Hubness, Not Anisotropy, Drives Cross-Lingual Retrieval Asymmetry in Multilingual Embedding Models
Pith reviewed 2026-06-29 18:37 UTC · model grok-4.3
The pith
Hubness in multilingual embedding spaces drives asymmetric cross-lingual retrieval, while anisotropy does not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
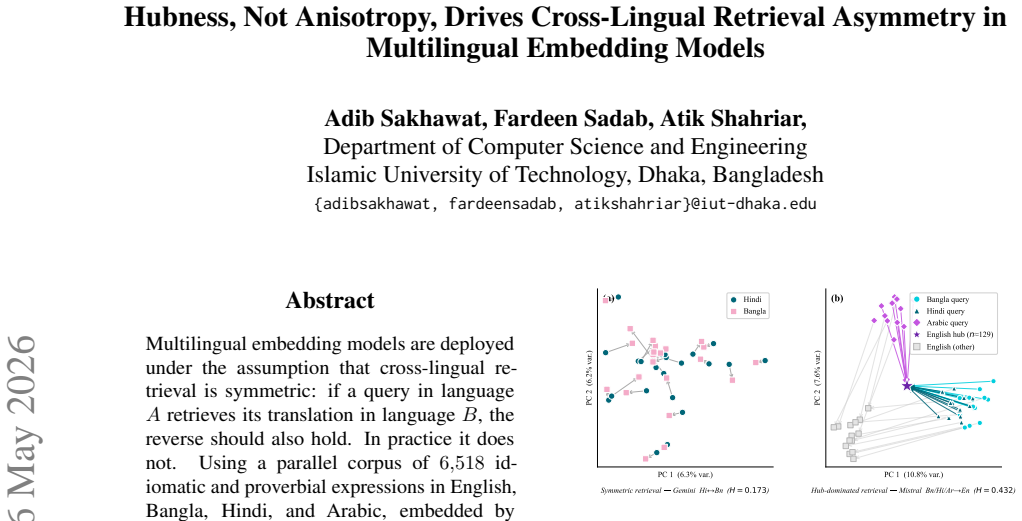
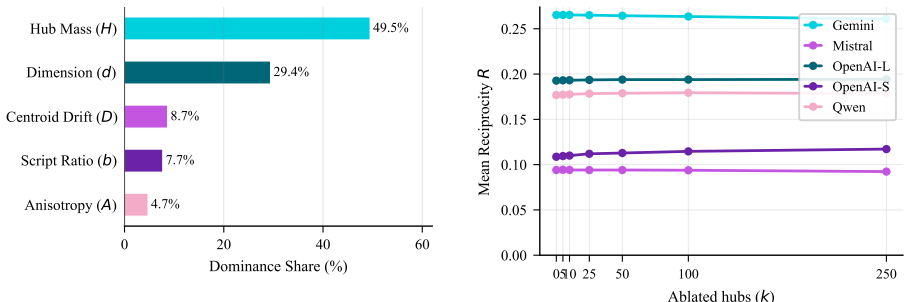
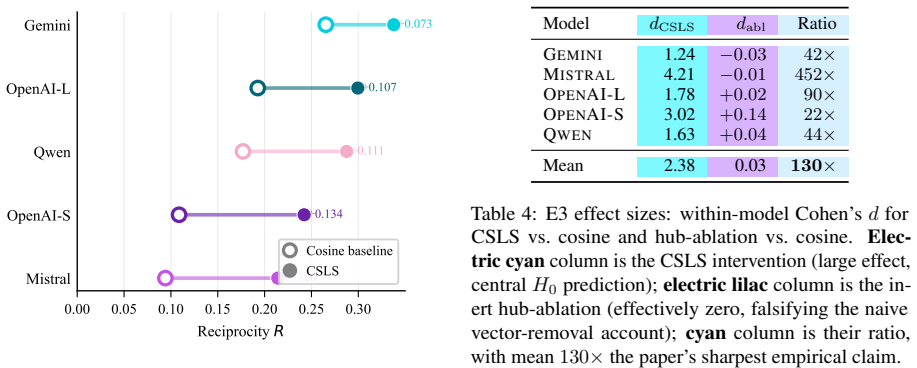
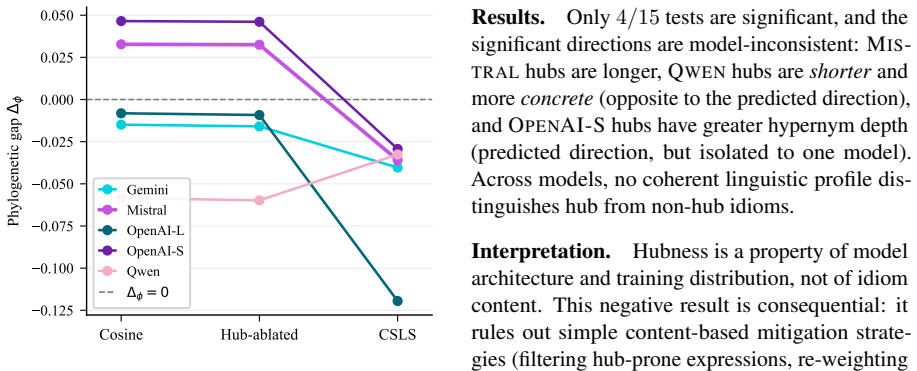
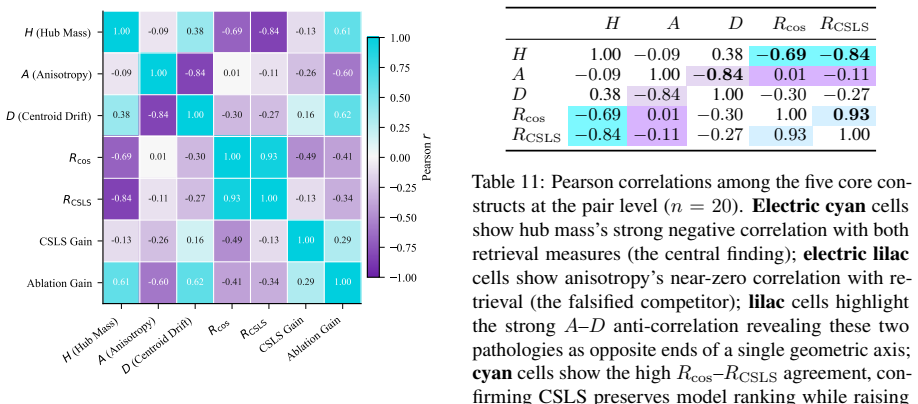
Across five pre-registered experiments, hub mass dominates a joint regression on reciprocity with a 49.5% dominance share and partial R² of 0.302, compared to 0.003 for anisotropy. The CSLS correction closes 63.5% of the worst-to-best reciprocity gap and produces a mean within-model effect size 130 times larger than surgical hub-vector ablation, establishing that hubness is a pathology of the similarity metric. The experiments also show that anisotropy and hubness are statistically dissociable.
What carries the argument
Hub mass as the dominant predictor in regressions on reciprocity, contrasted against anisotropy, centroid drift, and magnitude; the CSLS score correction that accounts for hubness in the similarity computation.
If this is right
- Replacing cosine similarity with CSLS as the default metric improves reciprocity in multilingual retrieval pipelines.
- Hubness and anisotropy are statistically separable, so interventions can target one without the other.
- The asymmetry arises from the similarity computation rather than properties of individual hub vectors.
- Production systems should apply hub-aware corrections before addressing other geometric properties.
Where Pith is reading between the lines
- Similar metric-driven asymmetries could appear in high-hubness monolingual retrieval settings.
