LATTE: Forecasting Peer Anchored Preference Trajectories for Personalized LLM Generation
Pith reviewed 2026-06-29 18:34 UTC · model grok-4.3
The pith
Personalization for frozen LLMs improves by forecasting how a user deviates from peers on shared items rather than averaging past responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
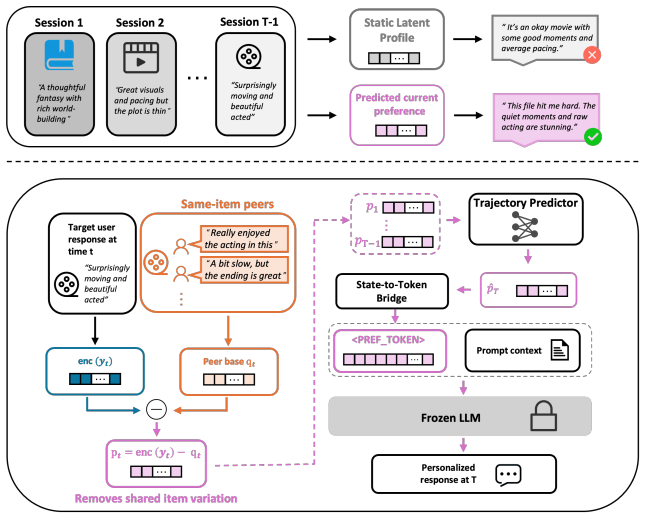
LATTE represents personalization as forecasting a peer anchored relative preference state. For each historical session it subtracts a time-masked baseline formed from comparable users who responded to the same item, producing a state that measures how the target user differs from peers under a shared item context. A lightweight sequence predictor then forecasts the next state in this trajectory, and a State to Token Bridge injects the forecast into a frozen instruction-tuned LLM through a single anchored soft token. Latent factor analysis shows when peer anchoring cancels shared item variation, and experiments on Amazon Reviews 2023 and MemoryCD show consistent gains over retrieval, summary
What carries the argument
Peer anchored relative preference state formed by subtracting time-masked peer baselines, then forecasted by a sequence predictor and passed through a State to Token Bridge as one soft token.
If this is right
- User histories become trajectories of relative deviations rather than absolute aggregates, allowing separation of item content from personal drift.
- A single soft token can carry enough dynamic information to condition an instruction-tuned LLM without full history retrieval.
- Forecasting future states trades off stale historical averages against noisy recent observations, improving recency without added noise.
- The method's gains arise from the forecasting step rather than the mere presence of a soft prompt interface.
- Lightweight sequence models suffice to capture useful preference dynamics once the state is expressed in peer-relative terms.
Where Pith is reading between the lines
- The same deviation-forecasting structure could apply to sequential recommendation or dialogue tasks where user interests shift over repeated interactions.
- Efficient peer-group identification at inference time would be needed for online deployment, perhaps via precomputed clusters.
- Extending the forecast to multiple future steps could support proactive generation that anticipates preference changes before they appear in new data.
- Hybrid systems might combine the forecasted deviation token with selective retrieval of only the most recent sessions to further reduce staleness.
Load-bearing premise
Subtracting a time-masked baseline from comparable users isolates only the target user's deviation and that this deviation state follows a trajectory a lightweight sequence model can forecast usefully instead of simply recovering fitted averages.
What would settle it
If replacing the forecasted state with the most recent observed deviation or with a static peer-average deviation removes the ROUGE-L gains on the same datasets, the value of trajectory forecasting would be refuted.
