Variational Inference for Evidential Deep Learning
Pith reviewed 2026-06-29 19:48 UTC · model grok-4.3
The pith
Reformulating evidential deep learning as variational inference yields an ELBO that curbs excessive evidence and justifies setting the Dirichlet parameter α to e plus one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reformulating evidential learning through variational inference, the authors derive an Evidence Lower Bound that prevents evidence from growing excessively. They rigorously establish a generalization bound showing how predicted uncertainty, feature complexity, and network complexity affect the bound, and prove that setting α = e + 1 minimizes it.
What carries the argument
The Evidence Lower Bound (ELBO) derived from the variational inference reformulation of the evidential objective, which serves as a regularizer on evidence accumulation.
If this is right
- The ELBO prevents evidence from growing excessively on both positive and negative classes.
- The generalization bound is minimized when the Dirichlet parameter is set to α = e + 1.
- Predicted uncertainty, feature complexity, and network complexity directly influence the tightness of the generalization bound.
- VI-EDL improves performance on out-of-distribution detection, noise detection, and autonomous driving scenarios compared with prior evidential methods.
Where Pith is reading between the lines
- The same variational reformulation technique could be tested on other uncertainty-aware losses that rely on Dirichlet or similar conjugate priors.
- The explicit dependence of the bound on feature and network complexity suggests a route to architecture search guided by uncertainty calibration rather than accuracy alone.
- If the bound remains predictive on larger models, it may offer a way to set the single hyperparameter α without cross-validation on new tasks.
Load-bearing premise
The variational inference reformulation of the original evidential objective produces an ELBO whose optimization yields the claimed uncertainty behavior and whose derived generalization bound is tight enough to justify the specific Dirichlet parameter choice.
What would settle it
Training the VI-EDL objective on a dataset where conventional EDL produces growing evidence and checking whether the new ELBO keeps total evidence bounded while the generalization bound reaches its minimum at α = e + 1.
Figures
