Beyond Holistic Models: Systematic Component-level Benchmarking of Deep Multivariate Time-Series Forecasting
Pith reviewed 2026-06-29 19:05 UTC · model grok-4.3
The pith
Systematic component selection from a performance corpus outperforms state-of-the-art holistic models in multivariate time series forecasting.
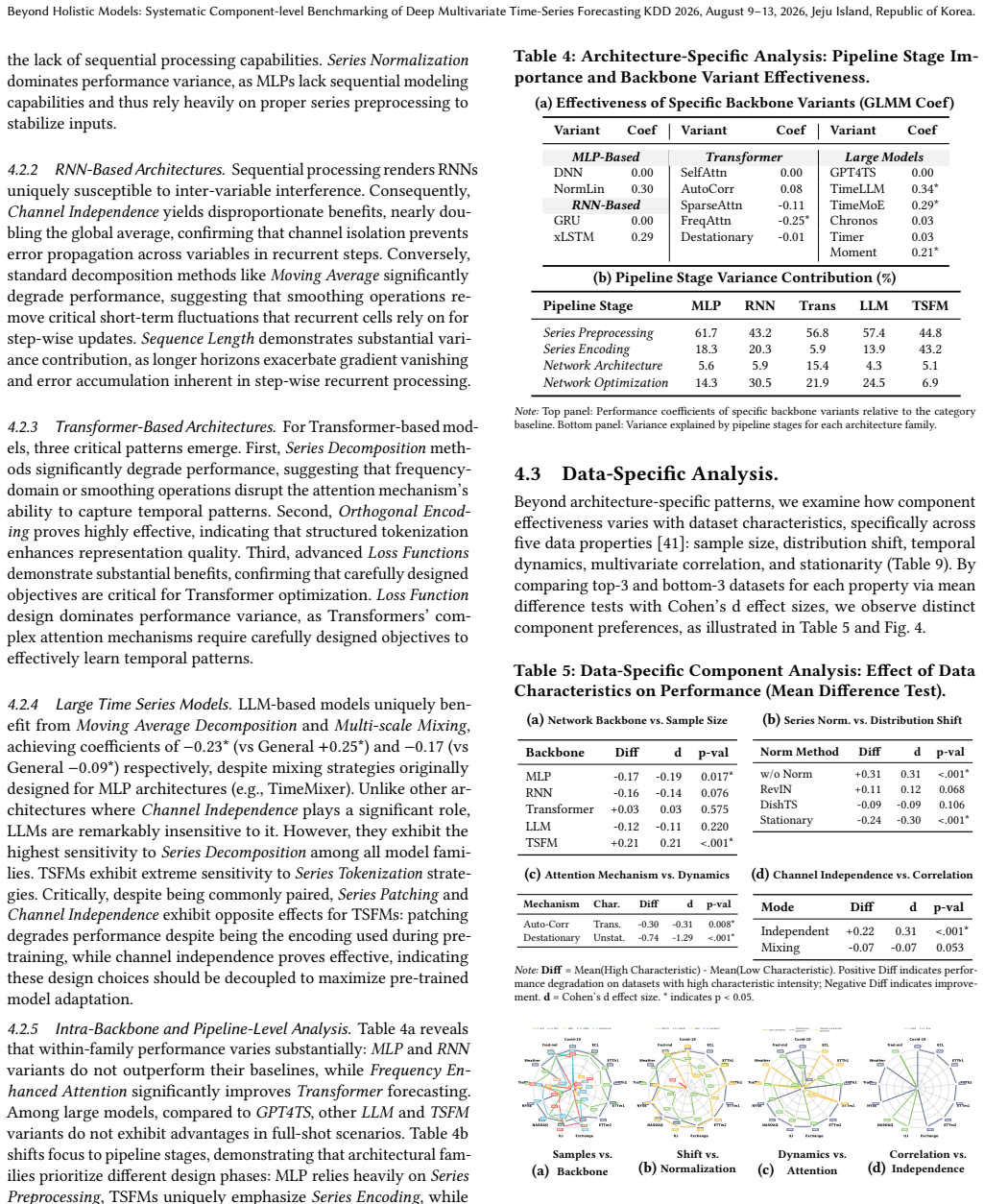
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
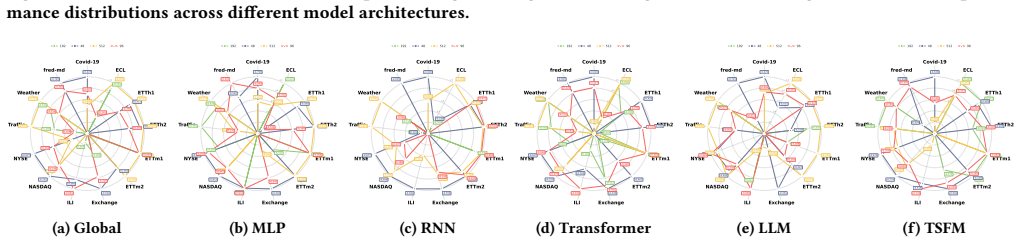
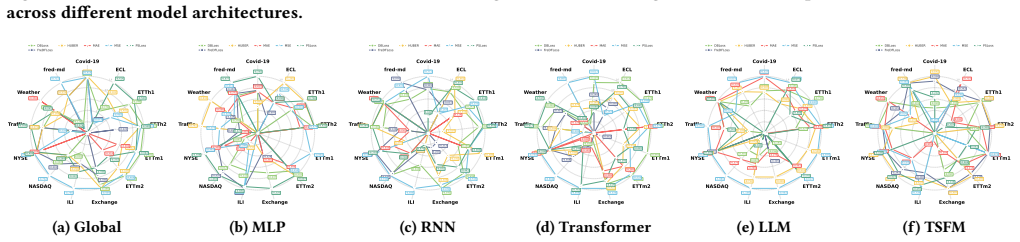
Deconstructing deep multivariate time-series forecasting methods into core components and using the resulting empirical performance corpus for automated selection produces models that outperform state-of-the-art holistic architectures, as shown by multi-view analyses of component effectiveness, interactions, and data characteristics.
