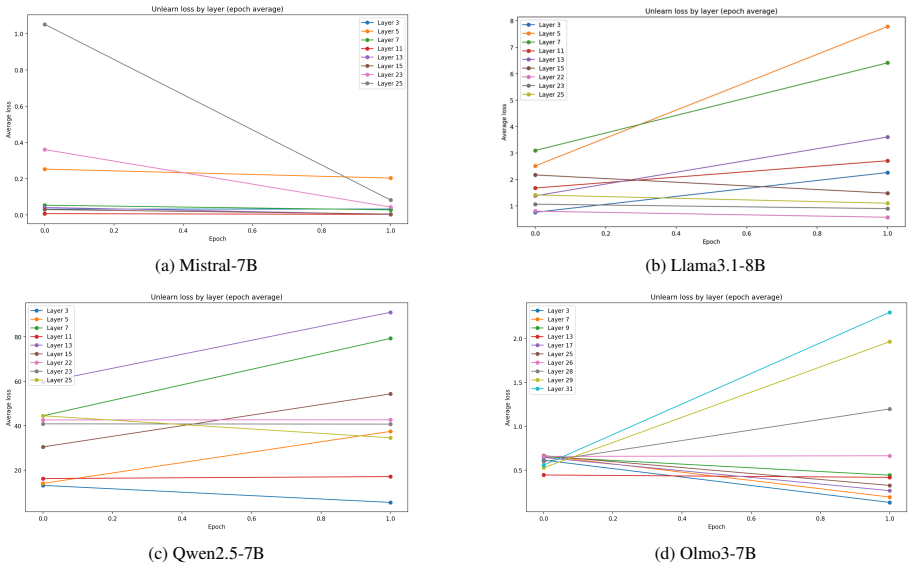
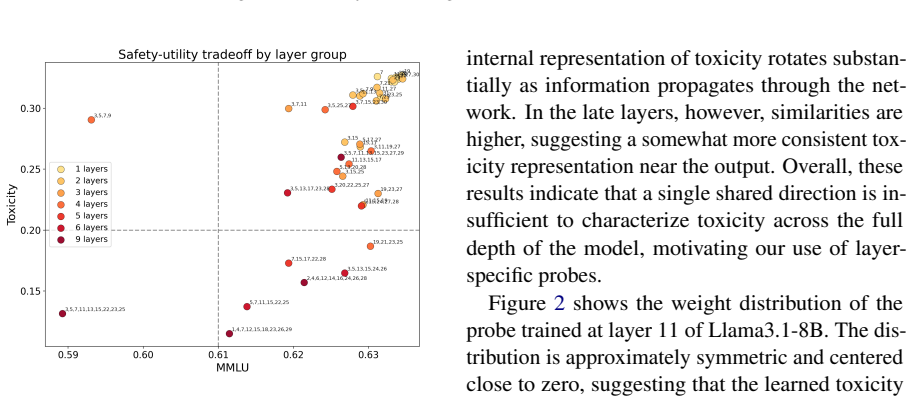
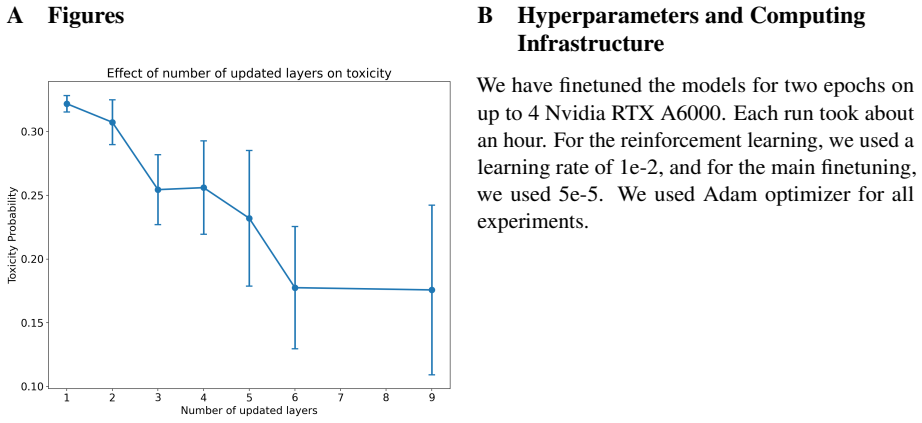
Distinct training objectives for different unlearning goals: a cosine-based meta-learned RMU for dangerous knowledge and a multi-layer probe objective for toxicity.