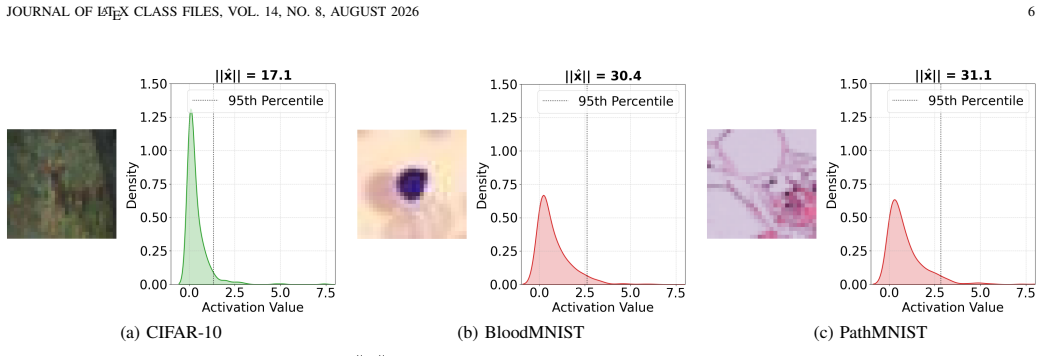
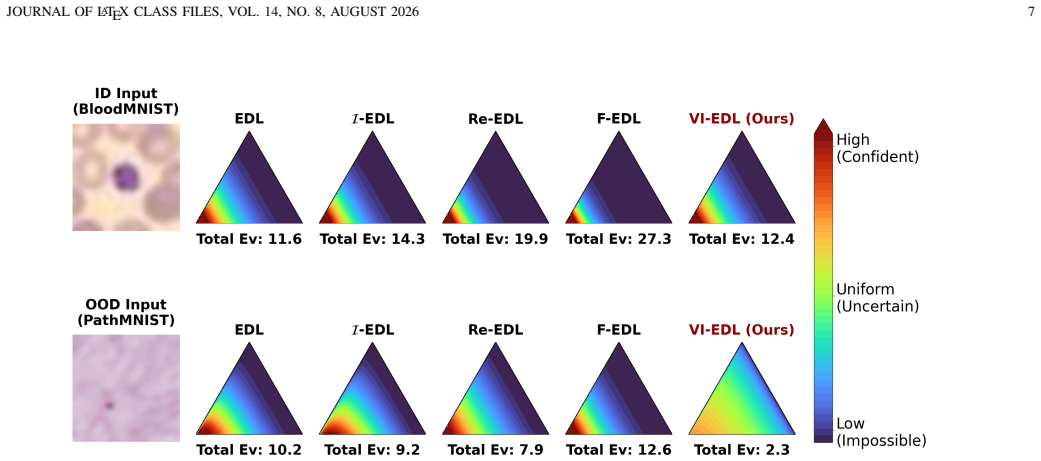

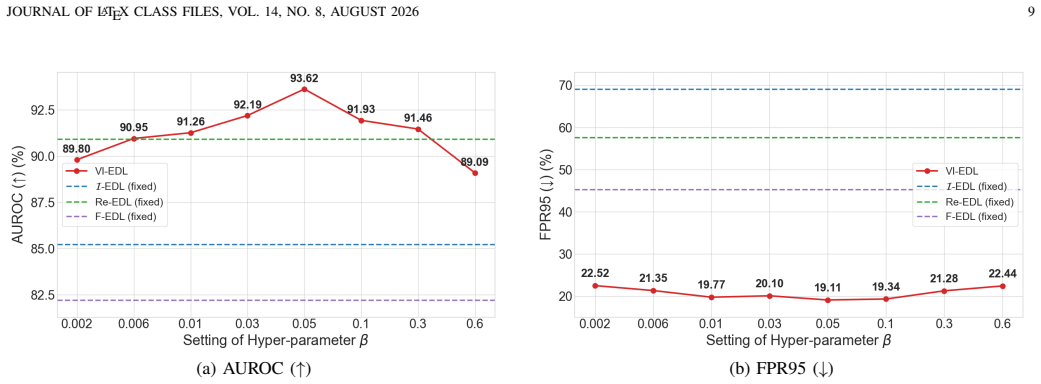
read the original abstract
While Deep Neural Networks (DNNs) achieve remarkable performance, their tendency to produce overconfident predictions. Evidential Deep Learning (EDL) mitigates this by formulating predictions as a Dirichlet distribution over class probabilities to explicitly quantify epistemic uncertainty. However, we found that the conventional EDL suffers from two fundamental limitations: a Kullback-Leibler (KL) penalty that only suppresses the evidence of negative classes, producing excessively high evidence therefore decreasing the model's ability to quantify uncertainty, and an absence in theoretical guarantee of setting Dirichlet parameter $\alpha=e+1$. In this paper, we propose a mathematically principled framework, Variational Inference Evidential Deep Learning (VI-EDL). By reformulating evidential learning through the lens of variational inference, we derive an Evidence Lower Bound (ELBO), which prevents the evidence from growing excessively. Theoretically, we rigorously establish a generalization bound and reveal how the predicted uncertainty, feature and network complexity affect this bound, and why setting $\boldsymbol{\alpha} = \mathbf{e} + \mathbf{1}$ can minimize it. Extensive experiments on standard visual and medical datasets demonstrate that VI-EDL achieves state-of-the-art performance, showing excellent performance in out-of-distribution detection, noise detection and autonomous driving scenario. The code is available in https://github.com/seutjw/VI-EDL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard Evidential Deep Learning (EDL) suffers from a KL penalty that only suppresses evidence on negative classes (leading to excessive evidence and poor uncertainty quantification) and lacks theoretical justification for the Dirichlet parameter choice α = e + 1. It proposes VI-EDL, which reformulates evidential learning via variational inference to derive an ELBO that controls evidence growth, rigorously establishes a generalization bound that reveals the effects of predicted uncertainty, feature complexity, and network complexity, and shows why α = e + 1 minimizes the bound. Experiments on visual and medical datasets report state-of-the-art results on out-of-distribution detection, noise detection, and autonomous driving scenarios, with code released.