What carries the argument
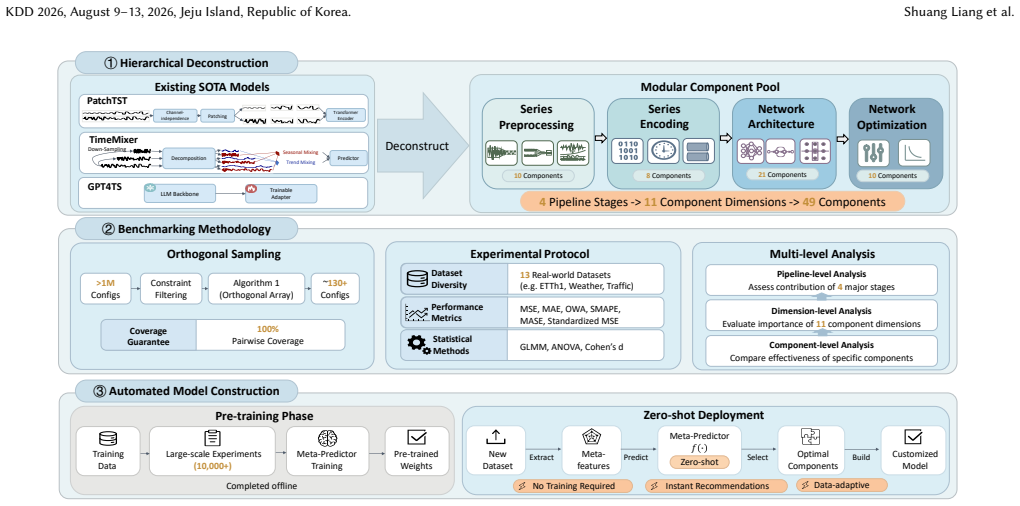
TSCOMP benchmark that applies constrained orthogonal experimental design to evaluate components and build a reusable performance corpus for zero-shot model construction.
If this is right
- Component effectiveness varies across different model backbones and data characteristics.
- Interactions among components become measurable through the orthogonal design.
- Zero-shot construction of competitive models on unseen datasets is enabled by the corpus.
- Systematic component selection surpasses manually designed complex architectures.
Where Pith is reading between the lines
- Future model development may benefit from treating forecasting systems as composable modules rather than fixed end-to-end designs.
- The benchmarking approach could be adapted to evaluate components in other sequence modeling domains.
- Corpus quality depends on dataset diversity, so expanding the collection of evaluation datasets would strengthen the method.
Load-bearing premise
The chosen components are sufficiently independent and the experimental design captures relevant interactions without systematic bias from the selected datasets or component definitions.
What would settle it
A new multivariate time series dataset on which the corpus-driven selection method performs worse than a current state-of-the-art holistic model.