- Model training objectives could incorporate explicit penalties for hub formation to reduce downstream asymmetry.
- Extending the tests to sentence-level or document-level retrieval would show whether the hubness effect scales beyond short idiomatic phrases.
Load-bearing premise
The 6518 idiomatic and proverbial expressions form a representative sample of the phenomena that drive asymmetry in production multilingual retrieval systems.
What would settle it
A replication in which hub mass fails to show the highest dominance share in the joint regression on reciprocity or in which CSLS fails to close a substantial share of the reciprocity gap.
Figures
read the original abstract
Multilingual embedding models are deployed under the assumption that cross-lingual retrieval is symmetric: if a query in language A retrieves its translation in language B, the reverse should also hold. In practice it does not. Using a parallel corpus of 6,518 idiomatic and proverbial expressions in English, Bangla, Hindi, and Arabic, embedded by five production-grade encoders (Gemini, Mistral, OpenAI-L, OpenAI-S, Qwen), we formalise this failure as a deficit in mutual nearest-neighbour reciprocity and test a single mechanistic claim: among the geometric pathologies of multilingual spaces, hubness, not anisotropy, centroid drift, or magnitude, is the dominant causal driver. Across five pre-registered experiments with falsification conditions specified in advance, hub mass dominates a joint regression on reciprocity (49.5% dominance share, 1.68x the next predictor; partial R^2 = 0.302 versus 0.003 for anisotropy), while a hub-aware score correction (CSLS) closes 63.5% of the worst-to-best reciprocity gap and yields a mean within-model effect size 130x larger than surgical hub-vector ablation. The latter contrast pinpoints the mechanism: hubness is a pathology of the similarity metric, not of individual hub vectors. We resolve the well-known anisotropy-hubness paradox by showing the two are statistically dissociable, and we recommend replacing cosine similarity with CSLS as the default retrieval metric for multilingual embedding pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hubness (specifically hub mass), rather than anisotropy, centroid drift, or magnitude, is the dominant driver of asymmetric cross-lingual retrieval (measured as lack of mutual nearest-neighbor reciprocity) in multilingual embedding models. Using a parallel corpus of 6,518 idiomatic and proverbial expressions in English, Bangla, Hindi, and Arabic embedded by five production encoders (Gemini, Mistral, OpenAI-L, OpenAI-S, Qwen), five pre-registered experiments with a priori falsification conditions show hub mass dominating a joint regression on reciprocity (49.5% dominance share, 1.68x the next predictor; partial R²=0.302 vs. 0.003 for anisotropy), while the hub-aware CSLS correction closes 63.5% of the worst-to-best reciprocity gap (with mean within-model effect size 130x larger than surgical hub-vector ablation). The work also claims to resolve the anisotropy-hubness paradox by statistical dissociation and recommends replacing cosine with CSLS as the default retrieval metric.
Significance. If the central mechanistic dissociation and the superiority of CSLS hold beyond the tested corpus, the result would be significant for multilingual retrieval pipelines, as it identifies a metric-level pathology rather than a vector-level one and supplies a simple, previously published correction with large reported effect sizes. The pre-registered design, explicit falsification conditions, and use of an external correction (CSLS) rather than a fitted quantity are methodological strengths that support internal validity of the regression and ablation contrasts.
major comments (2)
- [Data and Experiments sections (corpus of 6,518 idiomatic expressions)] The central claim that hubness dominates anisotropy as a driver of reciprocity (49.5% dominance share, partial R²=0.302 vs. 0.003) and that CSLS closes 63.5% of the gap is derived entirely from the 6,518 idiomatic/proverbial expressions. These items exhibit non-compositional semantics and lower lexical diversity than the literal sentences or documents typical in production cross-lingual retrieval; the pre-registered falsification conditions isolate predictors internally but do not test external validity across corpus types. This is load-bearing for the general recommendation to replace cosine with CSLS in multilingual embedding pipelines.