Significance. If the ELBO derivation is valid and the generalization bound is sufficiently tight and non-circular, the work supplies a principled variational foundation for evidential methods together with an explicit complexity-dependent analysis of uncertainty; this could strengthen reliability guarantees for DNNs in safety-critical settings. The reproducibility via public code is a positive factor.
major comments (2)
- [§4, Theorem 1] §4 (Generalization bound, Theorem 1): the bound is derived directly from the paper's own ELBO; to confirm it supplies independent grounding rather than restating properties built into the variational objective, the paper must show that the bound's dependence on uncertainty and complexity is tight enough to distinguish α = e + 1 from nearby values (e.g., α = e or α = 2e) under the stated modeling assumptions on features and network complexity. A concrete test would be to evaluate the bound numerically on the trained models and compare predicted vs. observed uncertainty behavior.
- [§3.2] §3.2 (ELBO derivation): the claim that the derived ELBO prevents evidence from growing excessively rests on the specific form of the variational objective; the manuscript should explicitly compare the resulting evidence magnitudes (or the effective KL term) against the original EDL objective on the same architectures to demonstrate the claimed suppression of positive-class evidence.
minor comments (2)
- Notation for the Dirichlet parameter vector is inconsistent between the abstract (bold α = e + 1) and later sections; standardize throughout.
- Figure captions for the autonomous-driving results should include the exact metrics (e.g., AUROC or ECE) and baseline names for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate the requested analyses in the revision to strengthen the theoretical grounding.
read point-by-point responses
-
Referee: [§4, Theorem 1] §4 (Generalization bound, Theorem 1): the bound is derived directly from the paper's own ELBO; to confirm it supplies independent grounding rather than restating properties built into the variational objective, the paper must show that the bound's dependence on uncertainty and complexity is tight enough to distinguish α = e + 1 from nearby values (e.g., α = e or α = 2e) under the stated modeling assumptions on features and network complexity. A concrete test would be to evaluate the bound numerically on the trained models and compare predicted vs. observed uncertainty behavior.
Authors: We acknowledge that the generalization bound is formally derived from the ELBO. Nevertheless, the bound yields an explicit, non-circular dependence on predicted uncertainty, feature complexity, and network complexity that is not presupposed by the variational objective itself and that directly identifies α = e + 1 as the minimizer. To address the tightness concern, we will add numerical evaluations of the bound on the trained models for α = e, e + 1, and 2e, together with comparisons against observed uncertainty behavior, in the revised manuscript. revision: yes
-
Referee: [§3.2] §3.2 (ELBO derivation): the claim that the derived ELBO prevents evidence from growing excessively rests on the specific form of the variational objective; the manuscript should explicitly compare the resulting evidence magnitudes (or the effective KL term) against the original EDL objective on the same architectures to demonstrate the claimed suppression of positive-class evidence.
Authors: We agree that a side-by-side comparison would make the suppression effect more transparent. In the revision we will include quantitative comparisons of per-class evidence magnitudes and the effective KL divergence terms between VI-EDL and standard EDL, evaluated on identical network architectures and datasets. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central derivation begins with a variational reformulation of the existing EDL objective to produce an ELBO, followed by a generalization bound derived from that ELBO under explicit modeling assumptions on uncertainty, features, and network complexity. This bound is then used to analyze the effect of α = e + 1. No quoted step reduces the claimed result to a fitted parameter renamed as prediction, a self-definitional loop, or a load-bearing self-citation whose content is itself unverified. The derivation chain is self-contained against external benchmarks once the VI reformulation and bound assumptions are granted; the α choice follows from minimizing the derived expression rather than being imposed by construction. This is the normal, non-circular outcome for a paper that introduces a new objective and then proves properties of it.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Variational inference yields a valid evidence lower bound (ELBO) for the target distribution.
- domain assumption The Dirichlet distribution appropriately represents epistemic uncertainty over class probabilities.