Figures




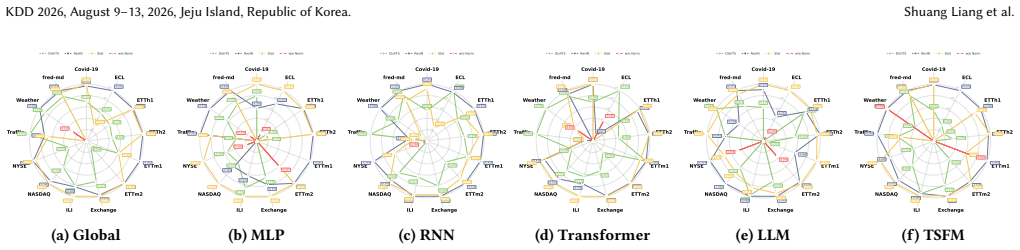

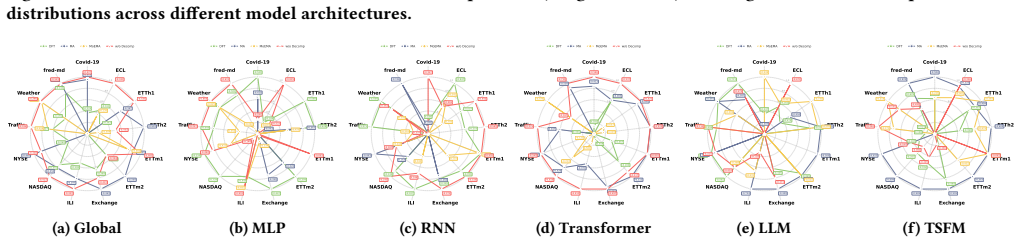
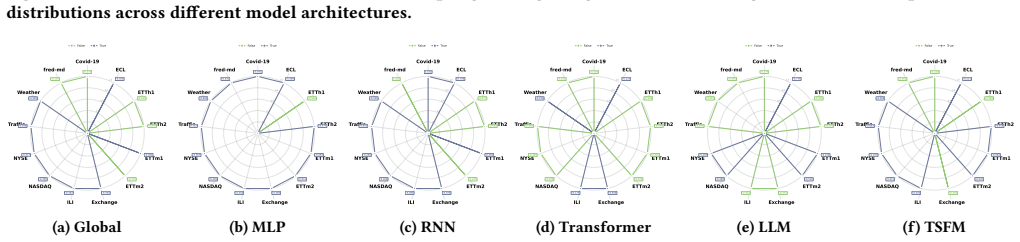

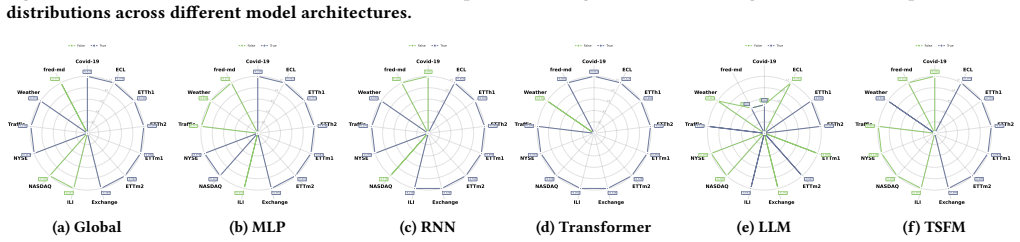
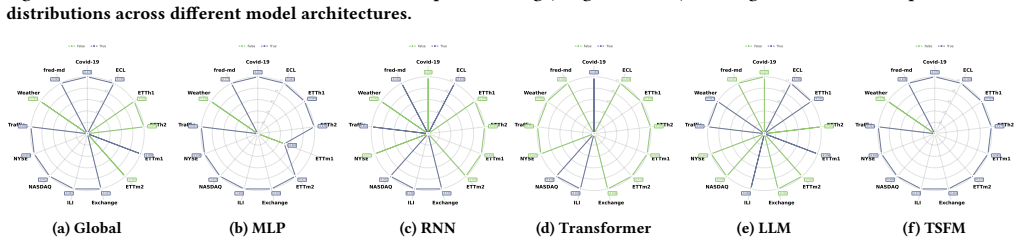
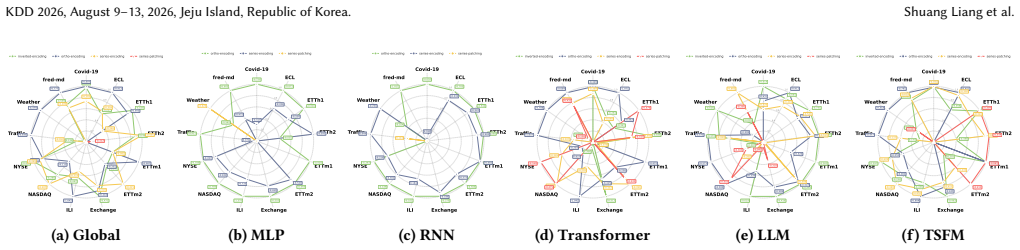


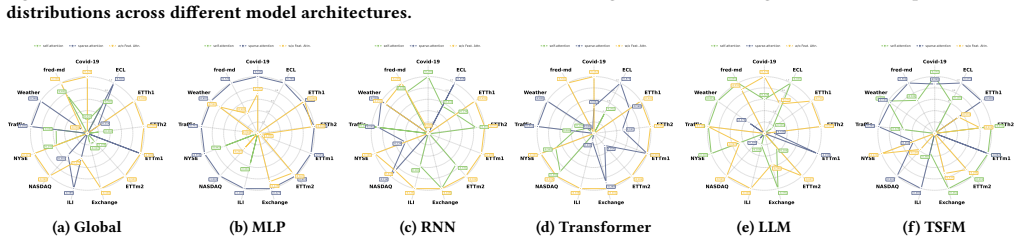
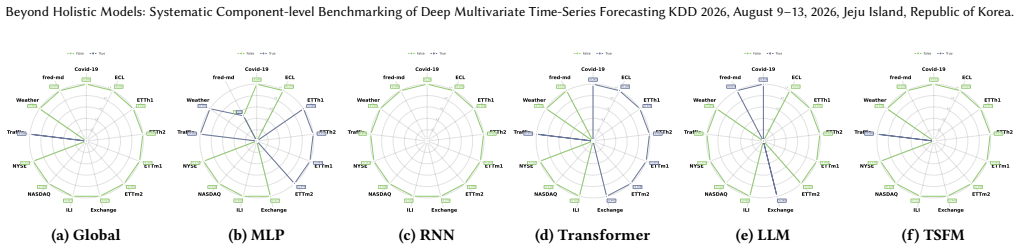


read the original abstract
While previous research in multivariate time series forecasting has focused on developing complex holistic models, this work advocates for a shift toward a granular, component-level understanding of their impacts. We propose TSCOMP, the first large-scale benchmark that systematically deconstructs deep forecasting methods into their core, fine-grained components--spanning series preprocessing, encoding strategies, network architectures including specific and large time-series models, and optimization methods. Using constrained orthogonal experimental design and extensive evaluations, we conduct multi-view analyses that reveal component effectiveness across different backbones, data characteristics, and their interactions. Beyond providing insights, this benchmark establishes a fine-grained performance corpus comprising over 20,000 model-dataset evaluations, which supports the learning of automated component selection, enabling zero-shot model construction on new datasets. Our experiments demonstrate that the corpus-driven approach, despite its simplicity, consistently outperforms state-of-the-art methods, validating the soundness of our evaluation design and confirming that systematic component selection surpasses manually designed complex architectures. All code and the performance corpus are publicly available at https://github.com/SUFE-AILAB/TSCOMP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSCOMP, the first large-scale benchmark deconstructing deep multivariate time-series forecasting models into fine-grained components (series preprocessing, encoding strategies, network architectures including specific and large TS models, and optimization methods). Using constrained orthogonal experimental design, it conducts over 20,000 model-dataset evaluations for multi-view analyses of component effectiveness and interactions, builds a performance corpus, and shows that automated component selection from the corpus enables zero-shot construction of models that outperform state-of-the-art holistic methods on new datasets. Code and corpus are released publicly.
Significance. If the central empirical claims hold after addressing methodological details, the work could meaningfully shift the field from end-to-end holistic model design toward systematic, corpus-driven component selection, offering both practical gains in forecasting performance and new insights into component interactions across data regimes. The public release of the 20k+ evaluation corpus and code is a clear strength that supports reproducibility and follow-on research.
major comments (3)