If this is right
- Unlearning techniques developed for one goal will not transfer directly to the other.
- Research should treat unlearning as multiple specialized problems rather than seeking a universal method.
- Benchmarks and evaluations for unlearning success should account for the distinct mechanisms involved.
- Post-training analogies imply that families of unlearning techniques will continue to develop.
Where Pith is reading between the lines
- Safety engineering may shift toward modular toolkits of unlearning methods for different risk categories.
- The distinction could apply to additional functions such as reducing hallucinations or enforcing specific factual constraints.
- Testing whether the two objectives interfere when applied together would clarify practical deployment limits.
Load-bearing premise
That dangerous-knowledge unlearning and toxicity unlearning are mechanistically distinct enough to require entirely separate objectives.
What would settle it
Showing that the cosine-based RMU for dangerous knowledge performs as well on toxicity reduction as the multi-layer probe method does, or vice versa, without any adaptation.
Figures
read the original abstract
Large language models (LLMs) learn undesirable properties during pretraining, including dangerous knowledge and toxic text generation. Just as post-training uses different objectives to shape different behaviors, we argue that unlearning methods should be designed for the language function at issue. To study this, we consider two mechanistically distinct unlearning goals, dangerous-knowledge unlearning and toxicity unlearning. For dangerous knowledge, we introduce a cosine-based, meta-learned variant of RMU. For toxicity, we propose a multi-layer objective based on layer-specific probe directions. Across four open-source 7-8B models, our methods achieve strong results, based on distinct training objectives for the two types of unlearning. Overall, our results suggest that unlearning should be studied as a family of problems, analogous to the multiple types of LLM post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM unlearning requires distinct objectives tailored to specific language functions, as dangerous-knowledge unlearning and toxicity unlearning are mechanistically distinct. It introduces a cosine-based meta-learned variant of RMU for the former and a multi-layer probe objective for the latter, reporting strong results across four 7-8B open-source models and concluding that unlearning should be studied as a family of problems analogous to post-training objectives.
Significance. If the central empirical claim holds after addressing the experimental gaps, the work would provide a useful framing for unlearning research by highlighting the need for function-specific methods rather than generic approaches. The introduction of task-tailored techniques (meta-learned RMU and layer-specific probes) offers concrete starting points for future specialization, though the current evidence does not yet establish that these are non-interchangeable.
major comments (2)
- [Experimental results] Experimental results section: No cross-task ablation is reported in which the cosine-based meta-learned RMU is applied to toxicity unlearning or the multi-layer probe is applied to dangerous-knowledge unlearning. Without these comparisons, the observed performance cannot distinguish between method specialization (supporting the claim of distinct objectives) and the possibility that both techniques are broadly effective unlearning methods; this directly undermines the load-bearing assertion that separate families of objectives are required.
- [Methods and results] Methods and results: The abstract and methods describe 'strong results' but the provided text gives no quantitative metrics, baselines, statistical tests, or controls for post-hoc selection; without these details it is impossible to assess whether the reported gains are robust or task-specific.
minor comments (1)
- [Abstract] Abstract: Lacks any mention of specific evaluation metrics, dataset sizes, or statistical significance, making the 'strong results' claim difficult to interpret without reading the full experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important ways to strengthen the evidence for our central claim. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: No cross-task ablation is reported in which the cosine-based meta-learned RMU is applied to toxicity unlearning or the multi-layer probe is applied to dangerous-knowledge unlearning. Without these comparisons, the observed performance cannot distinguish between method specialization (supporting the claim of distinct objectives) and the possibility that both techniques are broadly effective unlearning methods; this directly undermines the load-bearing assertion that separate families of objectives are required.