Reference graph
Works this paper leans on
-
[1]
Deep learning
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521(7553):436–444, 2015
2015
-
[2]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, pages 770–778, 2016
2016
-
[3]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the International Conference on Machine Learning, ICML 2017, pages 1321–1330, 2017
2017
-
[4]
Deep neural networks are easily fooled: High confidence predictions for unrecognizable images
Anh Mai Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, pages 427–436, 2015
2015
-
[5]
A baseline for detecting misclassified and out-of-distribution examples in neural networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. InInternational Conference on Learning Representations, ICLR 2017
2017
-
[6]
Generalized out-of-distribution detection: A survey.CoRR, abs/2110.11334, 2021
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey.CoRR, abs/2110.11334, 2021
-
[7]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InAdvances in Neural Information Processing Systems on Neural Information Processing Systems 2018, NeurIPS 2018, pages 7167–7177, 2018
2018
-
[8]
Owens, and Yixuan Li
Weitang Liu, Xiaoyun Wang, John D. Owens, and Yixuan Li. Energy- based out-of-distribution detection. InAdvances in Neural Information Processing Systems on Neural Information Processing Systems 2020, NeurIPS 2020
2020
-
[9]
Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. InInternational Conference on Learning Representations, ICLR 2018
2018
-
[10]
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? InAdvances in Neural Information Processing Systems on Neural Information Processing Systems 2017, NeurIPS 2017, pages 5574–5584, 2017
2017
-
[11]
Towards safe autonomous driving: Capture uncertainty in the deep neural network for lidar 3d vehicle detection
Di Feng, Lars Rosenbaum, and Klaus Dietmayer. Towards safe autonomous driving: Capture uncertainty in the deep neural network for lidar 3d vehicle detection. InInternational Conference on Intelligent Transportation Systems, ITSC 2018, pages 3266–3273, 2018
2018
-
[12]
de Albuquerque
Khan Muhammad, Amin Ullah, Jaime Lloret, Javier Del Ser, and Victor Hugo C. de Albuquerque. Deep learning for safe autonomous driving: Current challenges and future directions.IEEE Trans. Intell. Transp. Syst., 22(7):4316–4336, 2021
2021
-
[13]
A guide to deep learning in healthcare
Andre Esteva, Alexandre Robicquet, Bharath Ramsundar, V olodymyr Kuleshov, Mark DePristo, Katherine Chou, Claire Cui, Greg Corrado, Sebastian Thrun, and Jeff Dean. A guide to deep learning in healthcare. Nature Medcine, 25(1):24–29, 2019
2019
-
[14]
Weight uncertainty in neural network
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. InProceedings of the International Conference on Machine Learning, ICML 2015, pages 1613–1622, 2015
2015
-
[15]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of the International Conference on Machine Learning, ICML 2016, pages 1050–1059, 2016
2016
-
[16]
Kaplan, and Melih Kandemir
Murat Sensoy, Lance M. Kaplan, and Melih Kandemir. Evidential deep learning to quantify classification uncertainty. InAdvances in Neural Information Processing Systems Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, pages 3183–3193, 2018
2018
-
[17]
Artificial Intelligence: Foundations, Theory, and Algorithms
Audun Jøsang.Subjective Logic - A Formalism for Reasoning Under Uncertainty. Artificial Intelligence: Foundations, Theory, and Algorithms. Springer, 2016
2016
-
[18]
Dempster
Arthur P. Dempster. Upper and lower probabilities induced by a multivalued mapping. InClassic Works of the Dempster-Shafer Theory of Belief Functions, pages 57–72. Springer, 2008
2008
-
[19]
Variational Inference: A Review for Statisticians
David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. Variational inference: A review for statisticians.CoRR, abs/1601.00670, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors,International Conference on Learning Representations, ICLR 2014
2014
-
[21]
Uncertainty estimation by fisher information-based evidential deep learning