- [Abstract] Abstract: the claim that the corpus-driven approach 'consistently outperforms state-of-the-art methods' is load-bearing for the central contribution, yet the abstract (and by extension the manuscript) provides no details on component definitions, the precise values or ranges tested in each category, the statistical testing protocol, or controls against post-hoc selection bias, so the outperformance result cannot be verified.
- [Abstract] Abstract (experimental design paragraph): the constrained orthogonal design is asserted to capture interactions and support reliable zero-shot selection, but no evidence or validation is given that the design accounts for higher-order interactions (e.g., specific normalization paired with temporal encoders or large TS models) that may be dataset-dependent; if such interactions exist, the learned selector's predictions will deviate from actual performance on unseen data.
- [Abstract / Experiments] The manuscript does not report the number of datasets, the exact component enumeration, or the learning procedure for the automated selector (e.g., which regression or ranking model is trained on the corpus), all of which are required to assess whether the 20k evaluations suffice to generalize beyond the corpus.
minor comments (2)
- [Abstract] The GitHub link for code and corpus is a positive step for reproducibility; ensure the released materials include the exact component definitions and experimental scripts used to generate the corpus.
- [Abstract] Clarify the phrasing 'specific and large time-series models' when listing architecture components to avoid ambiguity in the taxonomy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the corpus-driven approach 'consistently outperforms state-of-the-art methods' is load-bearing for the central contribution, yet the abstract (and by extension the manuscript) provides no details on component definitions, the precise values or ranges tested in each category, the statistical testing protocol, or controls against post-hoc selection bias, so the outperformance result cannot be verified.
Authors: We agree that the abstract is too high-level and does not supply these specifics, which hinders immediate verification of the central claim. We will revise the abstract to briefly describe the four component categories, note the use of statistical significance testing, and reference the orthogonal design as a safeguard against selection bias. Full definitions and ranges will remain in the methods section but will be cross-referenced from the abstract. revision: yes
-
Referee: [Abstract] Abstract (experimental design paragraph): the constrained orthogonal design is asserted to capture interactions and support reliable zero-shot selection, but no evidence or validation is given that the design accounts for higher-order interactions (e.g., specific normalization paired with temporal encoders or large TS models) that may be dataset-dependent; if such interactions exist, the learned selector's predictions will deviate from actual performance on unseen data.