Figures
read the original abstract
Personalized generation with frozen large language models requires a conditioning signal that is both compact and current. Existing personalization methods typically retrieve or summarize user histories in text, or compress them into static latent profiles and soft prompts. These approaches are efficient, but they treat a user's past behavior as an aggregate profile and therefore mix stable identity, recent drift, and item content in the same representation. We propose LAtent Trajectory Tracking and Extrapolation (LATTE), a framework that represents personalization as forecasting a peer anchored relative preference state. For each historical session, LATTE subtracts a time masked baseline formed from comparable users who responded to the same item, producing a state that measures how the target user differs from peers under a shared item context. A lightweight sequence predictor then forecasts the next state in this trajectory, and a State to Token Bridge injects the forecast into a frozen instruction tuned LLM through a single anchored soft token. We provide a latent factor analysis showing when peer anchoring cancels shared item variation and why temporal forecasting trades off stale averages against noisy recent states. Experiments on Amazon Reviews 2023 and MemoryCD show that LATTE consistently outperforms retrieval, summary memory, static latent profiles, difference aware latent profiles, and soft prompt compression baselines. On Amazon Reviews 2023, LATTE improves average ROUGE-L from 0.219 for a static latent profile and 0.245 for the strongest added latent compression baseline to 0.259. Additional pairwise comparisons and diagnostic analyses suggest that the improvement is mainly due to forecasting user-specific trajectory information, rather than merely adding a soft prompt interface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LATTE, a framework for personalized generation with frozen LLMs. It represents user histories as trajectories in a peer-anchored relative preference state obtained by subtracting a time-masked baseline formed from comparable users responding to the same item. A lightweight sequence predictor forecasts the next state, which is injected into the LLM via a single soft token through a State to Token Bridge. Experiments on Amazon Reviews 2023 and MemoryCD report consistent outperformance over retrieval, summary memory, static latent profiles, difference-aware profiles, and soft-prompt compression baselines, with ROUGE-L improving from 0.245 (strongest baseline) to 0.259 on Amazon Reviews 2023; pairwise comparisons and diagnostics are said to attribute gains primarily to trajectory forecasting rather than the soft-prompt interface. A latent factor analysis is provided to explain when peer anchoring cancels shared item variation.
Significance. If the central mechanism holds, the work would offer a compact, dynamic alternative to static profiles for capturing preference drift in LLM personalization. The peer-anchoring construction and explicit forecasting step are conceptually distinct from prior retrieval or compression methods, and the reported gains on two public datasets plus diagnostic analyses constitute a concrete empirical contribution. Reproducible experiments on named public datasets are a strength.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the ROUGE-L lift (0.259 vs. 0.245) is presented without error bars, statistical tests, or dataset statistics; this is load-bearing for the claim that gains are due to forecasting user-specific trajectories rather than the soft-prompt interface, as the modest absolute improvement could be within noise.
- [Method (peer anchoring)] Method section on peer-anchored state construction: the subtraction of a time-masked baseline from comparable users is asserted to isolate only the target user's deviation after canceling shared item variation, but no validation (e.g., correlation checks between comparable-user selection and target preferences, or residual temporal structure after masking) is supplied; this assumption is central to the claim that the forecasted state contains genuine trajectory signal rather than fitted averages or contamination.
- [Latent factor analysis / Diagnostics] Latent factor analysis and diagnostic analyses: these are invoked to show when peer anchoring works and that improvements stem from trajectory forecasting, yet the abstract supplies no concrete equations, ablation tables, or quantitative checks ruling out that the lightweight predictor simply recovers averages; without these details the attribution to the trajectory component remains unverified.
minor comments (2)
- [Method] Notation for the State to Token Bridge and the sequence predictor architecture is introduced without a clear diagram or pseudocode, making the injection mechanism harder to follow.
- [Experiments] The paper should include a table of dataset statistics (number of users, sessions, items) and baseline implementation details to allow direct replication of the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional rigor in reporting and validation would strengthen the claims. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the ROUGE-L lift (0.259 vs. 0.245) is presented without error bars, statistical tests, or dataset statistics; this is load-bearing for the claim that gains are due to forecasting user-specific trajectories rather than the soft-prompt interface, as the modest absolute improvement could be within noise.
Authors: We agree that error bars, statistical tests, and dataset statistics are needed to substantiate the reported gains and rule out noise. In the revision we will add standard deviations from multiple random seeds, pairwise statistical significance tests (e.g., paired t-tests), and basic dataset statistics (user/item counts, session lengths) to both the abstract and experiments section. revision: yes
-
Referee: [Method (peer anchoring)] Method section on peer-anchored state construction: the subtraction of a time-masked baseline from comparable users is asserted to isolate only the target user's deviation after canceling shared item variation, but no validation (e.g., correlation checks between comparable-user selection and target preferences, or residual temporal structure after masking) is supplied; this assumption is central to the claim that the forecasted state contains genuine trajectory signal rather than fitted averages or contamination.
Authors: The peer-anchoring step is defined to cancel shared item effects via the time-masked baseline. We acknowledge that explicit validation (correlation between peer selection and target deviation, or checks on residual temporal structure) was not reported. We will add these quantitative checks in the revised method and experiments sections to confirm the states isolate user-specific trajectory signal. revision: yes
-
Referee: [Latent factor analysis / Diagnostics] Latent factor analysis and diagnostic analyses: these are invoked to show when peer anchoring works and that improvements stem from trajectory forecasting, yet the abstract supplies no concrete equations, ablation tables, or quantitative checks ruling out that the lightweight predictor simply recovers averages; without these details the attribution to the trajectory component remains unverified.