- [Abstract and regression results] The abstract reports dominance shares and partial R² values without error bars or details of the joint regression specification (e.g., exact predictors, multicollinearity checks, or held-out split procedure). Given that the 1.68x dominance claim and the 0.302 vs. 0.003 contrast are central to the mechanistic argument, these omissions make it difficult to assess stability of the reported effect sizes.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and the positive assessment of the methodological strengths. We address the major comments point by point below.
read point-by-point responses
-
Referee: The central claim that hubness dominates anisotropy as a driver of reciprocity (49.5% dominance share, partial R²=0.302 vs. 0.003) and that CSLS closes 63.5% of the gap is derived entirely from the 6,518 idiomatic/proverbial expressions. These items exhibit non-compositional semantics and lower lexical diversity than the literal sentences or documents typical in production cross-lingual retrieval; the pre-registered falsification conditions isolate predictors internally but do not test external validity across corpus types. This is load-bearing for the general recommendation to replace cosine with CSLS in multilingual embedding pipelines.
Authors: We selected the idiomatic corpus to ensure high-quality parallel translations with controlled semantics, enabling precise measurement of reciprocity. While we agree that this corpus type may limit generalizability to literal text, the geometric properties tested (hubness, anisotropy) are intrinsic to the embedding spaces and not corpus-specific. Nevertheless, to address external validity concerns, we will revise the discussion and conclusion to explicitly note the corpus limitation and recommend validation on additional corpora before broad adoption of CSLS. This constitutes a partial revision. revision: partial
-
Referee: The abstract reports dominance shares and partial R² values without error bars or details of the joint regression specification (e.g., exact predictors, multicollinearity checks, or held-out split procedure). Given that the 1.68x dominance claim and the 0.302 vs. 0.003 contrast are central to the mechanistic argument, these omissions make it difficult to assess stability of the reported effect sizes.
Authors: We accept this point. The full regression details, including predictors, VIF checks for multicollinearity, and cross-validation procedure, are provided in the Methods section. For the abstract, we will add a brief mention of the regression approach and report standard errors or confidence intervals for the key statistics in a revised version. This will improve transparency without changing the results. revision: yes
Circularity Check
No circularity: empirical regression on held-out data with external correction
full rationale
The paper's derivation rests on pre-registered regression experiments that treat hub mass as an independent predictor of reciprocity on a fixed corpus of 6518 expressions, with partial R² and dominance shares computed from the data. CSLS is invoked as a previously published external method rather than a quantity derived inside the paper. No step equates a claimed prediction to its own fitted inputs by construction, invokes self-citation as the sole justification for a uniqueness claim, or renames a known result via new coordinates. The chain is therefore self-contained and falsifiable against the stated corpus and external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Nearest-neighbor reciprocity on a parallel idiomatic corpus is a sufficient and unbiased measure of cross-lingual retrieval asymmetry in production systems.
- domain assumption The five production encoders produce vector spaces whose geometric properties can be compared directly via the same set of summary statistics.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 17th Conference of the European Chapter of the As- sociation for Computational Linguistics, pages 3682– 3700, Dubrovnik, Croatia
Automatic evaluation and analysis of idioms in neural machine translation. InProceedings of the 17th Conference of the European Chapter of the As- sociation for Computational Linguistics, pages 3682– 3700, Dubrovnik, Croatia. Association for Computa- tional Linguistics. Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek,...
2020
-
[2]
Improving zero-shot learning by mitigating the hubness problem
Improving zero-shot learning by mitigating the hubness problem.arXiv preprint arXiv:1412.6568. Kawin Ethayarajh. 2019. How contextual are contex- tualized word representations? comparing the ge- ometry of bert, elmo, and gpt-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Jo...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
remove abstract idioms before retrieval
Examining the tip of the iceberg: A data set for idiom translation. InProceedings of the Eleventh In- ternational Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA). Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. 2020. Language- agnostic bert sentence em...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.