Authors: The constrained orthogonal design is intended to support estimation of main effects and selected two-factor interactions while remaining computationally tractable; the multi-view analyses in the paper examine several such interactions across data regimes. The empirical success of the selector on held-out datasets provides indirect support for generalization. We acknowledge, however, that an explicit check for higher-order interactions on unseen data is not reported, and we will add a short discussion of this limitation together with any additional validation that can be performed within the existing corpus. revision: partial
-
Referee: [Abstract / Experiments] The manuscript does not report the number of datasets, the exact component enumeration, or the learning procedure for the automated selector (e.g., which regression or ranking model is trained on the corpus), all of which are required to assess whether the 20k evaluations suffice to generalize beyond the corpus.
Authors: This observation is correct; these quantities are not stated with sufficient clarity or prominence. We will add an explicit summary (including the number of datasets, a table or enumeration of all tested components, and the precise training procedure for the selector) in a new or expanded subsection of the experimental setup. revision: yes
Circularity Check
No circularity: empirical corpus built from independent evaluations; outperformance claim tested on new datasets
full rationale
The paper constructs a performance corpus via 20k+ evaluations under constrained orthogonal design, then shows corpus-driven component selection outperforms SOTA on unseen datasets. This is a standard empirical pipeline with no self-definitional reductions (no X defined in terms of Y that is then 'predicted'), no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The central result is externally falsifiable against prior models and held-out data, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forecasting models can be decomposed into separable components (preprocessing, encoding, architecture, optimization) whose individual contributions can be measured independently.
Reference graph
Works this paper leans on
-
[1]
Mustafa Abdallah, Ryan Rossi, Kanak Mahadik, Sungchul Kim, Handong Zhao, and Saurabh Bagchi. 2022. Autoforecast: Automatic time-series forecasting model selection. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 5–14
2022
-
[2]
2009.Statistical methods for forecasting
Bovas Abraham and Johannes Ledolter. 2009.Statistical methods for forecasting. John Wiley & Sons
2009
-
[3]
Francisco Martinez Alvarez, Alicia Troncoso, Jose C Riquelme, and Jesus S Aguilar Ruiz. 2010. Energy time series forecasting based on pattern sequence similarity. IEEE Transactions on Knowledge and Data Engineering23, 8 (2010), 1230–1243
2010
-
[4]
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, et al. 2024. Chronos: Learning the Lan- guage of Time Series.Transactions on Machine Learning Research2024 (2024)
2024
-
[5]
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. 2018. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.arXiv preprint arXiv:1803.01271(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Marília Barandas, Duarte Folgado, Letícia Fernandes, Sara Santos, Mariana Abreu, Patrícia Bota, Hui Liu, Tanja Schultz, and Hugo Gamboa. 2020. TSFEL: Time Series Feature Extraction Library.SoftwareX11 (2020), 100456
2020
-
[7]
C Bui, N Pham, A Vo, A Tran, A Nguyen, and T Le. 2018. Time series forecasting for healthcare diagnosis and prognostics with the focus on cardiovascular diseases. In6th International Conference on the Development of Biomedical Engineering in Vietnam (BME6) 6. Springer, 809–818
2018
-
[8]
Colin Catlin. 2020. AutoTS: Automated Time Series Forecasting for Python. https://github.com/winedarksea/AutoTS
2020
-
[9]
Ching Chang, Wen-Chih Peng, and Tien-Fu Chen. 2023. Llm4ts: Two-stage fine-tuning for time-series forecasting with pre-trained llms.CoRR(2023)
2023
-
[10]
Peng Chen, Yingying ZHANG, Yunyao Cheng, Yang Shu, Yihang Wang, Qingsong Wen, Bin Yang, and Chenjuan Guo. 2024. Pathformer: Multi-scale Transformers with Adaptive Pathways for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[11]
Si-An Chen, Chun-Liang Li, Sercan O Arik, Nathanael Christian Yoder, and Tomas Pfister. 2023. TSMixer: An All-MLP Architecture for Time Series Forecast-ing. Transactions on Machine Learning Research(2023)
2023
-
[12]
Razvan-Gabriel Cirstea, Bin Yang, Chenjuan Guo, Tung Kieu, and Shirui Pan
-
[13]
In2022 IEEE 38th International Conference on Data Engineering (ICDE)
Towards spatio-temporal aware traffic time series forecasting. In2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2900–2913
-
[14]
Chirag Deb, Fan Zhang, Junjing Yang, Siew Eang Lee, and Kwok Wei Shah. 2017. A review on time series forecasting techniques for building energy consumption. Renewable and Sustainable Energy Reviews74 (2017), 902–924
2017
-
[15]
Wei Fan, Pengyang Wang, Dongkun Wang, Dongjie Wang, Yuanchun Zhou, and Yanjie Fu. 2023. Dish-ts: a general paradigm for alleviating distribution shift in time series forecasting. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 7522–7529
2023
-
[16]
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. 2015. Efficient and Robust Automated Machine Learning. InAdvances in Neural Information Processing Systems 28 (2015). 2962–2970
2015
-
[17]