Authors: The manuscript body contains the latent factor analysis and diagnostics, including the trade-off between stale averages and noisy recent states. To strengthen attribution, we will insert the explicit equations for state construction and the forecasting objective, plus new ablation tables that directly compare the full trajectory model against a static-average variant of the same predictor. These additions will be referenced from the abstract. revision: yes
Circularity Check
No significant circularity; empirical method with external validation
full rationale
The paper describes an empirical framework (peer baseline subtraction followed by sequence prediction and soft-token injection) and validates it via experiments on public datasets (Amazon Reviews 2023, MemoryCD) against multiple baselines, reporting ROUGE-L gains. No equations, derivations, or self-citation chains are exhibited that reduce the claimed forecasting benefit to a fitted input or tautological definition by construction. The latent factor analysis is presented as explanatory rather than load-bearing, and the central performance claims rest on external test-set comparisons rather than internal self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- lightweight sequence predictor parameters
axioms (1)
- domain assumption Comparable users exist whose responses to the identical item form a valid time-masked baseline that cancels shared item variation.
invented entities (2)
-
peer anchored relative preference state
no independent evidence
-
State to Token Bridge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PeReGrINE: Evaluating Personalized Review Fidelity with User Item Graph Context
Steven Au and Baihan Lin. PeReGrINE: Evaluating personalized review fidelity with user-item graph context.arXiv preprint arXiv:2604.07788,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. BGE M3-Embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Learning phrase representations using RNN encoder-decoder for statistical machine translation
Kyunghyun Cho, Bart van Merriënboer, Çaglar Gülçehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2014
-
[4]
Yiming Du, Hongru Wang, Zhengyi Zhao, Bin Liang, Baojun Wang, Wanjun Zhong, Zezhong Wang, and Kam-Fai Wong. PerLTQA: A personal long-term memory dataset for memory classification, retrieval, and synthesis in question answering. InarXiv preprint arXiv:2402.16288,
-
[5]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/abs/2407.11016. Jiongnan Liu et al. PPlug: Personalized plug-and-play profile models for LLM personalization.arXiv preprint arXiv:2409.11901,
-
[8]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents.arXiv preprint arXiv:2402.17753,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Steve Menezes, Tina Baghaee, Em- manuel Barajas Gonzalez, Jennifer Neville, and Tara Safavi. PEARL: Personalizing large language model writing assistants with generation-calibrated retrievers.arXiv preprint arXiv:2311.09180,
-
[10]
User-LLM: Efficient LLM contextualization with user embeddings
Lin Ning, Luyang Liu, Jiaxing Wu, Neo Wu, Devora Berlowitz, Sushant Prakash, Bradley Green, Shawn O’Banion, and Jun Xie. User-LLM: Efficient LLM contextualization with user embeddings. arXiv preprint arXiv:2402.13598,
-
[11]
Latent inter-user difference modeling for LLM personalization
Yilun Qiu, Tianhao Shi, Xiaoyan Zhao, Fengbin Zhu, Yang Zhang, and Fuli Feng. Latent inter-user difference modeling for LLM personalization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025a. Oral presentation. Yilun Qiu, Xiaoyan Zhao, Yang Zhang, Yimeng Bai, Wenjie Wang, Hong Cheng, Fuli Feng, and Tat...
-
[12]
Zhaoxuan Tan, Zheyuan Liu, and Meng Jiang. Personalized pieces: Efficient personalized large language models through collaborative efforts.arXiv preprint arXiv:2406.10471,
-
[13]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
URLhttps://proceedings.mlr.press/v235/wang24s.html. 11 Di Wu, Hongwei Wang, Wenhao Yu, Yunsheng Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URL https://openreview.net/forum?id=TrjbxzRcnf-. Spotlight presentation. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang...
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
-
[16]
A beautiful and thoughtful book with an interesting plot and compelling characters. The writing is well crafted and the themes resonate
Buckets are computed per target user prefix and then averaged across categories. Bucket Static latent DEP style static LATTEGRU∆vs DEP Peer count 4 to 7 .213 .229 .243 +.014 Peer count 8 to 15 .221 .241 .259 +.018 Peer count 16 or more .226 .246 .266 +.020 History length 8 to 15 .218 .231 .243 +.012 History length 16 to 31 .221 .240 .258 +.018 History len...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.