Danruo Deng, Guangyong Chen, Yang Yu, Furui Liu, and Pheng-Ann Heng. Uncertainty estimation by fisher information-based evidential deep learning. InProceedings of the International Conference on Machine Learning, ICML 2023, Proceedings of Machine Learning Research, pages 7596–7616, 2023
2023
-
[22]
Revisiting essential and nonessential settings of evidential deep learning.IEEE Trans
Mengyuan Chen, Junyu Gao, and Changsheng Xu. Revisiting essential and nonessential settings of evidential deep learning.IEEE Trans. Pattern Anal. Mach. Intell., 47(10):8658–8673, 2025
2025
-
[23]
Uncertainty estimation by flexible evidential deep learning.CoRR, abs/2510.18322, 2025
Taeseong Yoon and Heeyoung Kim. Uncertainty estimation by flexible evidential deep learning.CoRR, abs/2510.18322, 2025
-
[24]
Region-based evidential deep learning to quantify uncertainty and improve robustness of brain tumor segmentation.Neural Comput
Hao Li, Yang Nan, Javier Del Ser, and Guang Yang. Region-based evidential deep learning to quantify uncertainty and improve robustness of brain tumor segmentation.Neural Comput. Appl., 35(30):22071–22085, 2023
2023
-
[25]
Namboodiri
Sai Susmitha Arvapalli and Vinay P. Namboodiri. Evidential retriever: Uncertainty-aware medical image retrieval. InProceedings of The 9th International Conference on Medical Imaging with Deep Learning, volume 315, pages 2208–2232, 2026
2026
-
[26]
Evidential deep learning for sensor fusion
Mihreteab Negash Geletu, Jean-Philippe Lauffenburger, Thomas Josso- Laurain, Maxime Devanne, and Mengesha Mamo Wogari. Evidential deep learning for sensor fusion. In27th International Conference on Information Fusion, FUSION 2024, Venice, Italy, July 8-11, 2024, pages 1–8, 2024
2024
-
[27]
Uncertainty-aware evidential fusion for multi-modal object detection in autonomous driving.Drones, 10(2), 2026
Qihang Yang, Yang Zhao, and Hong Cheng. Uncertainty-aware evidential fusion for multi-modal object detection in autonomous driving.Drones, 10(2), 2026
2026
-
[28]
Evidential deep learning for guided molecular property prediction and discovery.ACS Central Science, 2021
Ava P Soleimany, Alexander Amini, Samuel Goldman, Daniela Rus, Sangeeta Bhatia, and Connor Coley. Evidential deep learning for guided molecular property prediction and discovery.ACS Central Science, 2021
2021
-
[29]
Cambridge University Press, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understanding Machine Learning - From Theory to Algorithms. Cambridge University Press, 2014
2014
-
[30]
Bartlett and Shahar Mendelson
Peter L. Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results.J. Mach. Learn. Res., 3:463–482, 2002
2002
-
[31]
Natural posterior network: Deep bayesian predictive uncertainty for exponential family distributions
Bertrand Charpentier, Oliver Borchert, Daniel Zügner, Simon Geisler, and Stephan Günnemann. Natural posterior network: Deep bayesian predictive uncertainty for exponential family distributions. InInternational Conference on Learning Representations, ICLR 2022
2022
-
[32]
Sim- ple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Sim- ple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems on Neural Information Processing Systems 2017, NeurIPS 2017, pages 6402–6413, 2017
2017
-
[33]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, 2009
2009
-
[34]
Predicting the state of a house using google street view - an analysis of deep binary classification models for the assessment of the quality of flemish houses
Margot Geerts, Kiran Shaikh, Jochen De Weerdt, and Seppe vanden Broucke. Predicting the state of a house using google street view - an analysis of deep binary classification models for the assessment of the quality of flemish houses. InResearch Challenges in Information Science - 16th International Conference, RCIS 2022, pages 703–710, 2022
2022
-
[35]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. InSixth Indian Conference on Computer Vision, Graphics & Image Processing, ICVGIP 2008, pages 722–729, 2008
2008
-
[36]
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2: A large-scale lightweight benchmark for 2d and 3d biomedical image classification. CoRR, abs/2110.14795, 2021. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2026 11 APPENDIXA DETAILEDDERIVATION OFEQ. (9) First, recall the probabil...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.