Raphael Fischer and Amal Saadallah. 2024. AutoXPCR: Automated multi- objective model selection for time series forecasting. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 806–815
2024
-
[18]
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. 2024. MOMENT: A Family of Open Time-series Foundation Models. InForty-first International Conference on Machine Learning
2024
-
[19]
Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Sungwon Han, Seungeon Lee, Meeyoung Cha, Sercan O Arik, and Jinsung Yoon
-
[21]
InForty-second International Conference on Machine Learning
Retrieval Augmented Time Series Forecasting. InForty-second International Conference on Machine Learning
-
[22]
Anggit Dwi Hartanto, Yanuar Nur Kholik, and Yoga Pristyanto. 2023. Stock price time series data forecasting using the light gradient boosting machine (LightGBM) model.JOIV: International Journal on Informatics Visualization7, 4 (2023), 2270–2279
2023
-
[23]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2023. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InThe Eleventh International Conference on Learning Representations
2023
-
[24]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. 2024. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. InThe Twelfth International Conference on Learning Representations
2024
-
[25]
Shruti Kaushik, Abhinav Choudhury, Pankaj Kumar Sheron, Nataraj Dasgupta, Sayee Natarajan, Larry A Pickett, and Varun Dutt. 2020. AI in healthcare: time- series forecasting using statistical, neural, and ensemble architectures.Frontiers in big data3 (2020), 4
2020
-
[27]
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. 2021. Reversible instance normalization for accurate time-series forecasting against distribution shift. InInternational conference on learning representations
2021
-
[28]
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. 2020. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[29]
Josef Kraus et al . 2025. xLSTM-Mixer: Long Short-Term Memory Mixing for Time Series Forecasting. InICLR
2025
-
[30]
Dilfira Kudrat, Zongxia Xie, Yanru Sun, Tianyu Jia, and Qinghua Hu. 2025. Patch- wise Structural Loss for Time Series Forecasting. InInternational Conference on Machine Learning. PMLR, 31841–31859. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Shuang Liang et al
2025
-
[31]
Shiyang Li, Xiaoyong Jin, Yao Xuan, Xiyou Zhou, Wenhu Chen, Yu-Xiang Wang, and Xifeng Yan. 2019. Enhancing the locality and breaking the memory bottle- neck of transformer on time series forecasting.Advances in neural information processing systems32 (2019)
2019
-
[32]
Shengsheng Lin, Weiwei Lin, Wentai Wu, Feiyu Zhao, Ruichao Mo, and Haotong Zhang. 2025. Segrnn: Segment recurrent neural network for long-term time series forecasting.IEEE Internet of Things Journal(2025)
2025
-
[33]
Minhao Liu, Ailing Zeng, Muxi Chen, Zhijian Xu, Qiuxia Lai, Lingna Ma, and Qiang Xu. 2022. Scinet: Time series modeling and forecasting with sample convolution and interaction.Advances in Neural Information Processing Systems 35 (2022), 5816–5828
2022
-
[34]
Liu, and Schahram Dustdar
Shizhan Liu, Hang Yu, Cong Liao, Jianguo Li, Weiyao Lin, Alex X. Liu, and Schahram Dustdar. 2022. Pyraformer: Low-Complexity Pyramidal Attention for Long-Range Time Series Modeling and Forecasting. (2022)
2022
-
[35]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. 2024. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[36]
Yong Liu, Chenyu Li, Jianmin Wang, and Mingsheng Long. 2023. Koopa: Learning non-stationary time series dynamics with koopman predictors.Advances in neural information processing systems36 (2023), 12271–12290
2023
-
[37]
Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. 2022. Non-stationary transformers: Exploring the stationarity in time series forecasting.Advances in neural information processing systems35 (2022), 9881–9893
2022
-
[38]
Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. 2022. Non-stationary Transformers: Rethinking the Stationarity in Time Series Forecasting. InNeurIPS
2022
-
[39]
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. 2024. Timer: Generative Pre-trained Transformers Are Large Time Series Models. InForty-first International Conference on Machine Learning
2024
-
[40]
Zhining Liu, Ze Yang, Xiao Lin, Ruihong Qiu, Tianxin Wei, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. 2025. Breaking Silos: Adaptive Model Fusion Unlocks Better Time Series Forecasting. InInternational Conference on Machine Learning
2025
-
[41]
Ricardo P Masini, Marcelo C Medeiros, and Eduardo F Mendes. 2023. Machine learning advances for time series forecasting.Journal of economic surveys37, 1 (2023), 76–111
2023
-
[42]
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2023. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. In The Eleventh International Conference on Learning Representations
2023
-
[43]
Xiangfei Qiu, Jilin Hu, Lekui Zhou, Xingjian Wu, Junyang Du, Buang Zhang, Chenjuan Guo, Aoying Zhou, Christian S Jensen, Zhenli Sheng, et al. 2024. TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods.Proceedings of the VLDB Endowment17, 9 (2024), 2363–2377
2024
-
[44]
Xiangfei Qiu, Xingjian Wu, Hanyin Cheng, Xvyuan Liu, Chenjuan Guo, Jilin Hu, and Bin Yang. 2026. Dbloss: Decomposition-based loss function for time series forecasting.Advances in Neural Information Processing Systems38 (2026), 27741–27768
2026
-
[45]
Xiangfei Qiu, Xingjian Wu, Yan Lin, Chenjuan Guo, Jilin Hu, and Bin Yang. 2025. DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting(KDD ’25). Association for Computing Machinery, New York, NY, USA, 1185–1196. doi:10.1145/3690624.3709325