Authors: We agree this is a substantive gap. The manuscript demonstrates that each method achieves strong results on its intended task and is motivated by the distinct mechanisms of dangerous-knowledge versus toxicity unlearning, but without the requested cross-task ablations it is not possible to rule out that the techniques could be interchangeable. We will add the cross-task experiments (or, if compute constraints prevent full runs, a clear discussion of the limitation and planned follow-up) in the revised version. revision: yes
-
Referee: [Methods and results] Methods and results: The abstract and methods describe 'strong results' but the provided text gives no quantitative metrics, baselines, statistical tests, or controls for post-hoc selection; without these details it is impossible to assess whether the reported gains are robust or task-specific.
Authors: The full manuscript reports quantitative metrics, baseline comparisons (including standard RMU and other unlearning approaches), and evaluation details across the four models. We will revise the abstract to include key numerical results and expand the methods section to explicitly describe statistical tests, variance reporting, and controls against post-hoc selection. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes two new unlearning methods (cosine-based meta-learned RMU for dangerous knowledge; multi-layer probe for toxicity) and reports empirical results on four models. Claims rest on experimental performance rather than any derivation that reduces by construction to inputs, self-definitions, or self-citation chains. No equations or steps in the abstract or described content exhibit the enumerated circular patterns; the argument for task-specific objectives is framed as an empirical suggestion, not a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anne Auger, Johannes Bader, Dimo Brockhoff, and Eckart Zitzler
Something just like trust : Toxicity recognition of span and target.Preprint, arXiv:2506.02326. Anne Auger, Johannes Bader, Dimo Brockhoff, and Eckart Zitzler. 2012. Hypervolume-based multiob- jective optimization: Theoretical foundations and practical implications.Theoretical Computer Sci- ence, 425:75–103. Lucas Bourtoule, Varun Chandrasekaran, Christop...
-
[2]
Language Models are Few-Shot Learners
Language models are few-shot learners.arXiv preprint arXiv:2005.14165. Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. In2015 IEEE Symposium on Security and Privacy, pages 463–480. IEEE. Huu-Tien Dang, Thanh-Tung Hoang, Le-Minh Nguyen, and Naoya Inoue. 2025. Improving the robustness of representation misdirection ...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Shengyuan Hu, Yiwei Fu, Zhiwei Steven Wu, and Vir- ginia Smith. 2024. Jogging the memory of unlearned llms through targeted relearning attacks.arXiv preprint arXiv:2406.13356. Dang Huu-Tien, Trung-Tin Pham, Hoang Thanh-Tung, and Naoya Inoue. 2024. On effects of steering laten...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
In Proceedings of the 41st International Conference on Machine Learning, pages 26361–26378
A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity. In Proceedings of the 41st International Conference on Machine Learning, pages 26361–26378. PMLR. Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, et al
-
[5]
InProceedings of the 41st International Conference on Machine Learn- ing, pages 28525–28550
The wmdp benchmark: Measuring and reduc- ing malicious use with unlearning. InProceedings of the 41st International Conference on Machine Learn- ing, pages 28525–28550. PMLR. Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. Lin- guistic knowledge and transferability of contextual representations. InProceedings of ...
-
[6]
TOFU: A Task of Fictitious Unlearning for LLMs
ParaDetox: Detoxification with parallel data. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 6804–6818, Dublin, Ireland. Association for Computational Linguistics. Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. 2024. Tofu: A task of fictitious...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Olmo 3.Preprint, arXiv:2512.13961. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, et al. 2022. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290. Ronald J Williams. 1992. Simple statistical gradient- following algorithms for connectionist reinforcement learning.Machine learning, 8(3):229–256. Yanwu Xu, Mingming Gong, Tongliang Liu, Kayhan Batmanghelich, and Chaohui Wang. 2018. Robust angu...
work page internal anchor Pith review Pith/arXiv arXiv 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.