FAST-GOAL: Fast and Efficient Global-local Object Alignment Learning
Pith reviewed 2026-06-29 18:21 UTC · model grok-4.3
The pith
FAST-GOAL adapts CLIP to lengthy detailed captions by aligning local image regions with corresponding sentences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
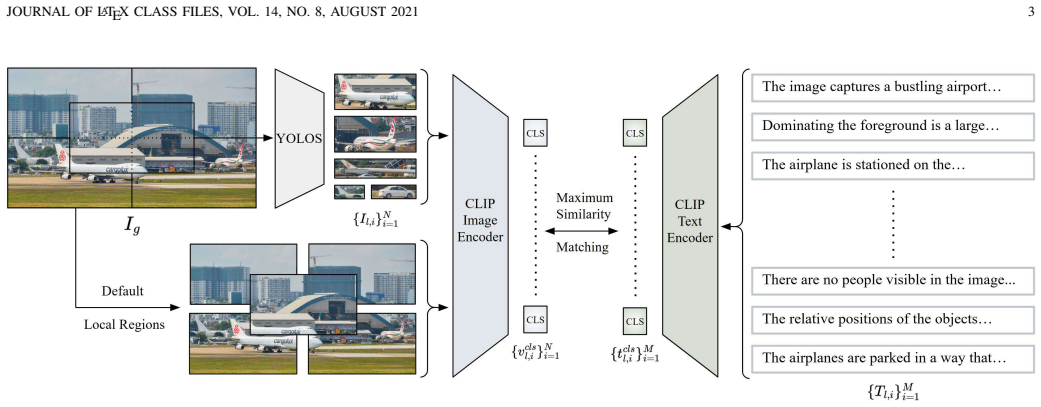
FAST-GOAL enhances CLIP's ability to handle lengthy text through global-local semantic alignment. Fast Local Image-Sentence Matching extracts local image regions via object detection and spatial division and pairs them with corresponding sentences. Token Similarity-based Learning then maximizes the similarity between patch tokens from those regions and their region embeddings, applying the same principle on the text side.
What carries the argument
FAST-GOAL framework consisting of Fast Local Image-Sentence Matching (FLISM) for region-to-sentence pairing and Token Similarity-based Learning (TSL) for patch-token similarity maximization.
If this is right
- The method produces significant improvements on long-caption datasets such as DOCCI and DCI.
- Performance on short-caption datasets such as MSCOCO and Flickr30k is maintained or improved.
- Adaptation to detailed textual descriptions occurs with limited extra computational cost.
- The introduced GLIT100k dataset supplies both global image-caption pairs and derived local pairs.
Where Pith is reading between the lines
- The same local-matching principle could be tested on other vision-language models that face length mismatches between pre-training and target data.
- Improvements in object detection accuracy would directly strengthen the reliability of the region extraction step.
- The alignment technique might support downstream tasks that require fine-grained correspondence, such as referring expression comprehension.
Load-bearing premise
Local descriptions extracted from global captions maintain semantic coherence and object detection combined with spatial division can reliably identify image regions that match specific sentences.
What would settle it
Apply the fine-tuning to a test set of images and captions where local sentence-region pairings have been randomly shuffled and check whether performance gains over baselines disappear.