-
[46]
Omer Berat Sezer, Mehmet Ugur Gudelek, and Ahmet Murat Ozbayoglu. 2020. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019.Applied soft computing90 (2020), 106181
2020
-
[47]
Zezhi Shao, Fei Wang, Yongjun Xu, Wei Wei, Chengqing Yu, Zhao Zhang, Di Yao, Tao Sun, Guangyin Jin, Xin Cao, et al. 2024. Exploring progress in multi- variate time series forecasting: Comprehensive benchmarking and heterogeneity analysis.IEEE Transactions on Knowledge and Data Engineering(2024)
2024
-
[48]
Oleksandr Shchur, Ali Caner Turkmen, Nick Erickson, Huibin Shen, Alexander Shirkov, Tony Hu, and Bernie Wang. 2023. AutoGluon–TimeSeries: AutoML for probabilistic time series forecasting. InInternational Conference on Automated Machine Learning. PMLR, 9–1
2023
-
[49]
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. 2025. Time-moe: Billion-scale time series foundation models with mix- ture of experts. InInternational conference on learning representations, Vol. 2025. 34635–34667
2025
-
[50]
Mingtian Tan, Mike Merrill, Vinayak Gupta, Tim Althoff, and Tom Hartvigsen
-
[51]
Are language models actually useful for time series forecasting?Advances in Neural Information Processing Systems37 (2024), 60162–60191
2024
-
[52]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[53]
Hao Wang, Lichen Pan, Yuan Shen, Zhichao Chen, Degui Yang, Yifei Yang, Sen Zhang, Xinggao Liu, Haoxuan Li, and Dacheng Tao. 2025. Fredf: Learning to forecast in the frequency domain. InInternational Conference on Learning Representations, Vol. 2025. 6893–6922
2025
-
[54]
Huiqiang Wang, Jian Peng, Feihu Huang, Jince Wang, Junhui Chen, and Yifei Xiao
-
[55]
InThe eleventh international conference on learning representations
Micn: Multi-scale local and global context modeling for long-term series forecasting. InThe eleventh international conference on learning representations
-
[56]
Zhang, and JUN ZHOU
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y. Zhang, and JUN ZHOU. 2024. TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[57]
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Chen Wang, Mingsheng Long, and Jianmin Wang. 2026. Deep time series models: A comprehensive survey and benchmark.IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
2026
-
[58]
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Yong Liu, Yunzhong Qiu, Jianmin Wang, and Mingsheng Long. 2024. TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[59]
Qingsong Wen, Liang Sun, Fan Yang, Xiaomin Song, Jingkun Gao, Xue Wang, and Huan Xu. 2021. Time Series Data Augmentation for Deep Learning: A Survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI). 4653–4660
2021
-
[60]
Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, and Liang Sun. 2023. Transformers in time series: a survey. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. 6778–6786
2023
- [61]
-
[62]
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. 2023. TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis. InThe Eleventh International Conference on Learning Representations
2023
-
[63]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Fore- casting. InNeurIPS
2021
-
[64]
Peter T Yamak, Li Yujian, and Pius K Gadosey. 2019. A comparison between arima, lstm, and gru for time series forecasting. InProceedings of the 2019 2nd international conference on algorithms, computing and artificial intelligence. 49–55
2019
-
[65]
Kun Yi, Qi Zhang, Wei Fan, Shoujin Wang, Pengyang Wang, Hui He, Ning An, Defu Lian, Longbing Cao, and Zhendong Niu. 2023. Frequency-domain mlps are more effective learners in time series forecasting.Advances in Neural Information Processing Systems36 (2023), 76656–76679
2023
-
[66]
Yi Yin and Pengjian Shang. 2016. Forecasting traffic time series with multivariate predicting method.Appl. Math. Comput.291 (2016), 266–278
2016
-
[67]
Wenzhen Yue et al. 2025. OLinear: A Linear Model for Time Series Forecasting in Orthogonally Transformed Domain. InNeurIPS
2025
-
[68]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. 2023. Are transformers effective for time series forecasting?. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 11121–11128
2023
-
[69]
G Peter Zhang. 2003. Time series forecasting using a hybrid ARIMA and neural network model.Neurocomputing50 (2003), 159–175
2003
- [70]
-
[71]
Yunhao Zhang and Junchi Yan. 2023. Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting. InThe eleventh international conference on learning representations
2023
-
[72]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient transformer for long se- quence time-series forecasting. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 11106–11115
2021
-
[73]
Tian Zhou, Ziqing Ma, Qingsong Wen, Liang Sun, Tao Yao, Wotao Yin, Rong Jin, et al. 2022. Film: Frequency improved legendre memory model for long-term time series forecasting.Advances in neural information processing systems35 (2022), 12677–12690
2022
-
[74]
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. 2022. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. InICML
2022
-
[75]
Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al . 2023. One fits all: Power general time series analysis by pretrained lm.Advances in neural information processing systems36 (2023), 43322–43355. A Datasets We conduct extensive evaluations on 13 standard long-term fore- casting benchmarks: four ETT variants (ETTh1, ETTh2, ETTm1, ETTm2), Electricity (abb...
2023
-
[76]
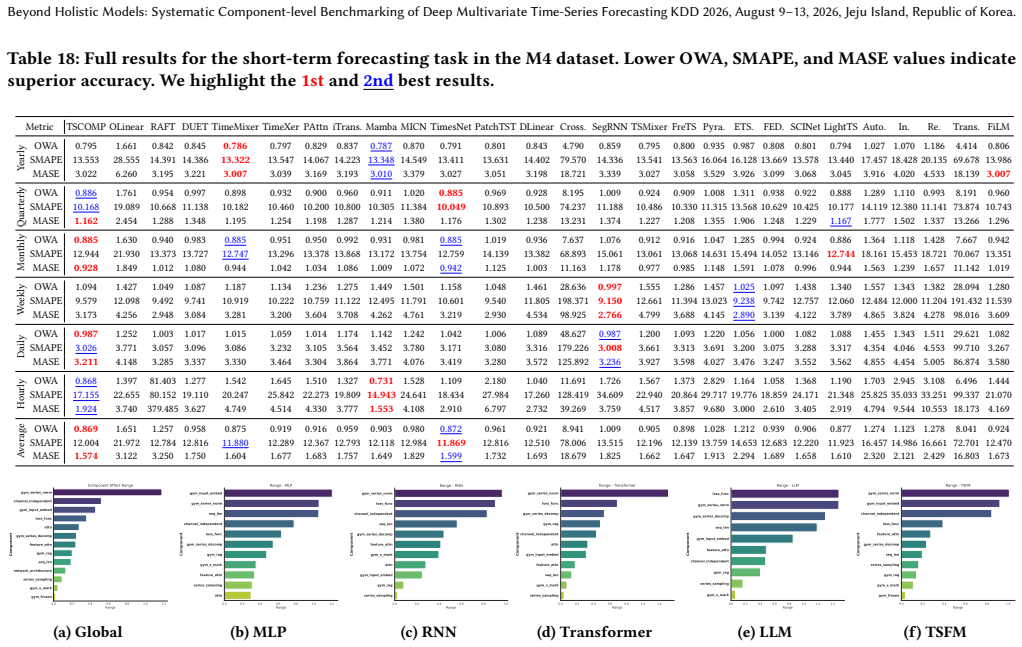
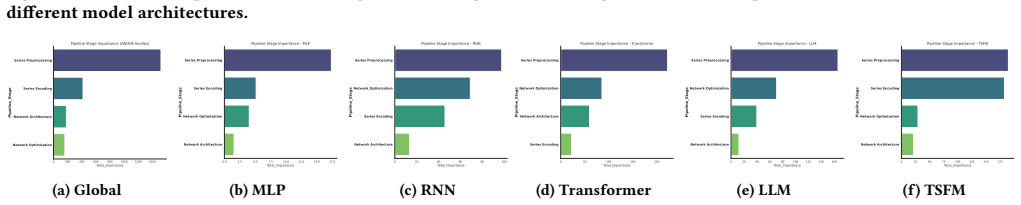
Table 18: Full results for the short-term forecasting task in the M4 dataset
[34] [11] [61] [32] [36] [57] [70] [31] [66] [59] [68] [26] [49] [69] Metric MSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAE ETTh1 96 0.371 0.3960.403 0.4160.483 0.4930.396 0.4080.707 0.6310.534 0.4990.496 0.4810.377 0.4160.467 0.4570.449 0.4520.438 0.4500.920 0.7290.834 0.6640.852 0.7230.411 0.428...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.