Figures





read the original abstract
Vision-language models such as CLIP have shown impressive capabilities in aligning images and text, but they often struggle with lengthy and detailed text descriptions due to pre-training on short and concise captions. We present FAST-GOAL (Fast and Efficient Global-local Object Alignment Learning), an efficient fine-tuning method that enhances ability of CLIP to handle lengthy text through global-local semantic alignment. Our method consists of two key components. First, Fast Local Image-Sentence Matching (FLISM) efficiently extracts local image regions through object detection and spatial division, then matches them with corresponding sentences. Second, Token Similarity-based Learning (TSL) maximizes the similarity between patch tokens from specific regions in the image and their corresponding region embeddings, applying the same principle to text, which enhances the ability of the model to capture detailed correspondences. Additionally, we introduce GLIT100k, a dataset that provides both global image-lengthy caption pairs and context-derived local pairs, where local descriptions are extracted from global captions to maintain semantic coherence. Through extensive experiments on long caption datasets (DOCCI, DCI) and short caption datasets (MSCOCO, Flickr30k), we demonstrate that FAST-GOAL achieves significant improvements over baselines, enabling effective adaptation of CLIP to detailed textual descriptions while maintaining computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FAST-GOAL, an efficient fine-tuning method for adapting CLIP to lengthy and detailed text descriptions via global-local semantic alignment. It consists of FLISM, which uses object detection and spatial division to extract and match local image regions to sentences from captions, and TSL, which maximizes similarity between image patch tokens from matched regions and corresponding embeddings (applied symmetrically to text). A new dataset GLIT100k is presented that supplies both global image-long caption pairs and context-derived local pairs. Experiments on long-caption datasets (DOCCI, DCI) and short-caption datasets (MSCOCO, Flickr30k) are claimed to show significant improvements over baselines while preserving computational efficiency.
Significance. If the reported gains are robust and the region-sentence alignment mechanism is shown to be effective rather than incidental, the work would supply a practical, low-cost route for extending vision-language models beyond their short-caption pre-training regime, with potential utility for tasks that require fine-grained correspondence between detailed text and image content.
major comments (2)
- [FLISM component (method description)] The description of FLISM provides no quantitative validation (e.g., local retrieval precision, alignment accuracy, or human judgment) that the regions produced by object detection plus spatial division meaningfully correspond to the extracted sentences. This is load-bearing for the central claim, because if the correspondences are noisy or heuristic, TSL cannot enforce the intended detailed global-local alignment and any observed gains may arise from generic fine-tuning.
- [Abstract and experimental claims] The abstract asserts 'significant improvements' on DOCCI, DCI, MSCOCO, and Flickr30k yet supplies no numerical results, baseline definitions, statistical tests, ablation controls, or effect sizes. Without these, it is impossible to assess whether the central empirical claim holds or whether post-hoc design choices affect the outcome.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., recall@1 or relative improvement) to substantiate the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of validation for FLISM and clarity in the abstract's empirical claims. We address each point below, indicating revisions where appropriate to strengthen the paper.
read point-by-point responses
-
Referee: [FLISM component (method description)] The description of FLISM provides no quantitative validation (e.g., local retrieval precision, alignment accuracy, or human judgment) that the regions produced by object detection plus spatial division meaningfully correspond to the extracted sentences. This is load-bearing for the central claim, because if the correspondences are noisy or heuristic, TSL cannot enforce the intended detailed global-local alignment and any observed gains may arise from generic fine-tuning.
Authors: We agree that direct quantitative validation of the region-sentence correspondences in FLISM would strengthen the central claim. The current manuscript relies on indirect evidence through performance improvements on long-caption tasks (DOCCI, DCI) where fine-grained alignment is essential, as well as the construction of GLIT100k which derives local pairs from global captions to preserve coherence. However, we acknowledge the absence of explicit metrics such as retrieval precision or human judgments on alignment quality. In the revised manuscript, we will add a dedicated analysis subsection (likely in Section 3 or 4) reporting alignment accuracy using object detection confidence thresholds and a small-scale human evaluation on a subset of matches to demonstrate that the correspondences are meaningful. revision: yes
-
Referee: [Abstract and experimental claims] The abstract asserts 'significant improvements' on DOCCI, DCI, MSCOCO, and Flickr30k yet supplies no numerical results, baseline definitions, statistical tests, ablation controls, or effect sizes. Without these, it is impossible to assess whether the central empirical claim holds or whether post-hoc design choices affect the outcome.
Authors: The abstract is written to be concise and high-level, with all numerical results, baseline comparisons, ablations, and effect sizes provided in the experimental section (Section 4) along with tables and statistical details. We recognize that including key quantitative highlights in the abstract would improve transparency. We will revise the abstract to incorporate specific improvement percentages and reference the main baselines (e.g., standard CLIP fine-tuning) while keeping the length appropriate. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper introduces FAST-GOAL as a fine-tuning procedure with two named components (FLISM for region-sentence extraction via detection+division, TSL for token similarity) plus a new dataset GLIT100k whose local pairs are derived from global captions. All load-bearing claims are empirical performance gains on DOCCI/DCI/MSCOCO/Flickr30k; no equations, fitted parameters, or self-citation chains are supplied that would reduce any reported quantity to an input by construction. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Object detection plus spatial division produces local image regions that meaningfully correspond to sentences within lengthy captions.
- domain assumption Local pairs derived by splitting global captions preserve semantic coherence with the original image.
Reference graph
Works this paper leans on
-
[1]
GOAL: Global-local object alignment learning,
H. Choi, Y . K. Jang, and C. Eom, “GOAL: Global-local object alignment learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 4070–4079
2025
-
[2]
DOCCI: Descriptions of connected and contrasting images,
Y . Onoe, S. Rane, Z. Berger, Y . Bitton, J. Cho, R. Garg, A. Ku, Z. Parekh, J. Pont-Tuset, G. Tanzeret al., “DOCCI: Descriptions of connected and contrasting images,” inProceedings of the European Conference on Computer Vision, 2024, pp. 291–309
2024
-
[3]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
2023
-
[4]
You only look at one sequence: Rethinking transformer in vision through object detection,
Y . Fang, B. Liao, X. Wang, J. Fang, J. Qi, R. Wu, J. Niu, and W. Liu, “You only look at one sequence: Rethinking transformer in vision through object detection,” inAdvances in Neural Information Processing Systems, 2021, pp. 26 183–26 197
2021
-
[5]
Learning transferable visual representations from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual representations from natural language supervision,” inProceed- ings of the International Conference on Machine Learning, 2021, pp. 8748–8763
2021
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inProceedings of the International Conference on Learning Representations, 2021
2021
-
[7]
A picture is worth more than 77 text tokens: Evaluating CLIP-style models on dense captions,
J. Urbanek, F. Bordes, P. Astolfi, M. Williamson, V . Sharma, and A. Romero-Soriano, “A picture is worth more than 77 text tokens: Evaluating CLIP-style models on dense captions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 700–26 709
2024
-
[8]
Long-CLIP: Unlocking the long-text capability of CLIP,
B. Zhang, P. Zhang, X. Dong, Y . Zang, and J. Wang, “Long-CLIP: Unlocking the long-text capability of CLIP,” inProceedings of the European Conference on Computer Vision, 2025, pp. 310–325
2025
-
[9]
Microsoft COCO: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft COCO: Common objects in context,” inProceedings of the European Conference on Computer Vision, 2014, pp. 740–755
2014
-
[10]
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,
P. Young, A. Lai, M. Hodosh, and J. Hockenmaier, “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,” inTransactions of the Association for Computational Linguistics, 2014, pp. 67–78
2014
-
[11]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Q. Sun, Y . Fang, L. Wu, X. Wang, and Y . Cao, “EV A-CLIP: Im- proved training techniques for CLIP at scale,” inarXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Siglip 2: Multilingual vision-language encoders with improved semantic un- derstanding, localization, and dense features,
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafaet al., “Siglip 2: Multilingual vision-language encoders with improved semantic un- derstanding, localization, and dense features,” 2025
2025
-
[13]
Mobileclip2: Improving multi-modal reinforced training,
F. Faghri, P. K. A. Vasu, C. Koc, V . Shankar, A. Toshev, O. Tuzel, and H. Pouransari, “Mobileclip2: Improving multi-modal reinforced training,” 2025
2025
-
[14]
Tinyclip: Clip distillation via affinity mimicking and weight inheritance,
K. Wu, H. Peng, Z. Zhou, B. Xiao, M. Liu, L. Yuan, H. Xuan, M. Valenzuela, X. S. Chen, X. Wanget al., “Tinyclip: Clip distillation via affinity mimicking and weight inheritance,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 970–21 980
2023
-
[15]
LLaV A- NeXT: Improved reasoning, OCR, and world knowledge,
H. Liu, C. Li, Y . Li, B. Li, Y . Zhang, S. Shen, and Y . J. Lee, “LLaV A- NeXT: Improved reasoning, OCR, and world knowledge,” 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.